













Оптимизационные алгоритмы играют незаменимую роль в глубоком обучении: они настраивают веса моделей для минимизации функций потерь в процессе обучения. Один из таких алгоритмов – оптимизатор Adam.
Adam стал очень популярным в глубоком обучении благодаря своей способности комбинировать преимущества метода момента и адаптивных скоростей обучения. Это сделало его очень эффективным для тренировки глубоких нейронных сетей. Кроме того, он требует минимальной настройки гиперпараметров, тем самым делая его широко доступным и эффективным во многих задачах.
В 2017 году Илья Лошчилов и Франк Хюттер представили более продвинутую версию популярного алгоритма Адама в своей статье “Decoupled Weight Decay Regularization.” они назвали его AdamW, который отличается тем, что он декоуптирует уменьшение вагины от процесса обновления градиента. Это разделение является критическим улучшением по сравнению с Адамом и помогает лучшему обучению модели.
АдамВ становится все более важным в современных приложениях глубокого leanedning, особенно в обработке масштабных моделей. Его превосходные способности регулировать обновления весов способствовали его применению в задачах, требующих высокой производительности и стабильности.
В этом руководстве мы познакомимся с ключевыми различиями между Адамом и АдамВ, а также с различными use cases, и мы создадимшаг по шагу руководство по внедрению АдамВ вPyTorch.
Адам vs АдамВ
Адам и AdamW являются адаптивными оптимизаторами, широко используемыми в глубоком обучении.большой разницы между ними является то, как они обрабатывают регуляризацию весов, что влияет на их эффективность в различных сценариях.
В то время как Adam комбинирует момент и адаптивные learning rates для оптимальной оптимизации, он включает L2 регуляризацию так, что может помешать повышению производительности. AdamW решает эту проблему, отделяя регуляризацию весов от обновления learning rate, что обеспечивает более эффективный метод для крупных моделей и улучшая generalization. Регуляризация весов, форма L2 регуляризации, наказывает большие веса в модели. Adam включает регуляризацию весов в процесс обновления градиента, в то время как AdamW применяет ее отдельно после обновления градиента
Вот несколько других способов, в которых они отличаются:
Ключевые различия между Adam и AdamW
尽管这两个优化器都是设计用来管理动量和动态调整学习率的,但它们在权重量衰减的处理上存在根本性的差异。
在Adam优化器中,权重量衰减是通过梯度更新间接应用的,这可能会无意中改变学习动态,并干扰优化过程。而AdamW优化器将权重量衰减与梯度步分离,确保正则化直接影响参数,而不改变适应性学习机制。
这种设计使得正则化更加精确,有助于模型更好地泛化,特别是在涉及大量复杂数据集的任务中。因此,这两个优化器通常有非常不同的应用场景。
Adam的使用场景
Adam在正则化不那么关键的任务中表现更好,或者当优先考虑计算效率而非泛化时。例如:
- Малые нейронные сети. Для таких задач, как базовая классификация изображений с использованием малых CNN (Конволюционные нейронные сети) на датасетах MNIST или CIFAR-10, где сложность модели низкая, Адам эффективно оптимизирует модель без необходимости широкого использования регуляризации.
- Простые регрессионные задачи. В простых регрессионных задачах с ограниченными наборами features, таких как прогнозирование цен на дома с использованием линейной регрессии, Адам может быстро сходиться без необходимости использования передовых техник регуляризации.
- Ранний прототип. во время ранних стадий разработки моделей, когда требуется быстрое экспериментирование, Адам позволяет быстро проходить итерации с прощей архитектурой, позволяя исследователям идентифицировать потенциальные проблемы без накладных расходов на настройку параметров регуляризации.
- Менеешудные данные. При работе с чистыми датасетами с минимальным шумом, такими как хорошо подготовленные текстовые данные для анализа настроения, Адам эффективно обучается позиции без риска переобучения, которое может требовать более тяжелой регуляризации.
- Короткие циклы обучения. В ситуациях с ограниченными сроками, таких как быстрое развертывание моделей для реального временных приложений, эффективная оптимизация Адама поможет быстро достичь удовлетворительных результатов, даже если они не полностью оптимизированы для всеобщей generalization.
Применения АдамW
АдамВ отличается в сценариях с угрозой переобучения и при значительных размерах модели. Например:
- Большие трансформеры. В задачах природного языковой обработки, таких как настройка моделей like GPT на обширных текстовых корпусах, способность АдамВ эффективно управлять затуханием весов предотвращает переобучение, обеспечивая лучшую generalizatsiyu.
- сложные компьютерные модели зрения. Чтобы задачи, включающие глубокие сверточные нейронные сети (CNNs) обученные на больших наборах данных, таких как ImageNet, АдамВ помогает поддерживать стабильность и эффективность модели, декоупливая затухание весов, что важно для достижения высокой точности.
- Многозадачное обучение. В сценариях, когда модель тренируется параллельно на нескольких задачах, AdamW обеспечивает гибкость в обработке различных наборов данных и предотвращение переобучения на любой отдельно взятой задаче.
- Генеративные модели. при обучении генеративных антагонистических сетей (GANs), где важно поддерживать баланс между генератором и дискриминатором, улучшенная регуляризация AdamW может помочь устоить тренировку и улучшить качество генерируемых выходов.
- Обучение поощрения. В приложениях обучения поощрения, где модели должны адаптироваться к сложным средам и научиться разумной политике, AdamW помогает смягчить переобучение на определенные состояния или действия, улучшая общее поведение модели в различных ситуациях.
Преимущества AdamW перед Adam
Но почему кто-то бы принял решение использовать AdamW вместо Adam?普普通通. AdamW предлагает несколько ключевых преимуществ, улучшающих его производительность, особенно в сложных сценариях建模.
Он решает некоторые из ограничений, найденных в оптимизаторе Adam, тем самым делая его более эффективным в оптимизации и способствуя улучшению обучения моделей и их устойчивости.
Ниже представлены еще некоторые выдающиеся преимущества:
- Отделение весового искажения.Переделавя весовое искажение и оgradientные обновления, AdamW позволяет проще управлять регуляризацией, что ведет к лучшей generalization модели.
- Улучшенная generalization. AdamW уменьшает риск overfitting, особенно в крупных моделях, делая его подходящим для задач с обширными данными и сложными архитектурами.
- Стабильность в процессе обучения. Структура AdamW помогает поддерживать стабильность на протяжении всего процесса обучения, что является необходимым для моделей, которые требуют тщательной настройки их гиперпараметров.
- Скалярность.AdamW особенно эффективен для масштабирования моделей, так как он может обрабатывать увеличенную сложность глубоких сетей без потери производительности, что позволяет применять его в современных архитектурах.
Как работает AdamW
Суть сильных сторон AdamW состоит в его методе весового затухания, который разделен от адаптивных итерационных уравнений, характерных для Adam. Эта коррекция обеспечивает регуляризацию прямо для весов модели, улучшая generalization без негативного влияния на динамику скорости обучения.
Оптимизатор основан на адаптивных свойствах Адама, сохраняя пользу с моменту и коррекции learning rate для каждого параметра. Apply вес затухания отдельно решает одну из основных недостатков Адама: его tendencias повлиять на градиентные обновления в процессе регуляризации. Эта раздельность позволяет AdamW maintain стабильное обучение, даже в сложных и крупномасштабных моделях, while keeping overfitting в check.
В следующих разделах мы исследуем теорию затухания весов и регуляризации и математику, лежащую в основе процесса оптимизации AdamW.
Теория Затухания Весов и L2 Регуляризации
L2 регуляризация – это техника, используемая для предотвращения overfitting. Это достигается добавлением штрафной ставки к функции потерь, disencouraging большие значения весов. Эта техника помогает создавать более простые модели, which generalize лучше на новые данные.
В традиционных оптимизаторах, таких как Adam, наложение весового затухания выполняется как часть обновления градиента, что незаметно влияет на скорость обучения и может привести к неOptimalной работе.
AdamW улучшает это тем, что декоуpling весового затухания от вычисления градиента. То есть, вместо того, чтобы применять весовое затухание во время обновления градиента, AdamW рассматривает его как отдельный шаг, применяя его непосредственно к весам после обновления градиента. Этоprevents весовое затухание от вмешивания в процесс оптимизации, что приводит к более стабильному тренированию и лучшей generalizции.
Mathematical Foundation of AdamW
AdamW modifies the traditional Adam optimizer by changing how weight decay is applied. The core equations for AdamW can be represented as follows:
- Момент и адаптивный уровень leanring:Подобно Адаму, АдамВ использует момент и адаптивные уровни leanring, чтобы вычислять обновления параметров на основе перемещающихся средних градиентов и квадратичных градиентов.
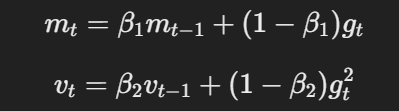
Formula для момента и адаптивного уровня leanring
- Оценки с исправлением наклона:Первый и второй момент оценок исправляются наклоном с использованием следующего:
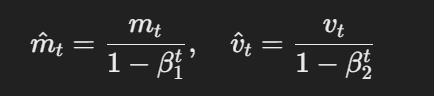
Формула для оценок с исправлением наклона
- Обновление параметров с декоапtedным убыванием весов:В AdamW убывание весов применяется непосредственно к параметрам после обновления градиентов. Правило обновления следующее:
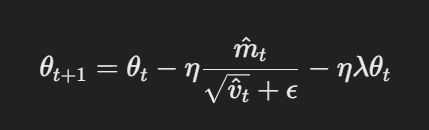
Обновление параметров с декоапtedным убыванием весов
Здесь η — это скорость leaning, λ — это фактор убывания весов, и θt — представляет параметры. Этот убывающийся оператор λθt гарантирует, что регуляризация применяется независимо от обновления градиента, что является ключевой разницей с Adam.
Реализация AdamW в PyTorch
Реализация AdamW в PyTorch является простой; этот раздел предлагает подробное руководство по его настройке. Следуйте этим шагам, чтобы научиться эффективно настраивать модели с помощью оптимизатора Adam.
Пошаговое руководство по AdamW в PyTorch
Примечание: данный指南 предполагает, что у вас уже установлен PyTorch. Пожалуйста, обратитесь к Документации для дополнительной информации.
Шаг 1: Импортируйте необходимые библиотеки
import torch import torch.nn as nn import torch.optim as optim Import torch.nn.functional as F
Шаг 2:Определите модель
class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1) self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = F.relu(self.fc1(x)) x = self.fc2(x)
Шаг 3:Установите гиперпараметры
learning_rate = 1e-4 weight_decay = 1e-2 num_epochs = 10 # количество эпох
Шаг 4:Инициализируйте оптимизатор AdamW и настройте функцию потерь
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) criterion = nn.CrossEntropyLoss()
Воля!
Теперь вы готовы начать обучение модели CNN, о чем мы будем говорить в следующей секции.
Практический пример: Finetuning модели с использованием AdamW
Выше мы определили модель, установили гиперпараметры, инициализировали оптимизатор (AdamW) и настроили функцию потерь.
Чтобы обучить модель, мы должны импортировать еще несколько модулей;
from torch.utils.data import DataLoader #предоставляет итерируемое представление датасета import torchvision import torchvision.transforms as transforms
Далее определите датасет и датаLoaderы. В этом примере мы будем использовать датасет CIFAR-10:
# Определение преобразований для тренировочного набора transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) # Загрузка набора данных CIFAR-10 train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) val_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) # Создание поLoader для данных train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
Поскольку мы уже определили свой модель, следующим шагом является реализация цикла обучения, для оптимизации модели с использованием AdamW.
Вот так это выглядит:
for epoch in range(num_epochs): model.train() # Установите модель в режим тренировки running_loss = 0.0 for inputs, labels in train_loader: optimizer.zero_grad() # Очистите градиенты outputs = model(inputs) # Шаг вперед loss = criterion(outputs, labels) # Calculate loss loss.backward() # Шаг назад optimizer.step() # обновите веса running_loss += loss.item() print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')
Последний шаг – это проверка performanse модели на validate наборе данных, который мы создали ранее.
コードは以下の通りです。
model.eval() # モデルを評価モードに設定する correct = 0 total = 0 with torch.no_grad(): for inputs, labels in val_loader: outputs = model(inputs) # 順伝播を行う _, predicted = torch.max(outputs.data, 1) # 予測されたクラスを取得する total += labels.size(0) # 合計サンプル数を更新する correct += (predicted == labels).sum().item() # 正解予測数を更新する accuracy = 100 * correct / total print(f'Validation Accuracy: {accuracy:.2f}%')
これで完了です。
これまでPyTorchでAdamWを実装する方法を学びました。
AdamWの一般的な使用例
AdamWは前のアドアムと比べて重み缩小白化をより効果的に管理するために人気を博しました。
では、この最適化器の一般的な使用例をいくつか見てみましょう。
Мы об этом пойдем в этом разделе…
Масштабные модели глубокого обучения
AdamW особенно полезен при обучении крупных моделей, таких как BERT, GPT и других архитектур трансформеров. Такие модели обычно имеют миллионы и даже миллиарды параметров, что часто означает, что для них требуются эффективные оптимизационные алгоритмы, которые обрабатывают сложные обновления весов и проблемы общей генеralizции.
Задачи компьютерной видеокарты и NLP
AdamW стал выбором оптимизатора в задачах компьютерного зрения,涉及到 CNN и задачах NLP, включающих трансформеры. Ее способность предотвращать переобучение делает ее идеальной для задач с большими наборами данных и сложными архитектурами. Отделение wieght decay означает, что AdamW избегает проблем, в которых оказывается Adam при чрезмерной регуляции моделей.
Настройка гиперпараметров в AdamW
Теuning гиперпараметров – это процесс выбора лучших значений параметров, управляющих обучением модели машинного обучения, которые не вычисляются самостоятельно на основе данных. Эти параметры непосредственно influencют оптимизацией и конвергенцией модели.
Корректный теuning этих гиперпараметров в AdamW обеспечивает эффективность обучения, предотвращает переобучение и обеспечивает хорошую generalizatsiyu модели на невиданные данные.
В этой секции мы посмотрим, как точно настроить ключевые гиперпараметры AdamW для оптимальных Performans.
Лучшие практики для выбора скоростей обучения и затухания весов
Скорость обучения – это гиперпараметр, который контролирует, насколько сильно настраивать веса модели на основе градиента потерь во время каждого шага обучения. Higher learning rate acceleration обучения, однако может привести к тому, что модель пройдет мимо оптимальных весов, а lower rate allows for more fine-tuned adjustments, но может замедлить обучение или застрять в локальном минимуме.
В противовес этому, регуляризация весов (weight decay) является техникой регуляризации, которая используется для предотвращения переобучения путём наказания больших весов в модели. Точнее, регуляризация весов добавляет небольшое наказание, пропорциональное размера весов модели, в процессе обучения, помогая уменьшить сложность модели и улучшить обобщаемость на новые данные.
Для выбора оптимальных скоростей обучения и значений регуляризации весов для AdamW:
- Начните с средней скорости обучения – для AdamW скорость обучения в районе 1e-3 зачастую является хорошим starting point. Вы можете настроить её на основе того, насколько хорошо модель конverгирует, снижая её, если модель с трудом конverгирует, или увеличивая, если тренировка слишком медленна.
- Экспериментируйте с убыванием весов. Начните с значения в районе 1e-2 до 1e-4, в зависимости от размера модели и набора данных. немного вышее убывание весов может помочь предотвратить переобучение для более крупных, сложных моделей, в то время как более малые модели могут требуть меньше регуляризации.
- Используйте планирование скорости обучения. ИмPLEMENTiruйте расписания скорости обучения (как ступенчатое уменьшение или аннелирование косинуса), чтобы динамически уменьшать скорость обучения по мере прогресса тренировки, помогая модели точно настроить свои параметры, когда она приближается к конвергенции.
- Observe performance. Постоянно отслеживайте показатели модели на выборке валидации. Если вы наблюдаете переобучение, подумайте о увеличении убывания весов, или если убывание тренировочной потертости замедляется, уменьшите скорость обучения для лучшей оптимизации.
Final Thoughts
АдамВ стал одним из самых эффективных оптимизаторов в глубоком обучении, особенно для крупномасштабных моделей. Это связано с его способностью разъединить детерминант сжатия от обновлений градиента. Точность проектирования АдамВ улучшает регуляризацию и помогает моделям лучше обобщать знания, особенно при работе с сложными архитектурами и обширными наборами данных.
Как показано в данном руководстве, внедрение АдамВ в PyTorch является простым — требуется всего лишь несколько корректировок у Адама. Однако, настройка гиперпараметров остается ключевым шагом для максимизации эффективности АдамВ. Нахождение правильного баланса между скоростью обучения и детерминант сжатия необходимо для обеспечения эффективной работы оптимизатора без переобучения или недообучения модели.
Теперь у тебя достаточно знаний, чтобы внедрить АдамВ в свои собственные модели. Чтобы продолжить свое обучение, посмотрите на некоторые из этих ресурсов:
Source:
https://www.datacamp.com/tutorial/adamw-optimizer-in-pytorch