













在实时数据时代,处理和分析流数据的能力对企业变得至关重要。Apache Kafka作为一款强大的分布式事件流平台,通常是这些实时流水线的核心。但是处理原始数据流可能会很复杂。这就是Streaming SQL发挥作用的地方:它允许用户以SQL的简单方式查询和转换Kafka主题。
什么是Streaming SQL?
Streaming SQL指的是将结构化查询语言(SQL)应用于处理和分析运动数据。与传统SQL不同,传统SQL查询数据库中的静态数据集,而Streaming SQL会持续处理数据流经系统。它支持实时的过滤、聚合、连接和窗口操作。使用Kafka作为实时数据流水线的支柱,Streaming SQL允许用户直接查询Kafka主题,使得分析和处理数据变得更加简单,无需编写复杂的代码。
Streaming SQL在Kafka上的关键组件
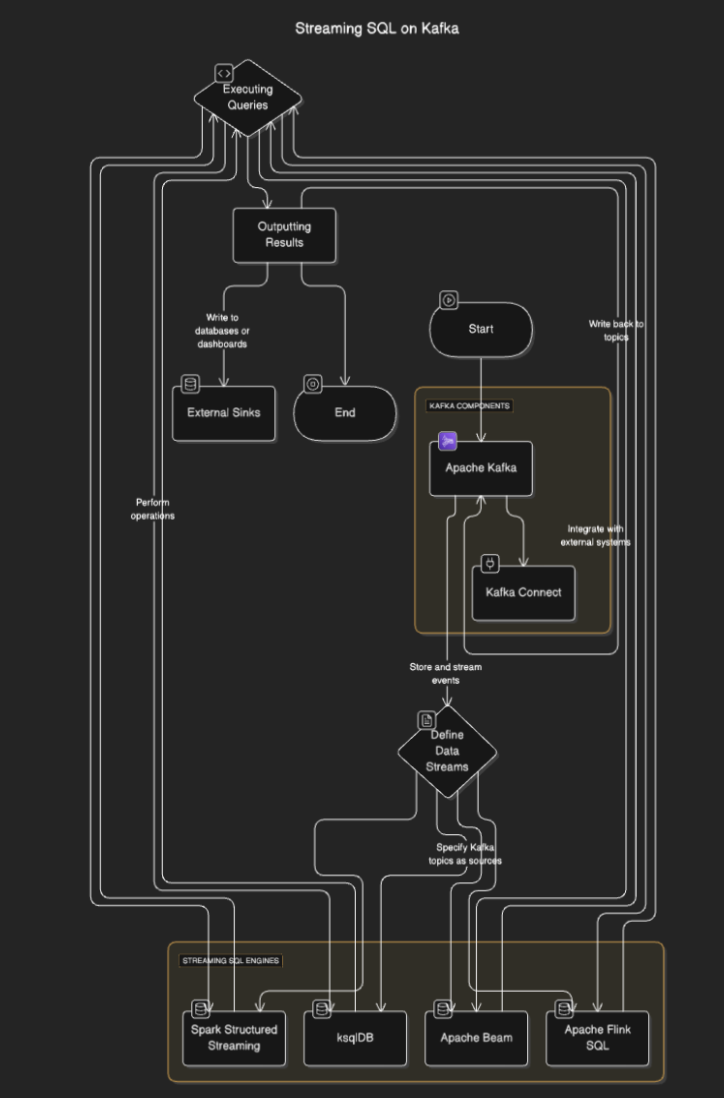
1. Apache Kafka
Kafka通过主题存储和传输实时事件。生产者将数据写入主题,消费者订阅并处理或分析这些数据。Kafka的耐用性、可扩展性和容错性使其非常适合用于流数据。
2. Kafka Connect
Kafka Connect 促进与外部系统(如数据库、对象存储或其他流处理平台)的集成。它实现了对数据从/到 Kafka 主题的无缝摄入或导出。
3. 流处理 SQL 引擎
有几种工具支持在 Kafka 上进行流处理 SQL,包括:
- ksqlDB:基于 Kafka Streams 构建的 Kafka 原生流处理 SQL 引擎。
- Apache Flink SQL:具有高级 SQL 功能的多功能流处理框架。
- Apache Beam:为批处理和流处理提供 SQL,兼容各种运行程序。
- Spark Structured Streaming:支持实时和批处理数据处理的 SQL。
流处理 SQL 是如何工作的?
流处理 SQL 引擎连接到 Kafka 从主题中读取数据,实时处理数据,并将结果输出到其他主题、数据库或外部系统。该过程通常包括以下步骤:
- 定义数据流:用户通过指定 Kafka 主题作为数据源来定义流或表。
- 执行查询:执行 SQL 查询以执行过滤、聚合和流连接等操作。
- 输出结果: 结果可以写回到Kafka主题或外部接收端,如数据库或仪表板。
流程图
Kafka的流式SQL工具
ksqlDB
ksqlDB 是专为Kafka构建的,提供SQL接口以处理Kafka主题。它简化了过滤消息、连接流和聚合数据等操作。主要功能包括:
- 声明式SQL查询: 定义实时转换而无需编码。
- 物化视图: 持久化查询结果以便快速查找。
- Kafka原生: 针对低延迟处理进行了优化。
示例:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink 是一个强大的流处理框架,提供批处理和流数据的SQL功能。它支持复杂操作,如事件时间处理和高级窗口处理。
示例:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark结构化流处理
Spark结构化流处理 实现基于SQL的流处理,并与其他Spark组件很好地集成。非常适合复杂的数据管道,结合了批处理和流处理。
示例:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Kafka流式SQL的用例
- 实时分析。监控用户活动、销售或物联网传感器数据,并在实时仪表板上查看。
- 数据转换。在数据流经Kafka主题时进行清洗、过滤或增强。
- 欺诈检测。实时识别可疑交易或模式。
- 动态警报。当达到特定阈值或条件时触发警报。
- 数据管道增强。将流与外部数据集合并,创建增强的数据输出。
Kafka流式SQL的优势
- 简化开发。许多开发人员熟悉SQL,降低学习曲线。
- 实时处理。实现对流数据的即时洞察和操作。
- 可伸缩性。利用Kafka的分布式架构确保可伸缩性。
- 集成。与现有基于Kafka的管道轻松集成。
挑战和注意事项
- 状态管理。复杂查询可能需要管理大状态,这可能会影响性能。
- 查询优化。确保查询高效以处理高吞吐量的数据流。
- 工具选择。根据您的需求(例如,延迟、复杂性)选择合适的SQL引擎。
- 容错性。流式SQL引擎必须处理节点故障并确保数据一致性。
结论
在Kafka上使用流式SQL使企业能够利用实时数据,同时保持SQL的简单性。像ksqlDB、Apache Flink和Spark结构化流处理这样的工具使得在没有深入编程专业知识的情况下构建强大、可扩展和低延迟的数据管道成为可能。
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka