













Les organisations d’aujourd’hui doivent utiliser le stockage de manière rationnelle car de grandes quantités de données peuvent augmenter les coûts de stockage et entraîner une prolifération des données. Les supports de stockage des données diffèrent en termes de coût, de vitesse d’écriture/lecture, etc., et différents types de données devraient être stockés sur les supports les plus efficaces afin d’économiser des coûts et des ressources.
Par exemple, stocker des sauvegardes sur des dispositifs SSD (disques à semi-conducteurs) haute vitesse est inutilement coûteux car la haute vitesse des SSD n’est pas nécessaire pour ce type de données secondaires. En revanche, stocker des machines virtuelles de production (VMs) sur des disques durs (HDDs) à faible RPM (révolutions par minute) peut être économique mais ne répondra pas aux exigences de performance des systèmes principaux.
Pour cette raison, les types de stockage devraient être catégorisés pour utiliser chaque type de stockage afin de stocker les données appropriées en utilisant le stockage par niveaux.
Qu’est-ce que le stockage par niveaux ?
Le stockage par niveaux est une stratégie de gestion du stockage des données utilisée pour optimiser les performances et l’efficacité des coûts d’un système de stockage en catégorisant les données en différents niveaux en fonction de leurs caractéristiques et de leurs schémas d’accès. L’objectif principal du stockage par niveaux est de garantir que les données les plus fréquemment consultées et les plus critiques sont stockées sur des supports de stockage haute performance, tandis que les données moins fréquemment consultées ou moins critiques sont stockées sur des supports de stockage moins coûteux.
Cette approche permet aux organisations de stocker leurs données sur différents types de supports de stockage, tels que des disques à semi-conducteurs (SSDs) rapides et coûteux ou des disques durs (HDDs) plus lents mais plus économiques, en fonction de la valeur des données et des schémas d’utilisation.
Le stockage par niveaux commence par classer les données en différentes catégories ou niveaux en fonction de critères tels que la fréquence d’accès, l’importance et les exigences de performance. Cette classification peut changer avec le temps si le processus de travail le nécessite. Le nombre et les types de niveaux de stockage peuvent varier – de 3 à 7 – en fonction de l’infrastructure de stockage.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
Classes de données pour le stockage par niveaux
Les classes de données dans une architecture de stockage par niveaux se réfèrent à la catégorisation ou à la classification des données en fonction d’attributs ou de caractéristiques spécifiques. Ces classes créent une hiérarchie de données et aident à déterminer où les données doivent être stockées dans un système de stockage par niveaux. Cette approche garantit que les données sont placées sur le niveau de stockage le plus approprié pour équilibrer les performances, les coûts et l’accessibilité. Les spécificités des classes de données peuvent varier en fonction des besoins de l’organisation et de l’infrastructure de stockage. Les attributs couramment utilisés pour la classification des données sont:
- Fréquence d’accès. L’un des principaux critères de classification des données est la fréquence à laquelle elles sont consultées par les utilisateurs et les applications. Les données qui sont utilisées régulièrement et activement (données chaudes) doivent être stockées sur des niveaux de stockage haute performance, tels que des SSD ou des disques NVMe, pour garantir des temps d’accès rapides. En revanche, les données consultées rarement (données froides) peuvent être placées sur des niveaux de stockage moins coûteux, tels que des disques durs HDD ou du stockage cloud.
- La criticité ou l’importance. Certaines données sont plus critiques pour les opérations d’une organisation ou les exigences de conformité que d’autres. Les données critiques peuvent nécessiter d’être stockées sur des niveaux de stockage plus fiables et résilients, tels que le RAID (ensemble redondant de disques indépendants) ou le stockage cloud avec redondance, afin de minimiser le risque de perte de données.
- Type de données. Différents types de données, tels que les fichiers de base de données, le contenu multimédia, les journaux d’application ou les documents d’archivage, peuvent avoir des exigences de stockage variables. Par exemple, les fichiers multimédias peuvent nécessiter un débit et une capacité élevés, tandis que les journaux peuvent être stockés sur un stockage plus lent tant qu’ils sont conservés à des fins de conformité.
- Période de rétention. Les données avec des exigences spécifiques de conservation ou de conformité peuvent nécessiter d’être stockées sur des niveaux qui peuvent garantir l’intégrité et la disponibilité des données pendant la durée requise. Les données de conformité nécessitent souvent une conservation à long terme et peuvent donc être stockées sur des niveaux de stockage plus fiables.
- Taille. Les grands objets de données peuvent bénéficier d’être stockés sur des niveaux de stockage optimisés pour la capacité, tandis que les petites données fréquemment accédées peuvent nécessiter un stockage avec une latence faible et des performances d’E/S élevées.
- Cycle de vie des données. Les données passent par différentes étapes de leur cycle de vie, de la création et de l’utilisation active à l’archivage ou à la suppression. Les classes de données doivent prendre en compte ces étapes et déplacer les données entre les niveaux au besoin. Par exemple, les données nouvellement créées peuvent commencer sur un niveau haute performance mais être progressivement déplacées vers des niveaux moins coûteux à mesure qu’elles deviennent moins actives.
- Sensibilité aux coûts. Les organisations ont souvent des contraintes budgétaires. Les classes de données peuvent aider à aligner les coûts de stockage des données avec les considérations budgétaires en veillant à ce que les ressources de stockage plus coûteuses soient réservées aux données justifiant le coût.
- Exigences de l’utilisateur ou de l’application. Différents utilisateurs ou applications peuvent avoir des besoins de stockage spécifiques. Les classes de données peuvent prendre en compte ces exigences pour garantir que chaque groupe reçoive les performances et la capacité de stockage nécessaires.
Une fois que les données sont classées dans ces classes, des politiques et des algorithmes sont utilisés pour gérer le placement et le déplacement des données au sein de l’infrastructure de stockage à niveaux. Cela garantit que les données sont continuellement optimisées pour les performances et l’efficacité des coûts tout en répondant aux besoins organisationnels et aux schémas d’accès.
Classification avec stockage chaud, tiède et froid
Le type commun de classification des données dans les systèmes de stockage à niveaux consiste à classer les données comme étant critiques pour la mission, chaudes, tièdes et froides. Ces classes aident à déterminer comment les données sont stockées, gérées et consultées au sein de l’infrastructure de stockage. Dans ce cas, les classes de données utilisées dans les stratégies de stockage à niveaux comprennent:
- Données critiques pour la mission. Cette classe de données concerne les données qui sont absolument essentielles aux opérations centrales d’une organisation. Les données critiques pour la mission nécessitent le plus haut niveau de performances, de fiabilité et de disponibilité. Elles sont généralement stockées sur les supports de stockage les plus résilients et les plus performants disponibles, tels que des matrices SSD redondantes ou des systèmes de stockage tolérants aux pannes.
- Données chaudes. Les données chaudes désignent les données qui sont activement et fréquemment consultées. Ces données sont généralement d’une importance capitale pour l’organisation et nécessitent des temps de réponse rapides et un stockage haute performance. Les données chaudes sont souvent stockées sur les supports de stockage de plus haut niveau, tels que les lecteurs à semi-conducteurs (SSD) ou les lecteurs NVMe, pour garantir une latence faible et un accès rapide.
- Données tièdes. Les données tièdes représentent des données qui sont consultées moins fréquemment que les données chaudes mais qui sont toujours utilisées activement. Cette classe de données réside généralement sur un niveau inférieur aux données chaudes en termes de performance, telles que les disques durs à haute performance (HDD) ou les solutions de stockage hybrides. Bien que les données tièdes ne nécessitent pas le stockage le plus rapide, elles doivent néanmoins être facilement accessibles pour un accès efficace.
- Données froides. Les données froides comprennent les données qui sont rarement consultées, historiques ou archivées. Ces données sont souvent considérées comme moins critiques et sont stockées sur des niveaux de stockage moins coûteux, qui peuvent être des disques durs traditionnels plus lents, ou même des options de stockage d’archives telles que la bande magnétique ou le stockage froid basé sur le cloud. L’accent sur les données froides est mis sur la rétention à long terme et les économies de coûts.
Le nombre de classes de données peut dépendre du nombre de niveaux de stockage dans le modèle de classification de stockage. Les organisations peuvent classer les données de manière plus complexe en utilisant les classes de données suivantes en plus des classes expliquées ci-dessus :
- Sauvegarde et récupération après sinistre des données. Les données utilisées à des fins de sauvegarde et de reprise après sinistre sont souvent catégorisées séparément. Ces classes de données se concentrent sur le fait de garantir que les données puissent être restaurées de manière fiable et rapidement en cas de perte de données ou de défaillance du système. Les données de sauvegarde peuvent être stockées sur des systèmes à base de disques, tandis que des copies de rétention à long terme pourraient être stockées sur bande ou dans le cloud.
- Données de conformité. Les données qui doivent se conformer aux exigences de conformité réglementaire, telles que les données financières ou de santé, peuvent avoir des besoins de stockage spécifiques. Les classes de données de conformité garantissent que ces données sont stockées de manière sécurisée, avec des fonctionnalités telles que le chiffrement et des contrôles d’accès stricts, et conservées pendant la durée requise.
- Données utilisateur ou départementales. Certaines organisations classent les données en fonction de leur source, telles que les données générées par des départements ou des utilisateurs spécifiques. Cette approche peut aider à allouer les ressources de stockage en fonction des besoins des différentes unités organisationnelles.
- Données temporaires ou de cache. Les classes de données pour les données temporaires ou de cache peuvent inclure des données qui ont une durée de vie courte et peuvent être stockées sur des niveaux de stockage haute vitesse pour un accès rapide, avec la compréhension qu’elles peuvent être jetées ou remplacées lorsqu’elles ne sont plus nécessaires.
Données de migration de niveau . Dans certains cas, des classes de données sont utilisées pour identifier des données qui se déplacent activement entre les niveaux de stockage en fonction des modèles d’accès. Par exemple, des données qui commencent comme chaudes mais deviennent moins fréquemment consultées avec le temps peuvent migrer vers des niveaux de stockage plus tièdes ou plus froids. - Données de migration de niveau. Dans certains cas, les classes de données sont utilisées pour identifier les données qui se déplacent activement entre les niveaux de stockage en fonction des modèles d’accès. Par exemple, les données qui commencent comme chaudes mais qui sont moins fréquemment consultées avec le temps peuvent migrer vers des niveaux de stockage plus chauds ou plus froids.
Ces classes de données peuvent servir de lignes directrices pour les administrateurs de stockage et les systèmes de gestion automatique du stockage pour prendre des décisions éclairées sur l’emplacement des données dans une infrastructure de stockage hiérarchisée.
Types de stockage multi-niveaux
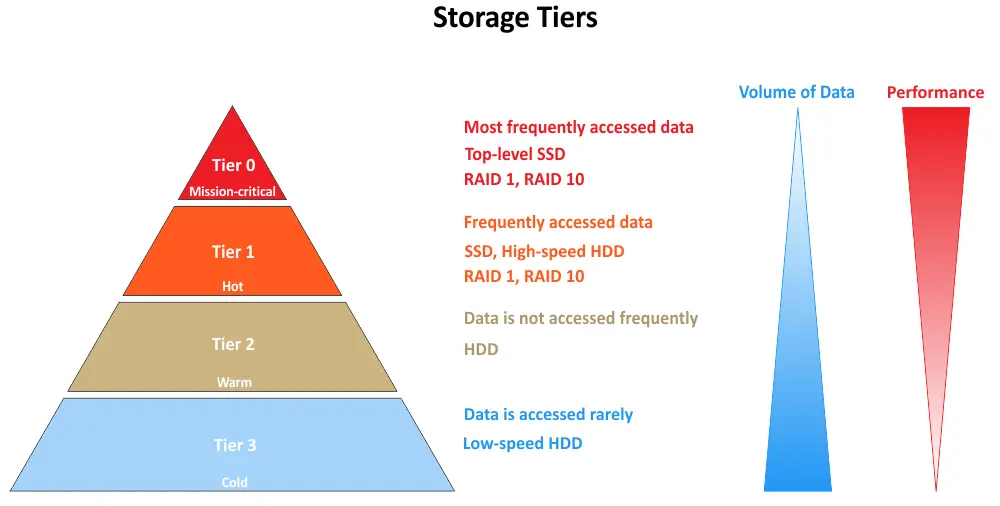
Le stockage multi-niveaux fait référence à une architecture de stockage où les données sont classées en différents niveaux en fonction de leurs exigences en matière de performance et d’accessibilité. Chaque niveau représente un niveau spécifique de performance de stockage et de coût. L’objectif est de s’assurer que les données sont stockées sur le niveau le plus approprié pour optimiser à la fois la performance et l’efficacité des coûts. Ci-dessous, vous pouvez voir les niveaux de stockage courants, en commençant par le niveau 0:
- Tier 0 représente le niveau de stockage le plus performant dans un système de stockage multi-niveaux. Il est souvent composé des supports de stockage les plus rapides et les plus coûteux disponibles, tels que les disques SSD (Solid State Drives) de qualité entreprise ou les SSD NVMe (Non-Volatile Memory Express). Les données stockées en Tier 0 sont généralement vitales et nécessitent une très faible latence, une haute performance E/S et un accès rapide aux données. Il est utilisé pour les applications et les données qui nécessitent les niveaux les plus élevés de performance.
- Niveau 1 est le niveau inférieur en termes de performance et de coût. Il se compose généralement de disques durs (HDD) haute performance, d’arrays de stockage hybrides (combinant des SSDs et des HDD) ou de SSDs plus rapides, qui ne sont pas aussi coûteux que ceux du niveau 0. Les données du niveau 1 sont importantes mais peuvent ne pas nécessiter l’accès le plus rapide au stockage disponible. Ce niveau convient aux applications et données qui nécessitent une bonne performance mais peuvent tolérer un léger retard de latence par rapport aux données du niveau 0.
- Niveau 2 représente un niveau de stockage à coût réduit avec une performance légèrement plus lente par rapport au niveau 1. Il inclut souvent des HDD traditionnels ou des solutions de stockage basées sur le cloud. Les données du niveau 2 sont généralement moins fréquemment consultées ou moins critiques pour les opérations en temps réel. Ce niveau convient aux données archivées, aux sauvegardes et aux données qui peuvent tolérer des temps d’accès plus longs.
- Niveau 3 est le niveau de stockage à coût le plus bas dans un système de stockage multi-niveaux. Il inclut généralement des solutions de stockage archivé, telles que des bibliothèques de bandes et des stockages froids basés sur le cloud. Les données du niveau 3 sont rarement consultées et sont principalement conservées pour des raisons de conformité, réglementaires ou d’archivage à long terme. Il offre la performance la plus faible mais le stockage le plus économique.
Certaines organisations utilisant principalement un stockage sur site dédient des niveaux supplémentaires spéciaux pour le stockage dans le cloud public et le stockage de sauvegarde :
- Couche de nuage. Dans certaines architectures de stockage à plusieurs niveaux, une couche de nuage distincte Couche de nuage est utilisée pour stocker des données dans un service de stockage cloud comme Amazon S3 ou Azure Blob Storage. Cela permet aux organisations de tirer parti d’un stockage cloud évolutif et rentable pour les données qui pourraient ne pas s’intégrer de manière transparente dans les niveaux locaux. Les données de la couche de nuage peuvent être consultées via Internet lorsque cela est nécessaire.
- Couche de sauvegarde. Bien que n’étant pas toujours considérée comme un niveau de stockage principal, le stockage de sauvegarde est une partie cruciale de la hiérarchie de stockage. Les données de sauvegarde sont stockées sur des systèmes basés sur des disques ou des bibliothèques de bandes, en fonction de la stratégie de sauvegarde de l’organisation. L’objectif est la protection des données et la récupération rapide en cas de perte de données ou de catastrophes.
Combien de niveaux sont généralement utilisés par les organisations?
Le nombre de niveaux utilisés par les organisations dans leurs architectures de stockage peut varier considérablement en fonction de leurs besoins spécifiques, des contraintes budgétaires et de la complexité de leurs exigences en matière de gestion des données. Cependant, en pratique, de nombreuses organisations mettent souvent en œuvre une hiérarchie de stockage à trois niveaux comme point de départ (Tier 0, Tier 1, Tier 2).
De nombreuses organisations commencent par ces trois niveaux en tant que fondement, puis personnalisent leur infrastructure de stockage pour répondre à leurs besoins spécifiques. Elles peuvent ajouter des niveaux supplémentaires ou adopter des classes de stockage spécialisées à mesure que leurs exigences en matière de données évoluent. Par exemple :
- Certaines organisations pourraient ajouter un Niveau 4 ou Niveau 5 pour le stockage archivage à long terme et profond, qui pourrait impliquer des technologies comme les bibliothèques de bandes ou un stockage cloud très peu coûteux.
- D’autres pourraient mettre en place un Niveau Cloud pour les sauvegardes hors site et les objectifs de récupération d’urgence, en utilisant des services de stockage cloud comme Amazon S3 ou Azure Blob Storage.
- Les stratégies de cloud hybride peuvent également introduire plus de niveaux, y compris des niveaux basés sur le cloud pour les données qui doivent être déplacées de manière transparente entre le stockage local et le cloud.
La clé est de concevoir une architecture de stockage qui s’aligne sur les modèles d’accès aux données, les exigences de performance et les considérations budgétaires de l’organisation. Il est également important d’implémenter des politiques de gestion et d’échelonnement des données efficaces pour garantir que les données sont stockées sur le niveau approprié en fonction des besoins changeants de ces données au fil du temps. Alors que les technologies de stockage de données continuent d’évoluer, les organisations peuvent ajuster leurs stratégies de stockage hiérarchisé pour tirer parti des nouvelles innovations et des solutions rentables.
Ces niveaux de stockage courants peuvent être résumés dans un tableau avec des explications brèves et des cas d’utilisation typiques :
| Numéro de Niveau | Nom du Niveau | Explication | Cas d’utilisation typiques |
| Niveau 0 | Ultra-rapide SSD | Stockage à haute performance, faible latence | Bases de données critiques, applications en temps réel |
| Niveau 1 | SSD haute performance | Bon équilibre entre vitesse et coût | Données d’applications générales, machines virtuelles |
| Niveau 2 | Stockage hybride | Mélange de SSDs et d’HDD, économique | Stockage de sauvegarde, données secondaires, partages de fichiers |
| Niveau 3 | HDD nearline | Stockage de sauvegarde, données secondaires, partages de fichiers | Données archivées, stockage à long terme |
| Niveau 4 | Stockage froid | Faible coût, très grande capacité, accès lent | Données archivées peu consultées |
| Niveau Cloud | Stockage cloud | Stockage basé sur le cloud scalable | Sauvegardes hors site, reprise après sinistre, partage de données |
Veuillez noter que les noms et les caractéristiques des niveaux de stockage peuvent varier entre les organisations et les fournisseurs de stockage. Le tableau ci-dessus fournit un aperçu général des niveaux de stockage courants et de leurs cas d’utilisation typiques, mais les implémentations spécifiques peuvent différer en fonction des besoins de l’organisation et des technologies disponibles.
Où les niveaux de stockage sont utilisés
Le classement des niveaux de stockage est une stratégie de gestion du stockage qui peut être utilisée à la fois sur site (dans les centres de données de l’organisation ou dans des environnements de cloud privé) et dans le cloud public. Il s’agit d’une approche flexible qui peut être appliquée à divers architectures de stockage pour optimiser le placement des données et les modèles d’accès.
Mise en niveaux de stockage sur site
La mise en niveaux de stockage est utilisée dans les environnements suivants axés sur l’infrastructure locale (sur site) :
- Centres de données traditionnels. Dans les centres de données traditionnels sur site, la mise en niveaux de stockage est couramment utilisée pour gérer les données stockées sur différents types de médias de stockage, tels que SSD, disques durs et bibliothèques de bandes. Les organisations mettent en œuvre la mise en niveaux de stockage pour optimiser les performances, le coût et la disponibilité des données au sein de leur propre infrastructure.
- Nuages privés. De nombreux environnements de nuage privé intègrent la mise en niveaux de stockage pour gérer efficacement les données à travers différents types de ressources de stockage. C’est particulièrement important dans les configurations de nuage privé où les ressources doivent être allouées dynamiquement pour soutenir différents types de charges de travail.
- Nuages hybrides. Dans un environnement de nuage hybride, qui combine l’infrastructure sur site avec des ressources de nuage public, la mise en niveaux de stockage peut être utilisée pour optimiser le placement des données à travers les deux environnements. Les organisations peuvent utiliser des politiques de mise en niveaux pour déterminer quelles données doivent résider sur site et quelles données doivent être déplacées vers le nuage public pour une efficacité ou une scalabilité coût.
Mise en niveaux de stockage dans le nuage public
En ce qui concerne le nuage public, la mise en niveaux de stockage est utilisée dans les environnements suivants :
- Services de stockage en nuage public. Les fournisseurs de nuage public tels que Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP) proposent leurs propres options de hiérarchisation de stockage en tant que partie de leurs services de stockage en nuage. Par exemple, AWS offre des classes de stockage S3 (Standard, Intelligent-Tiering, Glacier, etc.), chacune adaptée à différentes exigences de performance et de coût.
- Stockage d’objets. Les services de stockage d’objets dans le nuage public prennent souvent en charge la hiérarchisation de stockage pour permettre aux clients de choisir la classe de stockage la plus appropriée pour leurs données. Ceci est bénéfique pour optimiser les coûts et les temps d’accès.
Hiérarchisation de stockage automatisée
La hiérarchisation de stockage automatisée et l’optimisation de la hiérarchie de stockage sont des techniques utilisées dans la gestion moderne de l’espace de stockage pour garantir que les données sont placées sur la hiérarchie de stockage la plus appropriée efficacement et à temps.
Automatiséehiérarchisation de stockage est une technique de gestion des données qui consiste à déplacer automatiquement et dynamiquement les données entre différentes hiérarchies de stockage en fonction de politiques et de critères spécifiques. Ces politiques sont généralement définies par les administrateurs de stockage ou définies par des logiciels de gestion intelligente de stockage. L’objectif principal de la hiérarchisation de stockage automatisée est d’optimiser l’utilisation des ressources de stockage en garantissant que les données sont stockées sur la hiérarchie la plus appropriée à tout moment donné.
L’échelonnement automatisé des stocks vous permet d’optimiser dynamiquement votre échelonnement des stocks, en surveillant en permanence l’utilisation des données et l’accès pour déterminer les priorités des données et les niveaux d’échelonnement requis. Lorsque vous utilisez l’automatisation des stocks, vous définissez vos seuils préférés et l’automatisation s’occupe du reste.
Lorsque l’utilisation des données atteint des seuils prédéfinis, elle est déplacée en conséquence. Si la fréquence d’accès aux données augmente, elle passe à un niveau à latence inférieure. Lorsque les données ne sont pas utilisées, elles sont transférées vers un niveau à coût inférieur et à latence plus élevée. Cette approche optimise à la fois vos coûts et vos performances avec un effort minimal et sans besoin de maintenance continue.
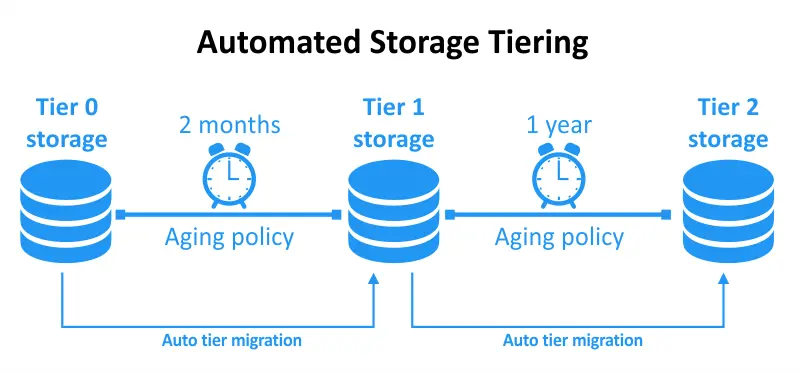
L’échelonnement automatisé des stocks facilite les transferts de données dirigés par des politiques entre les niveaux de stockage, s’alignant ainsi sur les besoins de performance et de capacité des utilisateurs. Cette fonctionnalité fonctionne efficacement avec votre architecture de stockage hiérarchisée existante et rationalise la gestion des données grâce à l’automatisation. L’échelonnement automatisé des stocks améliore l’optimisation des performances et l’efficacité des coûts en raison de l’ajustement en temps réel et du déplacement rapide des données.
Niveau de stockage optimisation est un concept plus large qui englobe diverses stratégies, y compris automatisé échelonnement des stocks, pour garantir qu’une organisation gère et utilise efficacement son infrastructure de stockage. Alors que l’échelonnement automatisé des stocks est un composant clé de l’optimisation de l’échelonnement des stocks, d’autres techniques et meilleures pratiques peuvent également être impliquées.
Echelonnement vs Mise en cache
Le classement et le cache sont deux techniques distinctes utilisées dans le stockage et la gestion des données – elles servent à des fins différentes. Les termes classement et cache sont souvent confondus par erreur, mais ils font référence à deux techniques différentes d’accélération du stockage. Les deux impliquent de placer les données fréquemment consultées ou chaudes sur des supports à haut débit comme la mémoire flash. Cependant, les similitudes s’arrêtent en grande partie là.
Le cache stocke temporairement des données sur un support à hautes performances comme la DRAM ou la mémoire à base de semi-conducteurs pour améliorer les performances. Le cache se situe entre l’application et le stockage principal. Les mêmes données se trouvent également sur un niveau de stockage inférieur, généralement un disque dur. Les données sont copiées dans le cache, mais les données originales restent à leur emplacement initial. Le cache est essentiellement une transaction unidirectionnelle et le cache annule les données après utilisation.
Le classement de stockage, en revanche, déplace physiquement les données entre les dispositifs de stockage. Lorsque des données sont identifiées comme chaudes, ces données sont déplacées vers un niveau à haut débit, rendant le niveau standard dépourvu d’une copie. Lorsque les données se refroidissent, elles sont déplacées à nouveau vers le niveau standard. Le classement de stockage implique de déplacer les données au lieu de simplement les copier, à la fois depuis un stockage plus lent vers un stockage plus rapide et vice versa.
Le classement de stockage et le cache améliorent tous deux l’accessibilité aux données, mais ils diffèrent dans la manière dont ils utilisent le stockage pour les données fréquemment consultées. Le cache crée des copies, tandis que le classement de stockage identifie les données et les déplace sans créer de copies supplémentaires.
Ainsi, le classement des données se concentre sur l’optimisation de l’emplacement des données à long terme à travers différents niveaux de stockage pour atteindre un équilibre entre la performance et le coût, tandis que le cache vise à accélérer l’accès aux données en stockant temporairement les données fréquemment consultées dans un tampon à haute vitesse. Le choix entre le classement et le cache dépend des besoins spécifiques de l’application ou du système de stockage et de la nature des modèles d’accès aux données. Dans certains cas, les organisations peuvent utiliser les deux techniques en combinaison pour obtenir les meilleures performances globales et une efficacité coût-efficacité.
Stockage hiérarchisé et Gestion hiérarchique de stockage
Le stockage hiérarchisé et la gestion hiérarchique de stockage sont tous deux des stratégies utilisées dans la gestion de l’infrastructure de stockage des données, mais elles diffèrent en termes de granularité, de mécanismes de déplacement des données et d’objectifs principaux. Le stockage hiérarchisé se concentre sur la catégorisation des données en niveaux discrets de médias de stockage en fonction de leurs caractéristiques, tandis que la gestion hiérarchique de stockage se concentre sur le déplacement transparent de fichiers ou d’objets individuels entre le stockage primaire et secondaire pour améliorer l’efficacité et les économies de coûts du stockage primaire.
Avantages du classement des données en stockage
Le classement des données en stockage offre plusieurs avantages significatifs pour les organisations qui cherchent à optimiser leur infrastructure de stockage de données. Les principaux avantages de la mise en œuvre du classement des données en stockage sont :
- Amélioration des performances. En plaçant les données fréquemment consultées ou critiques sur des niveaux de stockage à haute performance, tels que les disques durs SSD ou les systèmes de stockage NVMe, le classement des données en stockage peut considérablement améliorer les performances du système. Cela se traduit par une réduction de la latence et des temps d’accès aux données plus rapides pour les applications et les utilisateurs, ce qui entraîne une productivité améliorée et une satisfaction des utilisateurs.
- Utilisation efficace des ressources. Le classement des stockages garantit que chaque niveau de stockage est utilisé efficacement, évitant ainsi la sur-provision des médias de stockage à haute performance et l’utilisation insuffisante des stockages à coût plus faible. Cela maximise le retour sur investissement (ROI) pour l’infrastructure de stockage.
- Optimisation des coûts. Le classement des stockages aide les organisations à affecter des ressources de stockage coûteuses uniquement à des données qui nécessitent une haute performance, tandis que les données moins critiques ou peu consultées peuvent être stockées sur des niveaux à coût plus faible, tels que les disques durs ou le stockage cloud. Cette optimisation des coûts peut entraîner des économies potentielles sur les dépenses matérielles et opérationnelles.
- Travaux équilibrés. Le classement des stockages peut aider à répartir les données et les travaux entre différents niveaux, réduisant la concurrence pour les ressources. Ceci est particulièrement précieux dans des environnements avec des travaux mixtes, où certaines applications nécessitent une haute performance tandis que d’autres ont des exigences de stockage moins exigeantes.
- Gestion des données adaptative. Les modèles d’accès aux données peuvent changer avec le temps. Les solutions de classement des stockages analysent continuellement ces modèles et déplacent automatiquement les données entre les niveaux au besoin. Cette adaptabilité garantit que les données restent sur le niveau de stockage le plus approprié, même lorsque les exigences d’accès évoluent.
- Scalabilité. Alors que les besoins de stockage de données augmentent, le classement des stockages permet aux organisations d’évoluer efficacement leur infrastructure de stockage. De nouveaux niveaux de stockage peuvent être ajoutés ou les niveaux existants élargis au besoin pour accueillir les volumes croissants de données et les demandes de performance.
- Gestion simplifiée des données. Les solutions de hiérarchisation des stockages incluent souvent des politiques automatisées et des outils de gestion qui simplifient les tâches de gestion des données. Cela réduit le fardeau administratif associé au placement et au transfert de données manuels.
- Conformité et rétention. Les organisations ayant des exigences réglementaires ou de conformité tirent parti de la hiérarchisation des stockages en garantissant que les données sont stockées et conservées conformément aux mandats légaux. Les données de conformité peuvent être gérées sur des niveaux de stockage spécifiques avec les politiques de sécurité et de rétention nécessaires.
- Protection des données et reprise après sinistre. En classant les données en fonction de leur importance, la hiérarchisation des stockages aide les organisations à prioriser les efforts de protection des données. Les données critiques peuvent être stockées sur des niveaux résilients et redondants, garantissant la disponibilité et la récupérabilité des données en cas de défaillances ou de catastrophes.
- Sauvegarde et restauration optimisées. En séparant les données en fonction de leur importance et de leurs modèles d’accès, la hiérarchisation des stockages peut aider à prioriser les données pour les opérations de sauvegarde et de restauration. Les données critiques peuvent être sauvegardées avec une fréquence plus élevée, tandis que les données moins critiques peuvent être soumises à des intervalles de sauvegarde plus longs.
Bien que le principal objectif des niveaux de stockage soit d’optimiser le placement des données et les coûts de stockage, les avantages qu’ils offrent peuvent également améliorer la capacité de l’organisation à se remettre des catastrophes. La redondance et la conservation de données rentable augmentent les chances de récupération de données réussie. Cela aide les organisations à maintenir la continuité des activités et à se remettre des catastrophes avec une perte minimale de données et de temps d’arrêt, ce qui améliore finalement leur préparation globale à la récupération des catastrophes.
Meilleures pratiques pour le classement des niveaux de stockage
Le classement des niveaux de stockage est une technique précieuse pour optimiser le stockage des données, mais il est important de suivre les meilleures pratiques pour garantir son efficacité et son efficience. Voici les meilleures pratiques pour le classement des niveaux de stockage:
- Comprendre vos données. Effectuez une analyse approfondie de vos données pour comprendre leurs caractéristiques, leurs modèles d’accès et leur importance. Toutes les données n’ont pas besoin d’être classées, pour cette raison, vous devez identifier les ensembles de données qui bénéficieraient le plus du stockage par niveaux.
- Choisir le bon support de stockage. Choisissez le support de stockage pour chaque niveau en fonction des exigences de performance et budgétaires de votre organisation. Les disques SSD, les disques durs, le stockage cloud et les bibliothèques de bandes sont des options courantes.
- Surveiller et ajuster régulièrement. Surveillez en permanence votre environnement de stockage pour suivre les modèles d’accès aux données et l’utilisation des niveaux. Ajustez les politiques de classement en conséquence pour refléter les exigences changeantes. Examiner et affiner régulièrement vos politiques est essentiel pour un rendement optimal.
- Utilisez la classification et l’étiquetage des données. Utilisez les métadonnées et l’étiquetage des données pour classer les données. Ces métadonnées peuvent être utilisées par votre système de hiérarchisation pour prendre des décisions plus éclairées sur l’emplacement des données.
- Priorisez les données critiques. Veillez à ce que les données mission-critiques et fréquemment consultées soient placées sur des niveaux à hautes performances. Cela peut nécessiter des politiques ou des niveaux de priorité différents pour différents types de données.
- Incluez la redondance dans les niveaux critiques. Si vous stockez des données mission-critiques sur des niveaux à hautes performances, envisagez des mécanismes de redondance tels que RAID (Redundant Array of Independent Disks) pour protéger contre la perte de données due à des pannes matérielles.
- Mettre en œuvre des politiques de hiérarchisation automatisées. Définissez des politiques claires et automatisées pour le déplacement des données entre les niveaux. Ces politiques devraient prendre en compte des facteurs tels que la fréquence d’accès, l’âge des données et les exigences de performance. L’automatisation de l’emplacement et du déplacement des données contribue à garantir que les données sont toujours au bon niveau.
- Fournir des contrôles de sécurité et d’accès. Mettez en place des mesures de sécurité appropriées et des contrôles d’accès pour les données sur tous les niveaux. Assurez-vous que les données sensibles sont protégées et accessibles uniquement aux utilisateurs autorisés.
- Sauvegarde et reprise après sinistre. Prévoyez la protection des données et la reprise après sinistre. Assurez-vous que les stratégies de sauvegarde et de récupération sont alignées sur votre approche de hiérarchisation des données. Les données critiques devraient être sauvegardées plus fréquemment et conservées de manière sécurisée.
- Scalabilité. Conçoivez votre stratégie de hiérarchisation des données pour être scalable. Au fur et à mesure que vos besoins en stockage de données augmentent, soyez prêt à ajouter plus de niveaux ou à étendre ceux existants.
- Pensez aux solutions cloud hybrides. En fonction des besoins de votre organisation, envisagez d’intégrer le stockage cloud comme l’un de vos niveaux de stockage. Les solutions cloud hybrides peuvent offrir scalabilité et flexibilité.
- Évaluez régulièrement la technologie. Restez informé des avancées dans la technologie de stockage. Alors que la technologie évolue, de nouveaux supports de stockage et solutions peuvent devenir plus rentables et adaptés à vos niveaux de stockage.
NAKIVO Backup & Replication et Stratégie de stockage de sauvegarde
NAKIVO Backup & Replication est une solution moderne de protection des données et de récupération après sinistre qui peut fonctionner avec différents niveaux de stockage, vous permettant d’optimiser vos stratégies de sauvegarde et de récupération en fonction de leurs besoins spécifiques et de l’infrastructure de stockage disponible. La solution NAKIVO prend en charge différents types de stockage, y compris le stockage on-premise, le stockage cloud et les appliances de déduplication.
Vous pouvez configurer NAKIVO Backup & Replication pour utiliser différentsniveaux de stockage pour les sauvegardes. Par exemple, les sauvegardes critiques peuvent être stockées sur un stockage à hautes performances (Tier 1) pour une récupération rapide, tandis que les sauvegardes moins critiques peuvent être déplacées vers un stockage moins coûteux (Tier 2 ou cloud) pour une conservation à long terme.
Le produit propose des fonctionnalités comme copie de sauvegarde et réplication, qui permettent la création de copies supplémentaires de sauvegardes sur différents niveaux de stockage. Ceci améliore la redondance des données et la préparation à la récupération d’urgence en plaçant les sauvegardes dans plusieurs emplacements ou niveaux de stockage.
Vous pouvez définir des politiques de rétention dans NAKIVO Backup & Replication pour gérer automatiquement les données de sauvegarde en fonction de votre stratégie de hiérarchisation. Par exemple, les sauvegardes peuvent être conservées sur le niveau 1 pendant une période plus courte, puis transférées au niveau 2 pour une conservation à plus long terme.
La solution NAKIVO prend en charge les fournisseurs de stockage cloud populaires. Cela signifie que vous pouvez facilement intégrer le stockage cloud en tant que niveau de stockage pour les sauvegardes externes, réduisant ainsi le besoin d’une infrastructure sur site supplémentaire.
Conclusion
Les architectures de stockage à plusieurs niveaux permettent aux organisations d’allouer des ressources de stockage en fonction des besoins spécifiques de leurs données. En plaçant les données sur le niveau le plus approprié, les organisations peuvent optimiser à la fois les performances et les coûts, en veillant à ce que les données critiques reçoivent les performances nécessaires tandis que les données moins critiques ou moins fréquemment consultées sont stockées de manière rentable. Les politiques de hiérarchisation automatisée des données et les outils de gestion aident à garantir que les données sont déplacées entre les niveaux à mesure que les modèles d’accès et les exigences évoluent avec le temps.