













最適化アルゴリズムは深層学習において重要な役割を果たしています。これらのアルゴリズムは、学習中に損失関数を最小限にするためにモデル的重みを细工します。その一例はAdam最適化器です。
Adamは、動量と適応的学習率の利点を組み合わせることで深層学習で极めて人気を博しました。これにより、深層 neural networkのトレーニングには高効率であることができました。また、超 Parameterの調整が最小限になるため、さまざまな任务において幅広く適用でき、効果的です。
2017年、Ilya LoshchilovとFrank Hutterは、彼らの論文「Decoupled Weight Decay Regularization.」で一般的なAdamアルゴリズムのより進化したバージョンを紹介しました。彼らはそれをAdamWと名付け、重み減衰を勾配更新プロセスから解耦合させることで特に注目を集めました。この分離はAdamを超える重要な改善で、モデルの一般化が改善されます。
AdamWは、特に大規模モデルを処理する modern deep learning applicationsでより重要になっています。重み更新を調整する卓越した能力が、高パフォーマンスと安定性を要求するタスクに採用されています。
このチュートリアルでは、AdamとAdamWの主要な違いや、異なる用途について触れ、PyTorchでAdamWを実装する一歩一歩のガイドを実施します。
Adam vs AdamW
アダムとアダムWはどちらも深層学習で広く使用されている適応的な最適化器である。彼らの大きな違いは、重みの正則化をどのように処理するかであり、これが異なるシーンにおいて効果的かどうかに影響を与える。
アダムは動量と適応的な学習率を組み合わせて効率的な最適化を提供しているが、L2正則化を取り込んだ方法が性能を阻害する。アダムWはこれを解決するために、重み減衰を学習率更新から離れて適用し、大きなモデルにより効果的な方法を提供し、一般化を改善する。重み減衰はL2正則化の一形態で、モデルの大きな重みをペナルティーとする。アダムは重み減衰を勾配更新プロセスに組み込み、而るアダムWは勾配更新後に適用する。
以下は彼らの違いの他の方法です。
アダムとアダムWの关键的な違い
どちらの最適化器も動量管理と学習率の動的調整を行うために設計されましたが、重みの減衰に対する取り扱いは根本的に異なります。
Adamでは、重みの減衰は勾配更新の一部として间接的に適用されます。これは学習の動力学を意図しなくても変更し、最適化プロセスに干渉する可能性があります。しかし、AdamWは勾配ステップから重みの減衰を分離し、正则化がパラメーターに直接影響を与えるだけで、適応的な学習機構を変更しないようにしています。
この設計はより正確な正则化を提供し、特に大きくて複雑なデータセットを含んだタスクでモデルの一般化が改善されます。結果的に、この2つの最適化器はしばしば非常に異なる使用例に対応しています。
Adamの使用例
Adamは、正则化が重要でないタスクや、一般化よりも計算効率を重视する場合により良いパフォーマンスを示します。例えば:
- 小さなニューラルネットワーク。MNISTやCIFAR-10などのデータセットを使用し、小さなCNN(畳み込みニューラルネットワーク)を使用した基本的な画像分類など、モデルの複雑度が低いタスクにおいて、Adamは广範囲の正则化を必要としないで、効果的に最適化を行うことができます。
- 単純な回帰問題。線形回帰モデルを使用して不動産価格の予測など、特徴量が限られた単純な回帰タスクにおいて、Adamは高度な正则化技術を必要としないで、迅速に収束することができます。
- 初期段階のプロトタイプ作成。モデルの開発の初期段階で、迅速な実験が必要である場合、Adamはより単純なアーキテクチャで迅速なイテレーションを許可し、研究者は正則化パラメータの調整の overhead を受けず、潜在的な問題を识别することができます。
- ノイズの少ないデータ。感情分析用のよく整理されたテキストデータなど、ノイズが少ないクリーンなデータセットで工作时に、Adamは過学習の危険性を持たないで、パターンを学習することができます。
- 短期間のトレーニング。時間の制約がある場合、例えば実時間アプリケーションに迅速にモデルをデプロイするなど、Adamの効率的な最適化は、完全に最適化された一般化能力を必要としないにも関わらず、迅速に満足の報酬を提供することができます。
AdamWの使用例
AdamWは、過学習が懸念されるシーンや、モデルサイズが大きい場合に特に有効です。たとえば、
- 大規模トランスフォーマーなどです。自然言語処理の任务で、GPTのようなモデルを大量のテキストコープに細調整するのにおいて、AdamWの重み減衰を効果的に管理する能力が、過学習を防いで一般化能力を向上させます。
- 複雑なコンピュータビジョンモデル。深層コンビューションニューラルネットワーク(CNN)をImageNetのような大規模データセットでトレーニングするタスクにおいて、AdamWは重み減衰を解耦して、高精度を達成するために非常に重要なモデルの安定性と性能を維持するのを助けます。
- マルチタスク学習. モデルが同時に複数のタスクに訓練される場合、AdamWは多样なデータセットを処理する柔軟性を提供し、单一のタスクに対する過学習を防止します。
- 生成モデル. 生成対抗网络(GAN)の訓練において、生成器と識別器の間のバランスを保ち続けることが重要であるため、AdamWの改善された正则化は、訓練を安定化し、生成された出力の品質を向上させることができます。
- 強制学習. 強制学習のアプリケーションでは、モデルは複雑な環境に適応し、強固なポリシーを学ぶ必要があります。AdamWは特定の状態や行動に過学習することを軽減し、様々な状況でモデルの一般性能を向上させます。
AdamWとAdamの比較
しかし、なぜAdamWをAdamより使用する必要があるのか?簡単に言うと、AdamWは、複雑なモデリングシーンに特化した改善された性能を提供します。
アダム最適化器において見つかった限りその一部の制約を解決し、最適化により効果的になり、モデルのトレーニングと強固性の向上に貢献する。
以下は、その特徴的な利点のいくつか:
- 重み衰減を解耦した。重み衰減を勾配更新から分離することで、AdamWは正則化をより正確に控制在し、モデルの一般化を向上させます。
- 一般化を向上させた。AdamWは、特に大規模モデルにおいて過学習のリスクを低減し、広範囲のデータセットと複雑な構造を持つタスクに適しています。
- 学習中の安定性AdamWの設計は、学習過程全体にわたって安定性を维持することができるため、超参数の慎重な調整を必要とするモデルにとって重要です。
- スケール可能性。AdamWは、深层神经网络の複雑さを増やすことで性能を損なわないように処理でき、最も最先端のアーキテクチャに適用できるように特別に効果的です。
AdamWの仕組み
AdamWの本質的な強さは、ウェイトデクレーションに対する取り組みにあり、Adamのような適応的な勾配更新によるウェイトデクレーションを離れています。この調整は、モデルのウェイトに直接 Regularizationを適用することで、学習率の動きに影響を与えず一般化能力を向上させます。
最適化器はAdamの適応性に基づいており、動量と各パラメーターごとの学習率調整の利点を保持します。重み衰减を独立して適用することで、Adamの主な欠点の1つになるregularizationの際にgradient更新に影響を与える傾向を解決します。この分離により、AdamWは、重み衰减を制御しながら、複雑で大規模なモデルでも安定した学習を维持することができます。
以下の節で、重み衰减とregularizationの背後の理論と、AdamWの最適化プロセスを支える数学を探ることにします。
重み衰减とL2 Regularizationの背后的理論
L2 regularizationは、過剰学習を防ぐ技術です。これは、損失関数にペナルティ项を追加し、大きな重み値を避けるよう促して、新しいデータにより良く一般化するシンプルなモデルを作成することで実現します。
伝統的な最適化器は、Adamなど、重みの減衰を勾配更新の一部として適用しており、これは学習率に影響を与えながら、最適な性能を得ることができない場合があります。
AdamWは、重みの減衰を勾配計算から解耦することでこの問題を改善します。つまり、勾配更新の間に重みの減衰を適用する代わりに、AdamWは勾配更新の後、重みに直接適用する別のステップとして处理します。これにより、重みの減衰が最適化プロセスに干渉しないようにし、より安定した学習とより良い一般化を実現します。
AdamWの数学的基礎
AdamWは、重みの減衰がどのように適用されるかを変更することで、伝統的なAdam最適化器を修正します。AdamWの核心方程式は以下のように表記できます。
- モーメントumと適応的学習率:AdamWは、Adamと同様に、勾配と勾配の2乗の動的平均を基に、パラメータ更新を計算するために、モーメントumと適応的な学習率を使用します。
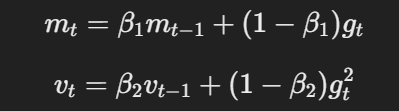
モーメントumと適応的学習率的方程式
- 偏置修正估计:初項と二項のモーメント估计を、以下のように偏置修正する:
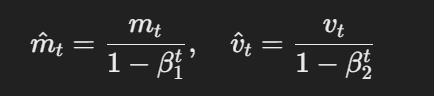
偏置修正估计の公式
- 解耦された重み衰减でのパラメータ更新:AdamWでは、重み衰减は勾配更新の後、パラメータに直接適用されます。更新ルールは以下の通りです。
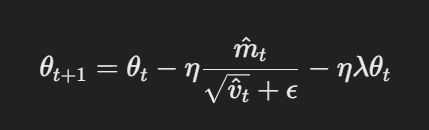
解耦された重み衰减でのパラメータ更新
ここで、ηは学習率、λは重み衰减因子、θtはパラメータを表します。この解耦された重み衰減項λθtは、勾配更新とは独立して正则化を適用することを保証しています。これはAdamとの主要な違いです。
PyTorchでAdamWの実装
AdamWをPyTorchに実装することは簡単です。この節では、設定方法を詳細に説明します。Adamオプティマイザーを使用してモデルを効果的にファインチューンする方法を学ぶために、以下の手順に従ってください。
PyTorchでAdamWを使うためのステップバイステップのガイド
注意:このチュートリアルは、PyTorchが既にインストールされていることを前提としています。ドキュメントを参照していただけます。
ステップ1:必要なライブラリをインポートします
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
手順2:モデルの定義
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
手順3:超参数の設定
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # エポック数
手順4:AdamWOptimizerを初期化し、損失関数を設定する
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
ヴォーラ!
今、CNNモデルのトレーニングを始める準備ができました。次の sectioinで行います。
実践的な例:AdamWを使用したモデルの细かい調整
上で、モデルを定義し、ハイパーパラメーターを設定し、最適化器(AdamW)を初期化し、損失関数を設定しました。
モデルのトレーニングには、いくつかのモジュールをインポートする必要があります。
from torch.utils.data import DataLoader # データセットをイテレーブルに提供します import torchvision import torchvision.transforms as transforms
次に、データセットとデータローダーを定義します。この例では、CIFAR-10 データセットを使用します。
# 学習 dataset の変換を定義します transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # CIFAR-10 データセットを読み込みます train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # データローダーを作成します train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
既に模型を定義したため、次のステップはAdamWを使用して模型を最適化するトレーニングループの実装です。
以下はそのようになります:
for epoch in range(num_epochs): model.train() # 模型を学習モードに設定します running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # 勾配をクリアします outputs = model(inputs) # 前向きパス loss = criterion(outputs, labels) # 損失を計算します loss.backward() # 後向きパス optimizer.step() # 重みを更新します running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
最後のステップは、先程作成したvalidation datasetでモデルのパフォーマンスを検証することです。
コードは以下の通りです。
model.eval() # モデルを評価モードに設定する correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # 順伝播を行う _, predicted = torch.max(outputs.data, 1) # 予測されたクラスを取得する total += labels.size(0) # 合計サンプル数を更新する correct += (predicted == labels).sum().item() # 正解予測数を更新する accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
これで完了です。
今度は、PyTorchでAdamWを実装する方法を学んだでしょう。
AdamWの一般的な使用例
AdamWは、重み缩小白化の管理が前のAdamを上回るために人気を博しました。
では、この最適化器の一般的な使用例は何でしょうか。
この節ではその内容について述べます…
大規模な深層学习モデル
AdamWはBERT、GPTなどの大きなモデルやトランスフォーマーアーキテクチャのトレーニングに特に効果的です。これらのモデルは通常、数百万または数亿のパラメータを持っており、これは复杂な重み更新と一般化の課題を処理する効率的な最適化アルゴリズムを必要とします。
コンピュータビジョンとNLPの課題
AdamWは、CNNを使用したコンピュータビジョンの課題と、トランスフォーマーを使用したNLPの課題において、最適化器として選ばれています。大規模なデータセットと複雑なアーキテクチャを持つ課題において、過学習を防止する能力があります。重み減衰の解耦は、Adamで遇えるモデルを過度に正則化する問題をAdamWが避けます。
AdamWの超参数調整
超 Parameter 調整は、機械学習モデルの学習に影響を与えながら、その学習に直接影響を与えるパラメーターの最適な値を選ぶプロセスです。これらのパラメーターは、データから学習されることはないため、それぞれにより重要です。これらのパラメーターは、モデルが最適化し、収束する方法を直接影響します。
AdamWでこれらの超 Parameter の適切な調整は、効率的な学習を実現し、過学習を避け、模型的な一般化が見られないデータに适応するようにするために非常に重要です。
この節では、AdamWの主要な超 Parameter を最適なパフォーマンスに微調整する方法を探索します。
学習率と重み减少の選択におけるベストプractices
学習率は、学習における各ステップで損失勾配に基づいてモデルの重みをいくつかの程度调整する際の調整量を制御する超 Parameter です。学習率が高いと学習を速めますが、最適な重みを超えてしまう可能性があります。学習率が低いとより細かい調整が可能ですが、学習が遅くなりやすく、局所的最小値にとって留まる可能性があります。
重み減少は、モデルの重みが大きすぎることをペナルティーとして処罰して、過学習を防ぐために使用される正则化技術です。つまり、重み減少は、学習時にモデルの重みの大きさに比例した小さなペナルティーを加えることで、モデルの复杂性を減少させ、新しいデータに対する一般化を改善します。
AdamWの最適な学習率と重み減少の値を選ぶには:
- 適切な学習率で始める – AdamWの場合、1e-3の学習率は往往にして良い出发点となります。モデルが収束するのがどのくらい良いかに基づいて調整してください。モデルが収束しにくいた場合には下げ、学習があまりに遅いた場合には上げてください。
- 重み衰减を試験する. モデルサイズとデータセットに応じて約1e-2から1e-4の値から始めます。少し高い重み衰减が大きく複雑なモデルにおいて過学習を防ぐことができますが、小さなモデルはより少ないregularizationが必要かもしれません。
- 学習率スケジューリングを使用してください。学習率スケジューリング(ステップ衰減や余弦衰減など)を実装して、トレーニングの進行に伴って学習率を動的に減少させることで、モデルが収束するに近づくにつれてパラメータを細微に調整するのを助けます。
- パフォーマンスを監視してください。validation set上でモデルのパフォーマンスを持続的に追跡してください。過学習を観察した場合、重み衰减を増やしてみてください。また、トレーニング損失が平原化した場合、学習率を下げて最適化を改善するかもしれません。
最終的な考え方
AdamWは、特に大規模モデルにおいて、最も効果的な最適化器として出現しています。これは、重み減少を勾配更新から解耦合する能力によります。つまり、AdamWの設計は、正则化を改善し、モデルがより良く一般化することを助け、特に複雑なアーキテクチャーや広範囲のデータセットに取り組む時には有効です。
このチュートリアルで示されるように、PyTorchでAdamWを実装することは簡単で、Adamから少しの調整が必要です。しかし、学習率と重み減少の間の適切なバランスを見つけることは、Optimizerがモデルに过剰に結合したり、結合し不足したりしない限り、効果的に動くようにするために非常に重要です。
今では、自分のモデルにAdamWを実装するための十分な知識があるでしょう。学習を続けるために、以下のリソースをご確認ください。
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch