













Las organizaciones hoy en día deben utilizar el almacenamiento de manera racional, ya que grandes cantidades de datos pueden aumentar los costos de almacenamiento y llevar a la proliferación de datos. Los medios de almacenamiento de datos difieren en cuanto a costos, velocidad de escritura/lectura, etc., y diferentes tipos de datos deben almacenarse en los medios más eficientes para ahorrar costos y recursos.
Por ejemplo, almacenar copias de seguridad en dispositivos SSD (unidades de estado sólido) de alta velocidad es innecesariamente costoso ya que la alta velocidad de los SSD no es necesaria para este tipo de datos secundarios. En cambio, almacenar máquinas virtuales (VMs) de producción en discos duros (HDDs) con baja velocidad de RPM (revoluciones por minuto) puede ser económico, pero no cumplirá con los requisitos de rendimiento para sistemas primarios.
Por esta razón, los tipos de almacenamiento deben categorizarse para utilizar cada tipo de almacenamiento para almacenar los datos apropiados mediante el uso de niveles de almacenamiento.
¿Qué es el Nivel de Almacenamiento?
El nivel de almacenamiento es una estrategia de gestión de almacenamiento de datos utilizada para optimizar el rendimiento y la eficiencia de costos de un sistema de almacenamiento mediante la categorización de datos en diferentes niveles según sus características y patrones de acceso. El objetivo principal del nivel de almacenamiento es asegurar que los datos más frecuentemente accedidos y críticos se almacenen en medios de almacenamiento de alto rendimiento, mientras que los datos menos frecuentemente accedidos o menos críticos se almacenen en almacenamiento de menor costo.
Este enfoque permite a las organizaciones almacenar sus datos en varios tipos de medios de almacenamiento, como unidades de estado sólido (SSDs) rápidas y costosas o discos duros (HDDs) más lentos pero más rentables, según el valor de los datos y los patrones de uso.
El almacenamiento en niveles comienza con la clasificación de datos en diferentes categorías o niveles basados en criterios como la frecuencia de acceso, la importancia y los requisitos de rendimiento. Esta clasificación puede cambiar con el tiempo si el proceso de trabajo lo requiere. El número y tipos de niveles de almacenamiento pueden variar, desde 3 hasta 7, dependiendo de la infraestructura de almacenamiento.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
Clases de Datos para Almacenamiento en Niveles
Las clases de datos en una arquitectura de almacenamiento en niveles se refieren a la categorización o clasificación de datos basada en atributos o características específicas. Estas clases crean una jerarquía de datos y ayudan a determinar dónde se debe almacenar los datos dentro de un sistema de almacenamiento en niveles. Este enfoque asegura que los datos se coloquen en el nivel de almacenamiento más apropiado para equilibrar el rendimiento, el costo y la accesibilidad. Los detalles de las clases de datos pueden variar según las necesidades de la organización y la infraestructura de almacenamiento. Los atributos comunes utilizados para la clasificación de datos son:
- Frecuencia de acceso. Uno de los criterios principales para la clasificación de datos es con qué frecuencia son accedidos por usuarios y aplicaciones. Los datos que se usan regularmente y de manera activa (datos calientes) deben almacenarse en niveles de almacenamiento de alto rendimiento, como SSD o unidades NVMe, para garantizar tiempos de acceso rápidos. En contraste, los datos accedidos con poca frecuencia (datos fríos) pueden colocarse en niveles de almacenamiento de menor costo, como HDD o almacenamiento en la nube.
- Crucialidad o importancia. Algunos datos son más críticos para las operaciones de una organización o los requisitos de cumplimiento que otros. Los datos críticos pueden necesitar almacenarse en capas de almacenamiento más confiables y resilientes, como RAID (conjunto redundante de discos independientes) o almacenamiento en la nube con redundancia, para minimizar el riesgo de pérdida de datos.
- Tipo de datos. Diferentes tipos de datos, como archivos de bases de datos, contenido multimedia, registros de aplicaciones o documentos de archivo, pueden tener diferentes requisitos de almacenamiento. Por ejemplo, los archivos multimedia pueden requerir un alto rendimiento y capacidad, mientras que los registros pueden almacenarse en almacenamiento más lento siempre que se retengan por motivos de cumplimiento.
- Periodo de retención. Los datos con requisitos específicos de retención o cumplimiento pueden necesitar almacenarse en capas que garanticen la integridad y disponibilidad de datos durante el tiempo requerido. Los datos de cumplimiento a menudo requieren una retención a largo plazo y, por lo tanto, pueden almacenarse en capas de almacenamiento más confiables.
- Tamaño. Los objetos de datos grandes pueden beneficiarse de almacenarse en capas de almacenamiento optimizadas para capacidad, mientras que los datos pequeños y de acceso frecuente pueden requerir almacenamiento con baja latencia y alto rendimiento de E/S.
- Ciclo de vida de los datos. Los datos pasan por varias etapas en su ciclo de vida, desde la creación y uso activo hasta el archivo o la eliminación. Las clases de datos deben tener en cuenta estas etapas y mover los datos entre capas según sea necesario. Por ejemplo, los datos recién creados pueden comenzar en una capa de alto rendimiento pero gradualmente ser movidos a capas de menor costo a medida que se vuelven menos activos.
- Sensibilidad al costo. Las organizaciones a menudo tienen limitaciones presupuestarias. Las clases de datos pueden ayudar a alinear los costos de almacenamiento de datos con las consideraciones presupuestarias al asegurar que los recursos de almacenamiento más caros se reserven para datos que justifiquen el costo.
- Requisitos del usuario o de la aplicación. Diferentes usuarios o aplicaciones pueden tener necesidades específicas de almacenamiento. Las clases de datos pueden tener en cuenta estos requisitos para garantizar que cada grupo reciba el rendimiento y la capacidad de almacenamiento necesarios.
Una vez que los datos se clasifican en estas clases, se utilizan políticas y algoritmos para gestionar la ubicación y el movimiento de datos dentro de la infraestructura de almacenamiento jerarquizado. Esto asegura que los datos se optimicen continuamente para el rendimiento y la eficiencia de costos mientras se satisfacen las necesidades organizativas y los patrones de acceso.
Clasificación con almacenamiento caliente, tibio y frío
El tipo común de clasificación de datos en sistemas de almacenamiento jerarquizado es clasificar los datos como críticos para la misión, calientes, tibios y fríos. Estas clases ayudan a determinar cómo se almacenan, administran y acceden los datos dentro de la infraestructura de almacenamiento. En este caso, las clases de datos utilizadas en las estrategias de almacenamiento jerarquizado incluyen:
- Datos críticos para la misión. Esta clase de datos se refiere a datos que son absolutamente esenciales para las operaciones centrales de una organización. Los datos críticos para la misión requieren el más alto nivel de rendimiento, confiabilidad y disponibilidad. Típicamente se almacenan en los medios de almacenamiento más resilientes y de alto rendimiento disponibles, como matrices SSD redundantes o sistemas de almacenamiento tolerantes a fallos.
- Datos calientes. Los datos calientes se refieren a datos que se acceden de manera activa y frecuente. Estos datos suelen tener una gran importancia para la organización y requieren tiempos de respuesta rápidos y almacenamiento de alto rendimiento. Los datos calientes suelen almacenarse en los medios de almacenamiento de la más alta categoría, como unidades de estado sólido (SSD) o unidades NVMe, para garantizar baja latencia y acceso rápido.
- Datos tibios. Los datos tibios representan datos que se acceden con menos frecuencia que los datos calientes pero que aún se utilizan activamente. Esta clase de datos suele residir en un nivel por debajo de los datos calientes en cuanto a rendimiento, como unidades de disco duro (HDD) de alto rendimiento o soluciones de almacenamiento híbridas. Aunque los datos tibios pueden no requerir el almacenamiento más rápido, aún deben estar disponibles fácilmente para un acceso eficiente.
- Datos fríos. Los datos fríos incluyen datos que rara vez se acceden, son históricos o están archivados. Estos datos a menudo se consideran menos críticos y se almacenan en niveles de almacenamiento de menor costo, que podrían ser HDD tradicionales más lentos o incluso opciones de almacenamiento de archivos como cintas o almacenamiento en frío basado en la nube. El énfasis para los datos fríos está en la retención a largo plazo y el ahorro de costos.
El número de clases de datos puede depender del número de niveles de almacenamiento en el modelo de clasificación de almacenamiento. Las organizaciones pueden clasificar los datos de una manera más compleja utilizando las siguientes clases de datos además de las clases explicadas anteriormente:
- Copia de seguridad y recuperación de datos en caso de desastre. Los datos utilizados con fines de copia de seguridad y recuperación de desastres a menudo se clasifican por separado. Estas clases de datos se centran en garantizar que los datos se puedan restaurar de manera confiable y rápida en caso de pérdida de datos o fallo del sistema. Los datos de copia de seguridad pueden almacenarse en sistemas basados en disco, mientras que las copias de retención a largo plazo podrían almacenarse en cinta o en la nube.
- Datos de cumplimiento. Los datos que deben cumplir con requisitos regulatorios de cumplimiento, como registros financieros o datos de salud, pueden tener necesidades de almacenamiento específicas. Las clases de datos de cumplimiento aseguran que estos datos se almacenen de manera segura, con características como cifrado y controles de acceso estrictos, y se conserven durante la duración requerida.
- Datos de usuario o departamentales. Algunas organizaciones clasifican los datos según su origen, como los datos generados por departamentos o usuarios específicos. Este enfoque puede ayudar a asignar recursos de almacenamiento según las necesidades de las diferentes unidades organizativas.
- Datos temporales o de caché. Las clases de datos para datos temporales o de caché pueden incluir datos que tienen una vida útil corta y se pueden almacenar en niveles de almacenamiento de alta velocidad para un acceso rápido, con la comprensión de que se pueden desechar o reemplazar cuando ya no sean necesarios.
Datos de migración de niveles . En algunos casos, se utilizan clases de datos para identificar datos que se están moviendo activamente entre niveles de almacenamiento según los patrones de acceso. Por ejemplo, los datos que comienzan como calientes pero que se acceden con menos frecuencia con el tiempo pueden migrar a niveles de almacenamiento más cálidos o más fríos. - Datos de migración de niveles. En algunos casos, se utilizan clases de datos para identificar datos que se mueven activamente entre niveles de almacenamiento en función de los patrones de acceso. Por ejemplo, los datos que comienzan como calientes pero que se acceden con menos frecuencia con el tiempo pueden migrar a niveles de almacenamiento más cálidos o fríos.
Estas clases de datos pueden servir como pautas para que los administradores de almacenamiento y sistemas automatizados de gestión de almacenamiento tomen decisiones informadas sobre dónde colocar los datos dentro de una infraestructura de almacenamiento en niveles.
Tipos de Almacenamiento Multinivel
El almacenamiento multinivel se refiere a una arquitectura de almacenamiento en la que los datos se categorizan en diferentes niveles en función de sus requisitos de rendimiento y accesibilidad. Cada nivel representa un nivel específico de rendimiento de almacenamiento y costo. El objetivo es garantizar que los datos se almacenen en el nivel más apropiado para optimizar tanto el rendimiento como la eficiencia de costo. A continuación, puede ver los niveles de almacenamiento comunes, comenzando con el Nivel 0:
- Nivel 0 representa el nivel de almacenamiento de mayor rendimiento en un sistema de almacenamiento multinivel. Suele estar compuesto por los medios de almacenamiento más rápidos y costosos disponibles, como unidades de estado sólido (SSDs) de gama empresarial o SSD NVMe (Non-Volatile Memory Express). Los datos almacenados en el Nivel 0 son típicamente de naturaleza crítica y requieren una latencia extremadamente baja, un alto rendimiento de E/S y un acceso rápido a los datos. Se utiliza para aplicaciones y datos que requieren los niveles más altos de rendimiento.
- Nivel 1 es el siguiente nivel en términos de rendimiento y costo. Por lo general, consiste en unidades de disco duro (HDD) de alto rendimiento, matrices de almacenamiento híbridas (que combinan SSDs y HDDs) o SSDs más rápidos, que no son tan costosos como los de Nivel 0. Los datos en Nivel 1 son importantes pero pueden no requerir el almacenamiento más rápido disponible. Este nivel es adecuado para aplicaciones y datos que necesitan un buen rendimiento pero pueden tolerar un poco más de latencia en comparación con los datos de Nivel 0.
- Nivel 2 representa un nivel de almacenamiento de menor costo con un rendimiento algo más lento en comparación con el Nivel 1. A menudo incluye HDD tradicionales o soluciones de almacenamiento basadas en la nube. Los datos en el Nivel 2 se acceden con menos frecuencia o son menos críticos para las operaciones en tiempo real. Este nivel es adecuado para datos de archivo, copias de seguridad y datos que pueden tolerar tiempos de acceso más largos.
- Nivel 3 es el nivel de almacenamiento de menor costo en un sistema de almacenamiento multinivel. Por lo general, incluye soluciones de almacenamiento de archivo, como bibliotecas de cintas y almacenamiento en frío basado en la nube. Los datos en el Nivel 3 se acceden raramente y se conservan principalmente por cuestiones de cumplimiento, normativas o para archivo a largo plazo. Ofrece el menor rendimiento pero el almacenamiento más económico.
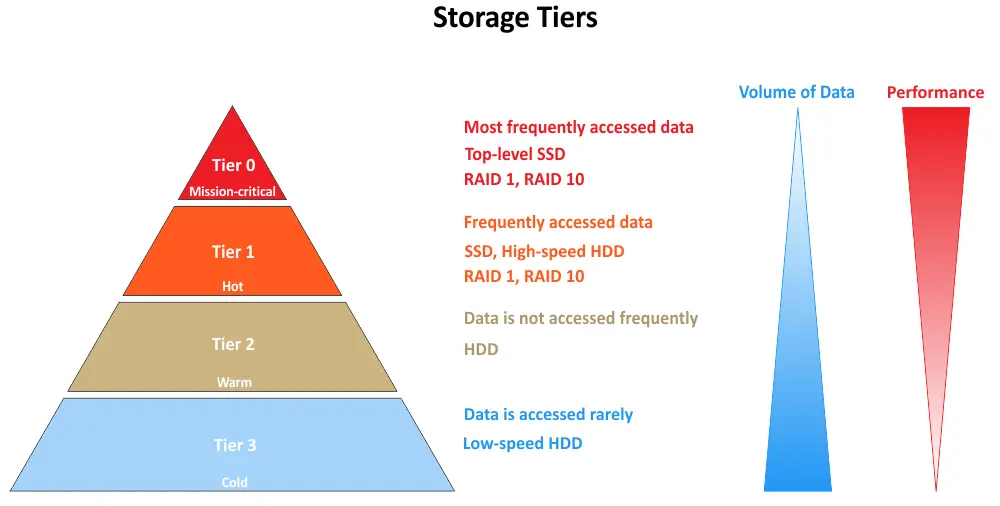
Algunas organizaciones que utilizan principalmente almacenamiento local dedican niveles adicionales especiales para el almacenamiento en la nube pública y el almacenamiento de respaldo:
- Nivel de Nube. En algunas arquitecturas de almacenamiento de múltiples niveles, se utiliza un nivel separado Nivel de Nube para almacenar datos en un servicio de almacenamiento en la nube como Amazon S3 o Azure Blob Storage. Esto permite a las organizaciones aprovechar el almacenamiento en la nube escalable y rentable para datos que pueden no encajar perfectamente en niveles locales. Los datos en el nivel de nube se pueden acceder a través de Internet cuando sea necesario.
- Nivel de respaldo. Aunque no siempre se considera un nivel de almacenamiento principal, el almacenamiento de respaldo es una parte crítica de la jerarquía de almacenamiento. Los datos de respaldo se almacenan en sistemas basados en disco o bibliotecas de cintas, dependiendo de la estrategia de respaldo de la organización. El enfoque está en la protección de datos y la recuperación rápida en caso de pérdida de datos o desastres.
¿Cuántos niveles suelen utilizar las organizaciones?
El número de niveles utilizados por las organizaciones en sus arquitecturas de almacenamiento puede variar ampliamente dependiendo de sus necesidades específicas, restricciones presupuestarias y la complejidad de sus requisitos de gestión de datos. Sin embargo, en la práctica, muchas organizaciones suelen implementar una jerarquía de almacenamiento de tres niveles como punto de partida (Nivel 0, Nivel 1, Nivel 2).
Muchas organizaciones comienzan con estos tres niveles como base y luego personalizan su infraestructura de almacenamiento para satisfacer sus necesidades específicas. Pueden agregar niveles adicionales o adoptar clases de almacenamiento especializadas a medida que sus requisitos de datos evolucionen. Por ejemplo:
- Algunas organizaciones podrían agregar una Nivel 4 o Nivel 5 para el almacenamiento a largo plazo y de archivo profundo, lo que podría implicar tecnologías como bibliotecas de cintas o almacenamiento en la nube de muy bajo costo.
- Otros podrían implementar un Nivel en la Nube para copias de seguridad fuera del sitio y propósitos de recuperación ante desastres, utilizando servicios de almacenamiento en la nube como Amazon S3 o Azure Blob Storage.
- Las estrategias de nube híbrida también pueden introducir más niveles, incluyendo niveles basados en la nube para datos que necesitan ser movidos de manera transparente entre el almacenamiento local y la nube.
La clave es diseñar una arquitectura de almacenamiento que se alinee con los patrones de acceso a datos, requisitos de rendimiento y consideraciones presupuestarias de la organización. También es importante implementar políticas efectivas de gestión de datos y clasificación para garantizar que los datos se almacenen en el nivel apropiado en función de las necesidades cambiantes de estos datos a lo largo del tiempo. A medida que las tecnologías de almacenamiento de datos continúen evolucionando, las organizaciones podrían ajustar sus estrategias de almacenamiento en niveles para aprovechar las nuevas innovaciones y soluciones de bajo costo.
Estos niveles de almacenamiento comunes se pueden resumir en una tabla con explicaciones breves y casos de uso típicos:
| Número de Nivel | Nombre de Nivel | Explicación | Casos de Uso Típicos |
| Nivel 0 | Ultra-rápido SSD | Almacenamiento de mayor rendimiento, baja latencia | Bases de datos críticas, aplicaciones en tiempo real |
| Nivel 1 | SSD de alto rendimiento | Buen equilibrio de velocidad y costo | Datos de aplicaciones generales, máquinas virtuales |
| Nivel 2 | Almacenamiento híbrido | Mezcla de SSDs y HDDs, económico | Almacenamiento de respaldo, datos secundarios, compartición de archivos |
| Nivel 3 | HDD de nearline | Almacenamiento de respaldo, datos secundarios, compartición de archivos | Datos archivados, almacenamiento a largo plazo |
| Nivel 4 | Almacenamiento frío | Bajo costo, muy alta capacidad, acceso lento | Datos archivados con acceso infrecuente |
| Nivel en la Nube | Almacenamiento en la nube | Almacenamiento basado en la nube escalable | Respaldos fuera del sitio, recuperación ante desastres, compartición de datos |
Tenga en cuenta que los nombres y características de los niveles de almacenamiento pueden variar entre organizaciones y proveedores de almacenamiento. La tabla anterior proporciona una visión general general de los niveles de almacenamiento comunes y sus casos de uso típicos, pero las implementaciones específicas pueden diferir en función de las necesidades de la organización y las tecnologías disponibles.
Dónde se utilizan los niveles de almacenamiento
El escalonamiento de almacenamiento es una estrategia de gestión de almacenamiento que se puede utilizar tanto en el entorno local (dentro de los propios centros de datos de una organización o entornos de nube privada) como en la nube pública. Es un enfoque flexible que se puede aplicar a varias arquitecturas de almacenamiento para optimizar la colocación de datos y los patrones de acceso.
Almacenamiento por niveles en el entorno local
El almacenamiento por niveles se utiliza en los siguientes entornos centrados en la infraestructura local (on-premises):
- Centros de datos tradicionales. En los centros de datos on-premises tradicionales, el almacenamiento por niveles se emplea comúnmente para administrar datos almacenados en diferentes tipos de medios de almacenamiento, como SSD, HDD y bibliotecas de cintas. Las organizaciones implementan el almacenamiento por niveles para optimizar el rendimiento, el costo y la disponibilidad de datos dentro de su propia infraestructura.
- Nubes privadas. Muchos entornos de nube privada incorporan el almacenamiento por niveles para gestionar de manera eficiente los datos a través de diferentes tipos de recursos de almacenamiento. Esto es especialmente importante en configuraciones de nube privada donde los recursos deben asignarse dinámicamente para soportar diversas cargas de trabajo.
- Nubes híbridas. En un entorno de nube híbrida, que combina la infraestructura on-premises con recursos de nube pública, el almacenamiento por niveles puede utilizarse para optimizar el posicionamiento de datos en ambos entornos. Las organizaciones pueden usar políticas de estratificación para determinar qué datos deben residir on-premises y cuáles deben trasladarse a la nube pública para lograr eficiencia en costos o escalabilidad.
Almacenamiento por niveles en la nube pública
En cuanto a la nube pública, el almacenamiento por niveles se utiliza en los siguientes entornos:
- Servicios de almacenamiento en la nube pública. Los proveedores de nube pública como Amazon Web Services (AWS), Microsoft Azure y Google Cloud Platform (GCP) ofrecen sus propias opciones de estratificación de almacenamiento en la nube como parte de sus servicios de almacenamiento en la nube. Por ejemplo, AWS ofrece clases de almacenamiento S3 (Estándar, Inteligente-Estratificación, Glacier, etc.), cada una adaptada para diferentes requisitos de rendimiento y costo.
- Almacenamiento de objetos. Los servicios de almacenamiento de objetos en la nube pública a menudo admiten la estratificación de almacenamiento para permitir a los clientes elegir la clase de almacenamiento más apropiada para sus datos. Esto es beneficioso para optimizar costos y tiempos de acceso.
Estratificación de Almacenamiento Automatizado
La estratificación automatizada de almacenamiento y la optimización de la estratificación de almacenamiento son técnicas utilizadas en la gestión moderna de almacenamiento de datos para garantizar que los datos se coloquen en el nivel de almacenamiento más adecuado de manera efectiva y en el momento adecuado.
Automatizadoestratificación de almacenamiento es una técnica de gestión de datos que implica el movimiento automático y dinámico de datos entre diferentes niveles de almacenamiento en función de políticas y criterios específicos. Estas políticas suelen ser definidas por administradores de almacenamiento o establecidas por software inteligente de gestión de almacenamiento. El objetivo principal de la estratificación automatizada de almacenamiento es optimizar el uso de los recursos de almacenamiento asegurando que los datos se almacenen en el nivel más apropiado en cualquier momento dado.
El almacenamiento automatizado por niveles te permite optimizar dinámicamente tus niveles de almacenamiento, monitorizando continuamente el uso de datos y el acceso para determinar las prioridades de los datos y los niveles de almacenamiento requeridos. Al utilizar el almacenamiento automatizado, estableces tus umbrales preferidos y la automatización se encarga del resto.
A medida que el uso de datos alcanza umbrales predefinidos, se reubica en consecuencia. Si la frecuencia de acceso a los datos aumenta, se mueve a un nivel de menor latencia. Cuando los datos no se utilizan, se desplazan a un nivel de menor costo y mayor latencia. Este enfoque optimiza tanto tus costos como el rendimiento con un mínimo esfuerzo y sin necesidad de mantenimiento continuo.
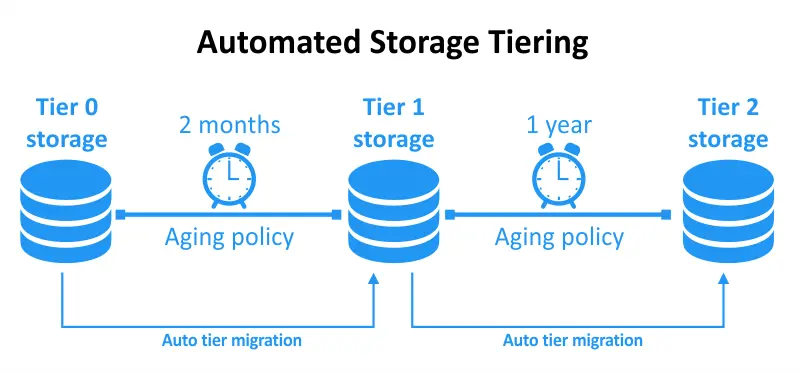
El almacenamiento automatizado por niveles facilita las transferencias de datos dirigidas por políticas entre niveles de almacenamiento, alineándose así con las necesidades de rendimiento y capacidad de los usuarios. Esta característica funciona de manera eficiente con tu arquitectura de almacenamiento por niveles existente y simplifica la gestión de datos a través de la automatización. El almacenamiento automatizado por niveles mejora la optimización del rendimiento y la eficiencia de costos debido a los ajustes en tiempo real y el rápido movimiento de datos.
Nivel de almacenamiento optimización es un concepto más amplio que abarca diversas estrategias, incluyendo automatizado almacenamiento por niveles, para garantizar que la infraestructura de almacenamiento de una organización se gestione y utilice de manera eficiente. Si bien el almacenamiento automatizado por niveles es un componente clave de la optimización del almacenamiento por niveles, también pueden estar involucradas otras técnicas y buenas prácticas.
Niveles vs Caché
Los sistemas de clasificación y almacenamiento en caché son dos técnicas distintas utilizadas en el almacenamiento y gestión de datos, que cumplen propósitos diferentes. Los términos clasificación y almacenamiento en caché a menudo se utilizan indistintamente por error, pero se refieren a dos técnicas de aceleración de almacenamiento diferentes. Ambas implican colocar datos accedidos con frecuencia o calientes en soportes de alta velocidad como la memoria flash. Sin embargo, las similitudes terminan en su mayoría allí.
Almacenamiento en caché almacena temporalmente datos en un medio de alto rendimiento como DRAM o memoria de estado sólido para mejorar el rendimiento. La caché se encuentra entre la aplicación y el almacenamiento de respaldo. Los mismos datos también residen en una capa de almacenamiento inferior, generalmente un HDD. Los datos se copian en la caché, pero los datos originales permanecen en su ubicación inicial. El almacenamiento en caché es esencialmente una transacción de ida y la caché invalida los datos después de su uso.
Clasificación de almacenamiento, por otro lado, mueve físicamente los datos entre dispositivos de almacenamiento. Cuando se identifica que los datos son calientes, estos datos se trasladan a una capa de alta velocidad, dejando la capa estándar sin una copia. Cuando los datos se enfrían, se mueven de vuelta a la capa estándar. La clasificación de almacenamiento implica mover datos en lugar de simplemente copiarlos, tanto desde almacenamiento más lento hasta más rápido y viceversa.
Tanto la clasificación de almacenamiento como el almacenamiento en caché mejoran la accesibilidad de los datos, pero difieren en cómo utilizan el almacenamiento para los datos accedidos con frecuencia. El almacenamiento en caché crea copias, mientras que la clasificación de almacenamiento identifica los datos y los mueve sin crear copias adicionales.
Por lo tanto, el escalonamiento se centra en optimizar la colocación a largo plazo de datos en diferentes niveles de almacenamiento para lograr un equilibrio entre rendimiento y costo, mientras que la caché busca acelerar el acceso a datos almacenando temporalmente datos frecuentemente accedidos en un búfer de alta velocidad. La elección entre escalonamiento y caché depende de los requisitos específicos de la aplicación o sistema de almacenamiento y la naturaleza de los patrones de acceso a datos. En algunos casos, las organizaciones pueden utilizar ambas técnicas en combinación para lograr el mejor rendimiento general y eficiencia en costos.
Almacenamiento escalonado y Administración de Almacenamiento Jerárquico
El almacenamiento escalonado y la administración de almacenamiento jerárquico son ambas estrategias utilizadas en la gestión de almacenamiento de datos, pero difieren en su granularidad, mecanismos de movimiento de datos y objetivos principales. El almacenamiento escalonado se enfoca en categorizar datos en niveles discretos de medios de almacenamiento basados en características, mientras que la administración de almacenamiento jerárquico se enfoca en migrar de manera transparente archivos o objetos individuales entre almacenamiento primario y secundario para mejorar la eficiencia y ahorro de costos del almacenamiento primario.
Beneficios del escalonamiento de almacenamiento
El escalonamiento de almacenamiento ofrece varios beneficios significativos para las organizaciones que buscan optimizar su infraestructura de almacenamiento de datos. Las principales ventajas de implementar el escalonamiento de almacenamiento son:
- Mejor rendimiento. Al colocar datos frecuentemente accedidos o críticos en niveles de almacenamiento de alto rendimiento, como unidades de estado sólido o almacenamiento NVMe, el escalonamiento de almacenamiento puede mejorar significativamente el rendimiento del sistema. Esto resulta en una menor latencia y tiempos de acceso a datos más rápidos para aplicaciones y usuarios, lo que lleva a una mayor productividad y satisfacción del usuario.
- Utilización eficiente de recursos. El escalonamiento de almacenamiento garantiza que cada nivel de almacenamiento se utilice de manera eficiente, evitando la sobre-explotación de medios de almacenamiento de alto rendimiento y la subutilización de almacenamiento de menor costo. Maximiza el retorno de la inversión (ROI) para la infraestructura de almacenamiento.
- Optimización de costos. El escalonamiento de almacenamiento ayuda a las organizaciones a asignar recursos de almacenamiento costosos solo a datos que requieren alto rendimiento, mientras que datos menos críticos o accedidos con poca frecuencia pueden almacenarse en niveles de menor costo, como unidades de disco duro o almacenamiento en la nube. Esta optimización de costos conduce a posibles ahorros en hardware y gastos operativos.
- Cargas de trabajo equilibradas. El escalonamiento de almacenamiento puede ayudar a distribuir datos y cargas de trabajo a través de diferentes niveles, reduciendo la contención de recursos. Esto es particularmente valioso en entornos con cargas de trabajo mixtas, donde algunas aplicaciones requieren alto rendimiento mientras que otras tienen requisitos de almacenamiento menos exigentes.
- Administración de datos adaptativa. Los patrones de acceso a datos pueden cambiar con el tiempo. Las soluciones de escalonamiento de almacenamiento analizan continuamente estos patrones y mueven automáticamente los datos entre niveles según sea necesario. Esta adaptabilidad garantiza que los datos permanezcan en el nivel de almacenamiento más adecuado, incluso a medida que cambian los requisitos de acceso.
- Escalabilidad. A medida que aumentan las necesidades de almacenamiento de datos, el escalonamiento de almacenamiento permite a las organizaciones escalar de manera eficiente su infraestructura de almacenamiento. Se pueden agregar nuevos niveles de almacenamiento o ampliar los niveles existentes según sea necesario para acomodar volúmenes crecientes de datos y demandas de rendimiento.
- Administración simplificada de datos. Las soluciones de estratificación de almacenamiento a menudo incluyen políticas automatizadas y herramientas de gestión que simplifican las tareas de administración de datos. Esto reduce la sobrecarga administrativa asociada con el posicionamiento y migración de datos manuales.
- Cumplimiento y retención. Las organizaciones con requisitos regulatorios o de cumplimiento se benefician de la estratificación de almacenamiento al garantizar que los datos se almacenen y conserven de acuerdo con las directrices legales. Los datos de cumplimiento pueden gestionarse en niveles de almacenamiento específicos con las políticas de seguridad y retención necesarias.
- Protección de datos y recuperación ante desastres. Al clasificar los datos según su importancia, la estratificación de almacenamiento ayuda a las organizaciones a priorizar los esfuerzos de protección de datos. Los datos críticos pueden almacenarse en niveles resistentes y redundantes, asegurando la disponibilidad y recuperación de datos en caso de fallos o desastres.
- Copias de seguridad y restauración optimizadas. Al separar los datos según su importancia y patrones de acceso, la estratificación de almacenamiento puede ayudar a priorizar los datos para las operaciones de copia de seguridad y restauración. Los datos críticos pueden guardarse con mayor frecuencia, mientras que los menos críticos pueden estar sujetos a intervalos de copia de seguridad más largos.
Mientras que el propósito principal de las capas de almacenamiento es optimizar la ubicación de los datos y los costos de almacenamiento, los beneficios que ofrecen también pueden mejorar la capacidad de la organización para recuperarse de desastres. La redundancia y la retención de datos rentable aumentan las posibilidades de recuperación exitosa de datos. Ayuda a las organizaciones a mantener la continuidad del negocio y a recuperarse de desastres con la mínima pérdida de datos y tiempo de inactividad, mejorando así su preparación general para la recuperación de desastres.
Buenas prácticas de estratificación de almacenamiento
La estratificación de almacenamiento es una técnica valiosa para optimizar el almacenamiento de datos, pero es importante seguir las mejores prácticas para garantizar su efectividad y eficiencia. Las mejores prácticas para la estratificación de almacenamiento son las siguientes:
- Conoce tus datos. Realiza un análisis exhaustivo de tus datos para comprender sus características, patrones de acceso e importancia. No todos los datos necesitan estar estratificados, por esta razón, debes identificar qué conjuntos de datos se beneficiarían más del almacenamiento estratificado.
- Selecciona el medio de almacenamiento adecuado. Elije el medio de almacenamiento para cada capa en función de los requisitos de rendimiento y presupuestarios de tu organización. Las unidades de estado sólido, los discos duros, el almacenamiento en la nube y las bibliotecas de cintas son opciones comunes.
- Monitorea y ajusta regularmente. Monitorea continuamente tu entorno de almacenamiento para rastrear patrones de acceso a datos y utilización de capas. Ajusta las políticas de estratificación según sea necesario para reflejar requisitos cambiantes. Revisar y ajustar regularmente tus políticas es esencial para un rendimiento óptimo.
- Utilizar clasificación y etiquetado de datos. Utilice metadatos y etiquetado de datos para clasificar los datos. Estos metadatos pueden ser utilizados por su sistema de estratificación para tomar decisiones más informadas sobre el lugar de los datos.
- Priorizar datos críticos. Asegúrese de que los datos críticos para la misión y los datos accesados con frecuencia se coloquen en niveles de alto rendimiento. Esto puede requerir políticas o niveles de prioridad diferentes para diferentes tipos de datos.
- Incluir redundancia en niveles críticos. Si almacena datos críticos para la misión en niveles de alto rendimiento, considere mecanismos de redundancia como RAID (Matriz redundante de discos independientes) para protegerse contra la pérdida de datos debido a fallas de hardware.
- Implementar políticas de estratificación automatizadas. Defina políticas claras y automatizadas para mover datos entre niveles. Estas políticas deben considerar factores como la frecuencia de acceso, la antigüedad de los datos y los requisitos de rendimiento. La automatización del lugar y la migración de datos ayuda a garantizar que los datos siempre estén en el nivel adecuado.
- Proporcionar controles de seguridad y acceso. Implemente las medidas de seguridad y controles de acceso apropiados para los datos en todos los niveles. Asegúrese de que los datos sensibles estén protegidos y accesibles solo para usuarios autorizados.
- Copias de seguridad y recuperación ante desastres. Planifique la protección de datos y la recuperación ante desastres. Asegúrese de que las estrategias de copia de seguridad y recuperación estén alineadas con su enfoque de estratificación de almacenamiento. Los datos críticos deben ser copiados con más frecuencia y conservados de forma segura.
- Escalabilidad. Diseñe su estrategia de estratificación de almacenamiento para ser escalable. A medida que sus necesidades de almacenamiento de datos crezcan, esté preparado para agregar más niveles o expandir los existentes.
- Considere soluciones de nube híbrida. Dependiendo de las necesidades de su organización, considere la integración de almacenamiento en la nube como una de sus capas de almacenamiento. Las soluciones de nube híbrida pueden ofrecer escalabilidad y flexibilidad.
- Evalúe regularmente la tecnología. Manténgase informado sobre los avances en tecnología de almacenamiento. A medida que la tecnología evoluciona, pueden surgir nuevos medios de almacenamiento y soluciones que sean más rentables y adecuadas para sus capas de almacenamiento.
NAKIVO Backup & Replication y Clasificación de Almacenamiento de Copias de Seguridad
NAKIVO Backup & Replication es una solución moderna de protección de datos y recuperación ante desastres que puede trabajar con diferentes capas de almacenamiento, permitiéndole optimizar sus estrategias de respaldo y recuperación en función de sus necesidades específicas y la infraestructura de almacenamiento disponible. La solución NAKIVO es compatible con varios tipos de almacenamiento, incluyendo almacenamiento on-premise, almacenamiento en la nube y dispositivos de eliminación de duplicados.
Puede configurar NAKIVO Backup & Replication para usar diferentes capas de almacenamiento para copias de seguridad. Por ejemplo, las copias de seguridad críticas pueden almacenarse en almacenamiento de alto rendimiento (Nivel 1) para una recuperación rápida, mientras que las copias de seguridad menos críticas pueden trasladarse a un almacenamiento de menor costo (Nivel 2 o en la nube) para retención a largo plazo.
El producto ofrece características como copia de respaldo y replicación, que permiten la creación de copias adicionales de respaldos en diferentes capas de almacenamiento. Esto mejora la redundancia de datos y la preparación para recuperación ante desastres al colocar los respaldos en múltiples ubicaciones o capas de almacenamiento.
Puedes definir políticas de retención dentro de NAKIVO Backup & Replication para gestionar automáticamente los datos de respaldo según tu estrategia de niveles. Por ejemplo, los respaldos pueden retenerse en el Nivel 1 por un período más corto y luego pasar al Nivel 2 para una retención a largo plazo.
La solución de NAKIVO es compatible con proveedores populares de almacenamiento en la nube. Esto significa que puedes incorporar fácilmente el almacenamiento en la nube como un nivel de almacenamiento para respaldos fuera del sitio, reduciendo la necesidad de infraestructura adicional en las instalaciones.
Conclusión
Las arquitecturas de almacenamiento multinivel permiten a las organizaciones asignar recursos de almacenamiento según las necesidades específicas de sus datos. Al colocar los datos en el nivel más adecuado, las organizaciones pueden optimizar tanto el rendimiento como el costo, asegurando que los datos críticos reciban el rendimiento necesario mientras que los datos menos críticos o poco accesibles se almacenan de manera rentable. Las políticas automatizadas de nivelación de datos y las herramientas de gestión ayudan a garantizar que los datos se muevan entre niveles a medida que cambian los patrones de acceso y los requisitos con el tiempo.