













Organisaties moeten vandaag de dag opslag rationeel gebruiken, aangezien grote hoeveelheden gegevens opslagkosten kunnen verhogen en tot gegevensvermenigvuldiging kunnen leiden. Gegevensopslagmedia verschillen qua kosten, schrijf-/leessnelheid, enz., en verschillende soorten gegevens moeten worden opgeslagen op de meest efficiënte media om kosten en middelen te besparen.
Bijvoorbeeld, het opslaan van back-ups op high-speed SSD’s (solid-state drives) is onnodig duur omdat de hoge snelheid van SSD’s niet nodig is voor dit type secundaire gegevens. Daarentegen kan het opslaan van productie virtuele machines (VM’s) op harde schijven (HDD’s) met een lage RPM (revoluties per minuut) budgetvriendelijk zijn, maar voldoet niet aan de prestatie-eisen voor primaire systemen.
Om deze reden moeten opslagtypen worden gecategoriseerd om elk opslagtype te gebruiken om de juiste gegevens op te slaan door gebruik te maken van opslagtiering.
Wat is opslagtiering?
Opslagtiering is een gegevensopslagbeheerstrategie die wordt gebruikt om de prestaties en kostenefficiëntie van een opslagsysteem te optimaliseren door gegevens in verschillende lagen te categoriseren op basis van hun kenmerken en toegangspatronen. Het belangrijkste doel van opslagtiering is ervoor te zorgen dat de meest frequent benaderde en kritieke gegevens worden opgeslagen op high-performance opslagmedia, terwijl minder vaak benaderde gegevens of minder kritieke gegevens worden opgeslagen op lagere kostenopslag.
Deze aanpak stelt organisaties in staat om hun gegevens op te slaan op verschillende soorten opslagmedia, zoals snelle en dure solid-state drives (SSD’s) of langzamere maar kosteneffectievere harde schijven (HDD’s), afhankelijk van de waarde van de gegevens en het gebruikspatroon.
Opslagtieren begint met het classificeren van gegevens in verschillende categorieën of lagen op basis van criteria zoals frequentie van toegang, belangrijkheid en prestatievereisten. Deze classificatie kan in de loop van de tijd veranderen als het werkproces dat vereist. Het aantal en de soorten opslagtieren kunnen variëren – van 3 tot 7 – afhankelijk van de opslaginfrastructuur.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
Gegevensklassen voor getrapte opslag
Gegevensklassen in een getrapte opslagarchitectuur verwijzen naar de categorisering of classificatie van gegevens op basis van specifieke eigenschappen of kenmerken. Deze klassen creëren een gegevenshiërarchie en helpen bepalen waar gegevens moeten worden opgeslagen binnen een getrapte opslagsysteem. Deze aanpak zorgt ervoor dat gegevens worden geplaatst op de meest geschikte opslaglaag om prestaties, kosten en toegankelijkheid in evenwicht te brengen. De specifieke kenmerken van gegevensklassen kunnen variëren afhankelijk van de behoeften van de organisatie en de opslaginfrastructuur. De gebruikelijke attributen die worden gebruikt voor gegevensclassificatie zijn:
- Toegangsfrequentie. Een van de belangrijkste criteria voor gegevensclassificatie is hoe vaak deze wordt benaderd door gebruikers en applicaties. Gegevens die regelmatig en actief worden gebruikt (warme gegevens) moeten worden opgeslagen op hoogwaardige opslagtieren, zoals SSD’s of NVMe-schijven, om snelle toegangstijden te garanderen. Daarentegen kunnen zelden benaderde gegevens (koude gegevens) worden geplaatst op opslagtieren met lagere kosten, zoals HDD’s of cloudopslag.
- Kritikaliteit of belangrijkheid. Sommige gegevens zijn belangrijker voor de werking of nalevingsvereisten van een organisatie dan andere. Kritieke gegevens moeten mogelijk worden opgeslagen op betrouwbaardere en veerkrachtigere opslagtiers, zoals RAID (redundant array of independent disks) of cloudopslag met redundantie, om het risico op gegevensverlies te minimaliseren.
- Type gegevens. Verschillende soorten gegevens, zoals databasebestanden, multimedia-inhoud, toepassingslogs of archiefdocumenten, kunnen variërende opslagvereisten hebben. Zo kunnen multimedia-bestanden een hoge doorvoer en capaciteit vereisen, terwijl logs kunnen worden opgeslagen op langzamere opslag, zolang ze maar worden bewaard voor nalevingsdoeleinden.
- Bewaarperiode. Gegevens met specifieke bewaar- of nalevingsvereisten moeten worden opgeslagen op tiers die gegevensintegriteit en beschikbaarheid gedurende de vereiste duur kunnen garanderen. Nalevingsgegevens vereisen vaak langdurige bewaring en kunnen daarom worden opgeslagen op meer betrouwbare opslagtiers.
- Grootte. Grote gegevensobjecten kunnen baat hebben bij opslag op opslagtiers die zijn geoptimaliseerd voor capaciteit, terwijl kleine, veelgebruikte gegevens opslag met lage latentie en hoge I/O-prestaties kunnen vereisen.
- Gegevenslevenscyclus. Gegevens doorlopen verschillende fasen in hun levenscyclus, van creatie en actief gebruik tot archivering of verwijdering. Gegevensklassen moeten rekening houden met deze fasen en gegevens tussen tiers verplaatsen indien nodig. Bijvoorbeeld, nieuw gecreëerde gegevens kunnen beginnen op een hoogwaardige tier, maar geleidelijk worden verplaatst naar lagere kostentiers naarmate ze minder actief worden.
. Organisaties hebben vaak budgetbeperkingen. Gegevensklassen kunnen helpen om de opslagkosten in lijn te brengen met budgettaire overwegingen door ervoor te zorgen dat duurdere opslagbronnen worden gereserveerd voor gegevens die de kosten rechtvaardigen. - Gebruikers- of toepassingsvereisten. Verschillende gebruikers of toepassingen kunnen specifieke opslagbehoeften hebben. Gegevensklassen kunnen rekening houden met deze vereisten om ervoor te zorgen dat elke groep de nodige opslagprestaties en -capaciteit krijgt.
Zodra gegevens zijn ingedeeld in deze klassen, worden beleidsregels en algoritmen gebruikt om gegevensplaatsing en -verplaatsing binnen de getrapte opslaginfrastructuur te beheren. Dit zorgt ervoor dat gegevens voortdurend worden geoptimaliseerd voor prestaties en kostenefficiëntie, terwijl wordt voldaan aan organisatorische behoeften en toegangspatronen.
Classificatie met hete, warme en koude opslag
Het gebruikelijke type gegevensclassificatie in getrapte opslagsystemen is het classificeren van gegevens als cruciaal, heet, warm en koud. Deze klassen helpen bepalen hoe gegevens worden opgeslagen, beheerd en benaderd binnen de opslaginfrastructuur. In dit geval omvatten de gegevensklassen die worden gebruikt in getrapte opslagstrategieën:
- Cruciale gegevens. Deze gegevensklasse heeft betrekking op gegevens die absoluut essentieel zijn voor de kernactiviteiten van een organisatie. Cruciale gegevens vereisen het hoogste niveau van prestaties, betrouwbaarheid en beschikbaarheid. Ze worden meestal opgeslagen op de meest veerkrachtige en hoogwaardige opslagmedia die beschikbaar zijn, zoals redundante SSD-arrays of fouttolerante opslagsystemen.
- Hot data. Hot data verwijst naar gegevens die actief en frequent worden benaderd. Deze gegevens zijn typisch van groot belang voor de organisatie en vereisen snelle reactietijden en hoogwaardige opslagprestaties. Hot data wordt vaak opgeslagen op de hoogste opslagmedia, zoals solid-state drives (SSD’s) of NVMe-schijven, om een lage latentie en snelle toegang te garanderen.
- Warm data. Warme data vertegenwoordigt gegevens die minder vaak worden benaderd dan hot data, maar nog steeds actief worden gebruikt. Deze datagroep bevindt zich typisch op een niveau onder hot data wat betreft prestaties, zoals harde schijven met hoge prestaties (HDD’s) of hybride opslagoplossingen. Hoewel warme data misschien niet de snelste opslag nodig heeft, moet het nog steeds direct beschikbaar zijn voor efficiënte toegang.
- Koude data. Koude data omvat gegevens die zelden worden benaderd, historisch zijn of gearchiveerd zijn. Deze gegevens worden vaak als minder kritiek beschouwd en worden opgeslagen op opslagtiers met lagere kosten, zoals traditionele, langzamere HDD’s, of zelfs archiefopslagopties zoals tape of cloudgebaseerde koude opslag. De nadruk bij koude data ligt op langetermijnretentie en kostenbesparingen.
Het aantal datagroepen kan afhangen van het aantal opslagtiers in het opslagsclassificatiemodel. Organisaties kunnen gegevens op een complexere manier classificeren door de volgende datagroepen toe te voegen aan de hierboven uitgelegde klassen:
- Back-up- en rampenherstelgegevens. Gegevens die worden gebruikt voor back-up- en rampenherstel worden vaak apart gecategoriseerd. Deze gegevensklassen richten zich erop te zorgen dat gegevens betrouwbaar en snel kunnen worden hersteld in geval van gegevensverlies of systeemstoring. Back-upgegevens kunnen worden opgeslagen op op schijf gebaseerde systemen, terwijl kopieën voor langetermijnbehoud kunnen worden opgeslagen op tape of in de cloud.
- Compliancegegevens. Gegevens die moeten voldoen aan regelgevende nalevingsvereisten, zoals financiële gegevens of gezondheidsgegevens, kunnen specifieke opslagbehoeften hebben. Compliancegegevensklassen zorgen ervoor dat deze gegevens veilig worden opgeslagen, met functies zoals versleuteling en strikte toegangscontroles, en worden behouden voor de vereiste duur.
- Gebruikers- of afdelingsgegevens. Sommige organisaties classificeren gegevens op basis van de bron, zoals gegevens die worden gegenereerd door specifieke afdelingen of gebruikers. Deze aanpak kan helpen bij het toewijzen van opslagbronnen op basis van de behoeften van verschillende organisatorische eenheden.
- Tijdelijke of cachegegevens. Gegevensklassen voor tijdelijke of cachegegevens kunnen gegevens bevatten die van korte duur zijn en kunnen worden opgeslagen op opslagtiers met hoge snelheid voor snelle toegang, met het begrip dat ze kunnen worden verwijderd of vervangen wanneer ze niet langer nodig zijn.
Tier migratiegegevens . In sommige gevallen worden gegevensklassen gebruikt om gegevens te identificeren die actief worden verplaatst tussen opslagtiers op basis van toegangspatronen. Bijvoorbeeld, gegevens die beginnen als heet maar minder vaak worden benaderd na verloop van tijd, kunnen migreren naar warmere of koudere opslagtiers. - Tier migratiegegevens. In sommige gevallen worden gegevensklassen gebruikt om gegevens te identificeren die actief tussen opslaglagen bewegen op basis van toegangspatronen. Bijvoorbeeld, gegevens die aanvankelijk heet zijn maar in de loop van de tijd minder vaak worden benaderd, kunnen migreren naar warmere of koudere opslaglagen.
Deze gegevensklassen kunnen dienen als richtlijnen voor opslagbeheerders en geautomatiseerde opslagbeheersystemen om geïnformeerde beslissingen te nemen over waar gegevens in een gestapeld opslaginfrastructuur moeten worden geplaatst.
Multi-Tiered Opslagtypen
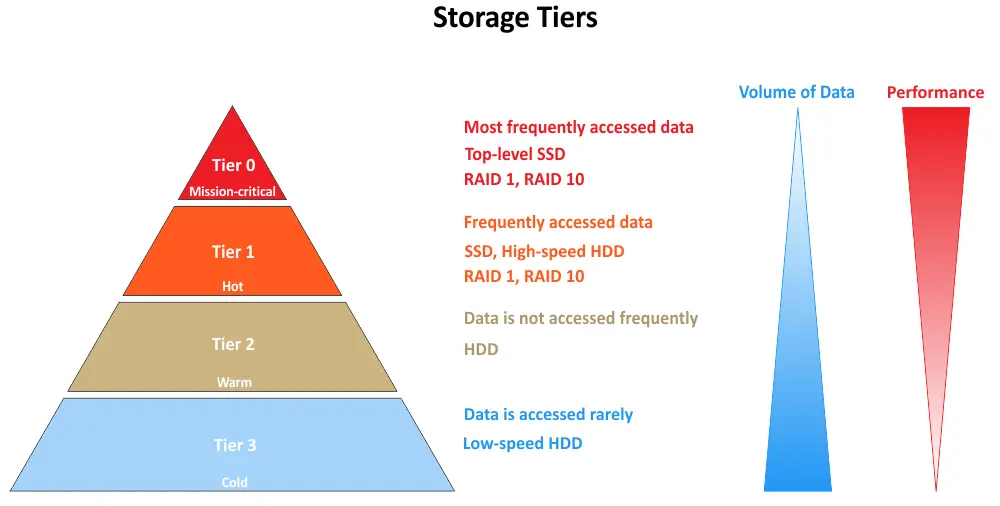
Multi-tiered opslag verwijst naar een opslagarchitectuur waarbij gegevens worden ingedeeld in verschillende lagen op basis van hun prestatie- en toegankelijkheidsvereisten. Elke laag vertegenwoordigt een specifiek niveau van opslagprestaties en -kosten. Het doel is ervoor te zorgen dat gegevens op de meest geschikte laag worden opgeslagen om zowel prestaties als kostenefficiëntie te optimaliseren. Hieronder kunt u de meest voorkomende opslaglagen zien, beginnend met Tier 0:
- Tier 0 vertegenwoordigt de meest presterende opslaglaag in een multi-tiered opslagsysteem. Het bestaat vaak uit de snelste en duurste opslagmedia die beschikbaar zijn, zoals enterprise-grade solid-state drives (SSDs) of NVMe (Non-Volatile Memory Express) SSDs. Gegevens die in Tier 0 worden opgeslagen, zijn meestal mission-critical en vereisen zeer lage latentie, hoge I/O-prestaties en snelle gegevenstoegang. Het wordt gebruikt voor applicaties en gegevens die de hoogste prestatieniveaus vereisen.
- Tier 1 is het volgende niveau lager in termen van prestaties en kosten. Het bestaat meestal uit high-performance harde schijven (HDDs), hybride opslagarrays (die SSDs en HDDs combineren) of snellere SSDs, die niet zo duur zijn als die in Tier 0. Data in Tier 1 is belangrijk, maar heeft mogelijk niet de absoluut snelste opslag nodig. Dit niveau is geschikt voor applicaties en data die goede prestaties nodig hebben, maar een iets hogere latentie kunnen tolereren in vergelijking met Tier 0 data.
- Tier 2 vertegenwoordigt een lager-kosten opslagniveau met enigszins tragere prestaties in vergelijking met Tier 1. Het omvat vaak traditionele HDDs of cloud-gebaseerde opslagoplossingen. Data in Tier 2 wordt meestal minder vaak geopend of is minder kritiek voor real-time operaties. Dit niveau is geschikt voor archiefdata, back-ups en data die langere toegangs-tijden kunnen tolereren.
- Tier 3 is het laagste-kosten opslagniveau in een multi-tiered opslagsysteem. Het omvat meestal archiefopslagoplossingen, zoals tapelibraries en cloud-gebaseerde koud opslag. Data in Tier 3 wordt zelden geopend en wordt voornamelijk bewaard voor naleving, regelgeving of lange-termijn archivering. Het biedt de laagste prestaties, maar de meest kosteneffectieve opslag.
Sommige organisaties die voornamelijk on-premises opslag gebruiken, wijden extra speciale niveaus toe voor opslag in het publieke cloud en back-upopslag:
- Cloud Tier. In sommige meerlagige opslagarchitectuuren wordt een aparte Cloud Tier gebruikt om gegevens op te slaan in een cloudopslagdienst zoals Amazon S3 of Azure Blob Storage. Dit stelt organisaties in staat om gebruik te maken van schaalbare en kosteneffectieve cloudopslag voor gegevens die misschien niet netjes in on-premises lagen passen. Gegevens in de cloud tier kunnen over het internet worden geaccepteerd wanneer nodig.
- Backup Tier. Hoewel het niet altijd wordt beschouwd als een primaire opslaglaag, is back-upopslag een cruciale onderdeel van de opslaghiërarchie. Back-upgegevens worden op schijfgebaseerde systemen of tapelibraries opgeslagen, afhankelijk van de back-upstrategie van de organisatie. De focus ligt op gegevensbescherming en snelle herstel in geval van gegevensverlies of rampen.
Hoeveel lagen worden meestal gebruikt door organisaties?
Het aantal lagen dat door organisaties wordt gebruikt in hun opslagarchitectuur kan sterk variëren afhankelijk van hun specifieke behoeften, budgetbeperkingen en de complexiteit van hun gegevensbeheervereisten. In de praktijk implementeren veel organisaties echter vaak een drietal opslaghiërarchieën als uitgangspunt (Tier 0, Tier 1, Tier 2).
Veel organisaties beginnen met deze drie lagen als basis en passen vervolgens hun opslaginfrastructuur aan om aan hun specifieke behoeften te voldoen. Ze kunnen extra lagen toevoegen of speciale opslagklassen aannemen als hun gegevensvereisten zich ontwikkelen. Bijvoorbeeld:
- Sommige organisaties kunnen een Tier 4 of Tier 5 toevoegen voor langetermijn, diepgaand archiefopslag, wat technologieën kan omvatten zoals tapelibraries of zeer goedkope cloudopslag.
- Anderen kunnen een Cloud Tier implementeren voor offsite back-ups en rampenhersteldoeleinden, met cloudopslagdiensten zoals Amazon S3 of Azure Blob Storage.
- Hybride cloudstrategieën kunnen ook meer lagen introduceren, inclusief cloud-based lagen voor gegevens die naadloos moeten worden verplaatst tussen on-premises en cloudopslag.
Het belangrijkste is om een opslagarchitectuur te ontwerpen die aansluit bij de gegevensbereikpatronen, prestatievereisten en budgettaire overwegingen van de organisatie. Het is ook belangrijk om effectieve gegevensbeheer- en laagindelingspolitieken in te voeren om ervoor te zorgen dat gegevens op de juiste laag worden opgeslagen op basis van de veranderende behoeften van deze gegevens in de loop van de tijd. Terwijl gegevensopslagtechnologieën zich blijven ontwikkelen, kunnen organisaties hun gelaagde opslagstrategieën aanpassen om te profiteren van nieuwe innovaties en kosteneffectieve oplossingen.
Deze veelvoorkomende opslaglagen kunnen worden samengevat in een tabel met korte uitleg en typische gebruiksgevallen:
| Tiernummer | Tier-naam | Uitleg | Typische gebruiksvoorbeelden |
| Tier 0 | Ultra-snelle SSD | Beste opslagprestaties, lage latentie | Kritieke databases, real-time applicaties |
| Tier 1 | Hoge-prestatie SSD | Goede balans tussen snelheid en kosten | Algemene toepassingsgegevens, virtuele machines |
| Tier 2 | Hybride opslag | Mix van SSDs en HDDs, kostenefficiënt | Back-upopslag, secundaire gegevens, bestandssharen |
| Tier 3 | Nearline HDD | Back-upopslag, secundaire gegevens, bestandssharen | Archiefgegevens, langetermijnopslag |
| Tier 4 | Koudelager | Laagkostende, zeer hoge capaciteit, trage toegang | Spijtige archiefgegevens |
| Cloud Tier | Cloudopslag | Schaalbaar cloud-based opslag | Offsite back-ups, rampenherstel, gegevensdeling |
Let op dat de namen en kenmerken van opslagentiers kunnen variëren tussen organisaties en opslagleveranciers. Het bovenstaande overzicht biedt een algemene indruk van veelvoorkomende opslagentiers en hun typische gebruiksvoorbeelden, maar specifieke implementaties kunnen afwijken op basis van de behoeften van de organisatie en beschikbare technologieën.
Waar opslagentiers worden gebruikt
Opslagentiering is een strategie voor opslagbeheer die zowel on-premises (binnen de eigen datacenters of privé-cloudomgevingen van een organisatie) als in de publieke cloud kan worden gebruikt. Het is een flexibele aanpak die kan worden toegepast op verschillende opslagarchitectuur om de gegevensplaatsing en toegangspatronen te optimaliseren.
Opslagtiersysteem on-premises
Opslagtiersysteem wordt gebruikt in de volgende omgevingen die zich richten op de on-premises (lokale) infrastructuur:
- Traditionele datacentra. In traditionele on-premises datacentra wordt opslagtiersysteem vaak gebruikt om gegevens op verschillende soorten opslagmedia te beheren, zoals SSD, HDD en tape libraries. Organisaties implementeren opslagtiersysteem om prestaties, kosten en gegevensbeschikbaarheid binnen hun eigen infrastructuur te optimaliseren.
- Private clouds. Veel private cloud-omgevingen integreren opslagtiersysteem om gegevens efficiënt te beheren over verschillende soorten opslagbronnen. Dit is vooral belangrijk in private cloud-setups waar resources dynamisch moeten worden toegewezen om verschillende workloads te ondersteunen.
- Hybride clouds. In een hybride cloud-omgeving, die on-premises infrastructuur combineert met publieke cloud-resources, kan opslagtiersysteem worden gebruikt om de gegevensplaatsing te optimaliseren over beide omgevingen. Organisaties kunnen tiersbeleid gebruiken om te bepalen welke gegevens on-premises moeten blijven en welke naar de publieke cloud moeten worden verplaatst voor kostenefficiëntie of schaalbaarheid.
Opslagtiersysteem in de publieke cloud
Wat de publieke cloud betreft, wordt opslagtiersysteem gebruikt in de volgende omgevingen:
- Openbare cloudopslagdiensten. Openbare cloudproviders zoals Amazon Web Services (AWS), Microsoft Azure en Google Cloud Platform (GCP) bieden hun eigen opslaglaagopties aan als onderdeel van hun cloudopslagdiensten. Bijvoorbeeld, AWS biedt S3-opslagklassen (Standard, Intelligent-Tiering, Glacier, enz.), elk afgestemd op verschillende prestatie- en kosteneisen.
- Objectopslag. Objectopslag diensten in de openbare cloud ondersteunen vaak opslaglaagindeling om klanten in staat te stellen de meest geschikte opslagklasse voor hun gegevens te kiezen. Dit is voordelig voor het optimaliseren van kosten en toegangstijden.
Geautomatiseerde Opslaglaagindeling
Geautomatiseerde opslaglaagindeling en opslaglaagoptimalisatie zijn technieken die worden gebruikt in moderne gegevensopslagbeheer om ervoor te zorgen dat gegevens op de meest geschikte opslaglaag worden geplaatst en op het juiste moment.
Geautomatiseerde opslaglaagindeling is een gegevensbeheertechniek die inhoudt dat gegevens automatisch en dynamisch worden verplaatst tussen verschillende opslaglagen op basis van specifieke beleidsregels en criteria. Deze beleidsregels worden meestal gedefinieerd door opslagbeheerders of ingesteld door intelligente opslagbeheersoftware. Het primaire doel van geautomatiseerde opslaglaagindeling is om de inzet van opslagbronnen te optimaliseren door ervoor te zorgen dat gegevens op elk gegeven moment op de meest geschikte laag worden opgeslagen.
Geautomatiseerde opslagtierarchievorming stelt u in staat om uw opslagtierarchievorming dynamisch te optimaliseren, waarbij continu gecontroleerd wordt op gegevensgebruik en toegang om gegevensprioriteiten en vereiste tierarchievormingsniveaus te bepalen. Wanneer u geautomatiseerde opslag gebruikt, stelt u uw gewenste drempels in en laat de automatisering het overige over.
Wanneer gegevensgebruik de vooraf bepaalde drempels bereikt, wordt het dienovereenkomstig verplaatst. Als de frequentie van gegevenstoegang toeneemt, wordt het verplaatst naar een laagdrempelige opslag. Wanneer gegevens ongebruikt raken, wordt het verplaatst naar een goedkopere, hoger latentie opslag. Deze aanpak optimaliseert zowel uw kosten als prestaties met minimale inspanning en zonder dat er voortdurende onderhoud nodig is.
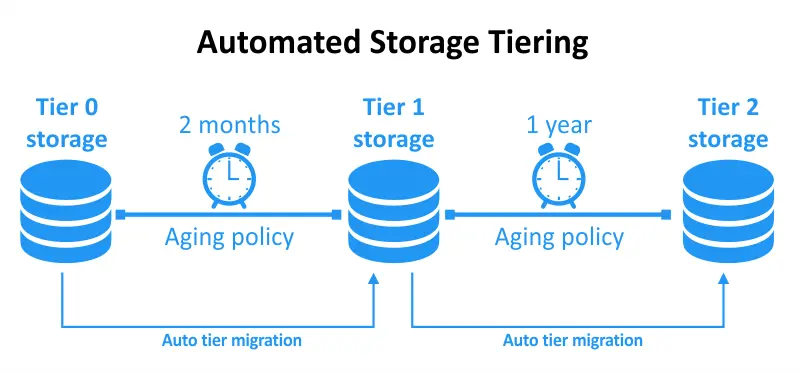
Geautomatiseerde opslagtierarchievorming faciliteert beleidsgestuurde gegevensoverdrachten tussen opslaglagen, waardoor het uitlijnt met gebruikersprestaties en capaciteitsbehoeften. Deze functie werkt efficiënt samen met uw bestaande gestructureerde opslagarchitectuur en stroomlijnt gegevensbeheer via automatisering. Geautomatiseerde opslagtierarchievorming verbetert de prestatieoptimalisatie en kostenefficiëntie door realtime aanpassing en snelle gegevensverplaatsing.
Opslaglaag optimalisatie is een breder concept dat verschillende strategieën omvat, waaronder geautomatiseerde opslagtierarchievorming, om ervoor te zorgen dat het opslaginfrastructuur van een organisatie efficiënt wordt beheerd en benut. Hoewel geautomatiseerde opslagtierarchievorming een sleutelcomponent is van opslaglaagoptimalisatie, kunnen er ook andere technieken en best practices betrokken zijn.
Tierarchievorming versus caching
Tiering en caching zijn twee verschillende technieken die worden gebruikt in dataopslag en -beheer – ze dienen verschillende doeleinden. De termen tiering en caching worden vaak verward, maar ze verwijzen naar twee verschillende opslagversnellingstechnieken. Beide betreffen het plaatsen van regelmatig geaccesseerde of hete data op snelle media zoals flash. De gelijkenissen eindigen echter grotendeels daar.
Caching slaat tijdelijk data op in een hoogwaardige middel zoals DRAM of vaste-state geheugen om de prestaties te verbeteren. De cache bevindt zich tussen de applicatie en de back-end opslag. Dezelfde data bevindt zich ook op een lagere opslaglaag, meestal een HDD. Data wordt gekopieerd naar de cache, maar de oorspronkelijke data blijft op zijn oorspronkelijke locatie. Caching is in wezen een enkele transactie en de cache maakt data ongeldig na gebruik.
Opslagtiering, aan de andere kant, beweegt data fysiek tussen opslagapparaten. Wanneer data wordt geïdentificeerd als heet, wordt deze data verplaatst naar een snelle laag, waardoor de standaardlaag geen kopie meer bevat. Wanneer de data afkoelt, wordt het teruggeplaatst naar de standaardlaag. Opslagtiering bevat het verplaatsen van data in plaats van het alleen kopiëren ervan, zowel van langzamere opslag naar snellere opslag als vice versa.
Zowel opslagtiering als caching verbeteren de toegankelijkheid van data, maar ze verschillen in hoe ze opslag gebruiken voor regelmatig geaccesseerde data. Caching maakt kopieën, terwijl opslagtiering data identificeert en verplaatst zonder extra kopieën te creëren.
Zo, het inzetten van opslag legt de nadruk op het optimaliseren van de langetermijngegevensplaatsing over verschillende lagen van opslag om een evenwicht te bereiken tussen prestaties en kosten, terwijl caching erop gericht is om gegevenstoegang te versnellen door vaak gebruikte gegevens tijdelijk op te slaan in een snelle buffer. De keuze tussen tiering en caching hangt af van de specifieke eisen van de toepassing of opslagsysteem en de aard van de gegevenstoegangspatronen. In sommige gevallen kunnen organisaties beide technieken gecombineerd gebruiken om de beste algehele prestaties en kostenefficiëntie te bereiken.
Gedegradeerde opslag en hiërarchische opslagbeheer
Gedegradeerde opslag en hiërarchische opslagbeheer zijn beide strategieën die worden gebruikt in het gegevensopslagbeheer, maar ze verschillen in hun granulariteit, gegevensbewegingsmechanismen en primaire doelstellingen. Gedegradeerde opslag richt zich op het categoriseren van gegevens in discrete lagen van opslagmedia op basis van kenmerken, terwijl hiërarchisch opslagbeheer zich richt op het transparant migreren van afzonderlijke bestanden of objecten tussen primaire en secundaire opslag om de efficiëntie en kosteneconomie van de primaire opslag te verbeteren.
Voordelen van opslagtiering
Opslagtiering biedt organisaties die op zoek zijn naar optimalisatie van hun gegevensopslaginfrastructuur verschillende significante voordelen. De belangrijkste voordelen van het implementeren van opslagtiering zijn:
- Verbetering van de prestaties. Door vaak gebruikte of kritieke gegevens op te slaan op hoogwaardige opslaglagen, zoals solid-state drives of NVMe-opslag, kan opslagtiering de systeemprestaties aanzienlijk verbeteren. Dit resulteert in verminderde latentie en snellere gegevenstoegangstijden voor toepassingen en gebruikers, wat leidt tot verbeterde productiviteit en gebruikersvoldoening.
- Efficiente middelenbenutting. Opslagtierarchievorming zorgt ervoor dat elke opslaglaag efficiënt wordt gebruikt, waardoor er geen overbesteding van hoogwaardige opslagmedia ontstaat en onderbenutting van goedkopere opslag wordt voorkomen. Het maximaliseert de opbrengst op investering (ROI) voor opslaginfrastructuur.
- Kostenoptimalisatie. Opslagtierarchievorming helpt organisaties dure opslagmiddelen alleen toe te wijzen aan gegevens die hoge prestaties vereisen, terwijl minder kritieke of zelden geaccesseerde gegevens op goedkopere lagen kunnen worden opgeslagen, zoals harde schijven of cloudopslag. Deze kostenoptimalisatie leidt tot potentiële kostenbesparingen in hardware en operationele uitgaven.
- Gebalanceerde workloads. Opslagtierarchievorming kan helpen gegevens en workloads over verschillende lagen te verdelen, waardoor er minder concurrentie is om middelen. Dit is met name waardevol in omgevingen met gemengde workloads, waar sommige toepassingen hoge prestaties vereisen, terwijl andere minder veeleisende opslagvereisten hebben.
- Adaptief gegevensbeheer. Gegevenstoegangspatronen kunnen in de loop van de tijd veranderen. Opslagtierarchievormingsoplossingen analyseren deze patronen voortdurend en bewegen gegevens automatisch tussen lagen indien nodig. Deze aanpasbaarheid zorgt ervoor dat gegevens op het meest geschikte opslagniveau blijven, zelfs als toegangsvereisten veranderen.
- Schaalbaarheid. Naarmate de behoefte aan gegevensopslag toeneemt, stelt opslagtierarchievorming organisaties in staat hun opslaginfrastructuur efficiënt te schalen. Nieuwe opslaglagen kunnen worden toegevoegd of bestaande lagen uitgebreid indien nodig om toenemende gegevensvolumes en prestatievereisten te accommoderen.
- Vereenvoudigd gegevensbeheer. Opslagtiersystemen bevatten vaak geautomatiseerde beleidsregels en beheertools die gegevensbeheertaken vereenvoudigen. Dit vermindert de administratieve overhead die samenhangt met handmatige gegevensplaatsing en migratie.
- Compliantie en retentie. Organisaties met regelgevings- of compliantievereisten profiteren van opslagtiers door ervoor te zorgen dat gegevens worden opgeslagen en bewaard volgens juridische voorschriften. Compliantiegegevens kunnen worden beheerd op specifieke opslagtiers met de noodzakelijke beveiliging en retentiebeleid.
- Gegevensbescherming en rampenherstel. Door gegevens te classificeren op basis van belang, helpt opslagtiers organisaties bij het prioriteren van gegevensbeschermings inspanningen. Belangrijke gegevens kunnen worden opgeslagen op robuuste, redundante tiers, waardoor de beschikbaarheid en herstelbaarheid van gegevens in geval van storingen of rampen wordt gegarandeerd.
- Geoptimaliseerde back-up en herstel. Door gegevens te scheiden op basis van belang en toegangspatronen, kan opslagtiers helpen bij het prioriteren van gegevens voor back-up en hersteloperaties. Belangrijke gegevens kunnen vaker worden geregistreerd, terwijl minder belangrijke gegevens onderworpen kunnen zijn aan langere back-upintervallen.
Terwijl het primaire doel van opslaglagen is om data-plaatsing te optimaliseren en opslagkosten te beheersen, kunnen de voordelen die ze bieden ook de organisatie’s mogelijkheden om zich te herstellen van rampen versterken. Redundantie en kosteneffectief gegevensretentie verhogen de kansen op succesvolle gegevensherstel. Het helpt organisaties om continuïteit van de zaken te behouden en zich te herstellen van rampen met minimale gegevensverlies en downtime, wat uiteindelijk hun algehele rampenherstelbereidheid verbetert.
Best Practices voor Opslaglagen
Opslaglagen is een waardevolle techniek voor het optimaliseren van gegevensopslag, maar het is belangrijk om best practices te volgen om zijn effectiviteit en efficiëntie te garanderen. De best practices voor opslaglagen zijn als volgt:
- Begrijp je gegevens. Voer een grondige analyse uit van je gegevens om hun kenmerken, toegangspatronen en belang te begrijpen. Niet alle gegevens hebben behoefte aan gelagen opslag, daarom moet je identificeren welke gegevenssets het meest zouden profiteren van gelagde opslag.
- Kies het juiste opslagmedium. Kies opslagmedia voor elke laag op basis van de prestatie- en budgetvereisten van je organisatie. Solid-state drives, harde schijven, cloudopslag en tapelibraries zijn courante opties.
- Regelmatig controleren en aanpassen. Blijf continu je opslagomgeving monitoren om data-toegangspatronen en laaggebruik te volgen. Pas laagbeleid aan als nodig om veranderende vereisten weer te geven. Regelmatig controleren en afstemmen van je beleid is essentieel voor optimale prestaties.
- Gebruik gegevensclassificatie en -tagging. Gebruik metadata en gegevenstagging om gegevens te classificeren. Deze metadata kan worden gebruikt door uw tieringssysteem om beter geïnformeerde beslissingen te nemen over de plaatsing van gegevens.
- Kies kritieke gegevens prioriteit. Zorg ervoor dat missiekritieke en regelmatig geaccesseerde gegevens worden geplaatst op hoogwaardige lagen. Dit kan verschillende beleidsregels of prioriteitsniveaus voor verschillende soorten gegevens vereisen.
- Sluit redundantie in kritieke lagen. Als u missiekritieke gegevens opslaat op hoogwaardige lagen, overweeg redundantiemechanismen zoals RAID (Redundant Array of Independent Disks) om gegevensverlies te voorkomen door hardwarestoringen.
- Implementeer geautomatiseerde tieringsbeleidsregels. Definieer duidelijke, geautomatiseerde beleidsregels voor het verplaatsen van gegevens tussen lagen. Deze beleidsregels moeten rekening houden met factoren zoals toegangsfrequentie, ouderdom van gegevens en prestatievereisten. Het automatiseren van de gegevensplaatsing en migratie helpt ervoor te zorgen dat gegevens altijd op de juiste laag staan.
- Bied beveiliging en toegangscontroles. Implementeer geschikte beveiligingsmaatregelen en toegangscontroles voor gegevens op alle lagen. Zorg ervoor dat gevoelige gegevens worden beschermd en alleen toegankelijk zijn voor geautoriseerde gebruikers.
- Back-up en rampenherstel. Maak plannen voor gegevensbescherming en rampenherstel. Zorg ervoor dat back-up- en herstelstrategieën zijn afgestemd op uw aanpak van opslagtiering. Kritieke gegevens moeten vaker worden gebackup en veilig worden bewaard.
- Schaalbaarheid. Ontwerp uw opslagtieringsstrategie om schaalbaar te zijn. Als uw behoefte aan gegevensopslag groeit, bereidt u zich voor om meer lagen toe te voegen of bestaande lagen uit te breiden.
- Overweeg hybride cloudoplossingen. Afhankelijk van de behoeften van uw organisatie, overweeg het integreren van cloudopslag als een van uw opslaglagen. Hybride cloudoplossingen kunnen schaalbaarheid en flexibiliteit bieden.
- Blijf de technologie regelmatig evalueren. Blijf op de hoogte van de ontwikkelingen in opslagtechnologie. Naarmate de technologie evolueert, kunnen nieuwe opslagmedia en oplossingen kosteneffectiever en geschikter worden voor uw opslaglagen.
NAKIVO Backup & Replication en Backup Storage Tiering
NAKIVO Backup & Replication is een moderne oplossing voor gegevensbescherming en rampenherstel die kan werken met verschillende opslaglagen, waardoor u uw back-up- en herstelstrategieën kunt optimaliseren op basis van hun specifieke behoeften en beschikbare opslaginfrastructuur. De NAKIVO-oplossing ondersteunt verschillende opslagtypen, waaronder on-premises opslag, cloudopslag en deduplicatie-apparaten.
U kunt NAKIVO Backup & Replication configureren om verschillende opslaglagen te gebruiken voor back-ups. Bijvoorbeeld, kritieke back-ups kunnen op een high-performance opslag (Tier 1) worden opgeslagen voor snel herstel, terwijl minder kritieke back-ups kunnen worden verplaatst naar een goedkopere opslag (Tier 2 of cloud) voor langetermijnretentie.
Het product biedt functies zoals back-up kopiëren en replicatie, die de creatie van extra kopieën van back-ups op verschillende opslaglagen mogelijk maken. Dit verhoogt de redundantie van gegevens en de paraatheid voor rampenherstel door back-ups op meerdere locaties of opslaglagen te plaatsen.
Je kunt retentiebeleid definiëren binnen NAKIVO Backup & Replication om automatisch de back-upgegevens te beheren op basis van je indelingstrategie. Bijvoorbeeld, back-ups kunnen voor een kortere periode worden bewaard op T1 en vervolgens worden overgezet naar T2 voor langdurige retentie.
De NAKIVO-oplossing ondersteunt populaire cloudopslagproviders. Dit betekent dat je gemakkelijk cloudopslag kunt opnemen als opslagtier voor offsite back-ups, waardoor de noodzaak voor extra on-premises infrastructuur wordt verminderd.
Conclusie
Multi-tiered opslagarchitecturen stellen organisaties in staat om opslagmiddelen toe te wijzen op basis van de specifieke behoeften van hun gegevens. Door gegevens op de meest geschikte tier te plaatsen, kunnen organisaties zowel prestaties als kosten optimaliseren, zodat kritieke gegevens de noodzakelijke prestaties ontvangen, terwijl minder kritieke of zelden benaderde gegevens kosteneffectief worden opgeslagen. Geautomatiseerde gegevenstieringsbeleid en beheertools zorgen ervoor dat gegevens worden verplaatst tussen tiers naarmate toegangspatronen en vereisten in de loop van de tijd veranderen.