













Organisationen müssen heute Speicherplatz rational nutzen, da große Datenmengen die Speicherkosten erhöhen und zu einer Datenvervielfachung führen können. Datenspeichermedien unterscheiden sich hinsichtlich Kosten, Schreib-/Lesegeschwindigkeit usw., und verschiedene Arten von Daten sollten auf den effizientesten Medien gespeichert werden, um Kosten und Ressourcen zu sparen.
Zum Beispiel ist es unnötig teuer, Backups auf Hochgeschwindigkeits-SSD (Solid-State-Drive)-Geräten zu speichern, da die hohe Geschwindigkeit von SSDs für diese Art von Sekundärdaten nicht erforderlich ist. Im Gegensatz dazu kann die Speicherung von Produktions-Virtualisierungsmaschinen (VMs) auf Festplattenlaufwerken (HDDs) mit niedriger Umdrehungsgeschwindigkeit budgetfreundlich sein, aber nicht den Leistungsanforderungen für Primärsysteme entsprechen.
Aus diesem Grund sollten Speichertypen kategorisiert werden, um jeden Speichertyp zur Speicherung der geeigneten Daten durch Speichertierung zu verwenden.
Was ist Speichertierung?
Speichertierung ist eine Datenverwaltungsstrategie, die zur Optimierung der Leistung und Kosteneffizienz eines Speichersystems verwendet wird, indem Daten basierend auf ihren Eigenschaften und Zugriffsmustern in verschiedene Ebenen unterteilt werden. Das Hauptziel der Speichertierung besteht darin, sicherzustellen, dass die am häufigsten abgerufenen und wichtigen Daten auf Hochleistungsspeichermedien gespeichert werden, während seltener abgerufene Daten oder weniger wichtige Daten auf kostengünstigerem Speicher gespeichert werden.
Dieser Ansatz ermöglicht es Organisationen, ihre Daten auf verschiedenen Arten von Speichermedien zu speichern, wie schnellen und teuren Solid-State-Laufwerken (SSDs) oder langsameren, aber kostengünstigeren Festplattenlaufwerken (HDDs), abhängig vom Wert der Daten und den Nutzungsmustern.
Die Speicher-Tierung beginnt mit der Einteilung von Daten in verschiedene Kategorien oder Ebenen basierend auf Kriterien wie Häufigkeit des Zugriffs, Bedeutung und Leistungsanforderungen. Diese Klassifizierung kann sich im Laufe der Zeit ändern, wenn der Arbeitsprozess dies erfordert. Die Anzahl und Arten von Speichertierungen können je nach Speicherinfrastruktur variieren.
A tiered storage architecture helps organizations reduce storage costs by allocating high-cost storage resources only to the data that requires it. This ensures that expensive resources are not wasted on data that doesn’t benefit from them. By placing hot (frequently accessed) data on high-performance storage media and cold (less frequently accessed) data on lower-performance media, storage tiering optimizes overall system performance.
Datentypen für gestufte Speicherung
Datentypen in einer gestuften Speicherarchitektur beziehen sich auf die Kategorisierung oder Klassifizierung von Daten basierend auf bestimmten Attributen oder Merkmalen. Diese Klassen erstellen eine Datenhierarchie und helfen dabei zu bestimmen, wo Daten innerhalb eines gestuften Speichersystems gespeichert werden sollten. Dieser Ansatz gewährleistet, dass Daten auf der am besten geeigneten Speichertier platziert werden, um Leistung, Kosten und Zugänglichkeit auszugleichen. Die Details der Datentypen können je nach den Bedürfnissen der Organisation und der Speicherinfrastruktur variieren. Die üblichen Attribute, die für die Datenklassifizierung verwendet werden, sind:
- Zugriffshäufigkeit. Ein primäres Kriterium für die Datenklassifizierung ist, wie häufig sie von Benutzern und Anwendungen abgerufen wird. Daten, die regelmäßig und aktiv genutzt werden (heiße Daten), sollten auf hochleistungsfähigen Speichertieren wie SSDs oder NVMe-Laufwerken gespeichert werden, um schnelle Zugriffszeiten sicherzustellen. Im Gegensatz dazu können selten abgerufene Daten (kalte Daten) auf kostengünstigere Speichertierungen wie HDDs oder Cloud-Speicher platziert werden.
- Kritikalität oder Wichtigkeit. Einige Daten sind für die Geschäftstätigkeit oder die Compliance-Anforderungen einer Organisation wichtiger als andere. Kritische Daten müssen möglicherweise auf zuverlässigeren und widerstandsfähigeren Speichertiers gespeichert werden, wie z.B. RAID (Redundant Array of Independent Disks) oder Cloud-Speicher mit Redundanz, um das Risiko von Datenverlust zu minimieren.
- Datentyp. Unterschiedliche Arten von Daten, wie Datenbankdateien, Multimedia-Inhalte, Anwendungsprotokolle oder Archivdokumente, können unterschiedliche Speicheranforderungen haben. Zum Beispiel können Multimedia-Dateien hohe Durchsatzraten und Kapazität erfordern, während Protokolle auf langsamerem Speicher gespeichert werden können, solange sie aus Compliance-Gründen aufbewahrt werden.
- Aufbewahrungszeitraum. Daten mit spezifischen Aufbewahrungs- oder Compliance-Anforderungen müssen möglicherweise auf Speichertiers gespeichert werden, die die Datenintegrität und -verfügbarkeit für die erforderliche Dauer garantieren können. Compliance-Daten erfordern oft eine langfristige Aufbewahrung und können daher auf zuverlässigeren Speichertiers gespeichert werden.
- Größe. Große Datenobjekte können von der Speicherung auf für Kapazität optimierten Speichertiers profitieren, während kleine, häufig abgerufene Daten Speicher mit geringer Latenzzeit und hoher I/O-Performance erfordern können.
- Datenlebenszyklus. Daten durchlaufen verschiedene Phasen in ihrem Lebenszyklus, von der Erstellung und aktiven Nutzung bis zur Archivierung oder Löschung. Datenklassen sollten diese Phasen berücksichtigen und Daten bei Bedarf zwischen den Speichertiers verschieben. Zum Beispiel können neu erstellte Daten auf einem leistungsstarken Tier beginnen, aber nach und nach auf kostengünstigere Tiers verschoben werden, wenn sie weniger aktiv werden.
- Kostenempfindlichkeit. Organisationen haben oft Budgetbeschränkungen. Datenklassen können dazu beitragen, die Speicherkosten mit budgetären Überlegungen in Einklang zu bringen, indem sichergestellt wird, dass teurere Speicherressourcen für Daten reserviert werden, die die Kosten rechtfertigen.
- Benutzer- oder Anwendungsanforderungen. Unterschiedliche Benutzer oder Anwendungen haben möglicherweise spezifische Speicheranforderungen. Datenklassen können diese Anforderungen berücksichtigen, um sicherzustellen, dass jede Gruppe die notwendige Speicherleistung und -kapazität erhält.
Nach der Klassifizierung der Daten in diese Klassen werden Richtlinien und Algorithmen verwendet, um die Platzierung und Bewegung von Daten innerhalb der gestuften Speicherinfrastruktur zu verwalten. Dies gewährleistet, dass Daten kontinuierlich für Leistung und Kosteneffizienz optimiert werden, während organisatorische Anforderungen und Zugriffsmuster erfüllt werden.
Klassifizierung mit heißem, warmem und kaltem Speicher
Die gängige Art der Datenklassifizierung in gestuften Speichersystemen besteht darin, Daten als geschäftskritisch, heiß, warm und kalt zu klassifizieren. Diese Klassen helfen dabei zu bestimmen, wie Daten innerhalb der Speicherinfrastruktur gespeichert, verwaltet und zugegriffen werden. In diesem Fall umfassen die in gestuften Speicherstrategien verwendeten Datenklassen:
- Geschäftskritische Daten. Diese Datenklasse bezieht sich auf Daten, die für die Kernoperationen einer Organisation absolut unerlässlich sind. Geschäftskritische Daten erfordern das höchste Maß an Leistung, Zuverlässigkeit und Verfügbarkeit. Sie werden typischerweise auf den widerstandsfähigsten und leistungsstärksten Speichermedien gespeichert, wie redundante SSD-Arrays oder fehlertolerante Speichersysteme.
- Heiße Daten. Heiße Daten beziehen sich auf Daten, die aktiv und häufig abgerufen werden. Diese Daten sind in der Regel von hoher Bedeutung für die Organisation und erfordern schnelle Reaktionszeiten und eine leistungsstarke Speicherung. Heiße Daten werden häufig auf den Speichermedien der höchsten Ebene gespeichert, wie zum Beispiel Solid-State-Laufwerken (SSDs) oder NVMe-Laufwerken, um eine geringe Latenz und schnellen Zugriff zu gewährleisten.
- Warme Daten. Warme Daten repräsentieren Daten, die seltener als heiße Daten abgerufen werden, aber dennoch aktiv genutzt werden. Diese Datenklasse befindet sich typischerweise in einer Ebene unter heißen Daten in Bezug auf Leistung, wie zum Beispiel Hochleistungs-Festplattenlaufwerken (HDDs) oder hybriden Speicherlösungen. Auch wenn warme Daten nicht die schnellste Speicherung erfordern, müssen sie dennoch für einen effizienten Zugriff sofort verfügbar sein.
- Kalte Daten. Kalte Daten umfassen Daten, die selten abgerufen werden, historisch sind oder archiviert werden. Diese Daten gelten oft als weniger kritisch und werden auf Speicherebenen mit geringeren Kosten gespeichert, wie zum Beispiel herkömmlichen, langsameren HDDs oder sogar archivierten Speicheroptionen wie Bändern oder Cloud-basierten kalten Speichern. Der Schwerpunkt bei kalten Daten liegt auf langfristiger Aufbewahrung und Kosteneinsparungen.
Die Anzahl der Datenklassen kann von der Anzahl der Speicherebenen im Speicher-Klassifizierungsmodell abhängen. Organisationen können Daten auf eine komplexere Weise klassifizieren, indem sie zusätzlich zu den oben erklärten Klassen die folgenden Datenklassen verwenden:
- Datensicherung und Katastrophenschutzdaten. Daten, die für Backup- und Katastrophenschutzzwecke verwendet werden, werden oft separat kategorisiert. Diese Datenklassen konzentrieren sich darauf sicherzustellen, dass Daten im Falle von Datenverlust oder Systemausfall zuverlässig und schnell wiederhergestellt werden können. Backup-Daten können auf festplattenbasierten Systemen gespeichert werden, während Kopien für langfristige Aufbewahrung auf Band oder in der Cloud gespeichert werden können.
- Compliance-Daten. Daten, die regulatorischen Compliance-Anforderungen unterliegen, wie Finanzdaten oder Gesundheitsdaten, haben möglicherweise spezifische Speicheranforderungen. Compliance-Datenklassen gewährleisten, dass diese Daten sicher gespeichert werden, mit Funktionen wie Verschlüsselung und strengen Zugriffskontrollen, und für die erforderliche Dauer aufbewahrt werden.
- Benutzer- oder Abteilungsdaten. Einige Organisationen klassifizieren Daten nach ihrer Herkunft, wie Daten, die von bestimmten Abteilungen oder Benutzern generiert wurden. Dieser Ansatz kann dazu beitragen, Speicherressourcen basierend auf den Anforderungen verschiedener organisatorischer Einheiten zuzuweisen.
- Temporäre oder Cache-Daten. Datenklassen für temporäre oder Cache-Daten können Daten umfassen, die nur von kurzer Dauer sind und auf Hochgeschwindigkeitsspeichertiers für schnellen Zugriff gespeichert werden können, mit dem Verständnis, dass sie verworfen oder ersetzt werden können, wenn sie nicht mehr benötigt werden.
Daten für die Migration zwischen Tiers . In einigen Fällen werden Datenklassen verwendet, um Daten zu identifizieren, die aktiv zwischen Speichertiers aufgrund von Zugriffsmustern verschoben werden. Zum Beispiel können Daten, die zu Beginn heiß sind, aber im Laufe der Zeit seltener abgerufen werden, in wärmere oder kältere Speichertiers migrieren. - Tier migration data. In einigen Fällen werden Datenklassen verwendet, um Daten zu identifizieren, die aktiv zwischen Speicherschichten wechseln, basierend auf Zugriffsmustern. Zum Beispiel kann Daten, die zunächst heiß sind, aber im Laufe der Zeit weniger häufig abgerufen werden, zu wärmeren oder kälteren Speicherschichten migrieren.
Diese Datenklassen können als Richtlinien für Speicheradministratoren und automatisierte Speicherverwaltungssysteme dienen, um fundierte Entscheidungen darüber zu treffen, wo Daten innerhalb einer geschichteten Speicherinfrastruktur platziert werden sollen.
Multi-Tiered Storage Types
Multi-tiered Speicher bezieht sich auf eine Speicherarchitektur, bei der Daten basierend auf ihren Leistungs- und Zugänglichkeitsanforderungen in verschiedene Schichten eingeteilt werden. Jede Schicht stellt ein bestimmtes Niveau der Speicherleistung und des Kostenaufwands dar. Das Ziel ist es, sicherzustellen, dass Daten auf der geeignetsten Schicht gespeichert werden, um sowohl Leistung als auch Kosteneffizienz zu optimieren. Im Folgenden sehen Sie gängige Speicherschichten, beginnend mit Schicht 0:
- Tier 0 stellt die leistungsfähigste Speicherschicht in einem mehrschichtigen Speichersystem dar. Es besteht häufig aus den schnellsten und kostenintensivsten Speichermedien, wie z.B. Unternehmens-Solid-State-Drives (SSDs) oder NVMe (Non-Volatile Memory Express) SSDs. Daten, die in Tier 0 gespeichert sind, sind in der Regel entscheidend für die Geschäftstätigkeit und erfordern extrem geringe Latenz, hohe I/O-Leistung und schnellen Datenzugriff. Sie werden für Anwendungen und Daten verwendet, die die höchsten Leistungsanforderungen stellen.
- Tier 1 bezeichnet die nächstniedrigere Ebene in Bezug auf Leistung und Kosten. Es besteht typischerweise aus leistungsfähigen Festplattenlaufwerken (HDDs), hybriden Speicherarrays (kombiniert SSDs und HDDs) oder schnelleren SSDs, die nicht so kostspielig sind wie die in Tier 0. Die Daten in Tier 1 sind wichtig, benötigen jedoch möglicherweise nicht den absolut schnellsten Speicher, der verfügbar ist. Diese Stufe eignet sich für Anwendungen und Daten, die eine gute Leistung benötigen, aber im Vergleich zu Tier 0-Daten etwas höhere Latenz tolerieren können.
- Tier 2 stellt eine kostengünstigere Speicherebene mit etwas langsamerer Leistung im Vergleich zu Tier 1 dar. Es umfasst oft traditionelle HDDs oder cloud-basierte Speicherlösungen. Die Daten in Tier 2 werden typischerweise weniger häufig abgerufen oder sind für Echtzeitanwendungen weniger kritisch. Diese Stufe eignet sich für Archivdaten, Backups und Daten, die längere Zugriffszeiten tolerieren können.
- Tier 3 ist die kostengünstigste Speicherebene in einem mehrstufigen Speichersystem. Es umfasst typischerweise Archivspeicherlösungen wie Bandbibliotheken und cloud-basierte Kaltlagerung. Die Daten in Tier 3 werden selten abgerufen und werden hauptsächlich zur Einhaltung von Vorschriften, regulatorischen Anforderungen oder für langfristige Archivierungszwecke gespeichert. Es bietet die geringste Leistung, ist aber am kosteneffizientesten.
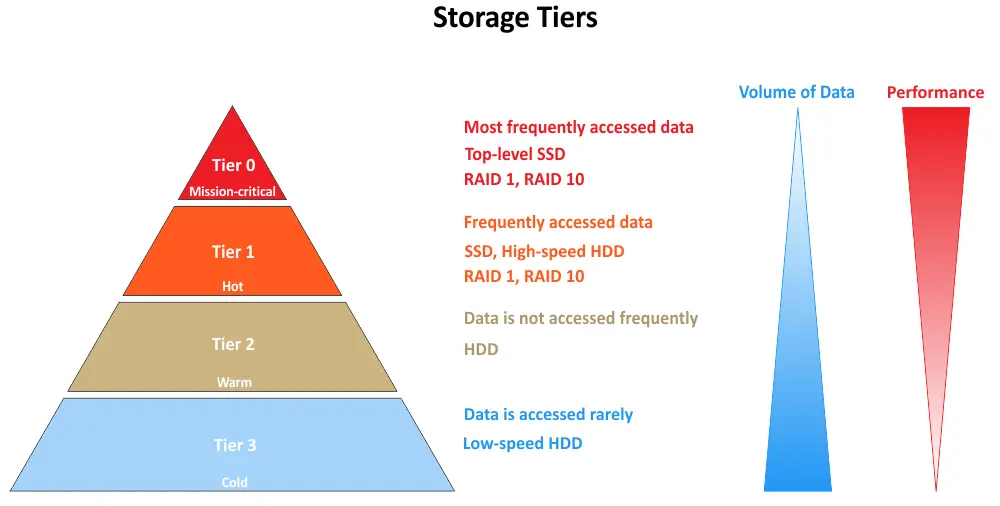
Einige Organisationen, die hauptsächlich lokales Speichervermögen nutzen, widmen zusätzliche spezielle Ebenen für den Speicher in der öffentlichen Cloud und Backup-Speicher:
- Cloud Tier. In einigen mehrstufigen Speicherarchitekturen wird ein separates Cloud Tier verwendet, um Daten in einem Cloud-Speicherdienst wie Amazon S3 oder Azure Blob Storage zu speichern. Dies ermöglicht Organisationen, skalierbare und kosteneffiziente Cloud-Speicher für Daten zu nutzen, die möglicherweise nicht einfach in lokale Speicherschichten passen. Daten im Cloud-Tier können bei Bedarf über das Internet abgerufen werden.
- Backup Tier. Obwohl Backup-Speicher nicht immer als primäre Speicherschicht betrachtet wird, ist er ein entscheidender Bestandteil der Speicherhierarchie. Backup-Daten werden je nach Backup-Strategie der Organisation auf diskbasierten Systemen oder Bandbibliotheken gespeichert. Der Schwerpunkt liegt auf Datenschutz und schnelle Wiederherstellung im Falle von Datenverlust oder Katastrophen.
Wie viele Ebenen werden in der Regel von Organisationen verwendet?
Die Anzahl der Ebenen, die Organisationen in ihren Speicherarchitekturen verwenden, kann je nach ihren spezifischen Bedürfnissen, Budgetbeschränkungen und der Komplexität ihrer Datenmanagementanforderungen stark variieren. In der Praxis implementieren jedoch viele Organisationen oft eine dreistufige Speicherhierarchie als Ausgangspunkt (Tier 0, Tier 1, Tier 2).
Viele Organisationen beginnen mit diesen drei Ebenen als Grundlage und passen dann ihre Speicherinfrastruktur an, um ihren spezifischen Bedürfnissen gerecht zu werden. Sie können zusätzliche Ebenen hinzufügen oder spezialisierte Speicherklassen übernehmen, wenn sich ihre Datenanforderungen entwickeln. Zum Beispiel:
- Einige Organisationen könnten ein Stufe 4 oder Stufe 5 für langfristige, tiefe Archivierung hinzufügen, die Technologien wie Bandbibliotheken oder sehr günstiges Cloud-Speicher beinhalten könnte.
- Andere könnten eine Cloud-Stufe für Ausfallsicherungen und Notfallwiederherstellungszwecke implementieren, indem sie Cloud-Speicherdienste wie Amazon S3 oder Azure Blob Storage nutzen.
- Hybride Cloud-Strategien können auch weitere Stufen einführen, einschließlich cloudbasierter Stufen für Daten, die nahtlos zwischen lokalem und cloudbasiertem Speicher verschoben werden müssen.
Der Schlüssel besteht darin, ein Speicherarchitektur zu entwerfen, die sich an die Datenzugriffsmuster, Leistungsanforderungen und Budgetüberlegungen der Organisation anpasst. Es ist auch wichtig, effektive Datenmanagement- und Schichtungsrichtlinien zu implementieren, um sicherzustellen, dass Daten auf der entsprechenden Stufe auf der Grundlage der sich ändernden Bedürfnisse dieser Daten im Laufe der Zeit gespeichert werden. Da sich Datenspeichertechnologien weiterentwickeln, können Organisationen ihre gestuften Speicherstrategien anpassen, um sich von neuen Innovationen und kosteneffizienten Lösungen zu profitieren.
Diese häufigen Speicherstufen können in einer Tabelle mit kurzen Erklärungen und typischen Anwendungsfällen zusammengefasst werden:
| Tier Nummer | Tier Name | Erklärung | Typische Anwendungsfälle |
| Tier 0 | Ultra-schneller SSD | Höchstleistungs-Speicher, geringe Latenz | Kritische Datenbanken, Echtzeit-Anwendungen |
| Tier 1 | Hochleistungs-SSD | Gute Balance aus Geschwindigkeit und Kosten | Allgemeine Anwendungsdaten, virtuelle Maschinen |
| Tier 2 | Hybrid-Speicher | Kombination aus SSDs und HDDs, kosteneffizient | Sicherungsspeicher, sekundäre Daten, Dateifreigaben |
| Tier 3 | Nearline-HDD | Sicherungsspeicher, sekundäre Daten, Dateifreigaben | Archivdaten, langfristiger Speicher |
| Tier 4 | Kaltes Speicher | Kostengünstig, sehr hohe Kapazität, langsame Zugriffsgeschwindigkeit | Selten zugängliche Archivdaten |
| Cloud Tier | Cloud-Speicher | Skalierbarer cloud-basierter Speicher | Offsite-Backups, Notfallwiederherstellung, Datenteilung |
Bitte beachten Sie, dass die Namen und Eigenschaften von Speichertiers von Organisationen und Speicheranbietern variieren können. Die obige Tabelle bietet einen allgemeinen Überblick über gebräuchliche Speichertiers und ihre typischen Anwendungsfälle, aber spezifische Implementierungen können sich je nach den Anforderungen der Organisation und verfügbaren Technologien unterscheiden.
Wo Speichertiers Angewendet Werden
Speichertierarchie ist eine Speicherverwaltungsstrategie, die sowohl vor Ort (innerhalb der eigenen Rechenzentren oder privater Cloud-Umgebungen einer Organisation) als auch in der öffentlichen Cloud eingesetzt werden kann. Es ist ein flexibler Ansatz, der auf verschiedene Speicherarchitekturen angewendet werden kann, um die Datenplatzierung und Zugriffsverhalten zu optimieren.
Speicherklassentrennung vor Ort
Speicherklassentrennung wird in den folgenden Umgebungen eingesetzt, die sich auf die vor Ort (lokale) Infrastruktur konzentrieren:
- Traditionelle Rechenzentren. In traditionellen, vor Ort befindlichen Rechenzentren wird die Speicherklassentrennung häufig eingesetzt, um Daten auf verschiedenen Arten von Speichermedien wie SSD, HDD und Bandbibliotheken zu verwalten. Organisationen setzen die Speicherklassentrennung ein, um die Leistung, den Kosten und die Datenverfügbarkeit innerhalb von ihrer eigenen Infrastruktur zu optimieren.
- Private Clouds. Viele private Cloud-Umgebungen integrieren die Speicherklassentrennung, um Daten effizient über verschiedene Arten von Speicherressourcen zu verwalten. Dies ist besonders wichtig in privaten Cloud-Setup, in denen Ressourcen dynamisch zugewiesen werden müssen, um verschiedene Workloads zu unterstützen.
- Hybrid Clouds. In einer Hybrid-Cloud-Umgebung, die vor Ort befindliche Infrastruktur mit öffentlichen Cloud-Ressourcen kombiniert, kann die Speicherklassentrennung eingesetzt werden, um die Datenplatzierung in beiden Umgebungen zu optimieren. Organisationen können Klassifizierungsrichtlinien verwenden, um zu bestimmen, welche Daten vor Ort bleiben sollten und welche in die öffentliche Cloud verschoben werden sollten, um Kosteneffizienz oder Skalierbarkeit zu erreichen.
Speicherklassentrennung in der öffentlichen Cloud
Im Hinblick auf die öffentliche Cloud wird die Speicherklassentrennung in den folgenden Umgebungen eingesetzt:
- Öffentliche Cloud-Speicherdienste. Öffentliche Cloud-Anbieter wie Amazon Web Services (AWS), Microsoft Azure und Google Cloud Platform (GCP) bieten ihre eigenen Cloud-Speicherrangfolgenoptionen als Teil ihrer Cloud-Speicherdienste an. Beispielsweise bietet AWS S3-Speicherklassen (Standard, Intelligent-Tiering, Glacier usw.), die jeweils auf unterschiedliche Leistungs- und Kostenanforderungen zugeschnitten sind.
- Objektspeicherung. Objektspeicherung -Dienste in der öffentlichen Cloud unterstützen oft die Speicherrangfolge, um Kunden dabei zu helfen, die geeignetste Speicherklasse für ihre Daten auszuwählen. Dies ist vorteilhaft für die Optimierung von Kosten und Zugriffszeiten.
Automatisierte Speicherrangfolge
Automatisierte Speicherrangfolge und Speicherrangfolgenoptimierung sind Techniken, die in der modernen Datenspeicherverwaltung verwendet werden, um sicherzustellen, dass Daten effektiv und zum richtigen Zeitpunkt auf die geeignetste Speicherrangfolge gesetzt werden.
AutomatisiertSpeicherrangfolge ist eine Datenmanagementtechnik, die das automatische und dynamische Verschieben von Daten zwischen verschiedenen Speicherrängen auf der Grundlage spezifischer Richtlinien und Kriterien beinhaltet. Diese Richtlinien werden in der Regel von Speicheradministratoren definiert oder von intelligenten Speicherverwaltungssoftware festgelegt. Das Hauptziel der automatisierten Speicherrangfolge ist die Optimierung der Speicherressourcen durch die Sicherstellung, dass Daten zu jedem Zeitpunkt auf dem geeignetsten Speicherrang gespeichert werden.
Automatisierte Speicherebenenoptimierung ermöglicht es Ihnen, Ihre Speicherebenen dynamisch zu optimieren, indem sie kontinuierlich Datennutzung und -zugriff überwacht, um Datenprioritäten und die erforderlichen Ebenen festzulegen. Wenn Sie automatisierte Speicher verwenden, legen Sie Ihre bevorzugten Schwellenwerte fest und die Automatisierung kümmert sich um den Rest.
Wenn die Datennutzung bestimmte Schwellenwerte erreicht, wird sie entsprechend verschoben. Steigt die Häufigkeit des Datenzugriffs, wird sie auf eine niedrigere Latenzebene verschoben. Wenn Daten ungenutzt bleiben, werden sie auf eine kostengünstigere, höher latenzbehaftete Ebene verschoben. Dieser Ansatz optimiert sowohl Ihre Kosten als auch die Leistung mit minimalem Aufwand und ohne laufenden Wartungsbedarf.
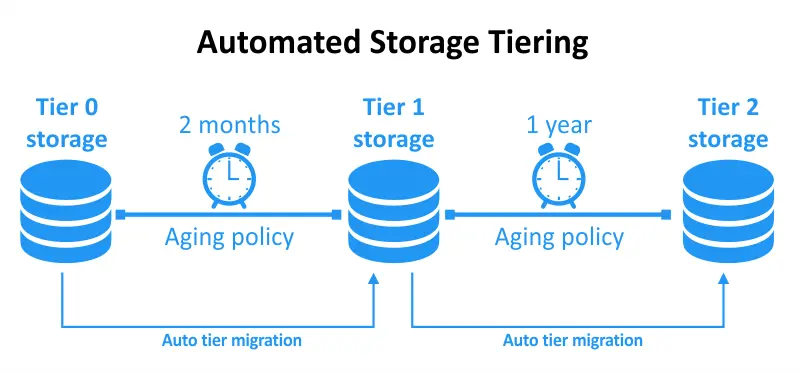
Die automatisierte Speicherebenenoptimierung ermöglicht die gesteuerte Datenübertragung zwischen Speicherebenen und passt sich so den Benutzerleistungs- und Kapazitätsanforderungen an. Diese Funktion arbeitet effizient mit Ihrer vorhandenen geschichteten Speicherarchitektur zusammen und vereinfacht die Datenverwaltung durch Automatisierung. Die automatisierte Speicherebenenoptimierung verbessert die Leistungsoptimierung und Kosteneffizienz aufgrund der Echtzeitanpassung und schnellen Datenbewegung.
SpeicherebeneOptimierung ist ein umfassenderer Begriff, der verschiedene Strategien umfasst, einschließlich automatisierterSpeicherebenenoptimierung, um sicherzustellen, dass die Speicherinfrastruktur einer Organisation effizient verwaltet und genutzt wird. Während die automatisierte Speicherebenenoptimierung ein zentrales Element der Speicherebenenoptimierung ist, können auch andere Techniken und Best Practices beteiligt sein.
Tiering vs. Caching
Tiering und Caching sind zwei unterschiedliche Techniken, die in der Datenspeicherung und -verwaltung eingesetzt werden – sie dienen unterschiedlichen Zwecken. Die Begriffe Tiering und Caching werden häufig fälschlicherweise synonym verwendet, beziehen sich jedoch auf zwei verschiedene Beschleunigungstechniken für die Speicherung. Beide beinhalten das Platzieren häufig aufgerufener oder heißer Daten auf schnellen Medien wie Flash. Die Ähnlichkeiten enden jedoch größtenteils dort.
Caching speichert Daten vorübergehend auf einem leistungsfähigen Medium wie DRAM oder Festkörperspeicher, um die Leistung zu steigern. Der Cache befindet sich zwischen der Anwendung und dem Back-End-Speicher. Die gleichen Daten befinden sich auch auf einem niedrigeren Speicherebene, meistens einem HDD. Daten werden in den Cache kopiert, aber die ursprünglichen Daten verbleiben an ihrem ursprünglichen Ort. Caching ist grundsätzlich ein einfacher Vorgang und der Cache macht die Daten nach der Verwendung ungültig.
Speichertyering hingegen bewegt Daten physisch zwischen Speichergeräten. Wenn Daten als heiß identifiziert werden, werden sie auf eine schnellere Ebene verschoben, wodurch die Standardebene frei von einer Kopie wird. Wenn die Daten abkühlen, werden sie zurück auf die Standardebene verschoben. Speichertyering beinhaltet das Verschieben von Daten anstelle des bloßen Kopierens, sowohl von langsameren Speichermedien zu schnelleren Speichermedien als auch umgekehrt.
Sowohl Speichertyering als auch Caching verbessern die Datenzugriffsmöglichkeiten, unterscheiden sich jedoch in der Art und Weise, wie sie Speicher für häufig aufgerufene Daten nutzen. Caching erstellt Kopien, während Speichertyering Daten identifiziert und sie ohne zusätzliche Kopien verschiebt.
Folglich konzentriert sich das Schichten von Daten auf die Optimierung der langfristigen Datenplatzierung über verschiedene Speicherschichten, um einen Ausgleich zwischen Leistung und Kosten zu erzielen, während das Caching darauf abzielt, den Datenzugriff zu beschleunigen, indem häufig genutzte Daten vorübergehend in einem Hochgeschwindigkeitsbuffer gespeichert werden. Die Wahl zwischen Schichten und Caching hängt von den spezifischen Anforderungen der Anwendung oder des Speichersystems und der Art der Datenzugriffsabläufe ab. In einigen Fällen können Organisationen beide Techniken kombinieren, um die beste Gesamtleistung und Kosteneffizienz zu erzielen.
Schichtspeicherung und Hierarchische Speicherverwaltung
Schichtspeicherung und hierarchische Speicherverwaltung sind beide Strategien in der Datenspeicherverwaltung, aber sie unterscheiden sich in ihrer Granularität, den Datenbewegungsmechanismen und ihren Hauptzielen. Schichtspeicherung konzentriert sich darauf, Daten anhand von Merkmalen in diskrete Speicherschichten einzuteilen, während hierarchische Speicherverwaltung darauf abzielt, einzelne Dateien oder Objekte transparent zwischen primärem und sekundärem Speicher zu migrieren, um die Effizienz und Kosteneinsparungen des primären Speichers zu verbessern.
Vorteile der Speicherschichtung
Die Speicherschichtung bietet Organisationen, die ihre Datenspeicherinfrastruktur optimieren möchten, mehrere bedeutende Vorteile. Die wichtigsten Vorteile der Implementierung der Speicherschichtung sind:
- Verbesserte Leistung. Durch das Platzieren häufig genutzter oder entscheidender Daten auf leistungsfähigen Speicherschichten, wie z.B. Solid-State-Drives oder NVMe-Speicher, kann die Speicherschichtung die Systemleistung erheblich verbessern. Dies führt zu verringerter Latenz und schnelleren Datenzugriffszeiten für Anwendungen und Benutzer, was zu erhöhter Produktivität und Benutzerzufriedenheit führt.
- Effiziente Ressourcennutzung. Die Speicherhierarchie stellt sicher, dass jede Speicherstufe effizient genutzt wird, wodurch der Überbereitstellung von Hochleistungs-Speichermedien und der Unterauslastung von kostengünstigeren Speichern entgegengewirkt wird. Sie maximiert die Rendite (ROI) für das Speicherinfrastruktur-Investment.
- Kostenoptimierung. Durch die Speicherhierarchie können Organisationen teure Speicherressourcen nur für Daten bereitstellen, die eine hohe Leistung benötigen, während weniger kritische oder selten aufgerufene Daten auf kostengünstigeren Ebenen wie Festplatten oder Cloud-Speicher abgelegt werden können. Diese Kostenoptimierung führt zu möglichen Einsparungen bei Hardware- und Betriebskosten.
- Ausgewogene Workloads. Die Speicherhierarchie kann dazu beitragen, Daten und Workloads auf verschiedenen Ebenen zu verteilen und dadurch den Wettbewerb um Ressourcen zu reduzieren. Dies ist besonders wertvoll in Umgebungen mit gemischten Workloads, in denen einige Anwendungen eine hohe Leistung benötigen, während andere weniger anspruchsvolle Speicheranforderungen haben.
- Adaptive Datenmanagement. Die Zugriffsmuster von Daten können sich im Laufe der Zeit ändern. Speicherhierarchielösungen analysieren diese Muster kontinuierlich und verschieben Daten automatisch zwischen den Ebenen nach Bedarf. Diese Anpassungsfähigkeit stellt sicher, dass die Daten auch bei sich ändernden Zugriffsanforderungen auf der geeignetsten Speicherebene verbleiben.
- Skalierbarkeit. Bei wachsenden Datenspeicherbedarf können Organisationen mit Hilfe der Speicherhierarchie ihre Speicherinfrastruktur effizient skalieren. Neue Speicherebenen können bei Bedarf hinzugefügt oder bestehende Ebenen erweitert werden, um zunehmende Datenvolumina und Leistungsanforderungen zu bewältigen.
- Vereinfachte Datenverwaltung. Speicherschichtungs-Lösungen enthalten häufig automatisierte Richtlinien und Verwaltungswerkzeuge, die Datenverwaltungsaufgaben vereinfachen. Dies reduziert den Verwaltungsaufwand, der mit manueller Datenplatzierung und -migration verbunden ist.
- Compliance und Aufbewahrung. Organisationen mit regulatorischen oder Compliance-Anforderungen profitieren von der Speicherschichtung, indem sichergestellt wird, dass Daten entsprechend rechtlicher Vorgaben gespeichert und aufbewahrt werden. Compliance-Daten können auf spezifischen Speicherschichten mit den erforderlichen Sicherheits- und Aufbewahrungsrichtlinien verwaltet werden.
- Datenschutz und Notfallwiederherstellung. Durch die Klassifizierung von Daten nach ihrer Wichtigkeit hilft die Speicherschichtung Organisationen bei der Priorisierung von Datenschutz-Bemühungen. Kritische Daten können auf widerstandsfähigen, redundanten Schichten gespeichert werden, um die Datenverfügbarkeit und Wiederherstellbarkeit im Falle von Ausfällen oder Katastrophen sicherzustellen.
- Optimierte Sicherung und Wiederherstellung. Durch die Trennung von Daten nach ihrer Wichtigkeit und Zugriffsverhalten kann die Speicherschichtung dabei helfen, Daten für Sicherungs- und Wiederherstellungsoperationen zu priorisieren. Kritische Daten können häufiger gesichert werden, während weniger kritische Daten längeren Sicherungsintervallen unterworfen sein können.
Während der primäre Zweck von Speicherschichten darin besteht, die Datenplatzierung und Speicherkosten zu optimieren, können die von ihnen angebotenen Vorteile auch die Fähigkeit der Organisation verbessern, sich von Katastrophen zu erholen. Redundanz und kosteneffizientes Datenretention erhöhen die Chancen erfolgreicher Datenwiederherstellung. Es hilft Organisationen, Geschäftskontinuität aufrechtzuerhalten und sich von Katastrophen mit minimalem Datenverlust und Ausfallzeit zu erholen, was letztendlich ihre allgemeine Katastrophenvorsorge verbessert.
Best Practices für Speicherschichtung
Die Speicherschichtung ist eine wertvolle Technik zur Optimierung des Datenspeichers, aber es ist wichtig, Best Practices zu befolgen, um ihre Effektivität und Effizienz sicherzustellen. Die Best Practices für die Speicherschichtung sind wie folgt:
- Verstehe deine Daten. Führe eine gründliche Analyse deiner Daten durch, um ihre Eigenschaften, Zugriffsmuster und Wichtigkeit zu verstehen. Nicht alle Daten müssen geschichtet werden, deshalb solltest du herausfinden, welche Datensätze am meisten von geschichtetem Speicher profitieren würden.
- Wähle das richtige Speichermedium. Wähle das Speichermedium für jede Schicht basierend auf den Leistungs- und Budgetanforderungen deiner Organisation. Solid-state-Laufwerke, Festplattenlaufwerke, Cloud-Speicher und Bandbibliotheken sind übliche Optionen.
- Regelmäßig überwachen und anpassen. Überwache dein Speichersystem kontinuierlich, um Datenzugriffsmuster und Schichtnutzung zu verfolgen. Passe Schichtierungsrichtlinien bei Bedarf an, um sich ändernde Anforderungen widerzuspiegeln. Das regelmäßige Überprüfen und Feintunen deiner Richtlinien ist unerlässlich für optimale Leistung.
- Datenklassifizierung und -tagging verwenden. Verwenden Sie Metadaten und Datentagging, um Daten zu klassifizieren. Diese Metadaten können von Ihrem Schichtungssystem verwendet werden, um fundiertere Entscheidungen über den Datenplatzierung zu treffen.
- Kritische Daten priorisieren. Stellen Sie sicher, dass mission-kritische und häufig genutzte Daten auf Leistungstiefen platziert werden. Dies kann unterschiedliche Richtlinien oder Prioritätsstufen für verschiedene Arten von Daten erfordern.
- Redundanz in kritischen Tiefen einbeziehen. Wenn Sie mission-kritische Daten auf Leistungstiefen speichern, sollten Sie Mechanismen wie RAID (Redundant Array of Independent Disks) zur Abdeckung von Datenverlusten aufgrund von Hardwarefehlern in Betracht ziehen.
- Automatisierte Schichtungsrichtlinien implementieren. Definieren Sie klare, automatisierte Richtlinien für das Verschieben von Daten zwischen Tiefen. Diese Richtlinien sollten Faktoren wie Zugriffshäufigkeit, Datenalter und Leistungsbedarf berücksichtigen. Die Automatisierung der Datenplatzierung und -migration stellt sicher, dass die Daten immer auf der richtigen Schicht sind.
- Sicherheits- und Zugriffssteuerungen bieten. Implementieren Sie angemessene Sicherheitsmaßnahmen und Zugriffssteuerungen für Daten auf allen Tiefen. Stellen Sie sicher, dass sensiblen Daten geschützt und nur für autorisierte Benutzer zugänglich sind.
- Sicherung und Notfallwiederherstellung. Planen Sie den Datenschutz und die Notfallwiederherstellung. Stellen Sie sicher, dass Sicherungs- und Wiederherstellungsstrategien mit Ihrem Speicher-Schichtungsansatz übereinstimmen. Kritische Daten sollten häufiger gesichert und sicher aufbewahrt werden.
- Skalierbarkeit. Entwerfen Sie Ihre Speicher-Schichtungsstrategie skalierbar. Bei wachsenden Datenspeicheranforderungen sollten Sie darauf vorbereitet sein, weitere Schichten hinzuzufügen oder bestehende auszubauen.
- Betrachten Sie hybride Cloud-Lösungen. Je nach den Bedürfnissen Ihrer Organisation sollten Sie in Betracht ziehen, Cloud-Speicher als eine Ihrer Speicherschichten zu integrieren. Hybride Cloud-Lösungen können Skalierbarkeit und Flexibilität bieten.
- Bewerten Sie die Technologie regelmäßig. Bleiben Sie über Fortschritte in der Speichertechnologie informiert. Wenn sich die Technologie weiterentwickelt, können neue Speichermedien und -lösungen kosteneffizienter und für Ihre Speicherschichten geeigneter werden.
NAKIVO Backup & Replication und Backup-Speicherschichtung
NAKIVO Backup & Replication ist eine moderne Datenschutz- und Notfallwiederherstellungslösung, die mit verschiedenen Speicherschichten arbeiten kann und Ihnen die Optimierung Ihrer Sicherungs- und Wiederherstellungsstrategien basierend auf ihren spezifischen Bedürfnissen und der verfügbaren Speicherinfrastruktur ermöglicht. Die NAKIVO-Lösung unterstützt verschiedene Speichertypen, einschließlich On-Premises-Speicher, Cloud-Speicher und Deduplikationsgeräte.
Sie können NAKIVO Backup & Replication so konfigurieren, dass es verschiedeneSpeicherschichten für Sicherungen verwendet. Zum Beispiel können kritische Sicherungen auf leistungsfähigem Speicher (Schicht 1) für eine schnelle Wiederherstellung gespeichert werden, während weniger kritische Sicherungen zu kostengünstigerem Speicher (Schicht 2 oder Cloud) für Langzeitaufbewahrung verschoben werden.
Das Produkt bietet Funktionen wie Sicherungskopie und Replikation, die die Erstellung zusätzlicher Sicherungskopien auf verschiedenen Speicherschichten ermöglichen. Dies erhöht die Datenredundanz und die Bereitschaft für Notfallwiederherstellung, indem Sicherungen an mehreren Orten oder Speicherschichten platziert werden.
Sie können innerhalb von NAKIVO Backup & Replication Retention-Richtlinien festlegen, um Sicherungsdaten automatisch basierend auf Ihrer Schichtungsstrategie zu verwalten. Beispielsweise können Sicherungen für einen kürzeren Zeitraum auf Tier 1 aufbewahrt und dann für eine langfristige Aufbewahrung auf Tier 2 überführt werden.
Die NAKIVO-Lösung unterstützt beliebte Cloud-Speicheranbieter. Das bedeutet, dass Sie Cloud-Speicher leicht als Speicherschicht für Offsite-Backups integrieren können, was den Bedarf an zusätzlicher On-Premises-Infrastruktur reduziert.
Schlussfolgerung
Mehrstufige Speicherarchitekturen ermöglichen es Organisationen, Speicherressourcen je nach den spezifischen Anforderungen ihrer Daten zuzuweisen. Durch Platzierung von Daten auf der geeignetsten Ebene können Organisationen sowohl Leistung als auch Kosten optimieren und sicherstellen, dass wichtige Daten die erforderliche Leistung erhalten, während weniger wichtige oder selten abgerufene Daten kosteneffizient gespeichert werden. Automatisierte Daten-Schichtungsrichtlinien und Verwaltungstools helfen sicherzustellen, dass Daten je nach Zugriffsmustern und Anforderungen im Laufe der Zeit zwischen Ebenen verschoben werden.