













Los algoritmos de optimización tienen un papel crucial en la aprendizaje profundo: ajustan los pesos del modelo para minimizar las funciones de pérdida durante el entrenamiento. Uno de estos algoritmos es eloptimizador Adam.
Adam se hizo extremadamente popular en la aprendizaje profundo debido a su capacidad para combinar las ventajas de la momento y las tasas de aprendizaje adaptativas. Esto lo hizo altamente eficiente para el entrenamiento de redes neuronales profundas. También requiere un ajuste mínimo de parámetros hiperópticos, lo que lo hace ampliamente accesible y efectivo en diferentes tareas.
En 2017, Ilya Loshchilov y Frank Hutter presentaron una versión más avanzada del popular algoritmo Adam en su documento “Decoupled Weight Decay Regularization.” Ellos la llamaron AdamW, que se destaca por desacoplar la decaimiento de pesos de la actualización de gradiente. Esta separación representa una mejora crucial respecto a Adam y ayuda a mejorar la generalización del modelo.
AdamW ha adquirido importancia creciente en aplicaciones modernas de aprendizaje profundo, particularmente en la manejo de modelos a gran escala. Su capacidad superior para regular actualizaciones de peso ha contribuido a su adopción en tareas que exigen alta performance y estabilidad.
En este tutorial, vamos a tocar las diferencias clave entre Adam y AdamW, y los diferentes casos de uso, y vamos a implementar un guía paso a paso para implementar AdamW enPyTorch.
Adam vs AdamW
Adam y AdamW son ambos optimizadores adaptativos ampliamente utilizados en aprendizaje profundo. La gran diferencia entre ellos es cómo manejan la regularización de pesos, lo que impacta su eficacia en diferentes escenarios.
Mientras que Adam combina momento y tasas de aprendizaje adaptativas para ofrecer una optimización eficiente, incluye la regularización L2 de una manera que puede obstaculizar el rendimiento. AdamW resuelve esto desenlazando la decaimiento de pesos de la actualización de la tasa de aprendizaje, proporcionando un enfoque más eficaz para modelos grandes y mejorando la generalización. El decaimiento de pesos, una forma de regularización L2, penaliza los pesos grandes en el modelo. Adam Incorpora el decaimiento de pesos en el proceso de actualización de gradiente, mientras que AdamW lo aplica por separado después de la actualización de gradiente
Aquí están algunas otras maneras en que difieren:
Diferencias clave entre Adam y AdamW
Aunque ambos optimizadores están diseñados para manejar el momento y ajustar las tasas de aprendizaje de manera dinámica, difieren fundamentalmente en su tratamiento de la decaimiento de pesos.
En Adam, el decaimiento de pesos se aplica indirectamente como parte del actualización de gradiente, lo que puede modificar accidentalmente las dinámicas de aprendizaje y interferir con el proceso de optimización. Sin embargo, AdamW separa el decaimiento de pesos de la etapa de gradiente, garantizando que la regularización impacte directamente los parámetros sin alterar el mecanismo adaptativo de aprendizaje.
Este diseño conduce a una regularización más precisa, ayudando a los modelos a generalizar mejor, particularmente en tareas que implican grandes y complejos conjuntos de datos. Como resultado, los dos optimizadores a menudo tienen casos de uso muy diferentes.
Casos de uso para Adam
Adam ofrece mejores resultados en tareas donde la regularización es menos crucial o cuando se prioriza la eficiencia computacional sobre la generalización. Ejemplos incluyen:
- Redes neuronales pequeñas. Para tareas como la clasificación básica de imágenes utilizando pequeñas CNNs (Redes Neuronales Convolucionales) en conjuntos de datos como MNIST o CIFAR-10, donde la complejidad del modelo es baja, Adam puede optimizar de manera eficiente sin necesidad de regularización extensa.
- Problemas de regresión simple. En tareas de regresión sencillas con conjuntos de características limitados, como predecir los precios de las casas utilizando un modelo de regresión lineal, Adam puede converger rápidamente sin necesidad de técnicas de regularización avanzadas.
- Prototipado en estadias iniciales. Durante las etapas iniciales del desarrollo del modelo, donde se necesita experimentación rápida, Adam permite iteraciones rápidas sobre arquitecturas más simples, lo que permite a los investigadores identificar problemas sin el overhead de ajustar parámetros de regularización.
- Datos menos ruidosos. Cuando se trabaje con conjuntos de datos limpios con mínimo ruido, como datos de texto bien curados para análisis de sentimiento, Adam puede aprender patrones efectivamente sin el riesgo de sobreajuste que podría requerir una regularización más pesada.
- Ciclos de entrenamiento cortos. En escenarios con limitaciones de tiempo, como el despliegue rápido de modelos para aplicaciones en tiempo real, la optimización eficiente de Adam puede ayudar a entregar resultados satisfactorios rápidamente, incluso si no están totalmente optimizados para la generalización.
Casos de uso para AdamW
AdamW destaca en escenarios donde se preocupa por el sobreajuste y el tamaño del modelo es sustancial. Por ejemplo:
- Transformadores a gran escala. En tareas de procesamiento de lenguaje natural, como la finetuning de modelos como GPT en corpora de texto extensivos, la habilidad de AdamW para manejar la decaimiento de pesos efectivamente previenen el sobreajuste, garantizando una mejor generalización.
- Modelos de computación de visiones complejos. Para tareas que implican redes neuronales convolucionales (CNNs) profundas entrenadas en bases de datos grandes como ImageNet, AdamW ayuda a mantener la estabilidad y el rendimiento del modelo desacoplando el decaimiento de pesos, lo cual es crucial para alcanzar una alta precisión.
- Aprendizaje multitarea. En escenarios donde un modelo se entrena simultáneamente en varias tareas, AdamW ofrece flexibilidad para manejar diferentes conjuntos de datos y prevenir el sobreajuste en cualquier tarea individual.
- Modelos generativos. Para el entrenamiento de redes adversarias generativas (GANs), donde mantener un equilibrio entre el generador y el discriminador es crítico, la regularización mejorada de AdamW puede ayudar a estabilizar el entrenamiento y mejorar la calidad de las salidas generadas.
- Aprendizaje por reforzamiento. En aplicaciones de aprendizaje por reforzamiento donde los modelos deben adaptarse a entornos complejos y aprender políticas robustas, AdamW ayuda a mitigar el sobreajuste a estados o acciones específicos, mejorando el rendimiento general del modelo en situaciones variables.
Ventajas de AdamW sobre Adam
¿Pero por qué habría de alguien usar AdamW en lugar de Adam? Es simple. AdamW ofrece varios beneficios clave que mejoran su rendimiento, particularmente en escenarios de modelado complejos.
Se adresa a algunas limitaciones encontradas en el optimizador Adam, haciéndolo así más efectivo en la optimización y contribuyendo a mejores resultados en el entrenamiento del modelo y su robustez.
Aquí van algunas de las ventajas destacadas:
- Decuplado del decaimiento de pesos.Al separar el decaimiento de los pesos de las actualizaciones de gradientes, AdamW permite un control más preciso sobre la regularización, lo que resulta en una mejor generalización del modelo.
- Mejor generalización. AdamW reduce el riesgo de sobreajuste, especialmente en modelos a gran escala, lo que lo hace adecuado para tareas que incluyen datos extensivos y arquitecturas complejas.
- Estabilidad durante el entrenamiento. El diseño de AdamW ayuda a mantener estabilidad a lo largo del proceso de entrenamiento, lo cual es fundamental para modelos que requieren un cuidado tuning de sus hiperparámetros.
- Escalabilidad. AdamW es particularmente efectivo para escalar modelos, ya que puede manejar la complejidad aumentada de redes profundas sin sacrificar rendimiento, lo que le permite ser aplicado en arquitecturas de punta.
Cómo funciona AdamW
La principal ventaja de AdamW radica en su enfoque respecto a la atenuación de pesos, que está desacoplada de los actualizados de gradiente adaptativos típicos de Adam. Este ajuste garantiza que la regularización se aplique directamente a los pesos del modelo, mejorando la generalización sin impactar negativamente las dinámicas de la tasa de aprendizaje.
El optimizador se basa en la naturaleza adaptativa de Adam, manteniendo los beneficios del momento y las ajustaciones de tasa de aprendizaje por parámetro. La aplicación de la decaimiento de peso de forma independiente aborda uno de los principales defectos de Adam: su tendencia a afectar las actualizaciones de gradiente durante la regularización. Esta separación permite a AdamW mantener un aprendizaje estable, incluso en modelos complejos y a gran escala, mientras mantiene la sobreajustación bajo control.
En las siguientes secciones, exploraremos la teoría detrás del decaimiento de peso y la regularización y la matemática que sustenta el proceso de optimización de AdamW.
Teoría Detrás del Decaimiento de Peso y la Regularización L2
La regularización L2 es una técnica utilizada para evitar la sobreajustación. Logra este objetivo agregando una penalidad a la función de pérdida, desalentando valores de peso grandes. Esta técnica ayuda a crear modelos más simples que generalizan mejor a nuevos datos.
En optimizadores tradicionales, como Adam, se aplica la decaimiento de pesos como parte de la actualización de gradiente, lo cual accidentalmente afecta las tasas de aprendizaje y puede llevar a un desempeño subóptimo.
AdamW mejora esto al desacoplar el decaimiento de pesos de la computación de gradiente. En otras palabras, en lugar de aplicar el decaimiento de pesos durante la actualización de gradiente, AdamW lo trata como un paso separado, aplicándolo directamente a los pesos después de la actualización de gradiente. Esto evita que el decaimiento de pesos interfiera con el proceso de optimización, lo que resulta en un entrenamiento más estable y mejor generalización.
fundamento matemático de AdamW
AdamW modifica el optimizador Adam tradicional cambiando cómo se aplica el decaimiento de pesos. Las ecuaciones centrales para AdamW pueden representarse de la siguiente manera:
- Momentum y tasa de aprendizaje adaptativa:Similar a Adam, AdamW utiliza momentum y tasas de aprendizaje adaptativas para calcular actualizaciones de parámetros basadas en las medias móviles de gradientes y gradientes cuadrados.
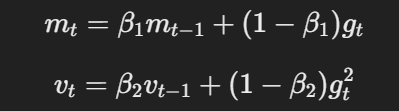
Ecuación para momentum y tasa de aprendizaje adaptativa
- Estimaciones corregidas por sesgo: Las primeras y segundas medidas de momentum se corrigen por sesgo usando lo siguiente:
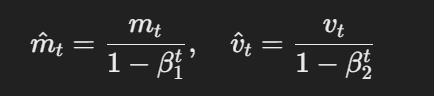
Fórmula para las estimaciones corregidas por sesgo
- Actualización de parámetros con decaimiento de peso desacoplado:En AdamW, el decaimiento de peso se aplica directamente a los parámetros después de la actualización de gradientes. La regla de actualización es:
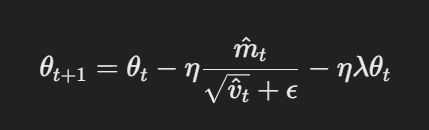
Actualización de parámetros con decaimiento de peso desacoplado
En este caso, η es la tasa de aprendizaje, λ es el factor de decaimiento de peso, y θt representa los parámetros. Este término de decaimiento de peso desacoplado λθt garantiza que la regularización se aplique independientemente de la actualización de gradientes, lo cual es la diferencia clave con Adam.
Implementación de AdamW en PyTorch.
La implementación de AdamW en PyTorch es sencilla; este apartado proporciona una guía completa para configurarlo. Siga estos pasos para aprender cómo fines-ajustar modelos efectivamente con el Optimizador Adam.
Un guía paso a paso de AdamW en PyTorch
Nota: este tutorial asume que ya ha instalado PyTorch. Consulte la Documentación para cualquier orientación.
Paso 1: Importar las bibliotecas necesarias
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Paso 2:Definir el modelo
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Paso 3:Establecer los hiperparámetros
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # número de épocas
Paso 4:Inicializar el optimizador AdamW y configurar la función de pérdida
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
¡Listo!
Ahora, está listo para comenzar a entrenar su modelo de CNN, y eso es lo que haremos en la siguiente sección.
Ejemplo Práctico: Ajuste fino de un modelo utilizando AdamW
Anteriormente, definimos el modelo, configuramos los hiperparámetros, inicializamos el optimizador (AdamW) y configuramos la función de pérdida.
Para entrenar el modelo, necesitará importar unos pocos módulos más;
from torch.utils.data import DataLoader # proporciona un iterable del conjunto de datos import torchvision import torchvision.transforms as transforms
A continuación, define el conjunto de datos y los dataloaders. Para este ejemplo, utilizaremos el conjunto de datos CIFAR-10:
# Define transformaciones para el conjunto de entrenamiento transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Cargar conjunto de datos CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Crear cargadores de datos train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Como ya hemos definido nuestro modelo, el siguiente paso es implementar el bucle de entrenamiento para optimizar el modelo usando AdamW.
Así es cómo se ve:
for epoch in range(num_epochs): model.train() # Establecer el modelo en modo de entrenamiento running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # Limpiar gradientes outputs = model(inputs) # Paso hacia delante loss = criterion(outputs, labels) # Calcular pérdida loss.backward() # Paso hacia atrás optimizer.step() # Actualizar pesos running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
El último paso es validar el rendimiento del modelo en el conjunto de validación que creamos anteriormente.
Aquí está el código:
model.eval() # Establece el modelo en modo de evaluación correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # Pasada frontal _, predicted = torch.max(outputs.data, 1) # Obtén la clase predicha total += labels.size(0) # Actualiza las muestras totales correct += (predicted == labels).sum().item() # Actualiza las predicciones correctas accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
Y aquí tienes.
Ahora sabes cómo implementar AdamW en PyTorch.
Casos de uso comunes para AdamW
Bien, hemos establecido que AdamW ganó popularidad debido a que maneja mejor la decaimiento de la carga que su predecesor, Adam.
Pero ¿cuáles son algunos casos de uso comunes para este optimizador?
En esta sección entraremos en este tema…
Modelos de Aprendizaje Profundo a Escala Grande
AdamW es particularmente beneficioso en el entrenamiento de modelos grandes como BERT, GPT y otras arquitecturas de transformador. Estos modelos típicamente tienen millones o incluso billones de parámetros, lo que a menudo significa que requieren algoritmos de optimización eficientes que manejen actualizaciones de peso complejas y desafíos de generalización.
Tareas de Visión por Computadora y Procesamiento de Lenguaje Natural
AdamW ha convertido en el optimizador de elección en tareas de visión por computadora que involucran CNNs y tareas de procesamiento de lenguaje natural que involucran transformadores. Su capacidad para prevenir el sobreajuste lo hace ideal para tareas que involucran grandes conjuntos de datos y arquitecturas complejas. La desacoplamiento de la decaimiento de peso significa que AdamW evita los problemas encontrados por Adam en la sobreregularización de los modelos.
Ajuste de Hiperparámetros en AdamW
El ajuste de hiperparámetros es el proceso de selección de los mejores valores para los parámetros que gobiernan el entrenamiento de un modelo de aprendizaje automático, sin que estos se lean directamente de los datos. Estos parámetros influyen directamente en cómo el modelo optimiza y converge.
El ajuste adecuado de estos hiperparámetros en AdamW es fundamental para alcanzar un entrenamiento eficiente, evitar el sobreajuste y asegurar que el modelo se generaliza bien a datos no vistos.
En esta sección, exploraremos cómo ajustar las hiperprámetros clave de AdamW para obtener un rendimiento óptimo.
Mejores prácticas para elegir tasas de aprendizaje y decaimiento de pesos
La tasa de aprendizaje es un hiperparámetro que controla cuánto ajustar los pesos del modelo en relación a la pendiente de la función de pérdida durante cada paso de entrenamiento. Una tasa de aprendizaje alta acelera el entrenamiento, pero puede causar que el modelo supere los pesos óptimos, mientras que una tasa baja permite ajustes más precisos pero puede hacer que el entrenamiento sea más lento o se quede atascado en un mínimo local.
La decadencia de peso, por otro lado, es una técnica de regularización utilizada para prevenir el sobreajuste penalizando los pesos grandes en el modelo. Es decir, la decadencia de peso añade una pequeña penalización proporcional al tamaño de los pesos del modelo durante el entrenamiento, ayudando a reducir la complejidad del modelo y mejorar la generalización a nuevos datos.
Para elegir tasas de aprendizaje y valores de decadencia de peso óptimos para AdamW:
- Comienza con una tasa de aprendizaje moderada – Para AdamW, una tasa de aprendizaje alrededor de 1e-3 suele ser un buen punto de partida. Puedes ajustarla según cómo converja el modelo, disminuyéndola si el modelo tiene dificultades para converger o aumentándola si el entrenamiento es demasiado lento.
- Experimente con decaimiento de peso. Comience con un valor alrededor de 1e-2 a 1e-4, dependiendo de la talla del modelo y del conjunto de datos. Un decaimiento de peso ligeramente superior puede ayudar a prevenir el sobreajuste para modelos más grandes y complejos, mientras que los modelos más pequeños pueden requerir menos regularización.
- Utilice programación de tasa de aprendizaje.Implemente programación de tasas de aprendizaje (como decaimiento por pasos o annealing coseno) para reducir dinámicamente la tasa de aprendizaje a medida que avanza el entrenamiento, ayudando al modelo a ajustar sus parámetros con precisión a medida que se acerca a la convergencia.
- Monitorear el rendimiento. Sigue de manera continua el rendimiento del modelo en el conjunto de validación. Si observa sobreajuste, considere aumentar el decaimiento del peso, o si la pérdida de entrenamiento se estabiliza, reduce la tasa de aprendizaje para una mejor optimización.
Pensamientos finales
AdamW ha emergido como uno de los optimizadores más eficaces en aprendizaje profundo, especialmente para modelos a gran escala. Esto se debe a su capacidad para desacoplar la decaimiento de pesos de las actualizaciones de gradientes. En particular, el diseño de AdamW mejora la regularización y ayuda a que los modelos generalicen mejor, particularmente cuando se trata de arquitecturas complejas y conjuntos de datos extensos.
Como se demuestra en este tutorial, implementar AdamW en PyTorch es sencillo, solo se necesitan unos pocos ajustes respecto de Adam. Sin embargo, la configuración de hiperparámetros sigue siendo un paso crucial para maximizar la eficacia de AdamW. Encontrar el equilibrio correcto entre la tasa de aprendizaje y el decaimiento de pesos es fundamental para asegurar que el optimizador funcione eficientemente sin sobreajuste o subajuste del modelo.
Ahora sabes lo suficiente para implementar AdamW en tus propios modelos. Para seguir aprendiendo, echa un vistazo a algunas de estas recursos:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch