













مقدمة
اكتسبت طرق تفسير النماذج أهمية متزايدة في السنوات الأخيرة نتيجة مباشرة لزيادة تعقيد النماذج والشفافية المرتبطة بها. فهم النموذج هو موضوع ساخن للدراسة ومجال محوري للتطبيقات العملية التي تستخدم تعلم الآلة في مختلف القطاعات.
توفر Captum للأكاديميين والمطورين تقنيات متقدمة مثل التدرجات المتكاملة التي تجعل من السهل تحديد العناصر التي تساهم في نتيجة النموذج. يجعل Captum من السهل على الباحثين في تعلم الآلة استخدام نماذج PyTorch لبناء طرق التفسير.
من خلال تسهيل تحديد العديد من العناصر التي تساهم في نتيجة النموذج ، يمكن لـ Captum مساعدة مطوري النماذج في إنشاء نماذج أفضل وإصلاح النماذج التي تقدم نتائج غير متوقعة.
وصف الخوارزمية
يعد Captum مكتبة تسمح بتنفيذ أنواع مختلفة من النهج التفسيري. يمكن تصنيف خوارزميات الإسناد في Captum إلى ثلاث فئات رئيسية:
- الإسناد الأساسي: يحدد مساهمة كل ميزة مدخل في نتيجة النموذج.
- تخصيص الطبقات: يتم تقييم مساهمة كل خلية في طبقة معينة في ما يمكن أن تساهم في مخرج النموذج.
- تخصيص الخلايا المخفية: يتم تحديد تنشيط الخلية المخفية بتقييم مساهمة كل ما يلي صفة المدخل.
ما يلي مرور سريع عن أشكال التخصيص المتبعة حاليًا داخل Captum للتخصيص الأولي، والطبقي، والخليوي. أيضًا يتضمن وصف النقب الضوئية، التي يمكن استخدامها لتنظيف نتائج أي طريقة من التخصيص.
Captum يوفر معايير لتقدير موثوقية توضيحات النموذج بالإضافة إلى خوارزميات التخصيص. في هذه الأثناء ، يوفرون معايير الخطأ والحساسية التي تساعد في تقييم دقة التوضيحات.
تقنيات التخصيص الأولي
التكامل الموحد للتقدمات
لنقل لدينا تمثيل رسمي لشبكة عميقة، F : Rn → [0, 1].
دعونا يكون x ∈ Rn الإدخال الحالي و x′ ∈ Rn الإدخال الأساسي.
قد يكون الأساس في شبكات الصور هو الصورة السوداء، بينما قد يكون في نماذج النصوص مجموعة التكامل الصفرية.
من الأساس x′ إلى الإدخال x، نحن نحاول حساب المسافرات في جميع النقاط على طريق الخط المستقيم (في Rn). من خلال تراكم هذه المسافرات، يمكن إنشاء المسافرات المتكاملة. تعرف المسافرات المتكاملة كمعدل المسافرات للمسافرات على طريق مباشر من الأساس x′ إلى الإدخال x.
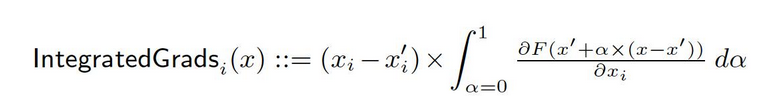
يتمثل الأساسيات الجانبين الأوليين، الحساسية ولا تغير التنفيذ، في الأساس لهذه الطريقة. يرجى المرور إلى الوثيقة الأصليةلتعلم المزيد عن هذه الأيقونات.
شبكة المسافرات المتكاملة
قيم الشابلي في النظرية التعاونية للألعاب يستخدم لحساب قيم الشابلي المتقاءة بالتقدم، التي يتم حسابها بواسطة طريقة التقدم. التقدم المتقاء بالشابلي يضيف ضجيج قوسي لكل عينة المدخلات مرات عديدة، ثم يختار نقطة عشوائية على الطريق بين الخط الأساسي والمدخلات لتحديد التقدم للمنابع. ونتيجةً لذلك، تمثل القيم الشابلي النهائية قيمة التوقع للتقدم. * (المدخلات – الأساسيات). يتم تقريب القيم الشابلي بشرط أن ما يلي الميزانيات المدخلة مستقلة وأن النموذج التوضيحي خط لا مربع بين المدخلات والأساسيات الموجودة.
