













優化算法在深度學習中扮演著重要角色:它們調整模型的權重,以最小化訓練过程中的損失函數。這樣一個算法就是Adam 優化器。
Adam 因其在結合動量與自適應學習率方面的能力而在深度學習中變得非常受欢迎。這使其對於訓練深層神经網絡非常高效率。它還需要最少的超參數調節,因此使其在各種任務上廣泛可用且有效。
在2017年,伊LYA Loshchilov和Frank Hutter在其論文“解耦權重衰减regularization。”中推出了Adam算法的一个更進階版本。他們將其命名為AdamW,這代表著將權重衰减與梯度更新過程解耦。這種分離是超過Adam的關鍵進步,並有助於更好的模型泛化。
AdamW 在 modern deep learning applications 中重要性愈來愈高,特别是在 handling large-scale models 的部分。其 superior ability to regulate weight updates 使其被采用於需要 high performance 和 stability 的任務中。
在這個教程中,我們將會探讨 Adam 和 AdamW 之間的主要差異以及不同的使用情境,並將提供一個步驟化的指南來在PyTorch中實作 AdamW。
Adam 對比 AdamW
亞當和亞當W都是常用於深度學習中的自適應優化器。它們之間的最大差異在於它們處理權重正則化的方式,這影響了它們在 different scenarios中的效果。
雖然亞當結合了動量和自適應學習率,以提供高效的優化,但它以一種可能會阻碍性能的方式纳入L2正則化。亞當W通過將權重衰减與學習率更新解耦,來解決這個問題,為大型模型提供更有效的方法並改善一般化。權重衰减是一種L2正則化形式,對模型中的大權重進行惩罚。亞當將權重衰减纳入梯度更新過程,而亞當W在梯度更新後單獨應用它
以下是它們之間的其他差異:
亞當和亞當W之間的關鍵差異
雖然兩款優化器都是設計來管理等效动力學和動態調整學習速率,但它们在權重衰減的處理上根本上有差異。
在Adam中,權重衰減是作為梯度更新的一部分間接應用,這可能會无意間修改學習動力學並干擾優化過程。然而,AdamW將權重衰減從梯度步驟中分離出來,確保正则化直接影響參數而不改變 Adaptive 學習機制。
這種設計導致更精確的正則化,幫助模型的泛化能力提升,特别是在涉及大型和複雜數據集的任務中。因此,這兩種優化器通常具有非常不同的應用場景。
Adam 的應用場景
Adam在正則化較不關鍵或當計算效率被視為比泛化能力更重要的任務中表現较好。例如:
- 小型神經網絡。對於使用小型卷積神經網絡(卷積神經網絡)進行基本影像分類等任務,如MNIST或CIFAR-10數據集中的模型複雜度較低,Adam可以有效地進行優化,而無需廣泛的正則化。
- 簡單的回歸問題。對於特點集有限的基本回歸任務,如使用線性回歸模型預測房價,Adam可以快速收敛,而無需複雜的正則化技術。
- 早期原型設計。在模型開發的初期階段,需要快速的實驗,Adam允許在較簡單的結構上快速迭代,讓研究人员能在調整正則化參數的開銷下發現潛在問題。
- 較少噪音的數據。當處理干净的數據集,噪音很少,如為情感分析而精心整理的文本數據,Adam可以有效學習模式,而無需過度擬合風險所必需的較重正則化。
- 短暫的訓練周期。在時間受限的情況下,如為實時應用快速部署模型,Adam的有效優化可以帮助快速達到滿意的結果,即使它們可能並不是為一般化而完全優化。
AdamW的應用案例
AdamW 在出现过擬合問題且模型大小較大的情況下表現出色。例如:
- 大型變壓器。在自然語言處理任務中,例如在廣泛文本 corpora 上微調 GPT 模型,AdamW 有效地管理權重衰減的能力可防止過擬合,確保更好的泛化能力。
- 複雜的電腦視覺模型。對於涉及深度卷積神經網絡(CNNs)在 ImageNet 這樣的大型數據集上訓練的任務,AdamW 通過解耦權重衰減來幫助维持模型穩定性和性能,这对于獲得高精度是至关重要的。
- 多任务學習. 在模型的同時訓練多個任務的情況下,AdamW 提供了靈活性以處理多样的數據集,並防止在任何單個任務上出现过拟合。
- 生成模型. 在訓練生成對抗網絡 (GANs) 時,其中保持生成器和辨別器之間的平衡至關重要,AdamW 的改良的正则化可以幫助穩定訓練並提升生成输出的質量。
- 強化學習. 在強化學習應用中,模型的必須適應複雜的環境並學習堅實的策略,AdamW 有助於減輕對特定狀態或行為的過拟合,提高模型在各種情況下的一般性能。
AdamW 相比 Adam 的優點
那麼,為什麼人們會想要使用 AdamW 而不是 Adam 呢?原因很簡單。AdamW 提供了一些關鍵的優點,這些優點增强了其性能,特別是 在複雜的建模情境下。
它解決了Adam優化器中發現的一些限制,因此使其在優化方面更有效,並有助於改善模型的訓練和堅固性。
以下是一些顯著的优势:
- 解耦權重衰减。通過將權重衰减與梯度更新分開,AdamW允許更精確的控制regularization,從而提高模型的泛化能力。
- 提升泛化能力。AdamW減少過擬合的風險,特別是對於大型模型的任務,使其適合於涉及大量數據和複雜結構的任務。
- 訓練过程中的穩定性. AdamW 的設計有助于在整個訓練過程中保持穩定性,這對於需要仔細調整超參數的模型来说是根本的。
- 可擴展性。AdamW 特別適合擴展模型,因為它能夠處理深層網絡的複雜性增加,而不犧牲性能,使其能夠應用於最先进的架構中。
AdamW 的工作原理
AdamW 的核心強點在於其對於權重衰減的处理方式,這與 Adaм 的自適應梯度更新typical是分離的。這種調整確保 regularization 直接應用於模型的權重,改善泛化而不影響學習率动态。
優化器建立於Adam的適應性,並保持速度和每個參數學習率調整的益處。獨立應用權重衰减解決了Adam的一個主要缺點:在的正则化過程中影響梯度更新。這種分離使AdamW在複雜和大规模模型中保持穩定學習,同時控制過擬合。
在以下的段落中,我們將探讨權重衰减和正則化的理論,以及支撐AdamW優化過程的數學原理。
權重衰减和L2正則化的 theory
L2正則化是一種用於防止過擬合的技術。它通過向損失函數添加罰款項目來實現这一目標,阻止大權重值。這種技術有助於创建更簡單的模型,使其更好地一般化到新數據。
在傳統的優化器,如Adam,中,權重衰減是作為梯度更新的一部分應用,這往往会無意間影響學習速率,導致表現不佳。
AdamW在这一点上進行了改進,將權重衰減與梯度計算分開。換句話說,AdamW不是在梯度更新時應用權重衰減,而是將其視為一個分開的步驟,在梯度更新後直接對權重應用權重衰減。這防止了權重衰減干擾優化過程,從而導致訓練更加穩定且泛化能力更好。
AdamW的數學基礎
AdamW通過更改應用權重衰減的方式來修改傳統的Adam優化器。AdamW的core equations可表示如下:
- 動量與適應性學習率:與Adam相同,AdamW使用動量與適應性學習率,根據梯度與梯度平方的移动平均來計算參數更新。
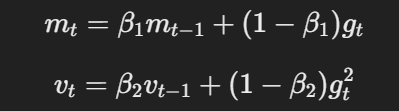
動量與適應性學習率的方程式
- 偏誤校正估計:第一矩與第二矩估計透過以下方式進行偏誤校正:
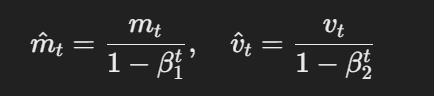
偏誤校正估計的公式
- Parameter update with decoupled weight decay: 在AdamW中,权重衰减是在梯度更新後直接应用于参数的。更新规则是:
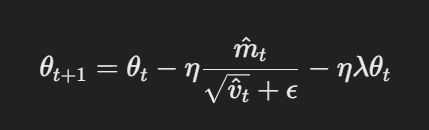
带有解耦权重衰减的参数更新
在此处,η是学习率,λ是权重衰减因子,而θt代表参数。这个解耦权重衰减项λθt确保了正规化独立于梯度更新应用,这是与Adam的主要区别。
在PyTorch中实现AdamW。
在 PyTorch 實現 AdamW 是很直接的;本節將提供一個全面的指導,教導如何設定。照著這些步驟,學習如何有效地对模型進行微調。
在 PyTorch 中實現 AdamW 的步驟指南
注意:本教程假定您已經安裝了PyTorch。請查看文件以取得任何指導。
步驟1:導入必要的庫
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
步驟2:定義模型
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
步驟3:設定超參數
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # 迭代的回合數
步驟4:初始化AdamW優化器並設定損失函數
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
完成!
