













SOLAR-10.7B 项目代表了大型语言模型开发中的重要飞跃,介绍了一种有效且高效地扩展这些模型的新方法。
本文首先解释了什么是 SOLAR-10.7B 模型,然后重点介绍了它相对于其他大型语言模型的性能,并深入探讨了使用其专门微调版本的过程。最后,读者将了解微调后的 SOLAR-10.7B-Instruct 模型的潜在应用及其局限性。
什么是 SOLAR-10.7B?
SOLAR-10.7B 是由韩国 Upstage AI 团队开发的一个拥有 107 亿参数的模型。
基于 Llama-2 架构,这个模型超过了其他拥有高达 300 亿参数的大型语言模型,包括 Mixtral 8X7B 模型。
要了解更多关于 Llama-2 的信息,我们的文章 微调 LLaMA 2:定制大型语言模型的逐步指南 提供了一个逐步指导,使用新方法克服内存和计算限制,以更好地访问开源的大型语言模型。
此外,基于 SOLAR-10.7B 的强大基础,SOLAR-10.7B-Instruct 模型通过强调遵循复杂指令进行微调。这一变体展示了增强的性能,展示了模型的适应性以及微调在实现专业目标方面的有效性。
最后,SOLAR-10.7B引入了一种称为深度扩展的方法,让我们在接下来的章节中进一步探索。
深度扩展方法
这种创新方法允许在不增加相应计算资源的情况下扩展模型的神经网络深度。这种策略提高了模型的效率和整体性能。
深度扩展的关键要素
深度扩展基于三个主要组件:(1)Mistral 7B权重,(2)Llama 2框架,(3)连续预训练。
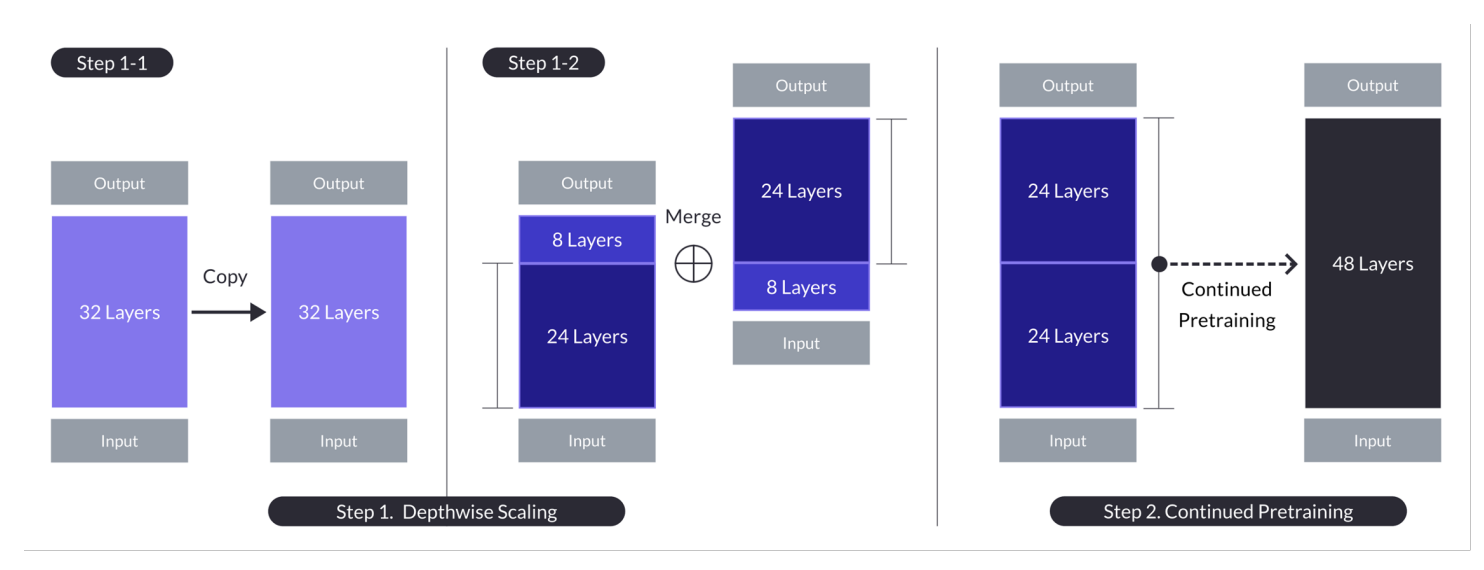
当n = 32,s = 48,m = 8时,深度扩展的情况。深度扩展通过先进行深度扩展然后继续预训练的双阶段过程实现。(来源)
基础模型:
- 使用一个32层的变压器架构,特别是Llama 2模型,初始化带有来自Mistral 7B的预训练权重。
- 由于其兼容性和性能而被选择,旨在利用社区资源并引入新的修改以增强功能。
- 为深度扩展和进一步预训练提供了基础,以便有效地扩大规模。
深度扩展:
- 通过考虑硬件能力为扩展模型设置目标层数,来扩展基础模型。
- 涉及到复制基础模型,从原始模型中移除最后的m层,从复制品中移除最初的m层,然后将它们连接起来形成一个具有s层的模型。
- 这个过程创建了一个缩放模型,通过调整层数以适应介于70亿到130亿个参数之间,特别使用n=32层的基础模型,移除m=8层以实现s=48层。
继续预训练:
- 通过继续对缩放模型进行预训练来解决深度缩放后初始性能下降的问题。
- 在继续预训练期间,观察到性能迅速恢复,这归因于减少模型中的异质性和不一致性。
- 继续预训练对于恢复并可能超越基础模型的性能至关重要,利用深度缩放模型的架构进行有效的学习。
这些总结突出了深度上缩放方法的关键策略和成果,重点是利用现有模型,通过深度调整进行缩放,并通过继续预训练提高性能。
这种多方面的方法SOLAR-10.7B在许多情况下实现了,并且在许多情况下超过了更大模型的能力。这种效率使其成为一系列特定应用的首选,展示了其强大和灵活性。
SOLAR 10.7B指令模型是如何工作的?
SOLAR-10.7B指令擅长解释和执行复杂指令,使其在需要精确理解和响应人类命令的重要场景中极具价值。这一能力对于开发更加直观和互动的AI系统至关重要。
- SOLAR 10.7B指令版是通过微调原始的SOLAR 10.7B模型来遵循QA格式的指令而得到的。
- 微调主要使用开源数据集以及合成的数学QA数据集来增强模型的数学技能。
- SOLAR 10.7B指令版的第一版通过整合Mistral 7B权重来增强其学习能力,以有效地进行信息处理。
- SOLAR 10.7B的骨干是Llama2架构,它提供了速度和准确性的结合。
总的来说,微调后的SOLAR-10.7B模型的价值在于其提高的性能、适应性和广泛应用的潜力,推动了自然语言处理和人工智能领域的发展。
微调后SOLAR-10.7B模型的潜在应用
在深入技术实现之前,让我们探索一些微调后SOLAR-10.7B模型的潜在应用。
以下是一些个性化教育和辅导、增强客户支持以及自动化内容创作的示例。
- 个性化教育和辅导:SOLAR-10.7B-Instruct可以通过提供个性化的学习体验来革新教育领域。它能够理解复杂的的学生问题,提供定制的解释、资源和练习。这种能力使它成为开发适应个人学习风格和需求的智能辅导系统的理想工具,从而提高学生的参与度和成果。
- 更优质的客户支持:SOLAR-10.7B-Instruct可以驱动高级聊天机器人和虚拟助手,能够理解和准确解决复杂的客户咨询。这种应用不仅通过提供及时和相关的支持来改善客户体验,还通过自动化常规查询来减轻人工客户服务代表的工作负担。
- 自动化内容创建和总结:对于媒体和内容创作者来说,SOLAR-10.7B-Instruct提供了自动化生成文字内容的能力,比如新闻文章、报告和创意写作。此外,它还可以将详尽文档总结成简洁易懂的格式,这对于记者、研究人员和专业人士来说非常有价值,因为他们需要快速吸收和报告大量信息。
这些示例凸显了SOLAR-10.7B-Instruct的多功能和潜力,它能够影响和提高各行各业中的效率、可访问性和用户体验。
使用SOLAR-10.7B指导的逐步指南
我们已经足够了解SOLAR-10.7B模型,现在该是我们亲自动手的时候了。
这部分旨在提供从upstage运行SOLAR 10.7 Instruct v1.0 – GGUF模型的全部指令。
代码灵感来源于Hugging Face上的官方文档。主要步骤如下:
- 安装并导入必要的库
- 从Hugging Face定义要使用的SOLAR-10.7B模型
- 运行模型推断
- 根据用户请求生成结果
库安装
主要使用的库是transformers和accelerate。
- transformers库提供了访问预训练模型的功能,这里指定的版本是4.35.2。
- accelerate库旨在简化在不同硬件(CPU、GPU)上运行机器学习模型的流程,无需深入了解硬件的具体情况。
%%bash pip -q install transformers==4.35.2 pip -q install accelerate
导入库
安装完成后,我们继续导入以下必要的库:
- torch是PyTorch库,这是一个流行的开源机器学习库,用于计算机视觉和NLP等应用。
- AutoModelForCausalLM用于加载预训练的因果语言建模模型,而AutoTokenizer负责将文本转换成模型可以理解的形式(分词)。
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
GPU配置
正在使用的模型是 Hugging Face 的 SOLAR-10.7B 模型的第 1 版。
需要 GPU 资源来加速模型加载和推理过程。
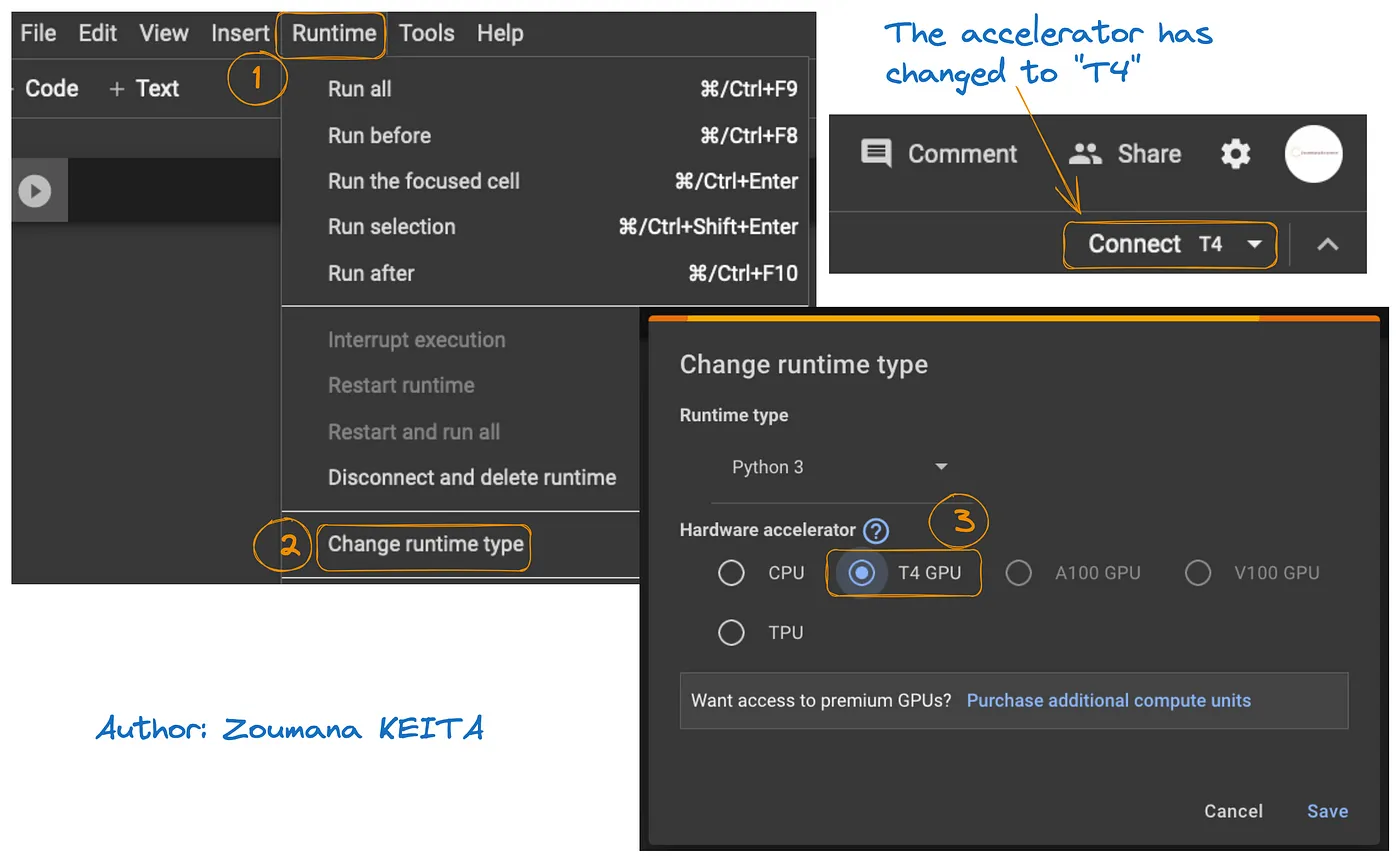
下图说明了在 Google Colab 上访问 GPU 的方法:
- 在 运行时 选项卡中,选择 更改运行时
- 然后,在硬件加速器部分选择 T4 GPU 并 保存 更改
这样会将默认运行时切换到 T4:
我们可以通过在 Colab 笔记本中运行以下命令来检查运行时的属性。
!nvidia-smi
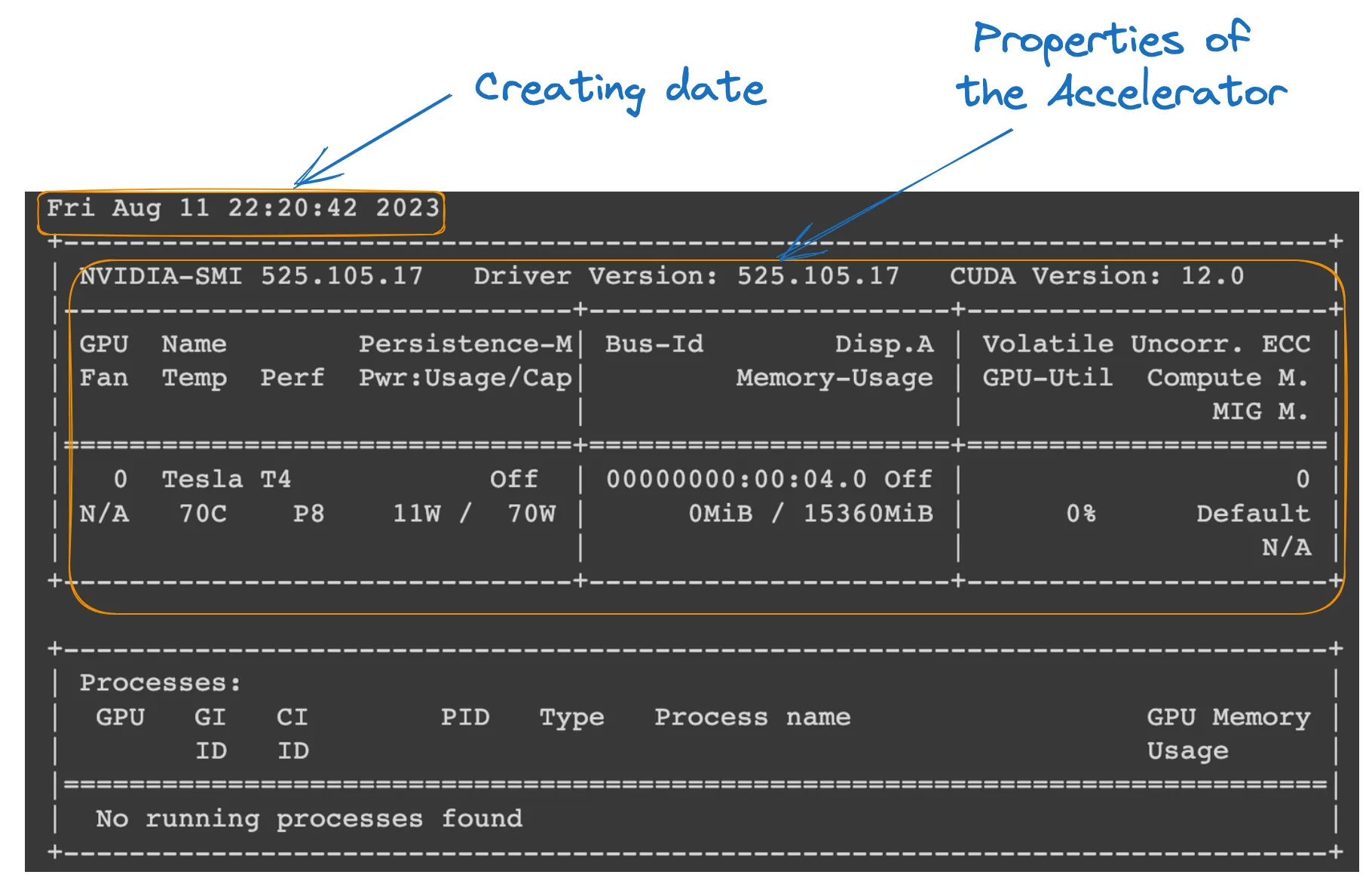
GPU 属性
模型定义
一切都已设置好;我们可以继续按如下方式加载模型:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained( model_ID, device_map="auto", torch_dtype=torch.float16, )
- model_ID 是唯一标识我们要使用的预训练模型的字符串。在这种情况下,指定 “Upstage/SOLAR-10.7B-Instruct-v1.0”。
- AutoTokenizer.from_pretrained(model_ID) 加载在指定 model_ID 上预训练的分词器,准备处理文本输入。
- AutoModelForCausalLM.from_pretrained() 加载因果语言模型,使用 device_map=”auto” 自动使用最佳可用硬件(我们已设置的 GPU),并且 torch_dtype=torch.float16 使用 16 位浮点数以节省内存并可能加速计算。
模型推理
在生成响应之前,输入文本(用户请求)会被格式化和分词。
- 用户请求包含模型的疑问或输入。
- 对话将输入格式化为对话的一部分,并标记角色(例如,“用户”)。
- 应用聊天模板将输入应用到对话模板中,以模型能够理解的方式准备输入。
- tokenizer(prompt, return_tensors=”pt”)将提示转换为令牌,并指定张量类型(”pt” 为 PyTorch 张量),而.to(model.device)确保输入与模型所在的设备(CPU 或 GPU)相同。
user_request = "What is the square root of 24?" conversation = [ {'role': 'user', 'content': user_request} ] prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True) inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
结果生成
最后部分使用模型根据输入问题生成回复,然后解码并打印生成的文本。
- model.generate()根据提供的输入生成文本,使用 use_cache=True 来通过复用之前计算的结果来加速生成。max_length=4096 限制了生成的文本的最大长度。
- tokenizer.decode(outputs[0])将生成的令牌转换回人类可读的文本。
- print 语句显示了对用户问题的生成回答。
outputs = model.generate(**inputs, use_cache=True, max_length=4096) output_text = tokenizer.decode(outputs[0]) print(output_text)
上述代码的成功执行生成了以下结果:

通过将用户请求替换为以下文本,我们可以得到生成的回复
user_request = "Tell me a story about the universe"

SOLAR-10.7B 模型的局限性
尽管SOLAR-10.7B模型具有许多优势,但它像任何其他大型语言模型一样,也有自己的局限性,主要体现在以下几个方面:
- 彻底的超参数探索:模型在进行深度扩展(DUS)时需要更彻底地探索超参数,这是一个关键的局限性。这导致了由于硬件限制,去除了基准模型中的8层。
- 计算要求高:该模型的计算资源需求显著,这限制了计算能力较低的个人和组织使用该模型。
- 偏见漏洞:训练数据中可能存在的偏见可能会影响模型在某些使用场景下的表现。
- 环境担忧:模型的训练和推理需要大量的能源消耗,这可能会引起环境担忧。
结论
本文探讨了SOLAR-10.7B模型,通过深度扩展方法突出了它在人工智能领域的贡献。本文概述了模型的运作方式和潜在应用,并提供了从安装到生成结果的实际使用指南。
尽管具有强大的功能,但本文也关注了SOLAR-10.7B模型的局限性,为用户提供了一个全面的视角。随着AI的不断发展,SOLAR-10.7B代表了朝着更易于访问和多功能的AI工具所取得的进步。
对于那些想要深入了解AI潜力的人来说,我们的教程FLAN-T5教程:指南和微调,为您提供了使用transformers库对FLAN-T5模型进行微调以用于问答任务的完整指南,并在现实世界场景中运行优化推理。您还可以找到我们的Fine-Tuning GPT-3.5教程和我们一起微调您自己的LlaMA 2模型的编码教程。
Source:
https://www.datacamp.com/tutorial/solar-10-7b-fine-tuned-model-tutorial