













Les algorithmes d’optimisation jouent un rôle crucial dans l’apprentissage profond : ils ajustent les poids du modèle pour minimiser les fonctions de perte pendant l’entraînement. Un de ces algorithmes est l’optimisateur Adam.
Adam a conquis une grande popularité dans l’apprentissage profond en raison de sa capacité à combiner les avantages du moment et des taux d’apprentissage adaptatifs. Cela lui a permis d’être très efficace pour l’entraînement de réseaux de neurones profonds. Il nécessite également un minimum de réglage des hyperparamètres, ce qui le rend accessible et efficace sur une large gamme de tâches.
En 2017, Ilya Loshchilov et Frank Hutter ont présenté une version plus avancée du populaire algorithme Adam dans leur article « Decoupled Weight Decay Regularization. » Ils l’ont nommé AdamW, qui se distingue par le fait de déconnecter la pénalité de poids du processus d’actualisation des gradients. Cette séparation constitue une amélioration cruciale par rapport à Adam et aide à une meilleure généralisation du modèle.
AdamW est devenu de plus en plus important dans les applications modernes de apprentissage profond, notamment dans la gestion de modèles à grande échelle. Sa supériorité dans la régulation des mises à jour des poids a contribué à sa réutilisation dans des tâches exigeant de hautes performances et de stabilité.
Dans ce tutoriel, nous allons aborder les principales différences entre Adam et AdamW, ainsi que les différents cas d’utilisation, et nous mettrons en œuvre une guide pas à pas pour implémenter AdamW dansPyTorch.
Adam vs AdamW
Adam et AdamW sont deux optimiseurs adaptatifs largement utilisés dans le domaine de l’apprentissage profond. La grande différence entre eux se situe dans la façon dont ils traitent la régularisation des poids, ce qui influence leur efficacité dans différents scénarios.
Whiles Adam combine la moment et les taux d’apprentissage adaptatifs pour offrir une optimisation efficiente, il incorpore la régularisation L2 d’une manière qui peut entraver la performance. AdamW résout ce problème en décochant la décroissance des poids de la mise à jour du taux d’apprentissage, offrant ainsi une approche plus efficace pour les grands modèles et améliorant la généralisation. La décroissance des poids, une forme de régularisation L2, pénalise les grands poids dans le modèle. Adam incorpore la décroissance des poids dans le processus d’actualisation des gradients, tandis que AdamW l’applique séparément après l’actualisation des gradients
Voici d’autres manières dans lesquelles ils se différentient :
Principales différences entre Adam et AdamW
Bien que les deux optimisateurs soient conçus pour gérer le moment et l’ajustement des taux d’apprentissage de manière dynamique, ils diffèrent fondamentalement dans leur traitement de la pénalité de poids.
Dans Adam, la pénalité de poids est appliquée indirectement comme partie de l’actualisation des gradients, ce qui peut modifier intentionnellement les dynamiques d’apprentissage et interférer avec le processus d’optimisation. Cependant, AdamW sépare la pénalité de poids de l’étape de gradient, assurant que la régularisation impacte directement les paramètres sans altérer le mécanisme d’apprentissage adaptatif.
Cette conception permet une régularisation plus précise, aidant les modèles à généraliser de manière supérieure, en particulier dans les tâches impliquant de grandes et complexes jeux de données. En conséquence, les deux optimisateurs sont souvent utilisés dans des cas d’utilisation très différents.
Cas d’utilisation pour Adam
Adam présente un meilleur rendement dans les tâches où la régularisation est moins critique ou lorsque l’efficacité calculatoire est priorisée sur la généralisation. Exemples :
- Petites réseaux neuronales. Pour des tâches telles que la classification d’images de base à l’aide de petites CNNs (Réseaux neuronales convolutionnels) sur des jeux de données tels que MNIST ou CIFAR-10, où la complexité du modèle est faible, Adam peut optimiser efficacement sans nécessiter une régularisation extensive.
- Problèmes de régression simples. Dans des tâches de régression directe avec des ensembles de caractéristiques limités, telles que la prédiction des prix de maisons à l’aide d’un modèle de régression linéaire, Adam peut converger rapidement sans nécessiter de techniques de régularisation avancées.
- Prototypage précoce. Pendant les premières étapes du développement du modèle, où des expériences rapides sont nécessaires, Adam permet des itérations rapides sur des architectures plus simples, ce qui permet aux chercheurs de détecter les potentielles difficultés sans l’overhead de l’ajustement des paramètres de régularisation.
- Données moins bruyantes. Lorsque l’on traite des jeux de données propres et sans bruit, tels que des données de texte bien curatées pour l’analyse des sentiments, Adam peut apprendre des patrons efficacement sans le risque d’overfitting qui pourrait nécessiter une régularisation plus pesante.
- Cycles de formation courts. Dans des scénarios avec des contraintes de temps, tels que le déploiement rapide de modèles pour des applications en temps réel, l’optimisation efficiente d’Adam peut fournir rapidement des résultats satisfaisants, même si ceux-ci ne sont pas pleinement optimisés pour la généralisation.
Cas d’utilisation pour AdamW
AdamW est avantageux dans les scénarios où il y a un risque d’overfitting et lorsque la taille du modèle est importante. Par exemple :
- Les transformateurs à grande échelle. Dans les tâches de traitement du langage naturel, telles que la finition de modèles tels que GPT sur de vastes corpus de textes, la capacité d’AdamW à gérer la pénalité de décence effectivement empêche l’overfitting, garantissant une meilleure généralisation.
- Les modèles complexes de vision par ordinateur. Pour les tâches impliquant des réseaux neuronaux convolutionnels profonds (CNN) entraînés sur de grands jeux de données tels que ImageNet, AdamW aide à maintenir la stabilité et la performance du modèle en décochant la pénalité de décence, ce qui est crucial pour atteindre une haute précision.
- Apprentissage multitâche. Dans les scénarios où un modèle est entraîné simultanément sur plusieurs tâches, AdamW offre la flexibilité de gérer des jeux de données diversifiés et de prévenir l’overfitting sur n’importe quelle seule tâche.
- Modèles génératifs. Pour l’entraînement de réseaux adversaires génératifs (GANs), où maintenir un équilibre entre le générateur et le discriminateur est critique, la régularisation améliorée d’AdamW peut aider à stabiliser l’entraînement et améliorer la qualité des sorties générées.
- Apprentissage par rétroaction. Dans les applications d’apprentissage par rétroaction où les modèles doivent s’adapter à des environnements complexes et apprendre des politiques robustes, AdamW aide à atténuer l’overfitting sur des états ou des actions spécifiques, améliorant ainsi le rendement général du modèle dans diverses situations.
Avantages d’AdamW par rapport à Adam
Mais pourquoi utiliser AdamW plutôt que Adam? Simple. AdamW offre plusieurs avantages clés qui améliorent son performance, en particulier dans les scénarios de modélisation complexes.
Il aborde certaines des limitations trouvées dans l’optimiseur Adam, ce qui le rend plus efficace dans l’optimisation et contribue à l’amélioration de l’entraînement du modèle et de sa robustesse.
Voici d’autres avantages remarquables :
- Décoquillage de la pénalité de poids.En séparant la pénalité de poids des mises à jour de gradient, AdamW permet un contrôle plus précis de la régularisation, ce qui amène une meilleure généralisation du modèle.
- Amélioration de la généralisation. AdamW réduit le risque d’overfitting, en particulier dans les grands modèles, ce qui le rend adapté pour des tâches impliquant de vastes jeux de données et des architectures complexes.
- Stabilité pendant l’entraînement. La conception d’AdamW permet de maintenir une stabilité tout au long du processus d’entraînement, ce qui est essentiel pour les modèles qui nécessitent un alignement précis de leurs hyperparamètres.
- Scalabilité.AdamW est particulièrement efficace pour l’escalade des modèles, car il peut gérer l’augmentation de complexité des réseaux profonds sans sacrifier la performance, ce qui lui permet d’être appliqué dans les architectures de pointe.
Comment fonctionne AdamW
La force de AdamW réside dans son approche du poids de décaissement, qui est désaccouplée des mises à jour adaptatives de gradient typiques d’Adam. Cette modification assure que la régularisation est appliquée directement aux poids du modèle, améliorant la généralisation sans impacter négativement les dynamiques de la vitesse d’apprentissage.
L’optimiseur se fonde sur la nature adaptative d’Adam, en conservant les avantages du moment et des ajustements de taux d’apprentissage par paramètre. L’application de la pénalité de poids indépendamment permet de résoudre l’une des principales lacunes d’Adam : sa tendance à affecter les mises à jour de gradient pendant la régularisation. Cette séparation permet à AdamW de maintenir une apprentissage stable, même dans des modèles complexes et à grande échelle, tout en contrôlant l’overfitting.
Dans les sections suivantes, nous explorerons la théorie derrière la pénalité de poids et la régularisation, ainsi que les mathématiques sous-jacentes au processus d’optimisation d’AdamW.
Théorie derrière la pénalité de poids et la régularisation L2
La régularisation L2 est une technique utilisée pour prévenir l’overfitting. Elle atteint cet objectif en ajoutant une pénalité au fonction de perte, en décourageant les valeurs de poids élevées. Cette technique aide à créer des modèles plus simples qui généralisent mieux aux nouveaux jeux de données.
Dans les optimisateurs traditionnels, tels que Adam, la pénalité de poids est appliquée comme partie de l’actualisation des gradients, ce qui affecte involontairement les taux d’apprentissage et peut conduire à des performances sous-optimales.
AdamW améliore cela en décochant la pénalité de poids de la computation du gradient. Autrement dit, plutôt que d’appliquer la pénalité de poids pendant l’actualisation des gradients, AdamW la traite comme une étape séparée, l’appliquant directement aux poids après l’actualisation des gradients. Cela empêche la pénalité de poids d’interférer avec le processus d’optimisation, menant à une formation plus stable et une meilleure généralisation.
Fondements mathématiques d’AdamW
AdamW modifie l’optimiseur Adam traditionnel en changeant la manière dont la pénalité de poids est appliquée. Les équations centrales pour AdamW peuvent être représentées comme suit :
- Momentum et taux d’apprentissage adaptatif :Comme Adam, AdamW utilise le momentum et des taux d’apprentissage adaptatifs pour calculer les mises à jour des paramètres sur la base des moyennes mobiles des gradients et des carrés des gradients.
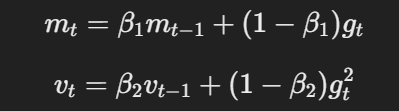
L’équation pour le momentum et le taux d’apprentissage adaptatif
- Estimations corrigées de l’erreur de biais:Les estimations du premier et du deuxième moment sont corrigées du biais en utilisant :
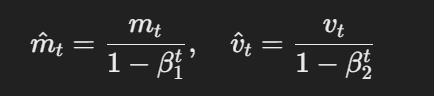
La formule pour les estimations corrigées de l’erreur de biais
- Mise à jour des paramètres avec une décroissance des poids déconnectée :Dans AdamW, la décroissance des poids est appliquée directement aux paramètres après l’actualisation des gradients. La règle d’actualisation est :
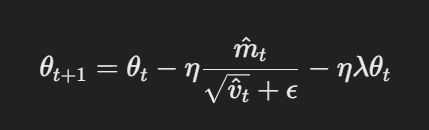
Mise à jour des paramètres avec une décroissance des poids déconnectée
Dans ce cas, η est le taux d’apprentissage, λ est le facteur de décroissance des poids, et θt représente les paramètres. Cette décroissance des poids déconnectée λθt assure que la régularisation est appliquée indépendamment de l’actualisation des gradients, ce qui est la différence principale par rapport à Adam.
Implémentation d’AdamW dans PyTorch.
Implémenter AdamW dans PyTorch est aisé ; cette section fournit une guide complet pour le configurer. S’il vous plaît suivre ces étapes pour apprendre comment tunez les modèles avec l’optimiseur Adam efficacement.
Un guide pas à pas pour AdamW dans PyTorch
Note : ce tutoriel présuppose que vous avez déjà installé PyTorch. Consultez la Documentation pour toute aide.
Étape 1 :Importez les bibliothèques nécessaires
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Étape 2 :Définir le modèle
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Étape 3 :Définir les hyperparamètres
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # Nombre d'époques
Étape 4 :Initialiser l’optimiseur AdamW et configurer la fonction de perte
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
Voila!
Maintenant, vous êtes prêt à commencer à entraîner votre modèle CNN, ce que nous ferons dans la prochaine section.
Exemple pratique : Tuning fin des modèles à l’aide d’AdamW
Au-dessus, nous avons défini le modèle, réglé les hyperparamètres, initialisé l’optimiseur (AdamW) et mis en place la fonction de perte.
Pour entraîner le modèle, nous aurons besoin d’importer quelques modules supplémentaires ;
from torch.utils.data import DataLoader # fournit une itération de la base de données import torchvision import torchvision.transforms as transforms
Ensuite, définissez le jeu de données et les chargeurs de données. Pour cet exemple, nous utiliserons le jeu de données CIFAR-10 :
# Définir les transformations pour le jeu d'entraînement transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Charger le jeu de données CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Créer des chargeurs de données train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Puisque nous avons déjà défini notre modèle, l’étape suivante est d’implémenter la boucle d’entraînement pour optimiser le modèle en utilisant AdamW.
Voici comment cela se présente :
for epoch in range(num_epochs): model.train() # Configurer le modèle en mode d'entraînement running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # Effacer les gradients outputs = model(inputs) # Passe avant loss = criterion(outputs, labels) # Calculer la perte loss.backward() # Passe arrière optimizer.step() # Mettre à jour les poids running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
La dernière étape est de valider la performance du modèle sur le jeu de données de validation que nous avons créé plus tôt.
Voici le code :
model.eval() # Définir le modèle en mode évaluation correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # Passe avant _, predicted = torch.max(outputs.data, 1) # Obtenir la classe prédite total += labels.size(0) # Mettre à jour le total des échantillons correct += (predicted == labels).sum().item() # Mettre à jour les prédictions correctes accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
Et voilà, c’est fini.
Vous savez maintenant comment implémenter AdamW dans PyTorch.
Use cases communs pour AdamW
D’accord, nous avons vu que AdamW a gagné en popularité en raison de son meilleur traitement du poids non nécessaire que son prédécesseur, Adam.
Mais quelles sont quelques cas d’utilisation communs pour cet optimiseur ?
Nous aborderons cela dans cette section…
Modèles de machine learning à grande échelle
AdamW est particulièrement bénéfique pour la formation de grands modèles tels que BERT, GPT et d’autres architectures de transformateurs. Ces modèles ont généralement des millions ou même des milliards de paramètres, ce qui implique souvent qu’ils nécessitent des algorithmes d’optimisation efficaces pouvant gérer des mises à jour de poids complexes et des défis de généralisation.
Tâches de vision par ordinateur et de traitement du langage naturel
AdamW est devenu l’optimiseur de prédilection pour les tâches de vision par ordinateur impliquant des CNN et les tâches de traitement du langage naturel impliquant des transformateurs. Sa capacité à prévenir l’overfitting le rend idéal pour des tâches impliquant de grands jeux de données et des architectures complexes. La désaccrochage de la pénalité de poids permet à AdamW d’éviter les problèmes rencontrés par Adam lors de la sur-régularisation des modèles.
Tunage des hyperparamètres dans AdamW
Le réglage des hyperparamètres est le processus de sélection des meilleures valeurs pour les paramètres qui gouvernent l’entraînement d’un modèle d’apprentissage automatique mais qui ne sont pas appris à partir des données elles-mêmes. Ces paramètres influent directement sur la manière dont le modèle optimise et converge.
Le réglage adéquat de ces hyperparamètres dans AdamW est essentiel pour atteindre un entraînement efficient, éviter l’overfitting et s’assurer que le modèle généralise bien sur des données non vues.
Dans cette section, nous explorons comment finissent-t-on les hyperparamètres clés d’AdamW pour une performance optimale.
Meilleures pratiques pour choisir les taux d’apprentissage et la décroissance des poids
Le taux d’apprentissage est un hyperparamètre qui contrôle la taille des ajustements des poids du modèle par rapport au gradient de perte pendant chaque étape d’entraînement. Un taux d’apprentissage élevé accélère l’entraînement mais peut provoquer que le modèle dépasse les poids optimaux, tandis qu’un taux plus bas permet des ajustements plus précis mais peut ralentir l’entraînement ou s’arrêter dans des minimums locaux.
La décroissance du poids, d’autre part, est une technique de régularisation utilisée pour éviter l’overfitting en sanctionnant les grands poids du modèle. Plus précisément, la décroissance du poids ajoute une petite pénalité proportionnelle à la taille des poids du modèle pendant l’entraînement, aidant à réduire la complexité du modèle et à améliorer la généralisation sur de nouveaux jeux de données.
Pour choisir des taux d’apprentissage et des valeurs de décroissance du poids optimaux pour AdamW :
- Commencez avec un taux d’apprentissage modéré – Pour AdamW, un taux d’apprentissage de l’ordre de 1e-3 est souvent un bon point de départ. Vous pouvez l’ajuster en fonction du cheminement du modèle, en le réduisant si le modèle a de la difficulté à converger ou en le multipliant si l’entraînement est trop lent.
- Experimenter avec la décroissance du poids. Commencez avec une valeur de l’ordre de 1e-2 à 1e-4, en fonction de la taille du modèle et du jeu de données. Une décroissance du poids légèrement plus élevée peut aider à éviter l’overfitting pour des modèles plus grands et plus complexes, tandis que les petits modèles peuvent nécessiter moins de régularisation.
- Utilisez un schéma d’apprentissage adaptatif. Implémentez des schémas d’apprentissage adaptatifs (comme la décroissance en étape ou l’anéaling cosinus) pour réduire dynamiquement la vitesse d’apprentissage au fur et à mesure de l’entraînement, afin que le modèle améliore ses paramètres lorsqu’il approche la convergence.
- Surveiller les performances. Surveillez en continu les performances du modèle sur le jeu de validation. Si vous constatez de l’overfitting, envisagez d’augmenter la décroissance du poids, ou si la perte de formation plateau, réduisez la vitesse d’apprentissage pour une meilleure optimisation.
Pensées finales
AdamW est devenu l’un des optimiseurs les plus efficaces dans le domaine de l’apprentissage profond, en particulier pour les modèles à grande échelle. Cela est dû à sa capacité à découpler la pénalité de poids de la mise à jour des gradients. En effet, la conception d’AdamW améliore la régularisation et aide les modèles à généraliser de manière meilleure, en particulier lorsqu’il s’agit de traiter des architectures complexes et de grandes bases de données.
Comme il est démontré dans cette tutorial, l’implémentation d’AdamW dans PyTorch est aisée — il ne nécessite que quelques ajustements par rapport à Adam. Cependant, la mise à l’essai des hyperparamètres demeure une étape cruciale pour maximiser l’efficacité d’AdamW. Trouver le bon équilibre entre la vitesse d’apprentissage et la pénalité de poids est essentiel pour s’assurer que l’optimiseur fonctionne efficacement sans surapprentissage ou sous-apprentissage du modèle.
Maintenant, vous savez suffisamment pour implémenter AdamW dans vos propres modèles. Pour continuer votre apprentissage, consultez certains de ces ressources :
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch