













紹介
近年、モデルの複雑度の増加と透明性の欠如との直接の結果として、モデルの可視性の方法は重要性が増しています。モデル理解は、 Machine learningを应用しているさまざまな分野において、研究の热点と実用の中心地となっています。
Captumは、統合ゲートレートなどの最先端の技術を提供し、モデルの出力に貢献している要素を簡単に特定することができます。Captumは、ML研究者がPyTorchモデルを使用して、可視性方法を構築することを簡素化することができます。
モデルの出力に貢献している多くの要素を簡単に特定することができるため、Captumはモデル開発者がより良いモデルを作成し、予期しない結果を提供するモデルを修正することを助けることができます。
アルゴリズムの説明
Captumは、さまざまな可視性手法の実装を許可するライブラリです。Captumの属性アルゴリズムを3つの大分类に分類することができます。
- 主な属性: 各入力特徴がモデルの出力に対する貢献を決定します。
- 層の属性: 特定の層のすべてのニューロンは、モデルの出力に対する貢献度を評価されます。
- ニューロンの属性: 隠れ層のニューロンの活性化は、各入力特徴の貢献度を評価して決まります。
以下は、Captumにおいて現在実装されている主要な層やニューロンの属性の手法の簡単な概要です。そして、任意の属性手法の結果を滑らかにするために使用できるノイズチューナルについても説明します。
Captumは、属性アルゴリズムに加えて、モデル説明の信頼性を評価する指標を提供しています。現在、不正確さと敏感度の指標を提供しています。これらは説明の正確性を評価するために使用します。
主要な属性技術
統合勾配
深層网络の正式な表現をF: Rn → [0, 1]とします。現在の入力としてx ∈ Rn、基準入力としてx′ ∈ Rnがあります。画像网络の基準は黒色の画像かもしれませんが、テキストモデルでは零の嵌入ベクトルかもしれません。基準x′から入力xまでの直線的なパス上のすべての点で勾配を計算し、これらの勾配を積み重ねることで、積分勾配を生成することができます。積分勾配は、基準x′から入力xへの直接パス上の勾配のパス積分として定義されています。
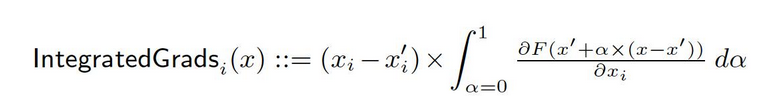
この方法の基盤を構成する2つの基本的前提、敏感度と実装的不変性があります。これらの公理についてもっと学ぶには原始論文をご参照ください。
勾配SHAP
Shapley値は協力ゲーム理論において使用され、GRADIENT SHAP値の計算には gradient approachを用います。GRADIENT SHAPは各入力サンプルに多次にGaussノイズを加え、その後基準値と入力の間のルートをランダムに選び、出力の梯度を決定します。結果的に、最終的なSHAP値は梯度の期待値を表します。*(入力 – 基準値)。SHAP値は、入力特徴が独立しており、説明モデルが入力と提供される基準値の間で線形であると前提として近似されます。
DeepLIFT
DeepLIFT(バックプロパション技術)を使用することで、入力とそれに対応する参照(または基準)の間の差分に基づいて入力変更を割り当てることが可能です。DeepLIFTは、参照からの入力と出力の間の不一致を説明しようとする技術であり、参照の入力と出力の間の不一致を使用して、参照の出力との間の不一致を説明しようとする。DeepLIFTは、
DeepLIFT SHAP
DeepLIFT SHAPと呼ばれるShapley値に基づくCooperativeゲーム理論の Extensionであり、DeepLIFTの属性を計算します。DeepLIFT SHAPは、各入力基準ペアに対するDeepLIFT属性を計算し、基準の分布を使用して結果を平均します。DeepLIFTの非線形性のルールは、ネットワークの非線形関数を線形化することを助けます。この方法のShapley値の近似も線形化されたネットワークに適用できます。この方法では、入力特徴が独立していると的前提されます。
特徴量
入力の影響度を特徴量を通じて計算することは、入力に対する出力の勾配を得る簡単なプロセスです。入力で一阶泰勒展开が行われ、勾配はモデルの線形表現における各特徴量の係数である。これらの係数の絶対値は、特徴量の関連性を示すことができます。原稿を参照して、特徴量の方法に関する詳細な情報を見つけることができます。
入力X勾配
入力X梯度は、salience手法の拡張です。入力に対する出力の梯度を取り出し、入力特徴量の値に乘じます。この手法の一つの直感は、線形モデルについて考えることです。梯度は各入力の係数として簡単に考えられ、入力と係数の積は、線形モデルの出力に対する特徴の総貢献を表します。
指導的バックプロパゲーションと解像度下降
指導的バックプロパゲーションおよび解像度下降を通じて梯度計算を行います。しかし、ReLU関数のバックプロパゲーションは、非負の梯度だけを伝播するように上書きされます。指導的バックプロパゲーションでは入力梯度にReLU関数を適用し、解像度下降では直接出力梯度に適用します。これらの手法を畳み込みネットワークと一緒に使用することが一般的ですが、他の種類のニューラルネットワーク構築も可能です。
ガイドド里的GradCAM
ガイドド里的GradCAM属性(ガイドド里的GradCAM)とアップサンプリングされた(層)GradCAM属性の要素ごとの積を計算するガイドド里的バックプロパゲーション属性計算。与えられた層に基づいて属性計算を行い、入力サイズに适応させるためにアップサンプリングする。この技術の対象は畳み込み人工知能ネットワークである。しかし、入力とスペース上で一致することができるどの層も提供できる。一般的には最後の畳み込み層が提供される。
特徴破壊
属性計算において、「特徴破壊」と呼ばれる技術は、出力の差分計算前に各入力特徴に既知の「基準線」または「参照値」(例えば0)を置き換える変異基準法を用いている。入力特徴を個別に破壊するよりも、入力特徴をグループ化して破壊することはより良い代替手段であり、多くの異なる應用にこれを有益に利用できる。画像のセグメントをグループ化して破壊することで、セグメントの相対的な重要性を決定することができる。
特性置换
特性置换は、置换を行うことで特徴量に影響を与える手法であり、これはbatch内の各特徴量に乱択的に置换を施すことで、出力(または損失)の変化を計算する手法です。特徴量は、特徴除去と同様に個別になく、グループ化されることもできます。Captumにある他のアルゴリズムと比較して、このアルゴリズムは、複数の入力例のbatchを与えられる場合にだけ、適切な属性を提供することができる唯一のアルゴリズムです。他のアルゴリズムは、入力として単一の例だけが必要です。
遮蔽
遮蔽は、属性計算に使用される変換基準の手法であり、各連続的な矩形領域を与えられた基準/参照に置き換え、出力の差分を計算します。複数の領域(超矩形)に位置する特徴量に対して、対応する出力差分を平均して、その特徴量の属性を計算します。遮蔽は、画像のような、連続的な矩形領域内の画素が高く相关している場合に最も有用です。
Shapley Value Sampling
Shapley值とは、協力ゲーム理論に基づく属性技術です。この手法は、入力特徴の各順列を取り出し、一度に一つの特徴を指定した基準線に加える。各特徴を加えるたびに出力の変化はその特徴の貢献度に対応し、これらの変化の差が全ての順列において合計され、属性を決定する。
Lime
最も幅広く使用されている解釈性手法の一つは、Limeです。これは入力の例の周りのデータ点をサンプリングし、これらの点でモデルの評価を使用して、線形モデルなどのより簡潔な解釈可能な「代理」モデルを学習するために训练される解釈可能な代替モデルを学習します。
KernelSHAP
Kernel SHAPは、LIMEフレームワークを使用してShapley値を計算する技術です。損失関数を設定し、核関数を重み付けし、適切に正則化項を追加することで、LIMEフレームワークでShapley値をより効率よく得ることができます。
層の属性技術
層の導電性
層の導電性は、ニューロンの活性化をInputに対するニューロンの偏導数と、Outputに対するニューロンの偏導数とを結合して、ニューロンの重要性をより全面的に表す方法です。隠れ層のニューロンを通じて、導電性はIntegrated Gradients (IG)の属性流を拡張します。隐れ層のニューロンyの総導電性は、原创論文で以下のように定義されます。
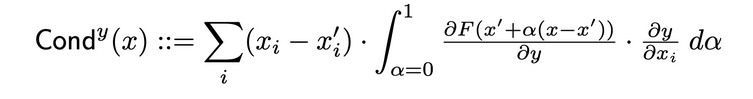
内部影響
内部影響を使用することで、基準入力から与えられた入力までのパス上の勾配の積分を計算することができます。この技術は、レイヤーに対する勾配の積分(入力に対する勾配ではない)を適用する integrated gradients と似ています。
レイヤー勾配Xアクティベーション
レイヤー勾配Xアクティベーションは、ネットワーク上の隠れ層用の入力X勾配技術のネットワーク対応です…
それは、レイヤーの各要素の活性化を目標出力に対する指定レイヤーの勾配と要素ごとに乘じます。
GradCAM
GradCAMは、最後の畳み込み層に通常適用される畳み込み Neural Network 層の属性技術です。GradCAMは、指定された層に対する目標出力の勾配を計算し、各出力チャンネル(出力次元2)を平均し、各チャンネルの平均勾配に層の活性化を乘じます。出力にReLUを適用し、結果のすべてのチャンネルの積算の結果に対してのみ非負の属性を返すようにします。
ニューロン属性技術
ニューロン導関数
導関数は、ニューロンの活性化と、入力に対するニューロンの偏微分と、出力に対する入力の偏微分を結合して、ニューロンの関連性をより全面的に表す。特定のニューロンの導関数を決定するためには、そのニューロンを通る各入力からのIG属性の流れを観察する必要がある。以下は、特定のニューロンyによる入力属性iの導関数的定義である:
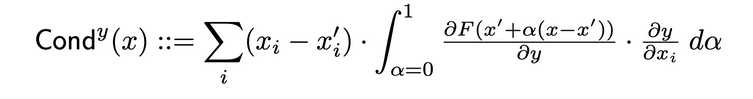
この定義により、ニューロンの導関数(すべての入力特徴において)の和が、その特定のニューロンを含む層の導関数と常に等しいことに注意するべきです。
ニューロン勾配
ニューロンのグラデーション手法は、ネットワーク内の1つのニューロンについての際立った性質の方法と同等です。
これは、モデルの入力に対するニューロンの出力の傾きを簡単に計算します。
この手法は、Saliencyと同様に、与えられた入力でのニューロンの出力を1次 Taylor 展开することと考えることができ、その傾きは、モデルの線形表現における各特徴の係数に対応します。
ニューロン整合勾配
「ニューロン整合勾配」と呼ばれる技術を使用して、基本入力から興味のある入力までの経路で、特定のニューロンへの入力勾配の積分を推定することができます。積分勾配は、出力が特定されたニューロンのみの出力であると仮定すると、この方法と同等です。ここには、整合勾配手法の詳細信息が原稿で提供されています。
ニューロンGradientSHAP
ニューロン・グラデーションSHAPは、特定のニューロンに適用されるGradientSHAPの対応するものです。ニューロン・グラデーションSHAPは、各入力サンプルに多次にガウスノイズを加え、基準と入力の間の路径上のランダムな点を選び、目標のニューロンに対してそれぞれ選ばれた点についての傾きを計算します。得られるSHAP値は、予測された傾き値*(入力 – 基準)に似ています。(inputs – baselines).
ニューロン・ディープライフトSHAP
ニューロン・ディープライフトSHAPは、特定のニューロンに適用されるディープライフトの対応するものです。基準の分布を使用して、ディープライフトSHAPアルゴリズムは各入力・基準のペアに対するニューロン・ディープライフト属性を計算し、各入力例に対する平均された結果の属性を計算します。
ノイズトゥーン
ノイズトゥーンは、他の方法と組み合わせられる属性技術です。ノイズトゥーンは、属性を計算し multiple times に回すことができ、各回に入力にガウスノイズを加え、選ばれたタイプに基づいて結果の属性を結合します。以下はサポートされるノイズトゥーンのタイプです:
- Smoothgrad:サンプリングされた属性の平均を返却します。指定された属性技術を高斯核を使用して滑らかにすることは、このプロセスの近似です。
- Smoothgrad Squared: サンプリングされた属性の平均の2乗を返却します。
- Vargrad: サンプリングされた属性の変异性数を返却します。
Metrics
Infidelity
Infidelityは、入力変更の量に対するモデルの説明と、予測機能がこれらの入力変更に対する変化を測るための係数の間の平均二乗誤差を測定します。Infidelityは以下のように定義されます。
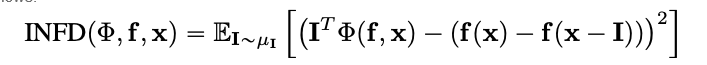
これは、統合的なゲインを使用するような既知の属性技術から、計算的にも効率が良く、Sensitivy-nの拡張概念です。後者は、属性の和と、予測機能がその入力と既定の基準に対する変化の差についての相関を分析します。
Sensitivity
敏感度は、Monte Carloサンプリング基づきの近似を用いて、微小な入力変化に対する説明変化の程度を定義する。敏感度の測定は以下のように行われます。

デフォルトでは、L-Infinity球のサブスペースからサンプリングを行い、敏感度を近似します。ユーザーは球的 radius とサンプリング関数を変更することができます。
Pretrained ResNet Model のモデル解釈
このチュートリアルは、選択された画像に対して、pretrained ResNet model にてモデル解釈方法を使用し、各画素の属性を画像上に重ねて可视化します。このチュートリアルでは、Integrated Gradients、GradientShape、Layer GradCAM と Occlusion の解釈アルゴリズムを使用します。
始める前に、以下のようなPython環境がある必要があります。
- Python 3.6 以降のバージョン
- PyTorch 1.2 以降のバージョン (最新版を推奨)
- TorchVision 0
- .6 以降のバージョン (最新版を推奨)
- Captum (最新版を推奨)
Anacondaまたはpip仮想環境を使用しているかによって、Captumを設定するための以下のコマンドを使用してください。
condaを使用して:
conda install pytorch torchvision captum -c pytorch
pip:
pip install torch torchvision captum
ライブラリを導入しましょう。
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
事前トレーニングされたResNetモデルを読み込み、評価モードに設定します。
model = models.resnet18(pretrained=True)
model = model.eval()
ResNetはImageNetデータセットでトレーニングされています。 memory_data_setにImageNetデータセットのクラス/ラベルリストをダウンロードして読み込みます。
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
モデルを完了したので、分析用に画像をダウンロードすることができます。私の場合、猫の画像を選びました。

猫.jpgを含む画像フォルダがあなたのフォルダには必要です。以下に示すように、Image.open()は与えられた画像ファイルを開き、识別し、np.asarry()はそれを配列に変換します。
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
以下のコードで、画像の変換器と正規化関数を定義します。私たちのResNetモデルをトレーニングするためには、ImageNetデータセットを使用する必要があり、画像は特定のサイズであり、チャネルデータは特定の範囲の値に正規化されなければなりません。transforms.Compose()はいくつかの変換を合成し、transforms.Normalize()は平均と標準偏差を使用してテンsor画像を正規化します。
# モデルの期待値は224x224の3色画像です
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# ImageNet正規化
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
# unsqueezeは指定位置に1次元の新しいテンソルを返します。
input = input.unsqueeze(0)
今、入力画像のクラスを予測します。問題として、「私のモデルはこの画像をどのように認識しているのか?」と尋ねることができます。
# モデルを呼び出します
output = model(input)
## softmax()関数を適用します
output = F.softmax(output, dim=1)
# torch.topkは与えられた入力テンソルの特定の次元に沿ってKの最大の要素を返します。ここでのKは1です。
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
# 予測ラベルの辞書形式に変換し、文字列に変換して予測ラベルを取得します
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
出力:
Predicted: tabby ( 0.5530276298522949 )
ResNetが我々の猫の画像を実際の猫と認識していることが確認されました。しかし、これが猫の画像であるという印象をモデルに与えたのは何か?この問題の解決策を得るために、Captumを参照します。
統合グラデーションを使用した特徴属性
Captumの様々な特徴属性技術の1つに统合グラデーションがあります。統合グラデーションは、モデルの出力の勾配の積分を入力に対して計算して、各入力特徴に対する関連度スコアを割り当てます。
私たちの場合、出力ベクトルの特定のコンポーネントを取り出すことにします。それは、モデルが選択したカテゴリーに対する信頼度を示しています。統合勾配法を使用して、この出力に貢献した入力画像のどの特徴があったかを調査します。これにより、この結果を生成した際に最も重要だった画像のどの部分かを決定することができます。
統合勾配法から取得した重要度マップを、Captumによって捉えた可视化ツールを使用して、明確で理解可能な形で表示します。
统合勾配法は、モデルの予測クラスpred_label_idxの出力の勾配の積分を決定します。それは、黒色画像から入力画像に向かう経路に沿って、入力画像の画素に対するものです。
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
# 統合勾配法のオブジェクトを作成し、属性を取得する
integrated_gradients = IntegratedGradients(model)
# アルゴリズムに対して、私たちの出力目标を割り当ててください
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
出力:
Predicted: tabby ( 0.5530276298522949 )
画像とそれに伴う属性を見てみましょう。属性データを画像に重ねて表示します。Captumが提供するvisualize_image_attr()メソッドは、属性データの表示を好みに合わせて調整する可能性のセットを提供します。ここで、自定制のMatplotlibの色変換マップ(見LinearSegmentedColormap())を渡します。
#結果の可视化にカスタムカラーマップを使用して
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
#比較のために元の画像を表示するためにvisualize_image_attrヘルパーメソッドを使用して
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
出力:
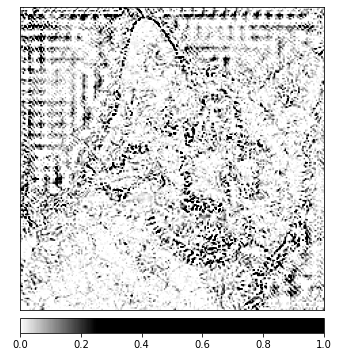
上で表示した画像において、综合力算法が最も強い信号を与えている猫の周辺領域があることに注意してください。
综合力算法を使用して属性を計算し、その後ノイズトンネルによって生成されたいくつかの画像に基づいてそれらを滑らかにします。後者は入力にガussianノイズを加え、標準偏差が1であり、10回(nt_samples=10)にわたって追加します。smoothgrad_sq手法は、ノイズトンネルによって属性が滑らかになっていることを保証するために使用されます。smoothgrad_sqの値はnt_samplesのノイズサンプル上の属性の平均の二乗値です。visualize_image_attr_multiple()は、指定されたサインの属性値(正の、負の、絶対値、またはすべて)を正規化し、選択されたモードでmatplotlib図で表示します。