現在,您已經準備好開始訓練您的CNN模型,我們在下個部分將要做這件事。
實用範例:使用AdamW微調模型
上面,我們定義了模型,設定超參數,初始化優化器(AdamW),並設定損失函數。
為了訓練模型,我們需要再匯入一些模塊;
from torch.utils.data import DataLoader # 提供了數據集的迭代器 import torchvision import torchvision.transforms as transforms
接下來,定義數據集和數據加載器。為這個例子,我們將使用CIFAR-10數據集:
# 定義訓練集中的變換 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # 載入CIFAR-10數據集 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # 創建數據加載器 train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
由於我們已經定義了我們的模型,下一步是實現訓練循環,使用AdamW optimize the model.
這是它的样子:
for epoch in range(num_epochs): model.train() # 將模型設置為訓練模式 running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # 清除梯度 outputs = model(inputs) # 前向傳播 loss = criterion(outputs, labels) # 計算損失 loss.backward() # 反向傳播 optimizer.step() # 更新權重 running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
最後一步是驗證模型在我們早先創建的驗證數據集中的表現。
以下是程式碼:
model.eval() # 將模型切換至評估模式 correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # 正向傳遞 _, predicted = torch.max(outputs.data, 1) # 獲取預測類別 total += labels.size(0) # 更新總樣本數 correct += (predicted == labels).sum().item() # 更新正確預測數 accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
就是这样。
現在你知道如何在PyTorch中實現AdamW。
AdamW的常見應用案例
好,我們已經确认AdamW因為比前身Adam更有效地管理權重衰减而變得受欢迎。
但這個優化器的一些常見應用案例是什麼呢?
我們在這一節會谈到…
大规模深度學習模型
AdamW在訓練像BERT、GPT等大模型以及其他變壓器結構的模型中特別有益。這些模型通常具有数百萬甚至数十億個參數,這通常意味著它們需要有效的優化算法來處理複雜的重量更新和泛化挑戰。
計算機視覺和自然語言處理任務
AdamW已成为 Computervision涉及CNNs和NLP涉及變壓器的任務中的首选優化器。它防止過擬合的能力使其成為涉及大型數據集和複雜結構的任務的理想選擇。權重衰減的解耦意味著AdamW避开了Adam在過度regularizing模型中遇到的問題。
AdamW中的超參數調整
超參數調整是指選擇影響機器學習模型訓練但不是從數據本身學習的參數的最佳值。這些參數直接影響模型如何進行優化和收敛。
在AdamW中適當調整這些超參數對於實現高效的訓練、避免過度擬合並確保模型對於未見過的數據有良好的泛化能力至關重要。
在這一節中,我們將探讨如何細調AdamW的關鍵超參數以達到最佳的性能。
選擇學習率和權重衰减的最佳實踐
學習率是一個超參數,用於控制在每個訓練步驟中模型權重根據損失梯度進行多少調整。較高的學習率會加快訓練,但可能會導致模型過度超出最優權重,而較低的學習率則允許更細致的調整,但可能會使訓練變慢或卡在局部的最小值。
另一方面,權重衰減是一種正规化技術,用於通過懲罰模型中的大權重來防止過擬合。具體來說,權重衰減在訓練過程中添加一個與模型權重大小成比例的小懲罰,幫助減少模型的複雜性並提高对新数据的泛化能力。
為AdamW選擇最佳的學習速率和解脫衰減值:
- 從中等的學習速率開始 – 对于AdamW,一個大约1e-3的學習率通常是一個不錯的開始點。您可以根據模型是否会 convergence 進行調整,如果模型難以 convergence,則降低它;如果訓練速度太慢,則增加它。
- 試探權重衰退. 從約1e-2至1e-4的值開始,這取決於模型大小和數據集。較高的權重衰退值有助於防止大型、複雜模型的過拟合,而較小的模型可能需要較少的正规化。
- 使用學習率計劃。 實現學習率計劃(如步驟衰退或餘弦減衰)以隨著訓練進行动态降低學習率,幫助模型在接近合併時微調其參數。
- 監控表現. 持續地在驗證集上追蹤模型表現。如果你觀察到過拟合,考慮提高權重衰退,或者如果訓練損失穩定,將學習率降低以獲得更好的優化。
結論
AdamW 已成為深度學習中最有效的優化器之一,特別是對於大型模型。這是因為它能夠將權重衰減與梯度更新而解耦。也就是說,AdamW 的設計改善了regularization,幫助模型更好地一般化,特別是當處理複雜結構和大量數據時。
如本教程所展示,者在 PyTorch 中實現 AdamW 是非常直接的—只需要對 Adam 做几点調整。然而,超參數調節仍然是 maximize AdamW 效果的關鍵一步。尋找學習率與權重衰減之間的正確平衡對於確保優化器有效而不過度擬合或拟合不足模型是至关重要的。
現在你已經知道足夠的內容可以在自己的模型中實現 AdamW。要继续你的學習,請查看這些資源:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch