













조직은 오늘날 데이터 양이 증가함에 따라 저장 비용이 증가하고 데이터 번식으로 이어질 수 있으므로 저장 공간을 합리적으로 사용해야합니다. 데이터 저장 매체는 비용, 쓰기/읽기 속도 등 측면에서 다르며, 다양한 유형의 데이터는 비용과 자원을 절약하기 위해 가장 효율적인 매체에 저장되어야 합니다.
예를 들어, 고속 SSD(solid-state drives) 장치에 백업을 저장하는 것은 이러한 유형의 보조 데이터에 대해 높은 속도가 필요하지 않으므로 불필요하게 비용이 많이 듭니다. 반면에, 저 RPM(분당 회전 수) 하드 디스크 드라이브(HDDs)에 생산 가상 머신(VMs)을 저장하는 것은 예산 효율적일 수 있지만 주요 시스템의 성능 요구 사항을 충족시키지 못할 것입니다.
이러한 이유로 저장 유형은 저장 티어링(storage tiering)을 사용하여 적절한 데이터를 저장하기 위해 각 저장 유형을 분류해야 합니다.
저장 티어링이란?
저장 티어링은 데이터의 특성과 액세스 패턴을 기반으로 데이터를 다양한 티어로 분류하여 저장 비용과 성능 효율성을 최적화하기 위해 사용되는 데이터 저장 관리 전략입니다. 저장 티어링의 주요 목표는 가장 자주 액세스되고 중요한 데이터가 고성능 저장 매체에 저장되어 있으며, 덜 자주 액세스되거나 중요하지 않은 데이터는 저렴한 저장 매체에 저장되어 있도록 하는 것입니다.
이 접근 방식을 통해 조직은 데이터를 가치와 사용 패턴에 따라 빠르고 비싼 고속 SSD(solid-state drives) 또는 느리지만 비용 효율적인 하드 디스크 드라이브(HDDs)와 같은 다양한 종류의 저장 매체에 저장할 수 있습니다.
저장 계층화는 데이터를 액세스 빈도, 중요성 및 성능 요구 사항과 같은 기준에 따라 다른 범주 또는 계층으로 분류하는 것으로 시작됩니다. 작업 프로세스가 필요하면이 분류는 시간이 지남에 따라 변경 될 수 있습니다. 저장 계층화의 숫자 및 유형은 저장 인프라에 따라 다를 수 있습니다.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
계층화 된 저장을위한 데이터 클래스
계층화 된 저장 아키텍처의 데이터 클래스는 특정 속성이나 특성을 기준으로 데이터를 분류 또는 분류하는 것을 의미합니다. 이러한 클래스는 데이터 계층 구조를 만들고 데이터가 계층화 된 저장 시스템 내에서 어디에 저장되어야하는지 결정하는 데 도움이됩니다. 이 접근 방식은 성능, 비용 및 접근성을 균형 있게 유지하기 위해 데이터가 가장 적합한 저장 계층에 배치되도록합니다. 데이터 클래스의 구체적인 속성은 조직의 요구 사항 및 저장 인프라에 따라 다를 수 있습니다. 데이터 분류에 사용되는 공통 속성은 다음과 같습니다:
- 액세스 빈도. 데이터 분류의 주요 기준 중 하나는 사용자 및 응용 프로그램에 의해 얼마나 자주 액세스되는지입니다. 정기적으로 및 활발하게 사용되는 데이터 (핫 데이터)는 빠른 액세스 시간을 보장하기 위해 SSD 또는 NVMe 드라이브와 같은 고성능 저장 계층에 저장되어야합니다. 반면에, 드물게 액세스되는 데이터 (콜드 데이터)는 HDD 또는 클라우드 저장소와 같은 저렴한 비용의 저장 계층에 배치 될 수 있습니다.
- 중요도 또는 중요성. 조직의 운영 또는 규정 요구사항에 따라 일부 데이터는 다른 데이터보다 더 중요할 수 있습니다. 중요 데이터는 데이터 손실의 위험을 최소화하기 위해 RAID(독립 디스크의 중복 배열) 또는 중복을 갖춘 클라우드 저장소와 같은 더 신뢰할 수 있고 견고한 저장 계층에 저장될 수 있습니다.
- 데이터 유형. 데이터 유형은 데이터베이스 파일, 멀티미디어 콘텐츠, 응용 프로그램 로그 또는 보관 문서와 같이 다양할 수 있습니다. 예를 들어, 멀티미디어 파일은 고 처리량과 용량이 필요할 수 있으며, 로그는 규정 준수를 위해 보관되는 한 더 느린 저장소에 저장될 수 있습니다.
- 유지 기간. 특정 보관 또는 규정 요구사항이 있는 데이터는 필요한 기간 동안 데이터 무결성과 가용성을 보장할 수 있는 계층에 저장되어야 할 수 있습니다. 규정 준수 데이터는 종종 장기 보관이 필요하므로 더 신뢰할 수 있는 저장 계층에 저장될 수 있습니다.
- 크기. 대규모 데이터 객체는 용량에 최적화된 저장 계층에 저장하는 것이 유리할 수 있으며, 작고 빈번하게 액세스되는 데이터는 낮은 대기 시간과 높은 I/O 성능을 갖춘 저장소에 저장되어야 할 수 있습니다.
- 데이터 라이프사이클. 데이터는 생성 및 활성 사용부터 보존 또는 삭제까지 여러 단계를 거칩니다. 데이터 클래스는 이러한 단계를 고려하고 필요에 따라 데이터를 계층간 이동해야 합니다. 예를 들어, 새로 생성된 데이터는 고성능 계층에서 시작할 수 있지만, 점차적으로 덜 활성 상태가 되면 저렴한 계층으로 이동될 수 있습니다.
- 비용 민감도. 조직은 종종 예산 제약이 있습니다. 데이터 클래스는 더 비싼 저장 리소스가 비용을 정당화하는 데이터에 예약되도록하여 예산 고려사항과 데이터 저장 비용을 조정하는 데 도움이 될 수 있습니다.
- 사용자 또는 애플리케이션 요구 사항. 서로 다른 사용자 또는 애플리케이션은 특정한 저장소 요구 사항을 가질 수 있습니다. 데이터 클래스는 이러한 요구 사항을 고려하여 각 그룹이 필요한 저장소 성능과 용량을 받을 수 있도록 보장할 수 있습니다.
데이터가 이러한 클래스로 분류되면 정책 및 알고리즘을 사용하여 계층별 저장 구조 내에서 데이터의 배치와 이동을 관리합니다. 이는 데이터가 지속적으로 성능 및 비용 효율성을 위해 최적화되고 조직의 요구 사항 및 액세스 패턴을 충족시키는 것을 보장합니다.
핫, 웜, 콜드 저장과의 분류
계층별 저장 시스템에서 일반적으로 사용되는 데이터 분류 유형은 미션 크리티컬, 핫, 웜, 콜드로 데이터를 분류하는 것입니다. 이러한 클래스는 데이터가 저장, 관리 및 액세스되는 방식을 결정하는 데 도움이 됩니다. 이 경우, 계층별 저장 전략에서 사용되는 데이터 클래스는 다음과 같습니다:
- 미션 크리티컬 데이터. 이 데이터 클래스는 조직의 핵심 운영에 절대적으로 필요한 데이터에 관련됩니다. 미션 크리티컬 데이터는 최고 수준의 성능, 신뢰성 및 가용성을 요구합니다. 일반적으로 이러한 데이터는 중복 SSD 배열이나 내결함성 저장 시스템과 같은 가장 견고하고 고성능의 저장 매체에 저장됩니다.
- 핫 데이터. 핫 데이터는 활발하게 액세스되고 자주 사용되는 데이터를 의미합니다. 이 데이터는 일반적으로 조직에게 매우 중요하며 빠른 응답 시간과 고성능 스토리지가 필요합니다. 핫 데이터는 주로 저지연 및 신속한 액세스를 보장하기 위해 고등급 스토리지 미디어에 저장됩니다. 예를 들어, 고체 상태 드라이브(SSD) 또는 NVMe 드라이브 등이 있습니다.
- 웜 데이터. 웜 데이터는 핫 데이터보다 덜 자주 액세스되지만 여전히 활발하게 사용되는 데이터를 나타냅니다. 이 데이터 클래스는 일반적으로 성능 측면에서 핫 데이터 아래의 티어에 위치하며, 고성능 하드 디스크 드라이브(HDD) 또는 하이브리드 스토리지 솔루션과 같은 것입니다. 웜 데이터는 가장 빠른 스토리지를 필요로하지 않을 수 있지만 효율적인 액세스를 위해 신속하게 사용 가능해야합니다.
- 콜드 데이터. 콜드 데이터에는 드물게 액세스되는 데이터, 역사적 데이터 또는 보관 데이터가 포함됩니다. 이 데이터는 종종 중요성이 낮으며 저렴한 스토리지 티어에 저장되며, 전통적이고 느린 HDD 또는 테이프 또는 클라우드 기반의 보관용 스토리지와 같은 보관용 옵션일 수 있습니다. 콜드 데이터의 중점은 장기 보존과 비용 절감에 있습니다.
데이터 클래스의 수는 스토리지 분류 모델의 스토리지 티어 수에 따라 다를 수 있습니다. 조직은 위에서 설명한 클래스에 추가적으로 다음 데이터 클래스를 사용함으로써 데이터를 더 복잡하게 분류할 수 있습니다:
- 백업 및 재해 복구 데이터. 백업 및 재해 복구 목적으로 사용되는 데이터는 종종 별도로 분류됩니다. 이러한 데이터 클래스는 데이터 손실 또는 시스템 장애 발생 시 데이터를 신뢰할 수 있고 빠르게 복원할 수 있도록 하는 데 중점을 둡니다. 백업 데이터는 디스크 기반 시스템에 저장될 수 있으며, 장기 보존 사본은 테이프나 클라우드에 저장될 수 있습니다.
- 컴플라이언스 데이터. 재무 기록이나 의료 데이터와 같은 규정 준수 요구 사항을 준수해야 하는 데이터는 특정 저장 요구 사항을 가질 수 있습니다. 컴플라이언스 데이터 클래스는 이러한 데이터가 암호화 및 엄격한 액세스 제어와 같은 기능을 갖추고 필요한 기간 동안 보존되도록 보장합니다.
- 사용자 또는 부서 데이터. 일부 조직은 특정 부서나 사용자가 생성한 데이터를 기반으로 데이터를 분류합니다. 이러한 접근 방식은 서로 다른 조직 단위의 필요에 따라 저장 리소스를 할당하는 데 도움이 될 수 있습니다.
- 임시 또는 캐시 데이터. 임시 또는 캐시 데이터를 위한 데이터 클래스에는 수명이 짧고 더 이상 필요하지 않을 때 폐기되거나 교체될 수 있는 데이터가 포함될 수 있습니다. 빠른 액세스를 위해 고속 저장 티어에 저장될 수 있습니다.
티어 이동 데이터 . 경우에 따라 데이터 클래스는 액세스 패턴에 따라 저장 티어 간에 활발하게 이동하는 데이터를 식별하는 데 사용됩니다. 예를 들어, 초기에는 활성 상태이지만 시간이 지남에 따라 접근 빈도가 줄어들 수 있는 데이터는 보다 따뜻한 또는 더 차가운 저장 티어로 이동할 수 있습니다. - 티어 마이그레이션 데이터. 일부 경우에는 데이터 클래스를 사용하여 접근 패턴에 따라 저장 티어 사이에서积极적으로 이동하는 데이터를 식별합니다. 예를 들어, 처음에는 핫 데이터이지만 시간이 지나면서 접근 빈도가 줄어들어 더温馨하거나 추운 저장 티어로 마이그레이션할 수 있습니다.
이러한 데이터 클래스는 저장 관리자와 자동화 저장 관리 시스템이 티어별 저장 인프라 내에서 데이터를 어디에 배치할지에 대한 지능적인 결정을 내리는 데 가이드 라인 역할을 수행합니다.
다중 티어 저장 유형
다중 티어 저장은 데이터가 성능과 접근성 요구에 따라 서로 다른 티어로 분류되는 저장 아키텍처를 의미합니다. 각 티어는 특정 수준의 저장 성능과成本를 나타냅니다. 목표는 데이터를 성능과 비용 효율을 최적화하기 위해 가장 적절한 티어에 저장되도록 보장하는 것입니다. 아래에서 일반적인 저장 티어를 볼 수 있으며, Tier 0부터 시작합니다:
- Tier 0는 다중 티어 저장 시스템에서 가장 성능이 좋은 저장 티어를 나타냅니다. 일반적으로 가장 빠르고 비싼 저장 매체를 구성하며, 이러한 매체로는 기업급 SSD(고정식 디스크)나 NVMe(비挥发性 메모리 익스프레스) SSD를 사용합니다. Tier 0에 저장된 데이터는 보통 미션 중요 데이터이며 매우 낮은 지연, 높은 I/O 성능, 빠른 데이터 액세스가 필요합니다. 가장 높은 수준의 성능을 요구하는 응용 프로그램과 데이터에 사용됩니다.
- 1단계(Tier 1)은 성능과 비용方面에서 다음 수준입니다. 일반적으로 고성능 하드디스크 드라이브(HDDs), 하이브리드 저장 배열(SSDs와 HDDs를 결합한 것), 또는 더 빠른 SSDs로 구성되며, 이들은 0단계(Tier 0)에 있는 것보다 비용이 적게 듭니다. 1단계에 있는 데이터는 중요하지만 절대적으로 가장 빠른 저장장치를 필요로 하진 않습니다. 이 단계는 좋은 성능을 필요로 하지만 0단계 데이터에 비해 약간 더 높은 지연을 허용할 수 있는 응용 프로그램과 데이터에 적합합니다.
- 2단계(Tier 2)는 1단계보다 성능이 약간 느리고, 비용이 낮은 저장 단계를 나타냅니다. 이 단계에서는 전통적인 HDDs 또는 클라우드 기반 저장 솔루션을 포함합니다. 2단계에 있는 데이터는 일반적으로 자주 액세스 되지 않거나 실시간 연산에 중요하지 않습니다. 이 단계는 보존 데이터, 백업, 그리고 더 오래의 액세스 시간을 허용할 수 있는 데이터에 적합합니다.
- 3단계(Tier 3)는 다단계 저장 시스템에서 가장 비용이 낮은 저장 단계입니다. 일반적으로 기록 매체 라이브러리나 클라우드 기반의冷酷��藏(cold storage)와 같은 보존 저장 솔루션을 포함합니다. 3단계에 있는 데이터는 거의 접근되지 않으며, 주로 준수, 규정, 또는 장기 보존 목적으로 보관됩니다. 이 단계는 가장 낮은 성능을 제공하지만, 가장 cost-effective한 저장 방식을 제공합니다.
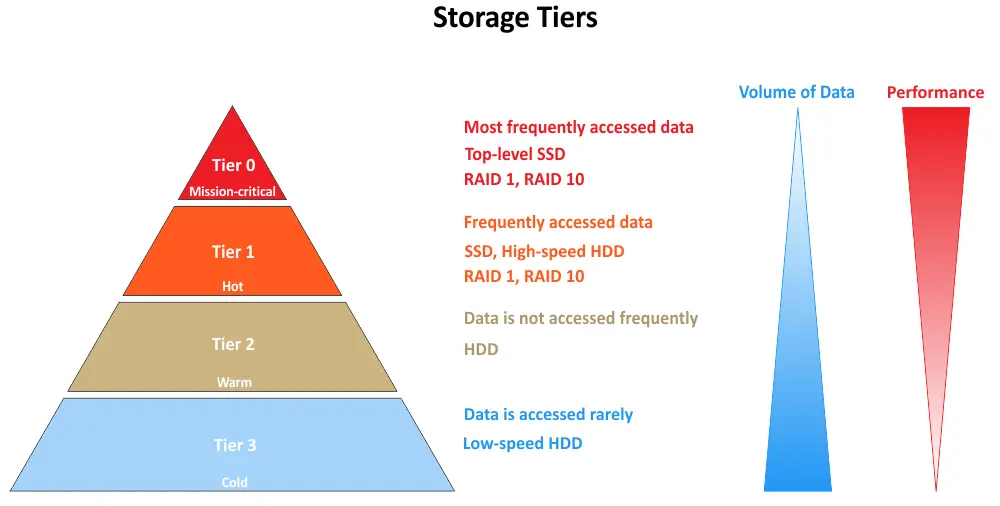
일부 기업은 주로 on-premises 저장을 사용하면서, 공용 클라우드 저장과 백업 저장을 위한 추가 특수 단계를 지정합니다:
- 클라우드 티어. 일부 다층 저장 아키텍처에서는 Amazon S3나 Azure Blob Storage와 같은 클라우드 저장 서비스에 데이터를 저장하기 위해 별도의 클라우드 티어를 사용합니다. 이렇게 함으로써 조직은 현장 내 티어에 적절하게 들어맞지 않을 수 있는 데이터를 위해 확장성이 있고 경제적인 클라우드 저장을 이용할 수 있습니다. 클라우드 티어의 데이터는 필요할 때 인터넷을 통해 액세스할 수 있습니다.
- 백업 티어. 항상 주요 저장 티어로 고려되는 것은 아니지만, 백업 저장은 저장 계층에 중요한 부분입니다. 백업 데이터는 조직의 백업 전략에 따라 디스크 기반 시스템 또는 테이프 라이브러리에 저장됩니다. 초점은 데이터 손실이나災害 시 빠른 복구를 위한 데이터 보호입니다.
조직들이 보통 몇 개의 티어를 사용하나요?
조직들이 저장 아키텍처에 사용하는 티어 수는 특정 필요, 예산 제약, 데이터 관리의 복잡성에 따라 크게 다를 수 있습니다. 그러나 실제로 많은 조직들은 시작점으로 세 개의 저장 티어(티어 0, 티어 1, 티어 2)을 일반적으로 구현합니다.
많은 조직들은 이 세 개의 티어를 기반으로 시작하여 자신의 특정 필요에 맞춰 저장 인프라를 커스터마이즈합니다. 데이터 요구가 발전할 때에는 추가 티어를 추가하거나 특화된 저장 클래스를 채택할 수 있습니다. 예를 들면:
- 일부 조직은 4단계 또는 5단계를 추가하여 오래 term, 깊은 보존 저장을 수행할 수 있습니다. 이 경우 테이프 라이브러리나 매우 저렴한 클라우드 스토리지와 같은 기술을 사용할 수 있습니다.
- 다른 조직은 클라우드 단계를 구현하여 Amazon S3 또는 Azure Blob Storage와 같은 클라우드 스토리지 서비스를 사용하여 오프사이트 백업 및災害 복구 목적으로 사용할 수 있습니다.
- 하이브리드 클라우드 전략으로 클라우드 기반의 단계를 더 추가할 수 있으며, 온-프레미스와 클라우드 스토리지 간에 끊임없이 이동해야 하는 데이터를 위한 클라우드 기반 단계를 포함합니다.
핵심은 조직의 데이터 액세스 패턴, 성능 요구 사항, 예산 고려 사항과 일치하는 저장 아키텍처를 디자인하는 것입니다. 또한 데이터가 시간이 지남에 따라 변화하는 필요에 따라 적절한 단계에 저장되도록 효과적인 데이터 관리 및 계층화 정책을 구현하는 것이 중요합니다. 데이터 저장 기술이 계속 발전하면서 조직은 새로운 혁신과 cost-efficient 솔루션을 이용하기 위해 계층화 저장 전략을 조정할 수 있습니다.
이러한 일반적인 저장 계층은 간략한 설명과典型的 use case와 함께 표로 요약할 수 있습니다:
| 티어 번호 | 티어 이름 | 설명 | 典型的使用案例 |
| 티어 0 | 초고속 SSD | 최고 성능 저장, 저 지연 | 중요 데이터베이스, 실시간 응용 프로그램 |
| 티어 1 | 고성능 SSD | 속도와 비용의 좋은 균형 | 일반 응용 프로그램 데이터, 가상 머신 |
| 티어 2 | 하이브리드 저장 | SSD와 HDD의 혼합, 비용 효율 | 백업 저장, 보조 데이터, 파일 공유 |
| 티어 3 | 내라인 HDD | 백업 저장, 보조 데이터, 파일 공유 | 아카이브 데이터, 장기 보존 |
| 티어 4 | 콜드 스토리지 | 저비용, 매우 높은 용량, 느린 액세스 | 자주 액세스되지 않는 아카이브 데이터 |
| 클라우드 티어 | 클라우드 저장 | 확장 가능한 클라우드 기반 저장 | 오프사이트 백업,災害復旧, 데이터 공유 |
저장 티어의 이름과 특성은 조직과 저장 소프트웨어 제공업체 간에 차이가 있을 수 있음을 유의하십시오. 위의 표는 일반적으로 사용되는 저장 티어와 그들의典型的使用案例을 제공하지만, 특정 구현은 조직의 필요와 사용 가능한 기술에 따라 달라질 수 있습니다.
저장 티어를 사용하는 곳
저장 티어링은 조직의 자체 데이터 센터나 사설 클라우드 환경 내에서(온-premises)以及在公共云에서 사용할 수있는 저장 관리 전략입니다. 다양한 저장 아키텍처에 적용할 수있는 유연한 접근법으로 데이터 배치와 액세스 패턴을 최적화 할 수 있습니다.
원장 층화(On-Premises Storage Tiering)
원장 층화는 다음과 같은 환경에서 사용되며, 현장(로컬) 인프라структура에 초점을 맞춥니다:
- 傳統的數據中心. 전통적인 현장 데이터 센터에서는, 원장 층화가 SSD, HDD, 테이프 라이브러리와 같은 여러 종류의 저장 매체에 저장된 데이터를 관리하는 데 일반적으로 사용됩니다. 조직들은 성능, 비용, 자체 인프라 내에서 데이터의 이용 가능성을 최적화하기 위해 원장 층화를 구현합니다.
- 개인 클라우드. 많은 개인 클라우드 환경들은 다양한 저장 자원들 사이에서 데이터를 효율적으로 관리하기 위해 원장 층화를 포함합니다. 이는 자원들이 다양한 작업負荷을 지원하기 위해 동적으로 할당되어야 하는 개인 클라우드 설정에서尤为重要합니다.
- 하이브리드 클라우드. 현장 인프라와 공용 클라우드 자원을 결합한 하이브리드 클라우드 환경에서는, 원장 층화를 사용하여 두 환경 모두에서 데이터 배치를 최적화할 수 있습니다. 조직들은 층화 정책을 사용하여 어느 데이터가 현장에 있어야하며, 어느 데이터는 비용 효율성이나 확장성을 위해 공용 클라우드로 옮겨져야 하는지를 결정할 수 있습니다.
공용 클라우드 내의 원장 층화
공용 클라우드의 경우, 다음과 같은 환경에서 원장 층화가 사용됩니다:
- 공용 클라우드 스토리지 서비스. 애마존 웹 서비스 (AWS), 마이크로소프트 Azure, 그룹 클라우드 플랫폼 (GCP)과 같은 공용 클라우드 제공업체는 클라우드 스토리지 서비스의 일부로 자신들만의 클라우드 스토리지 티어링 옵션을 제공합니다. 예를 들어, AWS는 S3 스토리지 클래스 (Standard, Intelligent-Tiering, Glacier 등)을 제공하며, 이들은 서로 다른 성능과成本要件에 맞게 꾸며져 있습니다.
- 오브젝트 스토리지. 공용 클라우드의 오브젝트 스토리지 서비스는 보통 스토리지 티어링을 지원하여 고객이 자신의 데이터에 가장 적절한 스토리지 클래스를 선택할 수 있게 합니다. 이는成本와 액세스 시간을 최적화하는 데 유리합니다.
자동 스토리지 티어링
자동 스토리지 티어링과 스토리지 티어 최적화는 현대 데이터 스토리지 관리에서 사용되는 기술로, 데이터를 최적의 스토리지 티어에 effectively하고 적절한 시간에 배치시키는 데 사용됩니다.
자동 스토리지 티어링은 특정 정책과 기준에 따라 데이터를 서로 다른 스토리지 티어 사이에서 자동으로 동적으로 이동시키는 데이터 관리 기술입니다. 이러한 정책은 보통 스토리지 관리자가 정의하거나 지능형 스토리지 관리 소프트웨어에 의해 설정됩니다. 자동 스토리지 티어링의 주요 목적은 데이터를 항상 가장 적절한 티어에 저장함으로써 스토리지 자원의 사용을 최적화하는 것입니다.
자동 저장 계층화(Automated storage tiering)은 스토리지 계층화를 동적으로 최적화할 수 있도록 도와주는 기능으로, 데이터 사용과 접근을 지속적으로 모니터링하여 데이터 우선순위와 필요한 계층화 수준을 결정합니다. 자동 저장을 사용하면, 기준 값을 설정하고 나머지는 자동화가 처리합니다.
데이터 사용이 사전 정의된 기준값에 도달하면, 적절하게 이동합니다. 데이터 액세스 빈도가 증가하면, 더 낮은 지연 시간 계층으로 이동합니다. 데이터가 사용되지 않으면, 낮은 비용, 더 높은 지연 시간 계층으로 이동합니다. 이 접근법은 최소한의 노력과 지속적인 유지 보수를 필요로 하지 않으면서도 both your costs and performance를 최적화합니다.
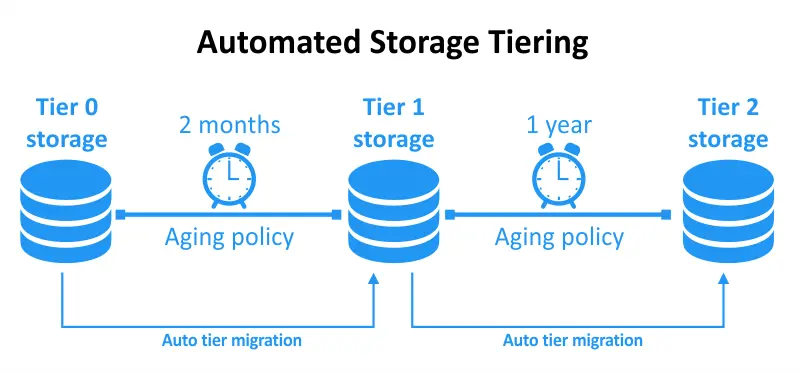
자동 저장 계층화는 정책 기반의 데이터 전송을 용이하게 하여 사용자의 성능과 용량 요구를 맞춥니다. 이 기능은 기존의 계층화된 저장 아키텍처와 잘 작동하고 자동화를 통해 데이터 관리를 정돈시킵니다. 자동 저장 계층화는 실시간 조정과 빠른 데이터 이동으로 성능 최적화와成本效率을 향상시킵니다.
Storage tier optimization는 여러 전략을 포함하는 보다 넓은 개념으로, 조직의 저장 인프라를 효율적으로 관리하고 사용할 수 있도록 합니다. 자동 저장 계층화는 저장 계층 최적화의 핵심 구성요소이지만, 다른 기술과 베스트 프랙티스도 포함될 수 있습니다.
계층화 vs 캐싱(Tiering vs Caching)
티어링과 캐싱은 데이터 저장 및 관리에 사용되는 두 가지 뚜렷한 기술로, 서로 다른 목적을 가지고 있습니다. 티어링과 캐싱이라는 용어는 종종 혼동되지만, 이는 두 가지 다른 저장 가속 기술을 의미합니다. 두 기술 모두 자주 액세스되는 또는 핫 데이터를 플래시와 같은 고속 미디어에 배치하는 것을 포함하지만, 유사성은 대부분 여기서 끝납니다.
캐싱은 성능을 향상시키기 위해 DRAM 또는 솔리드 스테이트 메모리와 같은 고성능 매체에 데이터를 일시적으로 저장합니다. 캐시는 애플리케이션과 백엔드 저장소 사이에 위치합니다. 동일한 데이터는 일반적으로 HDD와 같은 낮은 저장소 계층에도 존재합니다. 데이터는 캐시에 복사되지만, 원본 데이터는 초기 위치에 남아 있습니다. 캐싱은 기본적으로 일방향 거래이며, 사용 후 캐시는 데이터를 무효화합니다.
저장소 티어링은 반면에 데이터를 저장 장치 간에 물리적으로 이동시킵니다. 데이터가 핫으로 식별되면 이 데이터는 고속 계층으로 이동되어 표준 계층에는 복사본이 남아 있지 않습니다. 데이터가 냉각되면 표준 계층으로 다시 이동됩니다. 저장소 티어링은 단순히 데이터를 복사하는 대신 데이터를 느린 저장소에서 빠른 저장소로, 그 반대로 이동시키는 것을 포함합니다.
저장소 티어링과 캐싱은 모두 데이터 접근성을 향상시키지만, 자주 액세스되는 데이터를 저장하는 방식에서 다릅니다. 캐싱은 복사본을 생성하는 반면, 저장소 티어링은 데이터를 식별하고 추가 복사본을 생성하지 않고 이동시킵니다.
따라서, 계층화는 성능과 비용의 균형을 맞추기 위해 서로 다른 저장소 계층 전반에 걸쳐 장기적인 데이터 배치를 최적화하는 데 중점을 두는 반면, 캐싱은 자주 접근하는 데이터를 고속 버퍼에 일시적으로 저장하여 데이터 접근을 가속화하는 것을 목표로 합니다. 계층화와 캐싱 중 어떤 것을 선택할지는 애플리케이션 또는 저장 시스템의 특정 요구 사항과 데이터 접근 패턴의 특성에 따라 다릅니다. 어떤 경우에는 조직이 두 가지 기술을 결합하여 전반적인 성능과 비용 효율성을 극대화할 수 있습니다.
계층형 저장소 및 계층적 저장소 관리
계층형 저장소와 계층적 저장소 관리는 모두 데이터 저장소 관리에서 사용되는 전략이지만, 이들은 세분성, 데이터 이동 메커니즘 및 주요 목적에서 차이가 있습니다. 계층형 저장소는 데이터의 특성에 따라 서로 다른 저장 매체 계층으로 데이터를 분류하는 데 중점을 두는 반면, 계층적 저장소 관리는 개별 파일이나 객체를 1차 저장소와 2차 저장소 간에 투명하게 이동시켜 1차 저장소의 효율성과 비용 절감을 개선하는 데 중점을 둡니다.
저장소 계층화의 이점
저장소 계층화는 데이터 저장소 인프라를 최적화하려는 조직에 몇 가지 중요한 이점을 제공합니다. 저장소 계층화를 구현하면 다음과 같은 주요 장점을 얻을 수 있습니다:
- 향상된 성능. 자주 접근하거나 중요한 데이터를 SSD 또는 NVMe 저장소와 같은 고성능 저장소 계층에 배치함으로써 저장소 계층화는 시스템 성능을 크게 향상시킬 수 있습니다. 이는 지연 시간이 줄어들고 애플리케이션과 사용자를 위한 데이터 접근 시간이 빨라져 생산성과 사용자 만족도가 향상되는 결과를 초래합니다.
- 효율적인 자원 활용. 저장 티어링은 각 저장 티어가 효율적으로 사용되도록 하여 고성능 저장 매체의 과다 공급과 저렴한 비용의 저장 공간의 저효율화를 피합니다. 이는 저장 인프라의 투자 수익을 극대화합니다.
- 비용 최적화. 저장 티어링은 조직이 고성능을 요구하는 데이터에만 비싼 저장 자원을 할당하고, 중요하지 않거나 드물게 액세스되는 데이터를 하드 디스크 드라이브나 클라우드 저장소와 같은 저가 티어에 저장할 수 있도록 돕습니다. 이러한 비용 최적화는 하드웨어 및 운영 비용에서 잠재적인 비용 절감을 이끌어 냅니다.
- 균형 잡힌 워크로드. 저장 티어링은 데이터와 워크로드를 여러 티어로 분산시켜 리소스에 대한 경쟁을 줄입니다. 특히 일부 애플리케이션이 고성능을 요구하는 반면 다른 애플리케이션은 보다 요구가 적은 저장 요구 사항이 있는 환경에서 이것은 특히 가치 있는 기능입니다.
- 적응형 데이터 관리. 데이터 액세스 패턴은 시간이 지남에 따라 변할 수 있습니다. 저장 티어링 솔루션은 이러한 패턴을 지속적으로 분석하고 필요에 따라 데이터를 티어 간에 자동으로 이동시킵니다. 이러한 적응성은 액세스 요구 사항이 변할 때도 데이터가 가장 적합한 저장 티어에 남아 있도록 보장합니다.
- 확장성. 데이터 저장 필요가 증가함에 따라 저장 티어링을 사용하여 조직이 저장 인프라를 효율적으로 확장할 수 있습니다. 새로운 저장 티어를 추가하거나 기존 티어를 확장하여 증가하는 데이터 양과 성능 요구 사항을 수용할 수 있습니다.
- 단순화된 데이터 관리. 스토리지 계층화 솔루션에는 종종 자동화된 정책과 관리 도구가 포함되어 있어 데이터 관리 작업을 단순화합니다. 이는 수동 데이터 배치 및 이동과 관련된 관리 오버헤드를 줄여줍니다.
- 컴플라이언스 및 보존. 규제 또는 컴플라이언스 요구 사항이 있는 조직은 스토리지 계층화를 통해 데이터가 법적 명령에 따라 저장되고 보존되도록 보장받습니다. 컴플라이언스 데이터는 필요한 보안 및 보존 정책을 가진 특정 스토리지 계층에서 관리될 수 있습니다.
- 데이터 보호 및 재해 복구. 데이터를 중요도에 따라 분류함으로써 스토리지 계층화는 조직이 데이터 보호 노력을 우선시할 수 있도록 도와줍니다. 중요한 데이터는 탄력적이고 중복된 계층에 저장되어 장애나 재해 발생 시 데이터 가용성과 복구 가능성을 보장합니다.
- 최적화된 백업 및 복원. 데이터의 중요도와 접근 패턴에 따라 데이터를 분리함으로써 스토리지 계층화는 백업 및 복원 작업의 우선순위를 정하는 데 도움이 됩니다. 중요한 데이터는 더 높은 빈도로 백업될 수 있으며, 덜 중요한 데이터는 더 긴 백업 간격이 적용될 수 있습니다.
저장 계층의 주요 목적은 데이터 배치와 저장 비용을 최적화하는 것이지만, 제공하는 이점은 조직의 재난 복구 능력을 향상시킬 수도 있습니다. 중복성과 비용 효율적인 데이터 보존은 성공적인 데이터 복구의 가능성을 높입니다. 이는 조직이 최소한의 데이터 손실과 다운타임으로 비즈니스 연속성을 유지하고 재난에서 복구할 수 있도록 도와줌으로써 전반적인 재난 복구 준비성을 향상시킵니다.
스토리지 계층화 모범 사례
스토리지 계층화는 데이터 저장을 최적화하기 위한 귀중한 기술이지만, 그 효과와 효율성을 보장하기 위해 모범 사례를 따르는 것이 중요합니다. 스토리지 계층화 모범 사례는 다음과 같습니다:
- 데이터 이해하기. 데이터의 특성, 접근 패턴 및 중요성을 이해하기 위해 철저한 분석을 수행하십시오. 모든 데이터가 계층화될 필요는 없으므로, 계층형 저장소에서 가장 큰 혜택을 받을 데이터 세트를 식별해야 합니다.
- 적절한 저장 매체 선택. 조직의 성능 및 예산 요구 사항에 따라 각 계층에 적합한 저장 매체를 선택하십시오. 솔리드 스테이트 드라이브, 하드 디스크 드라이브, 클라우드 저장소 및 테이프 라이브러리는 일반적인 옵션입니다.
- 정기적으로 모니터링 및 조정. 데이터 접근 패턴과 계층 활용을 추적하기 위해 저장 환경을 지속적으로 모니터링하십시오. 변화하는 요구 사항을 반영하기 위해 계층화 정책을 필요에 따라 조정하십시오. 최적의 성능을 위해 정책을 정기적으로 검토하고 미세 조정하는 것이 필수적입니다.
- 데이터 분류 및 태그 지정. 메타데이터와 데이터 태그 지정을 사용하여 데이터를 분류합니다. 이 메타데이터는 티어링 시스템이 데이터 배치에 대해 보다 정보에 입각한 결정을 내릴 수 있도록 합니다.
- 중요 데이터를 우선적으로 처리. 미션 크리티컬하고 자주 액세스되는 데이터를 고성능 티어에 배치합니다. 이를 위해서는 다양한 데이터 유형에 대해 다른 정책이나 우선 순위 수준이 필요할 수 있습니다.
- 중요 티어에 중복성 포함. 고성능 티어에 미션 크리티컬 데이터를 저장하는 경우, 하드웨어 고장으로 인한 데이터 손실을 방지하기 위해 RAID(독립 디스크의 중복 배열)와 같은 중복 메커니즘을 고려하십시오.
- 자동 티어링 정책 구현. 티어 간 데이터 이동에 대한 명확하고 자동화된 정책을 정의합니다. 이러한 정책은 액세스 빈도, 데이터 나이 및 성능 요구 사항과 같은 요소를 고려해야 합니다. 데이터 배치 및 마이그레이션을 자동화하면 데이터가 항상 올바른 티어에 배치되도록 할 수 있습니다.
- 보안 및 접근 제어 제공. 모든 티어의 데이터에 적절한 보안 조치 및 접근 제어를 구현합니다. 민감한 데이터가 보호되고 권한이 있는 사용자만 액세스할 수 있도록 합니다.
- 백업 및 재해 복구. 데이터 보호 및 재해 복구를 계획합니다. 백업 및 복구 전략이 스토리지 티어링 접근 방식과 일치하도록 합니다. 중요한 데이터는 더 자주 백업되고 안전하게 유지되어야 합니다.
- 확장성. 스토리지 티어링 전략을 확장 가능하도록 설계합니다. 데이터 저장 요구 사항이 증가함에 따라 더 많은 티어를 추가하거나 기존 티어를 확장할 준비를 합니다.
- 하이브리드 클라우드 솔루션 고려. 조직의 필요에 따라 클라우드 스토리지를 스토리지 계층 중 하나로 통합하는 것을 고려하십시오. 하이브리드 클라우드 솔루션은 확장성과 유연성을 제공합니다.
- 기술을 정기적으로 평가. 스토리지 기술의 발전에 대해 정보를 지속적으로 습득하십시오. 기술이 진화함에 따라 새로운 스토리지 미디어와 솔루션이 비용 효율적이고 스토리지 계층에 적합할 수 있습니다.
NAKIVO 백업 & 복제와 백업 스토리지 계층화
NAKIVO Backup & Replication은 다양한 스토리지 계층과 함께 작동할 수 있는 최신 데이터 보호 및 재해 복구 솔루션으로, 특정 필요와 사용 가능한 스토리지 인프라에 따라 백업 및 복구 전략을 최적화할 수 있습니다. NAKIVO 솔루션은 온프레미스 스토리지, 클라우드 스토리지 및 중복 제거 장치를 포함한 다양한 스토리지 유형을 지원합니다.
NAKIVO Backup & Replication을 다른 스토리지 계층에 백업하도록 구성할 수 있습니다. 예를 들어, 중요한 백업은 빠른 복구를 위해 고성능 스토리지(Tier 1)에 저장하고, 덜 중요한 백업은 장기 보관을 위해 저비용 스토리지(Tier 2 또는 클라우드)로 이동할 수 있습니다.
제품은 백업 복사 및 복제와 같은 기능을 제공하여 다른 스토리지 계층에 백업의 추가 복사본을 생성할 수 있습니다. 이는 백업을 여러 위치 또는 스토리지 계층에 배치하여 데이터 중복성과 재해 복구 준비 태세를 강화합니다.
NAKIVO Backup & Replication에서는 보존 정책을 정의하여 티어링 전략에 기반해 백업 데이터를 자동으로 관리할 수 있습니다. 예를 들어, 백업은 Tier 1에서 짧은 기간 동안 보존한 후에 장기적인 보존을 위해 Tier 2로 이동될 수 있습니다.
NAKIVO 솔루션은 인기 있는 클라우드 스토리지 제공업체를 지원합니다. 이는 클라우드 스토리지를 오프사이트 백업의 저장 티어로 쉽게 통합할 수 있으므로 추가 온프레미스 인프라의 필요성을 줄일 수 있습니다.
결론
다중 티어 스토리지 아키텍처를 통해 조직은 데이터의 특정 요구에 따라 저장 리소스를 할당할 수 있습니다. 데이터를 가장 적합한 티어에 배치함으로써, 중요한 데이터는 필요한 성능을 확보하고, 중요하지 않거나 드물게 액세스되는 데이터는 비용 효율적으로 저장할 수 있습니다. 자동 데이터 티어링 정책과 관리 도구를 사용하여 액세스 패턴과 요구 사항이 시간에 따라 변경될 때 데이터가 티어 간에 이동되도록 보장할 수 있습니다.