













Сегодня организации должны рационально использовать хранилища из-за того, что крупные объемы данных могут увеличить затраты на хранение и привести к увеличению дубликатов данных.
Медиа хранения данных различаются по стоимости, скорости записи/чтения и другим показателям, поэтому разные типы данных должны храниться на наиболее эффективных носителях, чтобы сэкономить затраты и ресурсы.
Например, хранение резервных копий на устройствах сольных состояний твердотельных накопителей (SSD) с высокой скоростью излишне затратно, поскольку высокая скорость SSD не требуется для этого типа вторичных данных. В то же время хранение виртуальных машин (ВМ) производства на жестких дисках (HDD) с низкой частотой вращения (RPM) может быть бюджетно-дружественным, но не соответствовать требованиям производительности для основных систем.
Поэтому типы хранения должны классифицироваться для использования каждого типа хранения для хранения соответствующих данных с помощью слоев хранения.
Что такое слои хранения?
Слои хранения – это стратегия управления данными хранения, используемая для оптимизации производительности и стоимости эффективности системы хранения данных за счет категоризации данных в разные уровни на основе их характеристик и образцов доступа.
Начальная ступенчатая классификация данных начинается с классификации данных по разным категориям или уровням на основе критериев, таких как частота доступа, важность и требования к производительности. Эта классификация может изменяться со временем, если рабочий процесс этого требует. Количество и типы уровней хранения могут варьироваться – от 3 до 7 – в зависимости от инфраструктуры хранения.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
Классы данных для ступенчатого хранения
Классы данных в архитектуре ступенчатого хранения относятся к категоризации или классификации данных на основе конкретных атрибутов или характеристик. Эти классы создают иерархию данных и помогают определить, где данные должны храниться в ступенчатой системе хранения. Такой подход обеспечивает размещение данных на наиболее подходящем уровне хранения для сбалансированности производительности, стоимости и доступности. Конкретные характеристики классов данных могут варьироваться в зависимости от потребностей организации и инфраструктуры хранения. Общие атрибуты, используемые для классификации данных, включают:
- Частота доступа. Одним из основных критериев классификации данных является частота доступа к ним пользователями и приложениями. Данные, которые регулярно и активно используются (горячие данные), должны храниться на высокопроизводительных уровнях хранения, таких как SSD или диски NVMe, чтобы обеспечить быстрое время доступа. В отличие от этого, редко используемые данные (холодные данные) могут быть размещены на более дешевых уровнях хранения, таких как HDD или хранилища в облаке.
- Критичность или важность. Некоторые данные более критичны для операций организации или требований соответствия, чем другие. Критические данные могут требовать хранения на более надежных и устойчивых уровнях хранения, таких как RAID (избыточный массив независимых дисков) или облачное хранилище с избыточностью, для минимизации риска потери данных.
- Тип данных. Различные типы данных, такие как файлы баз данных, мультимедийный контент, логи приложений или архивные документы, могут иметь различные требования к хранению. Например, мультимедийные файлы могут требовать высокой пропускной способности и емкости, в то время как логи могут храниться на более медленном хранилище, пока они сохраняются в целях соответствия.
- Период хранения. Данные с определенными требованиями к хранению или соответствию могут требовать хранения на уровнях, которые гарантируют целостность и доступность данных в течение необходимого периода. Данные соответствия часто требуют длительного хранения и, следовательно, их можно хранить на более надежных уровнях хранения.
- Размер. Большие объемы данных могут выиграть от хранения на уровнях хранения, оптимизированных для емкости, в то время как малые, часто используемые данные могут требовать хранения с низкой задержкой и высокой производительностью ввода-вывода.
- Жизненный цикл данных. Данные проходят через различные этапы своего жизненного цикла, от создания и активного использования до архивирования или удаления. Классы данных должны учитывать эти этапы и перемещать данные между уровнями по мере необходимости. Например, новые данные могут начинаться на уровне высокой производительности, но постепенно перемещаться на более дешевые уровни по мере уменьшения активности.
- Чувствительность к затратам. Организации часто имеют ограничения бюджета. Классы данных могут помочь согласовать затраты на хранение данных с бюджетными соображениями, обеспечивая резервирование более дорогих ресурсов хранения для данных, которые обосновывают стоимость.
- Требования пользователя или приложения. Различные пользователи или приложения могут иметь конкретные потребности в хранении. Классы данных могут учитывать эти требования, чтобы гарантировать, что каждая группа получает необходимую производительность и емкость хранения.
После классификации данных в эти классы применяются политики и алгоритмы для управления размещением и перемещением данных внутри структуры хранения с разделением на уровни. Это гарантирует, что данные непрерывно оптимизируются с точки зрения производительности и эффективности затрат, при этом удовлетворяя организационные потребности и шаблоны доступа.
Классификация с горячим, теплым и холодным хранением
Обычный тип классификации данных в системах с разделением на уровни – это классификация данных как критически важных, горячих, теплых и холодных. Эти классы помогают определить, как данные хранятся, управляются и получают доступ внутри структуры хранения. В этом случае классы данных, используемые в стратегиях с разделением на уровни хранения, включают:
- Критически важные данные. Этот класс данных относится к данным, которые абсолютно необходимы для основных операций организации. Критически важные данные требуют высшего уровня производительности, надежности и доступности. Обычно они хранятся на наиболее надежных и высокопроизводительных носителях хранения, таких как резервированные массивы SSD или системы хранения с повышенной стойкостью к отказам.
- Горячие данные. Горячие данные относятся к данным, к которым активно и часто обращаются. Эти данные обычно имеют большое значение для организации и требуют быстрых времен ответа и высокопроизводительного хранилища. Горячие данные часто хранятся на носителях самого высокого уровня, таких как твердотельные накопители (SSD) или диски NVMe, чтобы обеспечить низкую задержку и быстрый доступ.
- Теплые данные. Теплые данные представляют собой данные, к которым обращаются реже, чем к горячим данным, но они все еще активно используются. Этот класс данных обычно находится на уровне ниже горячих данных по производительности, таких как высокопроизводительные жесткие диски (HDD) или гибридные решения хранения. Хотя теплые данные могут не требовать самого быстрого хранилища, они все равно должны быть доступны для эффективного доступа.
- Холодные данные. Холодные данные включают в себя данные, к которым редко обращаются, исторические или архивные. Эти данные часто считаются менее важными и хранятся на носителях более низкой стоимости, которые могут быть традиционными, медленными HDD или даже опциями хранения для архивов, такими как ленты или облачное хранилище для холодных данных. Основное внимание при работе с холодными данными уделяется их долгосрочному сохранению и снижению затрат.
Количество классов данных может зависеть от количества уровней хранения в модели классификации хранилища. Организации могут классифицировать данные более сложным образом, используя следующие классы данных в дополнение к описанным выше классам:
- Резервное копирование и восстановление данных. Данные, используемые для резервного копирования и восстановления после катастрофы, часто классифицируются отдельно. Эти классы данных направлены на обеспечение надежного и быстрого восстановления данных в случае их потери или сбоя системы. Данные резервного копирования могут храниться на дисковых системах, в то время как копии для долгосрочного хранения могут быть сохранены на ленте или в облаке.
- Данные соответствия требованиям по соблюдению. Данные, которые должны соответствовать требованиям регулятивного соответствия, такие как финансовые записи или данные о здравоохранении, могут иметь специфические потребности в хранении. Классы данных соответствия обеспечивают сохранность этих данных с помощью функций, таких как шифрование и строгие контроли доступа, и сохранение их на необходимый срок.
- Пользовательские или отделочные данные. Некоторые организации классифицируют данные на основе их источника, такого как данные, сгенерированные определенными отделами или пользователями. Этот подход может помочь распределить ресурсы хранения в соответствии с потребностями различных организационных подразделений.
- Временные или кэш-данные. Классы данных для временных или кэш-данных могут включать данные, которые существуют недолго и могут храниться на скоростных уровнях хранения для быстрого доступа, с пониманием того, что они могут быть удалены или заменены, когда больше не нужны.
Данные миграции уровней . В некоторых случаях классы данных используются для идентификации данных, которые активно перемещаются между уровнями хранения на основе образцов доступа. Например, данные, которые сначала являются актуальными, но со временем используются реже, могут мигрировать на более теплые или холодные уровни хранения. - Данные миграции уровней. В некоторых случаях классы данных используются для идентификации данных, которые активно перемещаются между уровнями хранения на основе паттернов доступа. Например, данные, которые начинаются как горячие, но со временем становятся менее часто используемыми, могут мигрировать на более теплые или холодные уровни хранения.
Эти классы данных могут служить руководством для администраторов хранения и автоматизированных систем управления хранилищами для принятия обоснованных решений о том, где разместить данные в инфраструктуре хранения с несколькими уровнями.
Типы многоуровневого хранения
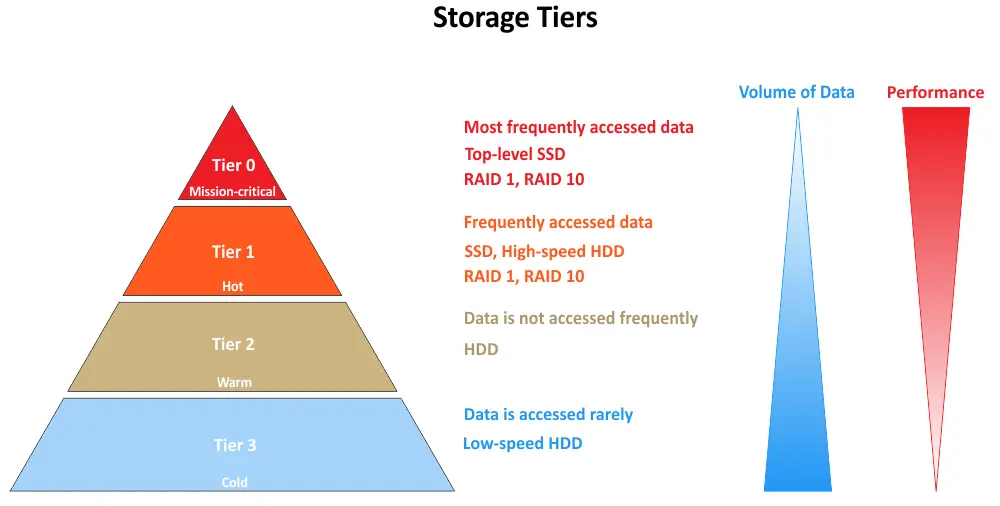
Многоуровневое хранилище относится к архитектуре хранения, где данные классифицируются на разные уровни на основе требований к производительности и доступности. Каждый уровень представляет собой определенный уровень производительности хранения и стоимости. Цель состоит в том, чтобы обеспечить хранение данных на самом подходящем уровне для оптимизации как производительности, так и эффективности затрат. Ниже вы можете увидеть распространенные уровни хранения, начиная с Tier 0:
- Уровень 0 представляет собой самый высокопроизводительный уровень хранения в многоуровневой системе хранения. Часто он состоит из самых быстрых и дорогих носителей хранения, таких как твердотельные накопители (SSDs) класса enterprise или NVMe (Non-Volatile Memory Express) SSDs. Данные, хранящиеся на уровне 0, обычно являются критически важными для бизнеса и требуют чрезвычайно низкой задержки, высокой производительности ввода-вывода и быстрого доступа к данным. Он используется для приложений и данных, которые требуют самых высоких уровней производительности.
- Уровень 1 – это следующий уровень вниз в плане производительности и стоимости. Он обычно состоит из высокопроизводительных жестких дисков (HDD), гибридных массивов хранения (объединяющих SSD и HDD) или более быстрых SSD, которые не так дороги, как те, что в Уровне 0. Данные на Уровне 1 важны, но могут не требовать абсолютно самого быстрого хранения, доступного на рынке. Этот уровень подходит для приложений и данных, которым нужна хорошая производительность, но они могут терпеть несколько более высокую задержку по сравнению с данными Уровня 0.
- Уровень 2 представляет собой уровень хранения с более низкой стоимостью и немного более медленной производительностью по сравнению с Уровнем 1. Часто он включает в себя традиционные HDD или облачные решения для хранения. Данные на Уровне 2 обычно доступны реже или менее критичны для операций в реальном времени. Этот уровень подходит для архивных данных, резервных копий и данных, которые могут терпеть более длительные времена доступа.
- Уровень 3 является самым низким уровнем стоимости хранения в многоуровневой системе хранения. Он обычно включает в себя архивные решения для хранения, такие как библиотеки лент и облачные холодные хранилища. Данные на Уровне 3 редко доступны и в основном хранятся для обеспечения соответствия, регулирования или долгосрочного архивирования. Он предлагает наименьшую производительность, но самые экономичные условия хранения.
Некоторые организации, использующие в основном локальное хранилище, выделяют дополнительные специальные уровни для хранения в публичном облаке и резервном хранении:
- Облачное уровневое хранилище. В некоторых многоуровневых архитектурах хранения используется отдельный Облачный уровень, предназначенный для хранения данных в облачных сервисах хранения, таких как Amazon S3 или Azure Blob Storage. Это позволяет организациям использовать масштабируемое и экономичное облачное хранилище для данных, которые могут не вписываться в локальные уровни. Данные в облачном уровне могут быть доступны через интернет при необходимости.
- Уровень резервного копирования. Хотя резервное хранилище не всегда считается основным уровнем хранения, оно является важной частью иерархии хранения. Резервные данные хранятся на системах на основе дисков или в библиотеках лент, в зависимости от стратегии резервного копирования организации. В фокусе находится защита данных и быстрое восстановление в случае потери данных или катастроф.
Сколько уровней обычно используют организации?
Количество уровней, используемых организациями в своих архитектурах хранения, может сильно варьироваться в зависимости от их конкретных потребностей, ограничений бюджета и сложности требований к управлению данными. Однако на практике многие организации обычно начинают с трехуровневой иерархии хранения (Уровень 0, Уровень 1, Уровень 2) в качестве отправной точки.
Многие организации начинают с этих трех уровней в качестве основы и затем настраивают свою инфраструктуру хранения для удовлетворения своих специфических потребностей. Они могут добавлять дополнительные уровни или принимать специализированные классы хранения по мере развития своих потребностей в данных. Например:
- Некоторые организации могут добавить уровень 4 или уровень 5 для долгосрочного, глубокого архивирования, которое может включать технологии, такие как библиотеки лент или очень дешевое облачное хранилище.
- Другие могут внедрить облачный уровень для удаленных резервных копий и целей аварийного восстановления, используя облачные хранилищы услуг, такие как Amazon S3 или Azure Blob Storage.
- Гибридные облачные стратегии также могут вводить больше уровней, включая облачные уровни данных, которые должны быть бесшовно перемещены между локальными и облачными хранилищами.
Ключ состоит в том, чтобы разработать архитектуру хранения, которая соответствует паттернам доступа к данным, требованиям производительности и бюджетным соображениям организации. Также важно реализовать эффективные политики управления данными и иерархии, чтобы обеспечить хранение данных на соответствующем уровне на основе изменяющихся потребностей этих данных со временем. Поскольку технологии хранения данных продолжают развиваться, организации могут корректировать свои стратегии иерархического хранения, чтобы воспользоваться новыми инновациями и экономичными решениями.
Эти общие уровни хранения можно суммировать в таблице с краткими объяснениями и типичными случаями использования:
| Номер уровня | Название уровня | Объяснение | Типичные области применения |
| Уровень 0 | Ультра-быстрый SSD | Наивысшая производительность хранилища, низкая задержка | Критические базы данных, реально-временные приложения |
| Уровень 1 | Высокопроизводительный SSD | Хороший баланс скорости и стоимости | Общее прикладное программное обеспечение данных, виртуальные машины |
| Уровень 2 | Гибридное хранилище | Смесь SSD и HDD, экономичное | Хранение резервных копий, вторичные данные, общие файлы |
| Уровень 3 | Хранение данных на ближних дисках | Хранение резервных копий, вторичные данные, общие файлы | Архивные данные, долгосрочное хранение |
| Уровень 4 | Холодное хранение | Низкая стоимость, очень высокая емкость, медленный доступ | Редко используемые архивные данные |
| Облачный уровень | Облачное хранилище | Масштабируемое облачное хранилище | Отложенные резервные копии, аварийное восстановление, обмен данными |
Обратите внимание, что названия и характеристики уровней хранения могут различаться между организациями и поставщиками хранилищ. Вышеприведенная таблица дает общее представление о распространенных уровнях хранения и их типичных областях применения, однако конкретные реализации могут отличаться в зависимости от потребностей организации и доступных технологий.
Где используются уровни хранения
Термином “хранилище уровней” обозначается стратегия управления хранилищем, которая может использоваться как на месте (в собственных дата-центрах организации или в частных облачных средах), так и в публичном облаке. Это гибкий подход, который может быть применен к различным архитектурам хранения для оптимизации размещения данных и паттернов доступа.
Хранение данных на разных уровнях на собственной территории
Хранение данных на разных уровнях используется в следующих средах, ориентированных на локальные (собственные) инфраструктуры:
- Традиционные центры обработки данных. В традиционных локальных центрах обработки данных хранение данных на разных уровнях часто используется для управления данными, хранящимися на различных типах носителей, таких как SSD, HDD и библиотеки лент. Организации внедряют хранение данных на разных уровнях для оптимизации производительности, затрат и доступности данных в своей собственной инфраструктуре.
- Частные облака. Многие частные облачные среды включают хранение данных на разных уровнях для эффективного управления данными на разных типах хранилищ. Это особенно важно в частных облачных настройках, где ресурсы должны динамически распределяться для поддержки различных рабочих нагрузок.
- Гибридные облака. В гибридной облачной среде, которая объединяет локальную инфраструктуру с ресурсами публичного облака, хранение данных на разных уровнях может использоваться для оптимизации размещения данных в обеих средах. Организации могут использовать политики хранения на разных уровнях для определения того, какие данные должны находиться на собственной территории, а какие – перенесены в публичное облако для экономии затрат или масштабируемости.
Хранение данных на разных уровнях в публичном облаке
Что касается публичного облака, хранение данных на разных уровнях используется в следующих средах:
- Облачные сервисы хранения данных. Облачные провайдеры, такие как Amazon Web Services (AWS), Microsoft Azure и Google Cloud Platform (GCP), предлагают свои собственные варианты иерархии хранения облака в рамках своих облачных сервисов хранения данных. Например, AWS предлагает классы хранения S3 (Standard, Intelligent-Tiering, Glacier и др.), каждый из которых предназначен для разных требований к производительности и стоимости.
- Объектное хранение. Объектное хранение в публичном облаке часто поддерживает иерархию хранения, что позволяет клиентам выбирать наиболее подходящий класс хранения для своих данных. Это полезно для оптимизации затрат и времени доступа.
Автоматическая иерархия хранения
Автоматическая иерархия хранения и оптимизация иерархии хранения – это методы, используемые в современном управлении данными для обеспечения того, чтобы данные размещались на наиболее подходящем уровне хранения эффективно и в нужный момент.
Автоматическая иерархия хранения – это метод управления данными, который включает автоматическое и динамическое перемещение данных между разными уровнями хранения на основе определенных политик и критериев. Эти политики обычно определяются администраторами хранения или устанавливаются с помощью интеллектуального программного обеспечения управления хранилищами. Основная цель автоматической иерархии хранения – оптимизировать использование ресурсов хранения, обеспечивая хранение данных на наиболее подходящем уровне в любой момент времени.
Автоматическое распределение хранения позволяет динамически оптимизировать ваше распределение хранения, постоянно отслеживая использование данных и доступ к ним, чтобы определить приоритеты данных и требуемые уровни распределения. Когда вы используете автоматическое хранение, вы устанавливаете свои предпочтительные пороги, и автоматизация занимается остальным.
Когда использование данных достигает предварительно определенных порогов, оно перемещается соответствующим образом. Если частота доступа к данным увеличивается, они перемещаются на уровень с меньшей задержкой. Когда данные не используются, они перемещаются на более дешевый, с большей задержкой уровень. Этот подход оптимизирует как ваши затраты, так и производительность с минимальными усилиями и без необходимости постоянного обслуживания.
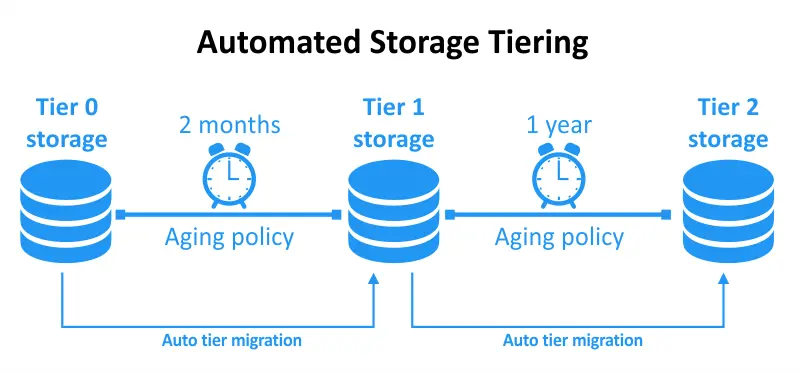
Автоматическое распределение хранения облегчает политикой управляемые передачи данных между уровнями хранения, тем самым соответствуя потребностям пользователя в производительности и емкости. Эта функция эффективно работает с вашей существующей архитектурой распределенного хранения и упрощает управление данными через автоматизацию. Автоматическое распределение хранения улучшает оптимизацию производительности и стоимостную эффективность благодаря реальному времени настройки и быстрого перемещения данных.
Уровень храненияоптимизация – более широкий концепт, который включает в себя различные стратегии, включая автоматическийраспределение хранения, чтобы гарантировать, что инфраструктура хранения организации эффективно управляется и используется. В то время как автоматическое распределение хранения является ключевой составляющей оптимизации уровней хранения, могут быть также задействованы другие методы и лучшие практики.
Распределение уровней против кэширования
Тарификация и кэширование – это две различные техники, используемые в хранении и управлении данными – они служат разным целям. Термины тарификация и кэширование часто путают друг с другом, но они относятся к двум разным техникам ускорения хранения. Обе включают размещение часто используемых или горячих данных на высокоскоростных носителях, таких как флеш-память. Однако сходства в основном заканчиваются здесь.
Кэширование временно хранит данные на высокопроизводительном носителе, таком как DRAM или твердотельная память, для повышения производительности. Кэш находится между приложением и базовым хранилищем. Такие же данные также находятся на более низком уровне хранения, обычно на HDD. Данные копируются в кэш, но оригинальные данные остаются в своем первоначальном месте. Кэширование по сути является односторонней транзакцией, и кэш аннулирует данные после использования.
Тарификация хранилища, с другой стороны, физически перемещает данные между устройствами хранения. Когда данные идентифицируются как горячие, эти данные перемещаются на высокоскоростной уровень, что делает стандартный уровень лишенным копии. Когда данные остывают, их перемещают обратно на стандартный уровень. Тарификация хранилища включает перемещение данных, а не просто копирование их, как от медленного хранения к быстрому, так и наоборот.
И тарификация хранилища, и кэширование улучшают доступность данных, но они различаются в том, как они используют хранилище для часто используемых данных. Кэширование создает копии, тогда как тарификация хранилища идентифицирует данные и перемещает их без создания дополнительных копий.
Таким образом, уровень фокусируется на оптимизации долгосрочного размещения данных на разных уровнях хранения для достижения баланса между производительностью и стоимостью, в то время как кэширование направлено на ускорение доступа к данным путем временного хранения часто используемых данных в высокоскоростном буфере. Выбор между уровнями и кэшированием зависит от конкретных требований приложения или системы хранения и природы паттернов доступа к данным. В некоторых случаях организации могут использовать обе техники в сочетании для достижения наилучшей общей производительности и эффективности затрат.
Уровень хранения и иерархическое управление хранилищем
Уровень хранения и иерархическое управление хранилищем – обе стратегии используются в управлении данными, но они различаются по своей тонкости, механизмам перемещения данных и основным целям. Уровень хранения фокусируется на категоризации данных на дискретные уровни носителей данных на основе характеристик, в то время как иерархическое управление хранилищем фокусируется на прозрачной миграции отдельных файлов или объектов между первичным и вторичным хранилищем для повышения эффективности первичного хранилища и экономии затрат.
Преимущества хранения по уровням
Хранение по уровням предлагает несколько значительных преимуществ для организаций, стремящихся оптимизировать свою инфраструктуру хранения данных. Основными преимуществами внедрения хранения по уровням являются:
- Улучшенная производительность. Размещая часто используемые или критически важные данные на высокопроизводительных уровнях хранения, таких как твердотельные накопители или хранилище NVMe, хранение по уровням может значительно повысить производительность системы. Это приводит к снижению задержек и более быстрому доступу к данным для приложений и пользователей, что приводит к повышению производительности и удовлетворенности пользователей.
- Эффективное использование ресурсов. Стратификация хранения обеспечивает эффективное использование каждого уровня хранения, избегая переоснащения высокопроизводительных носителей данных и недоиспользования более дешевых видов хранения. Она максимизирует возврат инвестиций (ROI) в инфраструктуру хранения.
- Оптимизация затрат. Стратификация хранения помогает организациям выделять дорогостоящие ресурсы хранения только для данных, требующих высокой производительности, в то время как менее критичные или редко используемые данные могут храниться на более дешевых уровнях, таких как жесткие диски или облачное хранилище. Эта оптимизация затрат приводит к возможной экономии на аппаратном обеспечении и операционных расходах.
- Сбалансированные нагрузки. Стратификация хранения может помочь распределить данные и нагрузки по разным уровням, уменьшив конкуренцию за ресурсы. Это особенно ценно в средах с различными нагрузками, где некоторые приложения требуют высокой производительности, а другие имеют менее строгие требования к хранению.
- Адаптивное управление данными. Шаблоны доступа к данным могут меняться со временем. Решения по стратификации хранения постоянно анализируют эти шаблоны и автоматически перемещают данные между уровнями по мере необходимости. Эта адаптируемость обеспечивает хранение данных на самом подходящем уровне хранения, даже когда требования к доступу меняются.
- Масштабируемость. По мере роста потребностей в хранении данных стратификация хранения позволяет организациям эффективно масштабировать свою инфраструктуру хранения. Можно добавлять новые уровни хранения или расширять существующие уровни в соответствии с возрастающими объемами данных и требованиями к производительности.
- Упрощенное управление данными. Решения для сегментации хранилища часто включают автоматические политики и инструменты управления, которые упрощают задачи по управлению данными. Это снижает административные накладные расходы, связанные с ручной установкой и миграцией данных.
- Соответствие и удержание. Организации с требованиями регулирования или соответствия выигрывают от сегментации хранилища, обеспечивая хранение и сохранение данных в соответствии с юридическими требованиями. Данные по соответствию могут управляться на определенных уровнях хранения с необходимыми политиками безопасности и удержания.
- Защита данных и аварийное восстановление. Классифицируя данные на основе их важности, сегментация хранилища помогает организациям приоритезировать защиту данных. Критические данные могут храниться на уровнях с высокой надежностью и избыточностью, что обеспечивает доступность и восстанавливаемость данных в случае сбоев или катастроф.
- Оптимизированное резервное копирование и восстановление. Разделяя данные на основе их важности и паттернов доступа, сегментация хранилища может помочь приоритизировать данные для операций резервного копирования и восстановления. Критические данные могут быть скопированы с более высокой частотой, в то время как менее критические данные могут подвергаться более длительным интервалам резервного копирования.
В то время как основной целью иерархии хранения данных является оптимизация размещения данных и затрат на хранение, преимущества, которые они предлагают, также могут повысить способность организации восстанавливаться после катастроф. Избыточность и экономичное хранение данных повышают вероятность успешного восстановления данных. Это помогает организациям поддерживать непрерывность бизнеса и восстанавливаться после катастроф с минимальными потерями данных и простоями, в конечном итоге улучшая их общую готовность к восстановлению после катастроф.
Лучшие практики иерархии хранения
Иерархия хранения – ценный метод оптимизации хранения данных, но важно следовать лучшим практикам, чтобы обеспечить его эффективность и эффективность. Лучшие практики иерархии хранения следующие:
- Поймите свои данные. Проведите тщательный анализ своих данных, чтобы понять их характеристики, паттерны доступа и важность. Не все данные нуждаются в иерархии, поэтому вы должны определить, какие наборы данных извлекут наибольшую пользу от иерархического хранения.
- Выберите правильное хранилище данных. Выберите носители хранения для каждого уровня на основе требований вашей организации к производительности и бюджету. Жесткие диски, твердотельные накопители, облачное хранилище и библиотеки лент являются распространенными вариантами.
- Регулярно отслеживайте и настраивайте. Непрерывно отслеживайте свою среду хранения, чтобы отслеживать паттерны доступа к данным и использование уровней. Настраивайте политики иерархии по мере необходимости для отражения изменяющихся требований. Регулярное рассмотрение и настройка ваших политик является ключом к оптимальной производительности.
- Используйте классификацию и тегирование данных. Используйте метаданные и тегирование данных для классификации данных. Эти метаданные могут использоваться вашей системой ранжирования для принятия более обоснованных решений о размещении данных.
- Обеспечьте приоритетность критических данных. Убедитесь, что миссионерски-критические и часто используемые данные размещены на высокопроизводительных уровнях. Это может потребовать различных политик или приоритетов для разных типов данных.
- Включите избыточность в критических уровнях. Если вы храните миссионерски-критические данные на высокопроизводительных уровнях, рассмотрите механизмы избыточности, такие как RAID (Резервированный массив независимых дисков), для защиты от потери данных из-за сбоев оборудования.
- Реализуйте автоматические политики ранжирования. Определите четкие автоматические политики для перемещения данных между уровнями. Эти политики должны учитывать такие факторы, как частота доступа, возраст данных и требования к производительности. Автоматизация размещения и миграции данных помогает обеспечить, чтобы данные всегда находились на правильном уровне.
- Предоставьте меры безопасности и контроль доступа. Реализуйте соответствующие меры безопасности и контроль доступа для данных на всех уровнях. Убедитесь, что конфиденциальные данные защищены и доступны только авторизованным пользователям.
- Резервное копирование и восстановление после катастроф. Планируйте защиту данных и восстановление после катастроф. Убедитесь, что стратегии резервного копирования и восстановления согласованы с вашим подходом к ранжированию хранения. Критические данные должны быть скопированы более часто и безопасно сохранены.
- Масштабируемость. Разработайте стратегию ранжирования хранилища данных с учетом масштабируемости. По мере роста потребностей в хранении данных будьте готовы добавить больше уровней или расширить существующие.
- Рассмотрите гибридные облачные решения. В зависимости от потребностей вашей организации, рассмотрите интеграцию облачного хранилища в качестве одного из ваших уровней хранения. Гибридные облачные решения могут предложить масштабируемость и гибкость.
- Регулярно оценивайте технологию. Будьте в курсе прогресса в области технологий хранения данных. По мере развития технологии могут появиться новые носители данных и решения, которые могут быть более экономичными и подходящими для ваших уровней хранения.
NAKIVO Backup & Replication и Уровни Хранения Резервных Копий
NAKIVO Backup & Replication – это современный продукт по защите данных и восстановлению после катастроф, который может работать с различными уровнями хранения, позволяя оптимизировать стратегии резервного копирования и восстановления на основе конкретных потребностей и имеющейся инфраструктуры хранения. Решение NAKIVO поддерживает различные типы хранилищ, включая локальное хранилище, облачные хранилища и аппараты для устранения дублирования данных.
Вы можете настроить NAKIVO Backup & Replication для использования различныхуровней хранения для резервных копий. Например, критически важные резервные копии могут храниться на высокопроизводительном хранилище (Уровень 1) для быстрого восстановления, а менее важные резервные копии могут быть перемещены на более дешевое хранилище (Уровень 2 или облако) для долгосрочного хранения.
Продукт предлагает такие функции, как резервное копирование и репликация, которые позволяют создавать дополнительные копии резервных копий на различных уровнях хранения. Это повышает уровень избыточности данных и готовности к восстановлению после катастроф, размещая резервные копии в нескольких местах или на различных уровнях хранения.
Вы можете определить политики удержания в NAKIVO Backup & Replication для автоматического управления данными резервного копирования на основе вашей стратегии уровней. Например, резервные копии могут храниться на Уровне 1 в течение более короткого периода, а затем переходить на Уровень 2 для долгосрочного хранения.
Решение NAKIVO поддерживает популярных поставщиков облачных хранилищ. Это означает, что вы легко можете интегрировать облачное хранилище как уровень хранения для резервных копий за пределами помещения, что сокращает необходимость в дополнительной инфраструктуре на месте.
Заключение
Многоуровневые архитектуры хранения позволяют организациям распределять ресурсы хранения в зависимости от конкретных потребностей их данных. Размещение данных на наиболее подходящем уровне позволяет организациям оптимизировать как производительность, так и стоимость, обеспечивая необходимую производительность для критически важных данных, в то время как менее критические или редко используемые данные хранятся экономично. Автоматизированные политики и инструменты управления уровнями данных помогают гарантировать перемещение данных между уровнями по мере изменения шаблонов доступа и требований со временем.