DeepLIFT
يمكن استخدام DeepLIFT (تقنية التدريج الخلفي) للتخصيص لتغيرات المدخلات وفقاً للاختلافات بين المدخلات وأساسها المرجعي (أو الجبر). يحاول DeepLIFT تفسير الاختلافات بين الخروج المرجعي باستخدام الاختلافات بين المدخلات المرجعية. DeepLIFT يستخدم فكرة المضاعفات للتحمل المسؤولية للخلايا العصبية المنفردة عن الاختلاف في الخروجات. للمدخل الخاص بالخلية x مع أختلافها من المرجع أي أختلاف أداة ∆x وللخلية الهدفية t مع أختلافها من المرجع أي أختلاف أداة ∆t الذي نريد حساب مساهمته يتم تعريف مضاعفة الاختلاف من أداة m∆x∆t بالتالي:
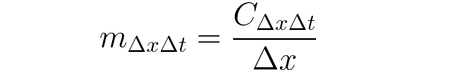
DeepLIFT SHAP
DeepLIFT SHAP هو توسعة لDeepLIFT تبني قيم الShapley الموجودة في نظرية الألعاب التعاونية. DeepLIFT SHAP يقوم بحساب الاختلافات DeepLIFT لكل مزيد من أزواج المدخل-الأساس ويمتص النتائج المحسوبة لكل مثال من المدخلات باستخدام توزيع من الأساسات. قواعد DeepLIFT الغير خطية تساعد في تحسين قواعد الشبكة الغير خطية، وتقريبية قيم الSHAP أيضًا تستطيع تطبيقها على الشبكة المُخطِطة. يتخيل أيضًا أن تتوافر الميزات المدخلة بشكل مستقل في هذه الطريقة.
البروز
الحساب بواسطة البروز هو عملية بسيطة تنتج مستويات التقدم البعدي للخروج بالنسبة للدخول. يستخدم توسعة أول أوردر للدخول وتلك المستويات هي معدلات الخصائص في تمثيل النظام الخط الواحد. تخطيط قيمة هذه المعدلات يمكن استخدامه للشهادة عن مناسبة تلك الخصائص. يمكنك إيجاد معلومات إضافية عن مقاربة البروز في ال الوثيقة الأصلية.
تقدم المعلومات X المستويات
المتوسط البتائي للمعلومات هو توسعة لمقاربة البروميدادية، حيث يتم تخزين المسافات للمخرج بالنسبة للمدخل ومضاعفتها بمعدلات الخصائص الأولية المدخلة. إحدى المفاهيم لهذه الطريقة تنظر إلى نموذج خطي ؛ تلك المسافات هي ببساطة معدلات كل مدخل، ومضاعفة المدخل بمعدل يمكن أن يمثل المساهمة الكلية للخصائص في مخرج النموذج الخطي.
التوجيه الخلفي المتوجه والتكامل
تم قم بحساب المسافات عن طريق التوجيه الخلفي المتوجه و التكامل، على الرغم من أن توجيه العملية الخلفية لوظائف ReLU يتم تغييره بحيث يتم توجيه المسافات السلسلية فقط. بينما يتم تطبيق ما يلي المعلومات في التوجيه الخلفي المتوجه، يتم تطبيقه مباشرة على المسافات الخارجية في التكامل. وهو من الممارسات الشائعة أن يستخدم هذه الطرق مع شبكات التكنولوجيا التصادعية، ولكنها يمكن أيضًا استخدامها في أنماط أخرى لهيكلات الشبكات العصبية.
التعقيد الموجه للGradCAM
يقوم حساب التعقيدات بحساب ما يلي من المصادر مع تكبير التعقيدات الموجهة للGradCAM (التعقيد الموجه للGradCAM) مع تكبير التعقيدات (للطبقة) الإضافية. يقوم هذا الحساب بالتعقيدات للطبقة المعطية ويتم تكبيرها لتتوافق مع حجم المعلومات الإدخالية. تركيز الشبكات العبارية هو مفتاح هذه التقنية. ومع ذلك ، يمكن تقديم أي طبقة يمكن توافقها في المساحة الحجمي مع المعلومات الإدخالية. عامًاً، يتم تقديم الطبقة المُعْرِكَة الأخيرة.
تعقيد الميزات
لحساب التعقيدات، تستخدم تقنية تعرف بـ “تعقيد الميزات” تستخدم طريقة تلوث-based التي تبدل كل ميزة معلومة “الأساس” أو “قيمة المرجع” (مثل 0) قبل حساب اختلاف الخاتم. تجميع وتعقيد الميزات المعلومة هو خيار أفضل للقيام به من فعلها بشكل فردي، ويمكن أن تساعد عدة تطبيقات مختلفة على هذا. من خلال تجميع وتعقيد الأجزاء في الصورة، يمكننا تحديد أهمية الجزء المحدد.
تشكيل الميزات
تشكيل الميزات هو طريقة تعريف على التشويش حيث يتم تشكيل كل ميزة بشكل عشوائي داخل مجموعة، ويحسب التغير في المخرج (أو الخسارة) كنتيجة لهذا التغيير. يمكن أيضًا تجميع الميزات في مجموعات بدلاً من التجميع الفردي بنفس الطريقة التي يتم بها تخفيض الميزات. تلاحظ أنه بخلاف الخوارزميات الأخرى المتوفرة في Captum، هذه الخوارزمية تكون الوحيدة التي قد توفر توحيدات صحيحة عندما يتم تقديمها مع مجموعة من أمثلة متعددة للإدخال. الخوارزميات الأخرى تحتاج فقط لمثال واحد كمعين.
إخفاء
إخفاء هو طريقة حساب التوحيد تعتمد على التشويش، حيث يحلل كل منطقة تربعية متتالية بالأساسيات/المرجع ويحسب الفرار من ذلك. للميزات الموجودة في مناطق متعددة (الأحيرة المتعددة), يمكن تقرياء الفرارات المتعددة لحساب التوحيد لهذه الميزة. يمكن أن يكون الإخفاء أكثر سيءًا في حالات مثل الصور، حيث يتم الاعتماد على أن تلك البكسور في مناطق تربعية متتالية مترابطة بشكل كبير.
عملية تعريف القيمة الشابلية
تقنية القيمة الشابلية تستند على نظرية الألعاب التعاونية. تقوم هذه التقنية بكل ترتيب لما يلي الميزانيات الإدخالية وتضيف كل ميزانية بمجرد إضافتها إلى خط مبني. يمكن التعرف على ما يحدده التفاوت بعد إضافة كل ميزانية وتجمع هذه التفاوتات عبر جميع الترتيبات للتعرف على الاعتماد.
Lime
أحد أكثر الأساليب الفهمية استخدامًا هو Lime, الذي يدرب نموذجًا مفهومًا من خلال تنقل النقاط البياناتية حول مثال إدخالي واستخدام تقديرات النموذج في هذه النقاط لتدريب نموذج أبسط وفهمي يمكن أن يكون مثل النموذج الخطي، مثل النموذج الخطي السياسي.
KernelSHAP
الجوانب الشابلي للنواة هي تقنية لحساب قيم الشابلي تستخدم الإطار اللامع للبرمجيات (LIME). قد تحصل على قيم الشابلي بكفاءة أفضل في الإطار LIME بتحديد المعاملة الخاطئة، ووزن الناقط اللامع، وتنظيم جيد للأوامر التنظيمية.
تقنيات تخصيص الطبقات
السلوكية الطبقية
تقنية السلوكية الطبقية هي طريقة تقوم بتكوين صورة شاملة أكثر لأهمية الخلية العصبية بالتركيب بين تنشيط الخلية والمائة الجانبية لكل من الخلية بالنسبة للإدخال والناتج بالنسبة للخلية. من خلال الخلية المخفية، يقوم السلوكية بتكسير جيد على تسلسل التخصيص للتكامل الموحد (IG). يعرف السلوكية الكاملة للخلية المخفية y بالتالي في الوثيقة الأصلية:
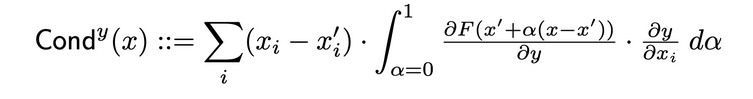
التأثير الداخلي
باستخدام التأثير الداخلي, يمكن تقدير جملة المستويات Along the path from a baseline input to the provided input. تقنية هذه مماثلة للتطبيق للجملات المكونة وهي تتضمن تكامل المستويات مع الطبقة (بدلاً من المدخل).
مستويات الجملة X التفعيل
مستويات الجملة X التفعيل هي معادل لتقنية Input X Gradient للمدارك المخفي في الشبكة…
هي تضاعف تفعيل العنصر في الطبقة مع المستويات للمادة المرشحة بالنسبة للطبقة المعنية.
GradCAM
GradCAM هي تقنية تخصيص الطبقة العصبية الكمبولية التي تتم تطبيقها عامةً على الطبقة الكمبولية الأخيرة. GradCAM تحسب المستويات المتعلقة بالمادة المرشحة مع الطبقة المحددة، تمتد كل قناة الخروج (متغير الخروج الثاني)، وتضاعف معدل المستويات المتوسطة لكل قناة بتفعيل الطبقة. يتم تطبيق ReLU على الخروج لضمان أن يتم إرجاع التخصيصات اللاسنغيلية فقط من جملة النتائج عبر جميع القناوين.
تقنيات تخصيص الخلايا العصبية
المقدار العصبي
المقدار يتحدث عن تركيبة تنشيط الخلية مع جزئيات جاهزة لكل من الخلية بالنسبة للإدخال والخلية بالنسبة للخروج لتوفير صورة شاملة أكثر للتركيبة المهمة للخلية. لتحديد المقدار العصبي لخلية معينة، يتوجب فحص تدفق IG التخصيص من كل إدخال يمر من خلال تلك الخلية. يلي التعريف الرسمي لمقدار العصبي لخلية y مع تخصيص الإدخال i التالي:
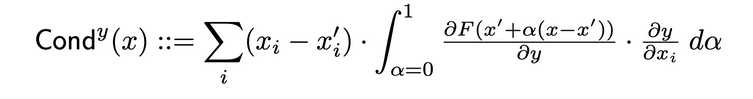
وفقاً لهذا التعريف، يتوجب علينا أن نلاحظ أن تضاعف المقدار العصبي للخلية (عبر جميع الميزات الإدخالية) دائمًا يساوي مقدار العصبي للطبقة التي توجد فيها تلك الخلية الخاصة.
المسافر العصبي
تقنية المسار العصبي هي متوازنة لطريقة البروز الواضح للخلية الواحدة في الشبكة.
إنها تقوم بحساب المسار لنتاج الخلية بالنسبة للإدخال المحدد.
هذه الطريقة، مثل بروز الواحدة، قد تبدو وكأنها تقوم بتوسعة أولية أول نوع لنتاج الخلية في الإدخال المحدد، حيث تتماشى مع معاملات جميع الأصول في تمثيلها الخط اللاخطي للنظام.
المسارات المتكاملة للخلية
يمكن القيام بتقدير المعاملات البناءة للمسارات الإدخالية بالنسبة للخلية المعينة خلال مسار من الإدخال الأساسي إلى الإدخال المهم باستخدام تقنية تدعى “المسارات المتكاملة للخلية.” المعاملات التكاملية متوازنة بهذه الطريقة، بافتراض أن نتاجها مجرد نتاج الخلية المحددة. يمكن الحصول على معلومات إضافية عن مقاربة المسارات المتكاملة في المادة الأصلية هنا.
المسارات العصبية لشيء
تعاونية تقنية الشبكية العصبية هي ما يمكن أن يكون مساوي لتقنية GradientSHAP للخلية العصبية المحددة. تضيف تعاونية تقنية الشبكية العصبية ضجيج جواسيبي إلى كل عينة المدخل مرات عديدة، ويختار نقطة عشوائية على طول المسار بين الأساس والمدخل، ويحاسب مساواة الخلية المحددة بالنسبة لكل نقطة مختارة عشوائيا. يمكن أن تكون قيم الSHAP الناجمة قريبة من قيم التقنية التنبؤية المتوسطة *. (المدخلات – الأساس).
تعاونية تقنية DeepLIFT SHAP
تعاونية تقنية DeepLIFT SHAP مماثلة لتقنية DeepLIFT للخلية المحددة. باستخدام توزيع الأساس، تقنية DeepLIFT SHAP تحاسب تعاونية تقنية DeepLIFT لكل زوج من المدخل والأساس وتمت المتوسط لتعاونيات الناجمة لكل مثال من المدخلات.
النهاية المنهارة
النهاية المنهارة هي تقنية للتوصيل يمكن استخدامها بالتزامن مع أساليب أخرى. تحاسب النهاية المنهارة مرات عديدة، بإضافة ضجيج جواسيبي إلى المدخل في كل مرة، ومن ثم يتم انصهار التعاونيات الناجمة بناءاً على النوع المختار. تم دعم أنواع النهاية المنهارة التالية:
- Smoothgrad: يتم إرجاع معدل التعيينات المماثلة. يتم تساؤل التقنية المحددة للتعيينات باستخدام قشرة غالبية تعابيري كمتابعة لهذه العملية.
- Smoothgrad Squared: يتم إرجاع معدل التعيينات المماثلة المضاعفة.
- Vargrad: يتم إرجاع تنوع تعيينات العينة.
مؤشرات
غيرة
غيرة تقييم الخطأ المضاعف المتوسط بين توضيحات النماذج في حجمية تغيرات المدخلات وتغيرات معالجة التنبؤ بهذه المدخلات. يتم تعريف غيرة كما يلي:
من تقنيات التعيين الشهيرة مثل التواصل المتكامل هذه هي مفهوم ذي فعالية أكثر وتوسع لـ Sensitivy-n. الأخر يقوم بتحليل الترابطات بين مجموع تعيينات المدخلات والفرواريف معالجة التنبؤ فيها وخلف هذه المدخلات وخلف خط الاساس.
الحساسية
الحساسية, التي يعرف بدرجة تغير التفسير بسبب تغيرات صغيرة في الإدخال من خلال تقريب بناء على المونتيكال ذات التقنية المتنوعة، تقييم بالتالي:

بشكل افتراضي، نقوم بعمل عيّب من مجال داخل كرة من المجال L-Infinity بقطر افتراضي لتقريب الحساسية. يمكن للمستخدمين تغيير قطر كرة المجال وما يتعلق بالمجموعة التي يتم من خلالها العيّب.
تفسير النماذج لنموذج ResNet مسبق التدريب
يوضح هذا الدرس الطريقة لاستخدام طرق التفسير النماذجية على نموذج ResNet مسبق التدريب مع صورة من الصور مختارة، ويتم تمييز الصفات لكل بكسل من خلال تضاعفها فوق الصورة. في هذا الدرس، سنستخدم خوارزميات التفسير المدمجة، GradientShape، Attribution with Layer GradCAM وOcclusion.
قبل البدء، يجب أن يكون لديك بيئة برمجية بالبتون تشمل:
- إصدار بتون 3.6 أو أعلى
- إصدار PyTorch 1.2 أو أعلى (يونجود إصدار جديد يوصل)
- إصدار TorchVision 0
- .6 أو أعلى (يونجود إصدار جديد يوصل)
- Captum (يونجود إصدار جديد يوصل)
وفقًا إذا كنت تستخدم Anaconda أو pip للبيئة الافتراضية، سيساعدك الأوامر التالية في إعداد Captum:
بواسطة conda:
conda install pytorch torchvision captum -c pytorch
مع pip:
pip install torch torchvision captum
دعونا نصب المكونات.
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
يحمل النموذج Resnet المتميز ويضعه في وضع التقديم.
model = models.resnet18(pretrained=True)
model = model.eval()
تم تدريب ResNet على مجموعة البيانات ImageNet. ويتم 下载 وقراءة قائمة ImageNet للصناديق/التسميات في الذاكرة.
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
بعد أن ننتهي من بناء النموذج، يمكننا تحميل الصورة التي سنقوم بتحليلها.
في حالتي، اخترت صورة للقط.

يتوجب أن يحتوي المجلد الصور الملف cat.jpg. كما يمكن المشاهدة أسفل، Image.open() يفتح ويتعرف على الملف الصوري المعطا وnp.asarray() يحوله إلى مجموعة.
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
في الشيء التالي سنحدد محركات تحويل و函数 لتعميم الصورة. لتدريب نموذج ResNet لدينا، استخدمنا مجموعة ImageNet، وهذا يتطلب أن يكون الصور من حجم معين، ويتم تنظيف بيانات القنال إلى نطاق معين من القيم. transforms.Compose() يتكون مجموعة عدة تحويلات معا وtransforms.Normalize() يتم تنظيف صورة التونسور بواسطة المعدلات والمعادلات.
# توقعات النموذج هي 224x224 صورة ثلاثة ألوان
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# تنظيم ImageNet
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
#unsqueeze يعود بتوانم جديد بعديد صغير بنموذج التنظيم المحدد.
input = input.unsqueeze(0)
الآن، سنقوم بتخمين الفئة للصورة المدرجة. السؤال الذي يمكن التساءل عنه هو “ما الذي تعتقد نموذجنا أن هذه الصورة تمثل ؟”
# مكالمة نموذجنا
output = model(input)
## تطبيق ما يلي softmax() الوظيفة
output = F.softmax(output, dim=1)
#torch.topk يعود بأكبر K عناصر في المصفوفة المعطاة على الاتجاه المحدد. هناك 1 من أعلى
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
# تحويل إلى قاموس من الأيادي المرتبط بالتنبيه المتوقع، ثم تحويله #إلى سطر للحصول على التنبيه المتوقع
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
خريطة الخارج:
Predicted: tabby ( 0.5530276298522949 )
يتم تحقيق أن ريسنت تظن صورة القطة التي نملكها تمثل قطة حقيقية. لكن ما الذي يعطي هذا النموذج للنظرة أن هذه صورة للقطة ؟ للحصول على إجابة هذا السؤال، سنقوم بالتواصل مع Captum.
تعيين الخصائص مع التكامل المتكامل
إحدى أشكال تعيين الخصائص العديدة في Captum هي التكامل المتكامل. يعلم Integrated Gradients أي خصائص الإدخال تمتلك درجة تعامل من خلال تقدير حساب التقاءات من تمام تلاشي التباينات لنموذج المنصة مقارنة بالإدخال.
في حالتنا سنأخذ عنصر معين من ال vectore الناتج – هذا الذي يعني ثقة النموذج في تختيارها للفئة – وسنستخدم تكامل التدرجات لمعرفت ما هي أجزاء الصورة المدرجة التي ساهمت في هذا النتيجة. سيسمح لنا بذلك بتحديد أجزاء الصورة التي كانت أهمية في إنشاء هذه النتيجة.
بعد أن حصلنا على خريطة الأهمية من تكامل التدرجات، سنستخدم أدوات التصور التي تم اختزالها من Captum لتوفير تصور واضح وقابل للفهم لخريطة الأهمية.
ستحدد Integrated gradients إجمالي تدرجات نتيجة النموذج للفئة المتوقعة pred_label_idx بالنسبة للبكسور المدرجة للصورة من خلال المسار من الصورة السوداء إلى صورة المدرجة.
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
# إنشاء جهة IntegratedGradients وحصول على خصائص
integrated_gradients = IntegratedGradients(model)
# طلب تخصيص الخوارزمية لتعيين هدفنا للناتج
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
الناتج:
Predicted: tabby ( 0.5530276298522949 )
دعونا نرى الصورة والتعبيرات التي تتم إلتقاءها معها عن طريق وضع التعبيرات فوق الصورة الأصلية. توفير الvisualize_image_attr() وسيلة التصور التي يقدمها Captum توفير مجموعة من الإمكانيات لتخصيص توظيف بيانات التعبيرات وطلبك. هنا، نقدم مجموعة تعبيرات مخصصة لـ Matplotlib (رؤية LinearSegmentedColormap()).
#تخيل النتائج بواسطة خط لون شخصي
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
# استخدم وصفة المساعدة للتصور التي تظهر الصورة الأصلية للمقارنة
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
الخريطة الخاصة:
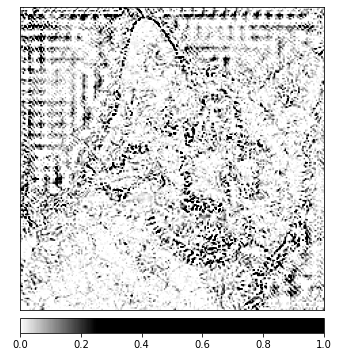
يمكنك أن تلاحظ في الصورة التي أظهرناها أعلاه أن منطقة القطة في الصورة هي حيث يعطينا الخوارزمية المتكاملة أقوى الإشارة.
دعونا نحسب الملاحظات باستخدام الخوارزمية المتكاملة ومن ثم ننسيطها عبر عدد من الصور التي تم إنتاجها من خلال تونيلر التشويش.
يغير الأداة التي تحدث التشويش للإدخال بالضبط باستعمال التشويش الغازي بمعدل 1 ، 10 مرات (nt_samples=10). تستخدم مقاربة smoothgrad_sq من تونيلر التشويش لجعل الملاحظات متوازية عبر جميع جميع nt_samples العينات الشوية. قيمة smoothgrad_sq هي معدل الملاحظات المضربة عبر nt_samples عينات.
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
الخريطة الخاصة:

يمكنني أن ألاحظ في الصور أعلاه أن النموذج يركز على رأس القطة.
ننتهي باستخدام GradientShap. GradientShap هو منهج للتصاعد الذي قد يستخدم لحساب قيم SHAP وهو أيضًا أداة رائعة للحصول على بينات عن السلوك العام. إنه نموذج توضيح خطي يشرح تخمينات النموذج باستخدام توزيع لعبة مرجعين. يحدد التقارير المتوقعة لمدخل يختار عشوائيًا بين المدخل والمبنى الأساسي.
يختار المبنى الأساسي عشوائيًا من توزيع المبنيات الأساسية المعطى.
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# تعريف توزيع المبنيات الأساسية للصور
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
خريطة:

توزيع تفاعل الطبقات مع Layer GradCAM
يمكنك ربط نشاط الطبقات الخفية داخل نموذجك بواحدات معلومات المعلومات المدخلة بمساعدة تخصيص الطبقات.
سنطبق خوارزمية لتخصيص الطبقات لاستكشاف نشاط واحد من طبقات الكونوشال يشمل نموذجنا.
GradCAM مسؤول عن حساب المسافات من ما يتعلق بالمخرج المحدد بالنسبة للطبقة المعينة. يتم تقرياء هذه المسافات لكل قناة المخرج (الأبعاد الثانية للمخرج), ويتم تكامل التنشيطات الطبقية بما يفوق المسافة التقرياء لكل قناة.
يتم حول النتائج عبر جميع القنات. ومن ثم يمكنك أن تضيف وتضخم تلك التخصيصات وتستخدمها لتغطية المعلومات المدخلة. يستخدم تلك التخصيصات لكشف الطبقات الكونوشالية من التصرفات المتعلقة بالأشعة البدنية. يتم إعداد تخصيص الطبقات بنفس الطريقة التي يتم إعداد تخصيص المعلومات المدخلة، ما عدا أن عليك أن توفر طبقة خفية داخل النموذج التي تريد تحليلها. ومماثلًا لما تحدثنا عنه من قبل، عندما نطلق على attribute()، نشير إلى الفئة المهمة للموضوع.
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
لجعل المقارنة أكثر دقة بين الصورة المدخلة وهذه البيانات التخصيصية، سنضخمها بمساعدة وظيفة interpolate() الموجودة في النوع الأساسي LayerAttribution.
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
المخرج:
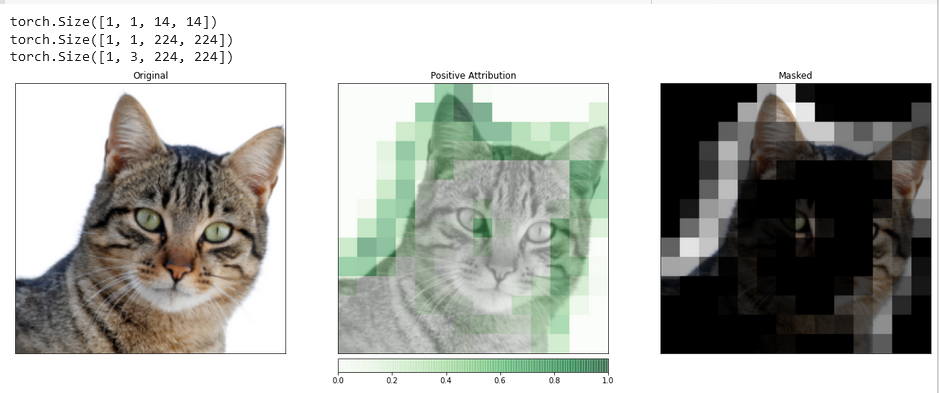
التصورات المثل هذه قد توفر عليك معلومات فريدة عن كيفية تفاعل طبقاتك الخفية مع المعلومات المدخلة.
تخصيص خاصية مع تشويش
الأساليب التي تستند على المادة الدرجية تساعد في فهم النموذج من خلال حساب التغيرات في الخريطة المختلفة مع المعلومات المدخلة.
تقنية التخصيص المبنية على التشويش المفاجئ تأخذ مساراً مباشر لهذه المشكلة بتغيير المعلومات المدخلة لتقييم التأثير هذه التغيرات على الخريطة الخارجية. واحد من هذه الاستراتيجيات يطلق عليها التشويش.
تتضمن تبديل أجزاء الصورة المدخلة وتحليل كيف يؤثر هذا التغيير على الإشارة التي ينتج عنها الخريطة الخارجية.
في المقالة التالية سنقوم ب配置 التخصيص المبني على التشويش. مثل تكوين الشبكة العصبية التصاعدية، يمكنك اختيار حجم المنطقة المحددة وعرض القطاع، ويحدد القطاع الذي يحدد تمامًا مسافة قياسات التغيير البسيط.
سنستخدم ما يطلق عليه visualize_image_attr_multiple() لمشاهدة نتائج تخصيصنا المبني على التشويش. ستظهر هذه الوظيفة خرائط الحرارة للتخصيص الإيجابي والسلبي لكل منطقة وتغطية الصورة الأصلية بمناطق التخصيص الإيجابي.
تغطية الصورة توفر نظرة مضيءة جداً على المناطق التي يعترف بها النموذج بأنها الأكثر “تشبيهًا للقطة”.
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
الخريطة الخارجية:
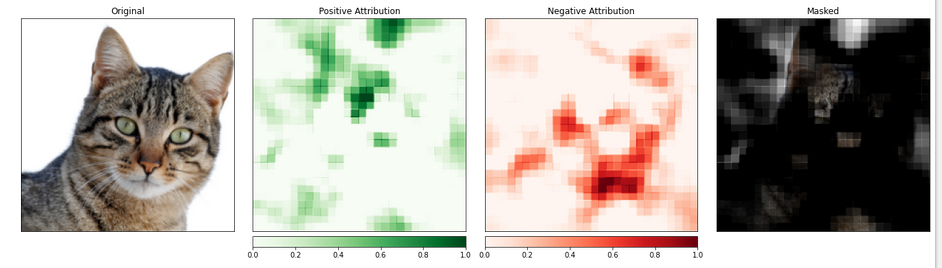
الجزء الذي يحتوي على القطة يبدو أنه يحصل على مستوى أولوية أعلى.
الخلاصة
Captum هو مكتبة للتفسير القابل للتجاوز لبيتورش وهي متنوعة وسهلة الاستخدام. وهي توفر تقنيات عالية المعرفة لفهم كيفية تأثير الخلايا العصبية والطبقات على التخمينات.
وتتضمن ثلاث أنواع رئيسية من التسلسل المساهمة: تقنيات التسلسل الأولية، وتقنيات التسلسل الخاصة بالطبقات، وتقنيات التسلسل الخاصة بالخلايا العصبية.
المراجعات
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf