













问题陈述
这个AI解决方案的“为什么”在多个领域中非常重要且普遍存在。
想象你有多个扫描的PDF文档:
- 客户进行一些手动选择,添加签名/日期/客户信息
- 你有多个已扫描的书面文件页面,希望解决方案能够从这些文件中获取文本
或者
- 你只是在寻找一个基于AI的途径,提供一种交互式机制来查询没有结构格式的文件
处理这些扫描的/混合的/非结构化的文件可能会很棘手,从它们中提取关键信息可能是手动操作,因此容易出错且繁琐。
下面的解决方案利用OCR(光学字符识别)和LLM(大型语言模型)的力量,以从这类文件中获取文本并查询以获取结构化且可信的信息。
高级架构
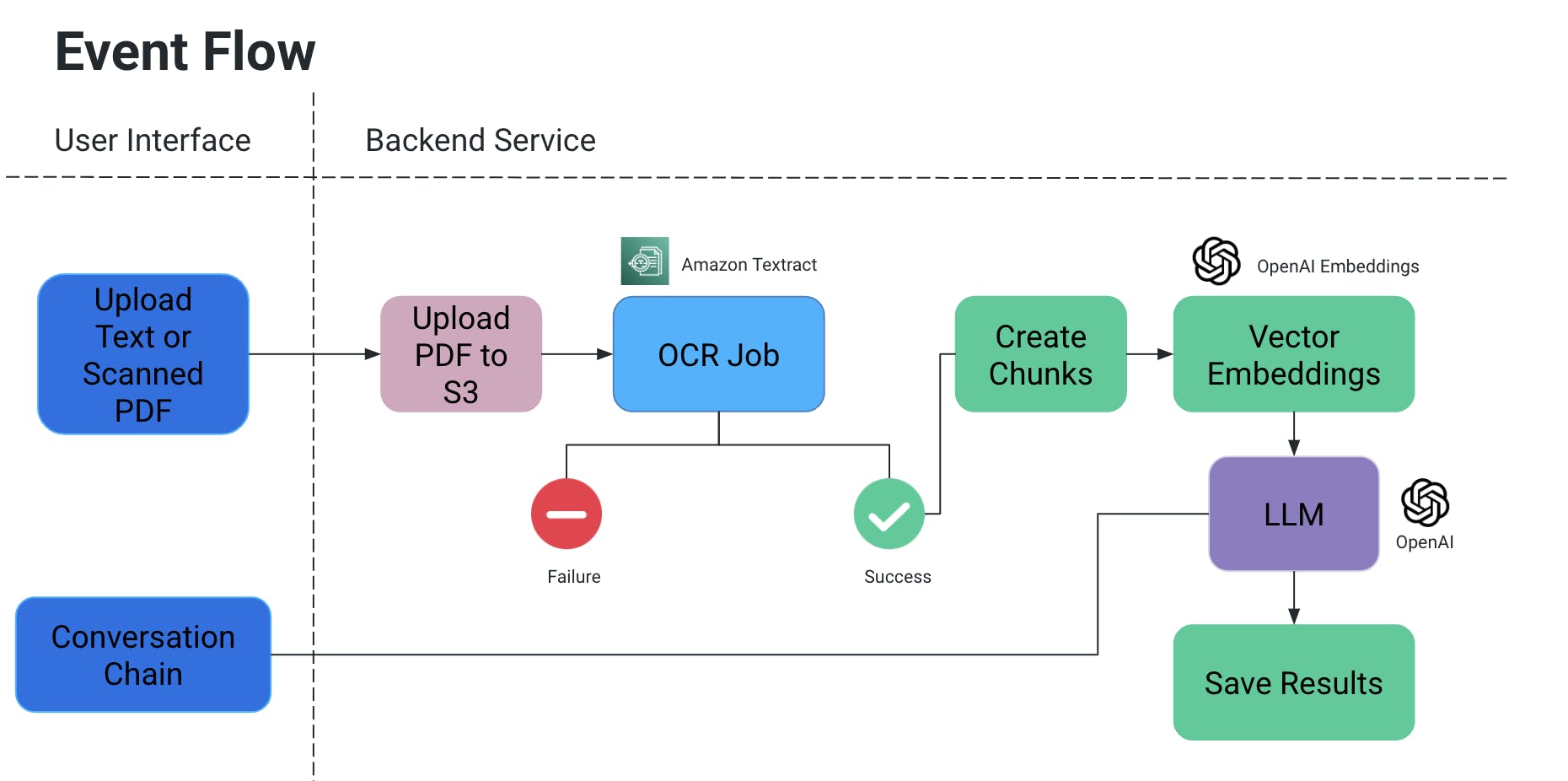
用户界面
- 用户界面允许上传PDF/扫描文档(还可以进一步扩展到其他文档类型)。
- Streamlit被用于用户界面:
- 这是一个开源的Python框架,非常易于使用。
- 随着更改的进行,它们会反映在正在运行的应用程序中,使其成为一种快速测试机制。
- Streamlit的社区支持相当强大且不断增长。
- 对话链:
- 这基本上是为了整合可以回答后续问题并提供聊天记录的聊天机器人。
- 我们利用LangChain来与我们使用的AI模型进行接口;针对这个项目,我们已经测试了OpenAI和Mistral AI。
后端服务
事件流程
- 用户上传一个PDF/扫描文档,随后该文档被上传到一个S3存储桶中。
- 一个OCR服务然后从这个S3存储桶中检索该文件,并处理它以从该文档中提取文本。
- 从上述输出创建文本片段,并为它们创建相关的向量嵌入。
- 现在这是非常重要的,因为当文本片段被分割时,你不希望失去上下文:它们可能会在句子中间被分割,如果没有一些标点符号,意思可能会丢失,等等。
- 因此,为了抵消这一点,我们创建了重叠的文本片段。
- 我们使用的这个大型语言模型将这些嵌入作为输入,并且我们有两个功能:
- 生成特定输出:
- 如果我们需要从文档中提取特定类型的信息,我们可以在代码中提供查询给AI模型,获取数据,并以结构化格式存储它。
- 通过显式地在代码查询中添加条件,避免AI虚构某些值,只使用文档的上下文。
- 我们可以将其作为S3/本地文件存储,或者写入数据库。
- 聊天
- 在这里,我们提供了用户与AI聊天以在文档的上下文中获取特定信息的途径。
- 生成特定输出:
OCR任务
- 我们使用亚马逊Textract对这些文档进行光学识别。
- 它非常适合同时具有表格/表单等文档。
- 如果在进行POC,请利用这个服务的免费层。
向量嵌入
- 理解向量嵌入的一个非常简单的方法是将单词或句子翻译成数字,这些数字捕捉了此上下文的含义和关系
- 想象你有一个单词“ring”,它是一种装饰品:就单词本身而言,它的一个接近的匹配是“sing”。但从单词的含义来看,我们希望它与“jewelry”(珠宝),“finger”(手指),“gemstones”(宝石)等匹配,或许还有像“hoop”(圆环),“circle”(圆)等。
- 因此,当我们创建“ring”的向量嵌入时,我们基本上是在填充它,包含了关于其含义和关系的大量信息。
- 这些信息与文档中其他单词/语句的向量嵌入一起,确保了根据上下文正确选择单词“ring”的含义。
- 我们使用了OpenAIEmbeddings来创建向量嵌入。
LLM
- 有多个大型语言模型可用于我们的场景。
- here 阅读更多OpenAI的 API 密钥
- 对于MistralAI,我们使用了HuggingFace。
用例和测试
我们进行了以下测试:
- 使用 OCR 阅读签名和手写日期/文本。
- 在文档中手选选项
- 在文档顶部进行数字选择
- 解析非结构化数据以获取表格内容(添加到文本文件/数据库等)
未来范围
我们可以进一步扩大上述项目的应用范围,以整合图像,与文档存储如Confluence/Drive等整合,从多个来源提取有关特定主题的信息,为比较分析两篇文档提供更强大的途径等。
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data