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
出力:

上の画像を見ると、モデルは猫の頭に集中していることがわかります。
GradientShapを使用して終了しましょう。GradientShapは、SHAP値の計算に使用できる勾配法として、全局の行動についての洞察を得るのに優れたツールです。これは、参照サンプルの分布を使用してモデルの予測について説明する線形の説明モデルです。任意の入力に対する予測の期待される勾配を決定するために、入力と基準にあたる間の任意のRandomly picked入力に基づいています。基準は、提供された基準の分布からRandomly pickedしたものです。
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
#画像の基準分布の定義
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
出力:

Lay鸺鹠鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩鹩
あなたのモデル内の隠れ層の活動を入力の特徴と関連付けるには、レイヤー・アトリビューションの助けを借りることができます。
私たちは、モデルに含まれる畳み込み層の1つを調査するために、レイヤー・アトリビューションのアルゴリズムを適用します。
GradCAMは、指定されたレイヤーに対するターゲット出力の勾配を計算する役割を果たします。これらの勾配は、各出力チャンネル(出力の次元2)ごとに平均化され、レイヤーの活性化は各チャンネルごとの平均勾配に乗算されます。
結果はすべてのチャンネルにわたって合計されます。畳み込み層の活性は、空間的に入力にマッピングされることが多いため、GradCAMアトリビューションは頻繁にアップサンプリングされ、入力にマスクされます。GradCAMは、明示的に畳み込みニューラルネットワーク(convnets)用に開発されたことに注意してください。レイヤー・アトリビューションは、入力・アトリビューションと同様の方法で設定されますが、モデルに加えて、分析したいモデル内の隠れ層を指定する必要があります。前回と同様に、attribute()を呼び出すと、関心のあるターゲット・クラスを示します。
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
入力画像とこのアトリビューションデータをより正確に比較するために、interpolate()関数を使用してアップサンプリングします。この関数は、LayerAttributionベースクラスにあります。
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
出力:
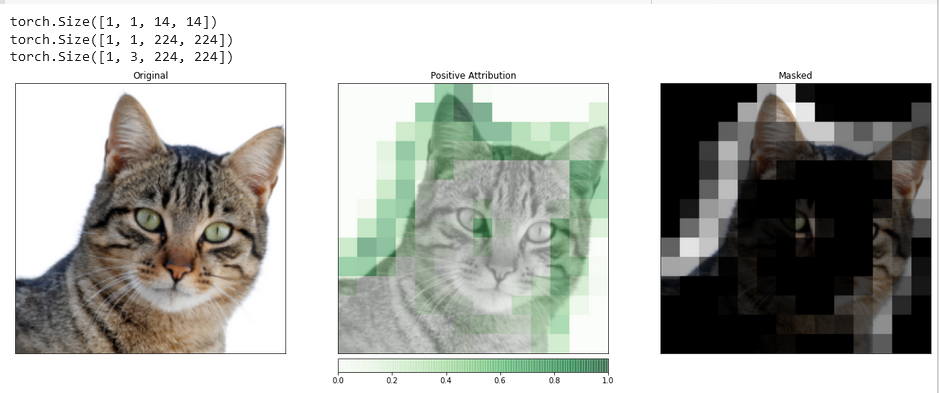
このような視覚化は、あなたの隠れ層が入力にどのように反応するかについて、独自の洞察を提供する可能性があります。
特徴属性と遮蔽
勾配に基づく方法は、出力に対する入力の変更に直接影響するのを計算することで、モデルを理解するために役立つ。変更による影響をquantifyするために、入力に変更を加えることによる直接的なアトリビューション技術は、この問題に取り組むためのより直接な手法を取る。その一つの戦略は遮蔽と呼ばれる。
これは、入力画像の一部を入れ替えて、この変更が出力上の信号に及ぼす影響を分析することである。
以下では、遮蔽アトリビューションを設定します。畳み込み神经망の設定と同様に、目標領域のサイズとストライド長さを選択することができ、これにより個々の測定の間隔を決定する。
visualize_image_attr_multiple()関数を使用して、遮蔽アトリビューションの結果を表示します。この関数は、各領域に対する正と負のアトリビューションを表示するヒートマップを表示し、元の画像に正のアトリビューション領域をマスクします。
マスクは、模型が「猫のような」と判定した画像の領域を非常に明確に示します。
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
出力:
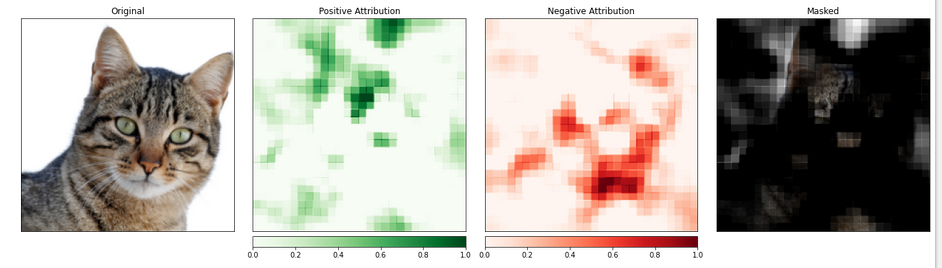
猫を含む画像の部分は、重要度の高いレベルに割り当てられているようです。
結論
Captumは、汎用性と簡洁性があるPyTorchのモデルの解釈性ライブラリです。特定のニューロンとレイヤが予測に及ぼす影響を理解するための最も最先端の技術を提供しています。
参考文献
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf