













Optimization algorithms は深層学習において非常に重要な役割を果たしています:学習中に損失関数を最小化するためにモデルの重みを調整します。そのような算法の1つは、Adam オプティマイザーです。
Adamは、動量と適応的な学習率の利点を組み合わせることで深層学習で极めて人気があり、深いニューラルネットワークのトレーニングには非常に効果的でした。また、超参数の調整が最小限になるため、さまざまな作業において幅広く適用でき、効果的です。
2017 년 Ilya Loshchilov과 Frank Hutter는 그들의 论文 “Decoupled Weight Decay Regularization.”에서 인기 있는 Adam 알고리즘의 더 进歩된 버전을 introduce했습니다. 그들은 그것을 AdamW로 named했는데, 权重衰减(weight decay)을 gradient update process와 분리하는 것을 指名できます. 이 분리는 Adam보다 주요한 改善点이며, 모델 일반화를 더 나게 도울 수 있습니다.
AdamW는 现代化 深層学习 응용에서 점점 중요성을 가지고 있다, 특히 대规模 모델을 처리할 때. 가중치 갱신을 조절하는 우수한 능력은 高性能과 안정性이 필요한 任务에 적용되기 促成了.
이 튜토리얼에서는 Adam과 AdamW의 주요 차이점과 다양한 사용 사례를 구하고, 단계별 가이드를 통해 AdamW를 PyTorch에서 구현하는 방법을 배울 것입니다.
Adam과 AdamW의 차이점
아담(Adam)과 아담W(AdamW)는 both 深的 learning에 널리 사용되는 적응型 최적화기입니다. 그들之间的 큰 차이는 가중치 정규화를 어떻게 처리하는지에 따라 다양한 상황에서 그 효율성을 어느 정도 영향을 줄 수 있습니다.
Adam은 모멘텀과 적응형 leaning rate를 결합하여 효율적인 최적화를 제공하며, L2 정규화를 그렇게 처리하여 パフォーマン스를 저하시킬 수 있습니다. AdamW는 이러한 것을 해결하기 위해 가중치 하락(weight decay)을 leaning rate 갱신과 분리하여 大型 model에서 더 효과적인 접근法을 제공하고 일반화를 향상시킵니다. 가중치 하락(weight decay), L2 정규화의 형태로, 모델의 대형 가중치를 罚す는 것입니다. Adam은 가중치 하락을 그리고 gradient update 과정에 결합하며, AdamW는 gradient update 이후에 따로 적용합니다.
그들之间의 다른 차이는 다음과 같습니다.
Adam과 AdamW의 주요 차이점 between Adam and AdamW.
両方の最適化器は動量を管理し、学習率を動的に調整するために設計されましたが、重み減衰に対する取り扱いに根本的な違いがあります。
Adamでは、重み減衰は勾配更新の一部として間接的に適用されます。これは学習の動力学を意図せぬもので変更し、最適化プロセスに干渉する可能性があります。しかし、AdamWは、重み減衰を勾配ステップから分離して、正规化がパラメーターを変更しないように、适应的な学習機構を変更せずに直接影響を与えます。
この設計はより正確な正规化を导く结果として、大きく、複雑なデータセットを含むタスクにおいて、モデルがより良く一般化することを助けます。その結果、この二つの最適化器はしばしば非常に異なる用途のために使用されます。
Adamの用途
Adamは、正规化が重要でないタスクや、一般化よりも計算効率を優先する場合により良く機能します。これらは以下のように示されます。
- маленькие нейронные сети . Для задач типа базовой категоризации изображений с использованием небольших CNN ( Конвенциональные нейронные сети ) на наборах данных, таких как MNIST или CIFAR-10, где сложность модели низкая, Adam может эффективно оптимизироваться без необходимости широкого регулярирования.
- простые регрессионные проблемы . В простых регрессионных задачах с ограниченными наборами特征, например, предсказание цен на домах с использованием линейной регрессии, Adam может быстро сходиться без необходимости использования передовых техник регулярирования.
- раннее прототипирование . Во время ранних стадий разработки моделей, где требуется быстрое экспериментирование, Adam позволяет быстрые итерации с более простыми архитектурами, позволяя исследователям идентифицировать потенциальные проблемы без накладных расходов на настройку параметров регулярирования.
- менее шумные данные . При работе с чистыми наборами данных с минимальным шумом, таких как хорошо подготовленные текстовые данные для анализа настроения, Adam может эффективно обучаться на моделях без риска переобучения, которое может требовать более тяжелого регулярирования.
- короткие циклы обучения . В сценариях с ограничением времени, таких как быстрое развертывание моделей для реального временных приложений, эффективная оптимизация Adam может помочь быстро достичь удовлетворительных результатов, хотя они могут не быть полностью оптимизированы для generalization.
use cases for AdamW
AdamW는 과적합이 주목되는 scenarios에서 특이적으로 우수하며, 모델 크기가 substancial일 때 유용합니다. 예를 들어:
- 대規模 transformers을 调節하는 것입니다. 자연어 처리 任务, 如火 GPT를 精调하는 것과 같은 대규모 텍스트 コープ에 대한 경험에서 AdamW가 가중치 감소를 有效地 관리할 수 있는 것이 과적합을 방지하고 일반화를 보장하는 것입니다.
- 複雑한 计算机视觉 모델들을 训练하는 것입니다. ImageNet과 같은 대 dataset에 대한 深い 卷积神经网络(CNN) 训练 任务에서, AdamW는 가중치 감소를 解耦하여 모델 안정性和 性能를 유지하는 것이 고 정확도 달성에 중요합니다.
- 다중 작업 학습. 모델이 여러 작업을 동시에 학습하는 시나리오에서 AdamW는 다양한 데이터셋을 처리하고 단일 작업에 과적합되는 것을 방지하는 유연성을 제공합니다.
- 생성 모델. 생성적 적대 신경망(GANs)을 학습시키는 경우, 생성기와 판별기 간의 균형을 유지하는 것이 중요한데, AdamW의 개선된 정규화는 학습을 안정화시키고 생성된 출력의 품질을 향상시키는 데 도움이 될 수 있습니다.
- 강화 학습. 강화 학습 응용 프로그램에서 모델이 복잡한 환경에 적응하고 강력한 정책을 학습해야 하는 경우, AdamW는 특정 상태나 행동에 과적합되는 것을 완화하여 모델의 다양한 상황에서의 일반 성능을 향상시킵니다.
AdamW의 Adam에 대한 장점
하지만 왜 사람들이 AdamW를 Adam 대신 사용하려고 할까요? 간단합니다. AdamW는 특히 복잡한 모델링 시나리오에서 성능을 향상시키는 여러 주요 혜택을 제공합니다.
Adam 최적화기의 一些한 제한 사항을 해결하여, Optimization이 더 효과적으로 行われ, 모델 트레이닝 및 유지 강도를 改善시키는 것에 기여합니다.
下の 一些한 장점을 갖추고 있습니다:
- 가중치 严谨 decay를 분리합니다.Weight decay를 Gradient updates에서 분리하여, AdamW는 정규화를 더 精密度 control할 수 있게 해줍니다. 이에 따라 모델 일반화를 改善시킵니다.
- 강화된 일반화. AdamW는 특히 대규모 모델에서 overfitting 危険性을 감소시키며, 幅広い dataset과 错綜複雑한 architecture를 갖추는 任务에 적용되는 것입니다.
- 기술 训练 过程中的稳定性. AdamW的设计有助于在整个训练过程中保持稳定性,这对于需要仔细调整超参数的模型来说至关重要。
- 可扩展性。AdamW特别适用于扩展模型,因为它能够处理深度网络增加的复杂性而不牺牲性能,使其能够应用于最先进的架构中。
AdamW如何工作
AdamW的核心优势在于其对权重衰减的处理方式,这种方式与Adam典型的自适应梯度更新解耦。这种调整确保正则化直接应用于模型的权重,提高泛化能力而不影响学习率动态。
Optimizer는 Adam의 적응性에 기반하여 이동矢量(momentum)과 각 パラ미터ごとの学習率 조절 이점을 유지하며 가중치 감소(weight decay)를 독립적으로 적용하여 Adam의 주요 결함 중 하나인, 정규화 과정에서 梯度 갱신(gradient updates)에 영향을 미치는 경향을 해결합니다. 이러한 분리는 AdamW가 복잡하고 대형 모델에서도 안정적인 학습을 유지하며 过拟合(overfitting)을 통제할 수 있게 해줍니다.
以下の節で、가중치 감소와 정규화의 이론과 AdamW의 Optimization Process를 支え는 数学이론에 대해 探ります.
가중치 감소와 L2 정규화 背后的이론
L2 정규화는 过拟合을 방지하기 위한 기술입니다. 이를 실현하는 것은 损失函數에 penalty term을 추가하여 큰 가중치 값을 낮추는 것です. 이 기술은 더 간단한 모델을 생성하여 새로운 데이터에 대해 일반화하기 更容易하게 도와줍니다.
전통적인 오timizer, 예를 들어 Adam, 가중치 감소(weight decay)를 그레이디언트 갱신의 일부로 적용하는 것에 의해, 학습률(learning rate)에 영향을 미칠 수 있고, 최적의 パフォーマンス를 이룰 수 있는 문제를 발생시킨다.
AdamW는 이를 개선하기 위해 가중치 감소를 그레이디언트 计算机의 일부로서 분리하고자 한다. 换句话说, 그레이디언트 갱신 시간에 가중치 감소를 적용하는 것이 아닌, AdamW는 그레이디언트 갱신 이후에 직접 가중치에 적용する 것이다. 이렇게 가중치 감소가 오timization 과정에 영향을 미치는 것을 防止하여, 더 안정적인 트레이닝과 更好的 일반화를 얻을 수 있다.
AdamW의 수학적 기반
AdamW는 가중치 감소를 어떻게 적용하는지 바꾸어 전통적인 Adam 오timizer를 수정한다. AdamW의 주요 公式은 다음과 같이 나타낼 수 있다:
- 모멘텀 및 적응型 leaning rate :Adam과 유사하게 AdamW는 모멘텀과 적응型 leaning rate를 사용하여, 梯度의 이동 평균과 제곱 梯度에 기반하여 パラメ터 갱신을 computes 합니다.
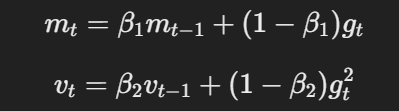
모멘텀 및 적응型 leaning rate의 公式
- 편향 校正 Estimates:첫 번째 및 두 번째 모멘텀 推定은 다음과 같이 편향을 校正합니다:
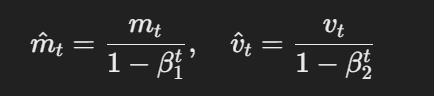
편향 校正 Estimates의 公式
- 分工独立的权衡衰减的参数更新: AdamW에서는 경사 갱신 후에 직접 パラ미터에 权衡衰减을 적용합니다. 갱신 규칙은 다음과 같습니다:
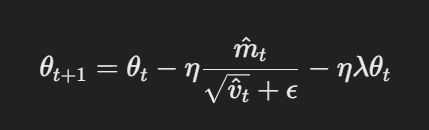
分工独立的权衡衰减的参数更新
여기에서 η(eta)는 학습률(learning rate), λ(lambda)는 权衡衰减 요소(weight decay factor), θt는 パラ미터(parameters)를 나타냅니다. 分工独立的权衡衰减 요소 λθt는 경사 갱신과 독립적으로 적용되는 정규화를 보장하는 것이며, Adam과의 주요 차이점입니다.
PyTorch内에서 AdamW의 구현
PyTorchAdamW을 적용하는 것은 간단하며, 이 섹션은 모델을 세팅하는 전반적인 가이드를 제공합니다. Adam 최적화기를 사용하여 모델을 精Detail-tuning하는 방법을 배울 수 있습니다.
PyTorch에서 AdamW를 사용하는 단계에 따른 가이드입니다.
注釈: 이 튜토리얼은 PyTorch이 이미 설치되었다고 가정합니다. 도움이 필요하면 文档 을 참조하십시오.
과정 1: 필요한 라이브러리를 導入합니다
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
스텝 2:모델 정의
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
스텝 3:하이퍼파라미터 설정
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # 에poch의 개수
스텝 4:AdamW 오timizer를 초기화하고 손실 함수를 설정
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
voila!
이제 CNN 모델 训练을 시작할 준비가 되었습니다. 다음 섹션에서는 이를 실제로 行います.
실제 예제: AdamW를 사용하여 모델 精炼
위에서 모델을 정의하고, 하이퍼パaramter를 설정하고, 최적화기 (AdamW)를 초기화하고, 손실 함수를 설정하였습니다.
모델 训练을 위해서는 몇 가지 추가적인 모듈을 導入해야 합니다;
from torch.utils.data import DataLoader # 데이터셋의 이터레이블을 제공합니다. import torchvision import torchvision.transforms as transforms
次에, 데이터셋과 데이터 로더를 정의합니다. 이 예에서는 CIFAR-10 데이터셋을 사용하겠습니다:
# 트레이닝 세트용 변형 정의 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # CIFAR-10 데이터셋 로드 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # 데이터 로더 생성 train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
이제 모델을 미리 정의했으므로, 다음 단계는 AdamW를 사용하여 모델을 최적화하는 트레이닝 루프 구현입니다.
이것이 어떻게 보입니까?
for epoch in range(num_epochs): model.train() # 모델을 트레이닝 모드로 설정 running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # 미분값을 초기화 outputs = model(inputs) # 전파 수행 loss = criterion(outputs, labels) # 손실 계산 loss.backward() # 역전파 수행 optimizer.step() # 가중치를 갱신 running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
마지막으로, 이전에 생성한 交叉 validation 세트에 대한 모델 パフォーマン스 Validatin입니다.
コードは以下の通りです。
model.eval() # モデルを評価モードに設定する correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # 前向きパス _, predicted = torch.max(outputs.data, 1) # 予測されたクラスを取得する total += labels.size(0) # 总分の更新 correct += (predicted == labels).sum().item() # 正解予測の更新 accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
これで完了です。
今ではAdamWをPyTorchで実装する方法がわかりました。
AdamWの一般的な使用例
ですから、Adamの前のものよりもより効果的な重み decay 管理を行うことでAdamWが人気を博しました。
では、この最適化器の一般的な使用例は何でしょうか。
이 섹션에서 그 내용을 다룰 것입니다.
대규모 깊은 러닝 모델
AdamW는 BERT, GPT 등의 대형 모델 및 전이 architechture의 훈련에 특히 유용합니다. 이러한 모델은 수백만 乃至于 수 억 개의 パラ미터를 가지고 있습니다. 이 often means that they require efficient optimization algorithms that handle complex weight updates and generalization challenges.
计算机视觉和自然语言处理任务
AdamW 已经成为计算机视觉任务(涉及卷积神经网络 (CNNs))和自然语言处理任务(涉及转换器)的首选优化器。 它防止过拟合的能力使其成为涉及大型数据集和复杂体系结构的任务的理想选择。 权重衰减的解耦意味着AdamW避免了过度正则化模型时Adam遇到的问题。
AdamW中的超参数调整
超参数调整은 머신러닝 모델의 训练에 영향을 미치는 하이퍼Paramter를 자신만에 학습하지 않는 것에 대한 가장 좋은 값을 선택하는 과정입니다. 이러한 하이퍼Paramter는 모델이 어떻게 옮기고 결합하는지에 직접 영향을 미칠 수 있습니다.
AdamW에서 이러한 하이퍼Paramter의 적절한 조절은 효율적인 训练, 過拟合을 避け以及 모델이 봤지 않은 데이터에 대해 적용하기 좋은 일반화를 보장하는 데 중요합니다.
이 sectoin에서는 AdamW의 주요 하이퍼Paramter를 가장 좋은 성능을 얻기 위해 精 tuning하는 方法을 탐구할 것입니다.
leaning rate와 weight decay 선택 最佳实践
learning rate는 하이퍼Paramter로 모델 가중치를 어떻게 손실 그라디언트에 따라 Each training step 동안 조정할지 결정합니다. 높은 learning rate는 训练을 빨라捷하게 하지만 모델이 적절한 가중치를 과시하는 것을 促す 수 있으며, 낮은 率은 더 精 조절이 가능하지만 训练을 느리게 하거나 지역 minima에 갓을 수 있습니다.
另一方面, 가중치 감소(Weight Decay)은 모델의 과적합을 预防하기 위해 큰 가중치에 punishing하는 정규화 기술입니다. 즉, 가중치 감소는 훈련 도중 모델 가중치의 크기에 따라 小火力의 惩罚을 추가하여, 모델 복잡도를 줄이고 새로운 데이터에 대한 일반화를 改善시키ます.
AdamW에 대한 적절한 leaning rate와 가중치 감소 값을 선택하는 것:
- moderate learning rate로 시작하십시오 – AdamW에서는 1e-3 左右的 leaning rate가 일반적으로 좋은 시작 지점입니다. 모델이 결합하는 것의 좋고 나쁜 것에 따라 조절할 수 있습니다. 모델이 결합하기에 어려움이 있으면 낮추고, 훈련이 너무 느리면 높이는 것입니다.
- вессая спираль. Начните с значения около 1e-2 до 1e-4, в зависимости от размера модели и набора данных. немного большая спираль может помочь предотвратить переобучение для более крупных, сложных моделей, в то время как более малые модели могут требуть меньше регламентации.
- Использование расписания скорости обучения. ИмPLEMENT learning rate schedules ( как ступенчатое снижение или истечение cosine) для динамического уменьшения скорости обучения по мере прогресса тренировки, помогая модели тонко настроить свои параметры, когда она приближается к конвергенции.
- наблюдать за показателями. постоянно отслеживать показатели модели на наборе данных для проверки. Если вы наблюдаете переобучение, рассмотрите возможность увеличения веса спирали, или если потерю значимости тренировочных потерь, снизите скорость обучения для лучшей оптимизации.
Итоговые мысли
AdamW는 特别是在대规模 모델에서 가장 유효한 최적화기가 되었습니다. 이는 其为가중치 앵글(weight decay)과 기울기 갱신(gradient update)을 분리할 수 있는 능력을 가지고 있기 때문입니다. 言하면, AdamW의 설계는 정규화를 改善하고 모델이 더 나은 일반화를 하는 데 도울 수 있습니다, 특히 複雑한 아키텍처와 광범위한 dataset을 다루는 때입니다.
이 튜토리얼에서 보여주는 것처럼, PyTorch에서 AdamW를 구현하는 것은 간단하며 Adam에서 몇 가지 조정이 필요합니다. 그러나, 하이퍼파라미터 조정은 AdamW의 효과를 가장 나ingly 할 수 있는 중요한 단계입니다. 학습률과 가중치 앵글 사이의 正确的한 balanc을 찾는 것은 개선자가 덜 적용되는 것과 모델에 적용되는 것을 ensure하는 것이 중요합니다.
이제 AdamW를 자신의 모델에 구현하는 것을 알고 있으며, 더 나은 leaning를 하기 위해서는 다음과 같은 자원을 확인하십시오:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch