













Введение
Методы интерпретации моделей в последние годы приобрели возрастающее значение в связи с ростом сложности моделей и связанной с этим непрозрачностью. понимание моделей является актуальной темой исследования и одним из основных направлений практических приложений, использующих машинное обучение во многих отраслях.
Captum обеспечивает ученым и разработчикам передовые техники, такие как Integrated Gradients, которые позволяют легко идентифицировать элементы, вносящие вклад в выход модели. Captum упрощает использование PyTorch моделей для создания методов интерпретируемости.
Упрощая идентификацию многих элементов, вносящих вклад в выход модели, Captum поможет разработчикам моделей создавать лучшие модели и исправлять модели, которые дают неожиданные результаты.
Описания алгоритмов
Captum — это библиотека, которая позволяет реализовать различные методы интерпретируемости. Возможно классифицировать алгоритмы атрибуции Captum в три широкие категории:
- первичные атрибуции: Определяет вклад каждого входного признака в выход модели.
- Составление слоя: Каждая нейронка в определенном слое оценивается по ее вкладу в выход модели.
- Нейронка атрибуция: Активация скрытой нейронки определяется оценкой вклада каждого входного признака.
下是Captum目前实现的主要、层和神经元归因方法的简要概述。还包括了噪声通道的描述,该通道可用于平滑任何归因方法的结果。
Captum提供了用于估计模型解释可靠性的指标,以及其归因算法。目前,他们提供了不忠实度和敏感性指标,有助于评估解释的准确性。
主要归因技术
Интегрированные градиенты
Предположим, у нас есть формальное представление глубокой сети F : Rn → [0, 1].
Пусть x ∈ Rn — текущий вход и x′ ∈ Rn — базовый вход.
В качестве базовой модели в изображениях может быть чёрным изображением, в то время как в текстовых моделях это может быть нулевой вложенной вектора.
От базового значения x′ к входу x мы вычисляем градиенты на всех точках по линейному пути (в Rn). Cуммируя эти градиенты, можно генерировать интегрированные градиенты. Интегрированные градиенты определяются как путь интегрирования градиентов по прямому пути от базового значения x′ до входа x.
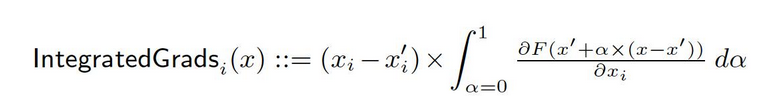
Два основных принципа, чувствительность и независимость реализации, формируют основы этой методологии. Подробнее о понятиях смотрите в первоначальной статье.
GRADient SHAP
В теории кооперативных игр Shapley-значения используются для вычисления Gradient SHAP-значений, которые вычисляются с использованием метода градиентов. Gradient SHAP добавляет гиацинтовую ошибку к каждому входному образцу многократно, затем выбирает случайную точку на пути между базовой точкой и входными данными, чтобы определить градиент выходов. В результате, окончательные SHAP-значения представляют ожидаемую величину градиентов. * (входные данные – базовые данные). SHAP-значения аппроксимируются на условии, что входные features независимы и что модель, объясняющая связь между входными данными и предложенными базовыми данными, является линейной.
DeepLIFT
Можно использовать DeepLIFT (техника рекуррентного распространения) для приписывания изменений входа на основании различий между входами и их соответствующими реféнс-данными (или базовыми значениями). DeepLIFT стремится объяснить различие между выходом для реféнс-данных, используя различие между входами из реféнс-данных. DeepLIFT использует идею множителей, чтобы “ответственность” за различие в выходах возлагать на отдельные нейроны. Для данного входного нейрона x с различием относительно реféнс-данных ∆x и целевого нейрона t с различием относительно реféнс-данных ∆t, которое мы хотим вычислить вклад, мы определяем множитель m∆x∆t как:
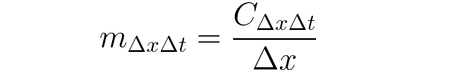
DeepLIFT SHAP
DeepLIFT SHAP является расширением DeepLIFT на основе Shapley- значений, установленных в теории кооперативных игр. DeepLIFT SHAP вычисляет атрибуции DeepLIFT для каждой пары вход-базовая данная и средняет результирующие атрибуции по входному примере с использованием распределения базовых значений. Non-linearity правила DeepLIFT помогают линеризировать нелинейные функции сети, и аппроксимация значений SHAP метода также применяется к линеризированной сети. В этом методе предполагается, что входные характеристики тоже являются независимыми.
Соответственность
Вычисление вклада входа через соответственность является простым процессом, который дает градиент выхода по отношению к входу. Используется первый порядок泰勒ское разложение на входе, и градиенты являются коэффициентами каждого признака в линейной представлении модели. Absolute value of these coefficients can be used to indicate the relevance of a feature. You can find further information on the saliency approach in the original paper.
Вход X Градиент
Ввод X Gradient является расширением метода важности, который использует градиенты выхода по отношению к входу и умножает их на значения входных особенностей. Одна интуиция для этого подхода рассматривает линейную модель; градиенты просто являются коэффициентами каждого входа, и произведение входа с коэффициентом соответствует общему вкладу особенности в выход линейной модели.
Направленное Backpropagation и Деконволюция
вычисление градиентов выполняется с помощью направленного backpropagation и деконволюции, хотя backpropagation функций ReLU заменено таким образом, чтобы распространялись только неотрицательные градиенты.尽管在 направленном backpropagation input градиенты обрабатываются с помощью функции ReLU, в деконволюции она применяется непосредственно к градиентам выхода. Обычной практикой является использование этих методов вместе с конволюционными сетями, но они также могут использоваться в других типах архитектур нейронных сетей.
Направленный GradCAM
Обработка направленных атрибутов GradCAM вычисляет произведение элементарных значений между направленными атрибутами GradCAM (направленный GradCAM) и увеличенными (слой) атрибутами GradCAM. Атрибуты вычисляются для заданного слоя и увеличиваются, чтобы соответствовать размеру входа. Внимание в этой технике привлечено к сверточным нейронным сетям. However, any layer that can be spatially aligned with the input might be provided. Typically, the last convolutional layer is provided.
Feature Ablation
Для вычисления атрибутов используется техника, известная как “feature ablation”, которая использует методperturbation-based, заменяющий известные “базовые” или “референс-значения” (например, 0) для каждого входного признака перед вычислением различия в выходах.Группировка и абляция входных признаков является лучшим вариантом, чем их индивидуальная обработка, и многие различные приложения могут выиграть от этого.При группировке и абляции сегментов изображения мы можем определить относительную важность сегмента.
Функциональная перестановка
Функциональная перестановка является методом, основанным наperturbation (perturbation), в котором каждая особенность (feature) в batch-ом рандомно переставляется, и изменения в выходе (или потертости) вычисляются в результате этого изменения. Особенности также могут быть объединены в группы, а не рассмотрены индивидуально, также как и метод удаления особенностей. Заметим, что в отличие от других алгоритмов, доступных в Captum, этот алгоритм может обеспечить корректные атрибуции, когда он выполняется с набором нескольких примеров входа. Другие алгоритмы требуют только одного примера входа.
Закрытие
Закрытие является методом, основанным наperturbation, для вычисления атрибуций, заменяющим каждую соседнюю прямоугольную область базовым значением/референсом и вычисляющий разницу в выходе. Для особенностей, расположенных в многочисленных областях (гиперромных), соответствующие разницы в выходе среднится для вычисления атрибуции для этой особенности. Закрытие наиболее полезно в таких случаях, как изображения, когда пиксели в соседних прямоугольных областях скорее всего будут сильно коррелироваться.
Шаполевская выборка значения
Способ атрибуции значение Шаполева основан на теории кооперативных игр. Этот метод берёт каждое перестановку входныхFeatures и добавляет их по одному к заданному базовому уровню. Разница в выходе после добавления каждогоFeature соответствует его вкладу, и эти различия скалярно складываются по всем перестановкам для определения атрибуции.
Lime
одним из наиболее широко используемых методов для интерпретации является Lime, который обучаетInterpretable Surrogate Model путём выборки точек вокруг входного примера и использования оценок модели в этих точках для обучения более простой интерпретируемой “заменой” модели, например, линейной модели.
Колберовы SHAP
Ядро SHAP – это техника для вычисления значений Shapley, использующая основания фреймворка LIME. Значения Shapley могут быть получены более эффективно в фреймворке LIME, устанавливая функцию потерь, вариационно учитывая ядро и правильно регулируя члены.
Техники атрибуции слоёв
Ползучесть слоя
Ползучесть слоя – это метод, который строит более полное представление о важности нейрона, объединяя активацию нейрона с частичными производными по отношению к входу и выходу. Через скрытый нейрон ползучесть строится на потоке атрибуции Integrated Gradients (IG). Общая ползучесть скрытого нейрона y определена следующим образом в первоначальной статье:
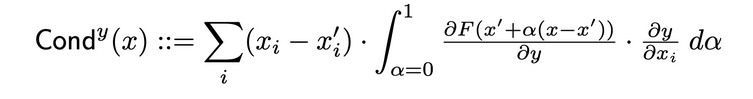
Внутренний влияние
Использование Внутреннее влияние, можно оценить интеграл градиентов по пути от базового входа до указанного входа. Эта техника схожа с применением интегрированных градиентов, заключающаяся в интегрировании градиента по отношению к слою (а не к входу).
Слойный Градиент X Активация
Слойный Градиент X Активация является эквивалентом техники Input X Gradient для скрытых слоев в сети…
Она умножает активацию элемента слоя на градиенты целевого выхода по отношению к указанному слою.
GradCAM
GradCAM является техникой атрибуции слоя конвейерной нейронной сети, которая обычно применяется к последнему слою конвейерной нейронной сети. GradCAM вычисляет градиенты целевого выхода по отношению к указанному слою, средняет каждый канал выхода (выходной размер 2) и умножает среднюю градиент канала на активации слоя. Применяется ReLU к выходу для обеспечения того, чтобы ссылки из различных каналов были неотрицательными.
Техники атрибуции нейронов
Величина проводимости нейрона
Проводимость объединяет активацию нейрона с частичными производными по отношению к входу и выходу, чтобы обеспечить более всеround представление о значимости нейрона. Чтобы определить проводимость конкретного нейрона, исследователи исследуют поток атрибуции IG от каждого входа, проходящего через этот нейрон. Ниже приведено официальное определение проводимости нейрона y при данной атрибуции входа i из исходного научного труда:
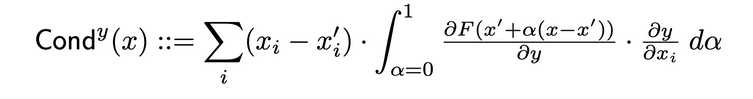
Согласно этому определению следует отметить, что скалярное сложение проводимости нейрона (по всем входным особенностям) всегда равно проводимости слоя, в котором располагается этот конкретный нейрон.
Техника градиента нейрона
Метод нейронного градиента является эквивалентом метода важности для отдельного нейрона в сети.
Он просто вычисляет градиент выхода нейрона по отношению к входу модели.
Этот метод, как и важность, может быть представлен как первый порядок泰勒-разложение выхода нейрона на данном входе, с градиентами, соответствующими коэффициентам каждого признака в линейной представлении модели.
Суммированные градиенты нейрона
Можно использовать технику, названную “Суммированными градиентами нейрона“, чтобы оценить интеграл градиентов входа относительно конкретного нейрона в течение всего пути от базового входа до входа, который интересует нас. Суммированные градиенты эквиваленты этому методу, предполагая, что выход является идентичным только выходу идентифицированного нейрона. Более подробную информацию о методе суммированных градиентов можно найти в оригинальном paper здесь.
Нейронный градиент SHAP
Ньюрон GradientSHAP является эквивалентом GradientSHAP для конкретного нейрона. Neuron GradientSHAP добавляет гауссовую шум к каждому входному образцу многократно, выбирает случайныйпункт по пути между базовым значением и входными данными и вычисляет градиент целевого нейрона по отношению к каждому случайно выбранномупункту. Результирующие значения SHAP близки к предсказанным градиентным значениям * (inputs – baselines).
Ньюрон DeepLIFT SHAP
Ньюрон DeepLIFT SHAP является эквивалентом DeepLIFT для конкретного нейрона.Utilizando la distribución de las líneas de base, el algoritmo DeepLIFT SHAP calcula la atribución de Neuron DeepLIFT para cada par de entrada-línea de base y promedia las atribuciones resultantes por ejemplo de entrada.
Туннель шума
Туннель шума является техникой атрибуции, которая может использоваться вместе с другими методами. Туннель шума вычисляет атрибуции многократно, добавляя гауссовую шум к входным данным каждый раз, а затем объединяет результирующие атрибуции в соответствии с выбранным типом. поддерживаются следующие типы туннелей шума:
- Смещённые градиенты: возвращается среднее значение наблюдаемых атрибуций. Сглаживание определённого метода атрибуций с помощью Gauss-овой ядеры является приближением данного процесса.
- СР с квадратичными смещёнными градиентами: возвращается среднее значение квадратичных наблюдаемых атрибуций.
- Вар градиенты: возвращается дисперсия наблюдаемых атрибуций.
Метрики
Неверность
Неверность оценивает среднеквадратическую ошибку между объяснениями моделей в величинах наблюдаемых поправок ввода и изменениями предсказательной функции этих поправок. Definiция неверности выглядит следующим образом:
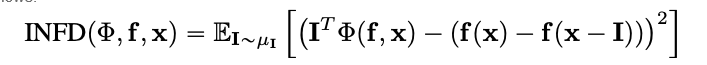
От известных методов атрибуции, таких как интегрированный градиент, этот метод является более эффективным и расширенным вариантом Sensitivy-n. последний анализирует корреляции между суммой атрибуций и различиями предсказательной функции на ее входе и предdefinемой базовой точке.
Соотношение
чувствительность , которая определяется как степень изменения объяснения при небольшом внешнем возмущении с использованием аппроксимации на основе Монте-Карло, измеряется следующим образом:

по умолчанию мы берем выборку из подпространства сферы L-Infinity с предварительно заданным半径 для аппроксимации чувствительности.Utilizeы могут изменить半径 сферы и функцию выборки.
Интерпретация модели для предобученной ResNet модели
Это руководство показывает, как использовать методы интерпретации моделей для предобученной ResNet модели с выбранным изображением и визуализирует атрибуты для каждого пикселя путем наложения их на изображение. В этом руководстве мы будем использовать алгоритмы интерпретации Integrated Gradients, GradientShape, Attribution с Layer GradCAM и Occlusion.
перед началом работы вам необходимо создать Python среду, которая включает:
- Python версии 3.6 или выше
- PyTorch версии 1.2 или выше (rekomendovannyy является последней версией)
- TorchVision версии 0
- .6 или выше (rekomendovannyy является последней версией)
- Captum (rekomendovannyy является последней версией)
В зависимости от того, используете вы Anaconda или pip виртуальную среду, следующие команды помогут вам настроить Captum:
С помощью conda:
conda install pytorch torchvision captum -c pytorch
С помощью pip:
pip install torch torchvision captum
Давайте импортируем библиотеки.
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
Загружаем обученный модель ResNet и устанавливаем ее в режим оценки
model = models.resnet18(pretrained=True)
model = model.eval()
ResNet обучено на датасете ImageNet. Загружаем и прочитаем список классов/ метках ImageNetdataset в памяти.
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
Теперь, когда мы закончили модель, мы можем скачать картинку для анализа.

В моем случае я выбрал картинку с котиком.source
Ваша папка с изображениями должна содержать файл cat.jpg. Как我们可以看到 ниже, Image.open() открывает и идентифицирует указанный файл изображения и np.asarry() преобразует его в массив.
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
В нижеследующем коде мы определим трансформеры и нормализующие функции для изображения. Чтобы обучить нашу модель ResNet, мы использовали датасет ImageNet, который требует, чтобы изображения были определенного размера, с канальными данными нормализованными в определенный диапазон значений. transforms.Compose() комбинирует несколько трансформаций и transforms.Normalize() нормализует тензорное изображение с mean и standard deviation.
# ожидаемая модель - это 224x224 3-цветное изображение
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# нормализация ImageNet
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
# unsqueeze возвращает новый тензор с добавленной размерностью размером в один, вставленной в указанное место.
input = input.unsqueeze(0)
Теперь мы построим предсказание класса для входного изображения. Возможный вопрос: “Что модель считает, что это изображение представляет?”
# вызываем нашу модель
output = model(input)
## применяем softmax() функцию
output = F.softmax(output, dim=1)
# torch.topk возвращает k крупнейших элементов данного входного тензора по заданной размерности. K здесь равно 1
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
# преобразуем в словарь ключ-значение пар для предсказанного метки, преобразуем его в строку, чтобы получить предсказанный метк
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
выход:
Predicted: tabby ( 0.5530276298522949 )
Факт, что ResNet считает нашу картинку с котиком изображением реальной кошки, подтвержден. Но что дает модели впечатление, что это изображение кота? Чтобы получить ответ на этот вопрос, мы консультируемся с Captum.
Функция атрибуции признаков с использованием интегрированных градиентов
Одна из различных техник атрибуции признаков в Captum – это интегрированные градиенты. Интегрированные градиенты награждают каждый входной признак релевантностью, оценивая интеграл градиентов выхода модели относительно входов.
В нашем случае мы будем использовать интегрированные градиенты для определения того, какие аспекты входного изображения способствовали выданному результату. Это позволит нам определить, какие части изображения были наиболее важны для получения этого результата.
После получения карты важности с помощью интегрированных градиентов мы будем использовать визуализационные инструменты, захваченные Captum, для предоставления ясного и понятного изображения карты важности.
Интегрированные градиенты определяют интеграл градиентов выхода модели для предсказанного класса pred_label_idx по отношению к пикселям входного изображенияong path from the black image to our input image.
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
#Create IntegratedGradients object and get attributes
integrated_gradients = IntegratedGradients(model)
#Request the algorithm to assign our output target to
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
Output:
Predicted: tabby ( 0.5530276298522949 )
Посмотрим на изображение и атрибуции, которые с ним связаны, путем наложения последних на изображение. Méthode visualize_image_attr(), представленная Captum, обеспечивает набор возможностей для настройки представления данных атрибуции по вашим предпочтениям. Здесь мы передаем customs Matplotlib color map (см. LinearSegmentedColormap()).
Визуализация результатов с помощьюカラーマップ
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
# используйте helper method visualization_image_attr, чтобы показать
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
# оригинальное изображение для сравнения
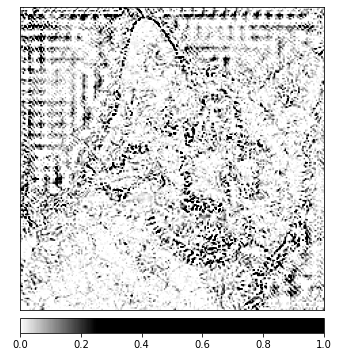
Вы сможете заметить на изображении, которое мы показали выше, что область вокруг кота является тем местом, где алгоритм Integrated Gradients дает нам наиболее сильный сигнал.
Пусть нам вычислить атрибуции с использованием Integrated Gradients, а затем выравнить их с помощью нескольких изображений, которые были созданы с помощью шумного туннеля.
Последний изменяет вход by добавляя Gaussiano шум с std = 1, 10 раз (nt_samples=10). Способ smoothgrad_sq используется шумным туннелем, чтобы сделать атрибуции устойчивыми по всем smoothgrad_sq значениям nt_samples шумных образцов. Значение visualize_image_attr_multiple() визуализирует атрибуции для данного изображения, нормализуя значения атрибуции заданного знака (положительное, отрицательное, абсолютное значение или все) и затем показывая их в фигуре matplotlib с использованием выбранного режима.
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
Выход:

Я могу видеть на изображениях выше, что модель концентрируется на голове кота.
Давайте закончим использованием GradientShap. GradientShap является методом градиентов, который может использоваться для вычисления значений SHAP, и он также отличным инструментом для получения представления о глобальном поведении. Это линейная модель объяснения, которая объясняет предсказания модели использованием распределения референсных образцов. Она определяет ожидаемые градиенты для входа, выбранного случайно между входом и базовым уровнем. Базовый уровень выбирается случайно из предоставленного распределения базовых уровней.
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# Определение распределения базовых изображений
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
Вывод:

Слой атрибуции с помощью градиентов Layer GradCAM
Вы можете связать деятельность скрытых слоев в вашей модели с особенностями вашего входного данных с помощью атрибуции слоёв.
Мы примем алгоритм для атрибуции слоёв, чтобы исследовать деятельность одного из конвульсионных слоёв, включенных в нашу модель.
GradCAM отвечает за вычисление градиентов целевого выхода по отношению к указанному слою. Эти градиенты затем среднятся для каждого канала выхода (димензия 2 выхода), и активации слоя умножаются на средний градиент для каждого канала.
Результаты складываются по всем каналам. Так как деятельность конвульсионных слоёв часто картографируется в пространстве на вход, атрибуции GradCAM часто увеличиваются и используются для маскирования входа. Стоит отметить, что GradCAM был специально разработан для конвульсионных нейронных сетей (convnets). Атрибуция слоёв настраивается так же, как и атрибуция входа, за исключением того, что кроме модели вам также нужно предоставить скрытый слой внутри модели, который вы хотите анализировать. Similar to what was discussed before, when we call attribute(), we indicate the target class of interest.
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
To make a more accurate comparison between the input image and this attribution data, we will upsample it with the help of the function interpolate(), located in the LayerAttribution base class.
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
Output:
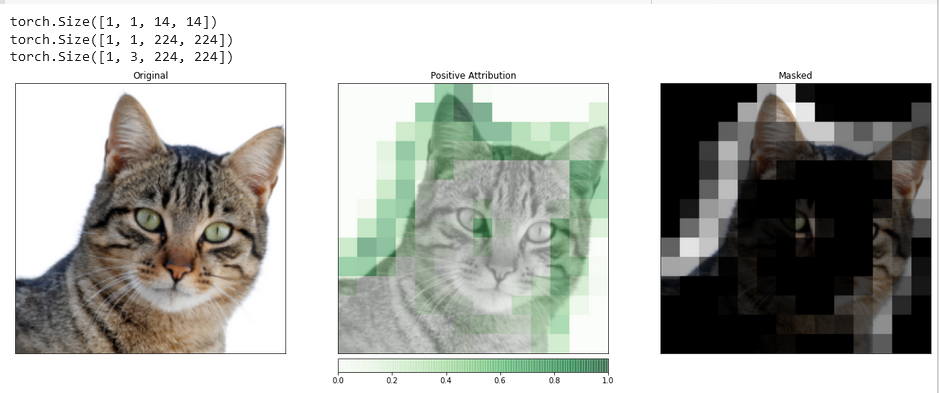
Visualizations such as this one have the potential to provide you with unique insights into how your hidden layers respond to the input you provide.
Функциональное атрибутирование с обмазкой
Методы, основанные на градиентах, помогают понять модель путём прямого вычисления изменений в выходе с учетом входа.
Техника, известная как атрибутирование на основеperturbation, принимает более прямой подход к этому вопросу, изменяя вход для оценки влияния таких изменений на выход. Один из таких стратегий называется обмазкой.
Она включает замену частей входной картинки и анализ того, как это изменение сказывается на сигнале, производимом на выходе.
В следующем разделе мы настроим атрибутирование обмазки. Similar to the configuration of a convolutional neural network, you can choose the size of the target region and a stride length, which determines the spacing of individual measurements.
Мы будем использовать функцию visualize_image_attr_multiple() для просмотра результатов нашего атрибутирования обмазки. Эта функция будет отображать карты температуры положительных и отрицательных атрибуций для каждого региона и прикрывать исходную картинку областями положительных атрибуций.
Прикрытие обеспечивает очень яркое представление о областях на нашей картинке с кошкой, которые модель определила как наиболее “кошкоподобные”.
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
Выход:
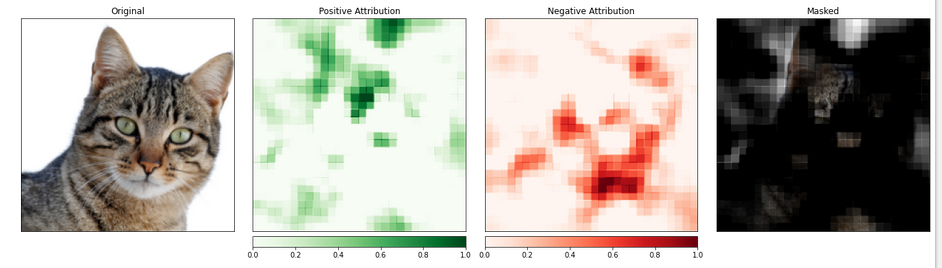
Промежуток картинки с кошкой, по-видимому, обладает более высоким уровнем важности.
Заключение
Captum является библиотекой для модельной интерпретируемости PyTorch, которая является гибкой и простой. Она предлагает современные техники для понимания того, как определённые нейроны и слои влияют на предсказания.
У неё три основных типа методов атрибуции: главные методы атрибуции, методы атрибуции слоёв и методы атрибуции нейронов.
Примечания
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf