













소개
최근 几年的 모델 複雑도의 증가 및 その 관련 불 透明确性의 결과로, 모델 이해에 대한 중요성이 끊임없이 증가하고 있습니다. 모델 이해는 연구에서 burnishing 주제로, 다양한 분야의 기계 leaning 기반 실제 적용에서 결정적인 영역입니다.
Captum은 학자 및 개발자에게 통합 기梯(Integrated Gradients)과 같은 쾌克里한 기술을 제공하여 모델의 출력에 기여하는 요인을 간단하게 식별할 수 있도록 합니다. Captum은 ML 연구자들이 PyTorch 모델을 사용하여 이해 가능한 기법을 快速 생성할 수 있도록 简単하게 합니다.
모델의 출력에 기여하는 많은 요인을 쉽게 식별할 수 있어, Captum은 모델 개발자들이 더 좋은 모델을 만들고, 기대 밖에 나타나는 결과를 제공하는 모델을 修正할 수 있습니다.
알고리즘 기술
Captum은 이해 가능한 다양한 기법을 구현할 수 있는 라이브러리입니다. Captum의 인 tribute 알고리즘을 세 가지 대표적인 분류할 수 있습니다 :
- 주요 인tribute: 모델의 출력에 기여하는 각 입력 특성의 공헌을 결정합니다.
- 层次別対応: 特定の层次にある各ニューロンがモデルの出力に対する貢献度を評価されます。
- ニューロンの対応: 隠れニューロンの激活は、各入力特徴の貢献度を評価することで決定されます。
以下は、Captum に実装されている主要な层次やニューロンの貢献度评価方法の簡単な概要です。また、ノイズトンネルの説明も含まれています。これは、どのような帰因方法の結果を滑らかにすることができます。
Captum は、归因アルゴリズムに加えて、モデルの説明の信頼性を評価する指標を提供しています。現在、彼らは不正確さと敏感度の指標を提供しています。これらは、説明の正確性を評価するために使用されます。
主要な归因技術
統合梯度
ormal representation of a deep network, F : Rn → [0, 1]를 가지고 있다고 하자. 현재 입력이 x ∈ Rn이고, 기본 입력이 x′ ∈ Rn이다. 이미지 네트워크에서 기본값은 검은 이미지일 수 있지만, 텍스트 모델에서는 zero embedding vector일 수 있다. 기본값 x′에서 입력 x로 직선 경로(Rn에서)上古에 모든 포인트에서 그레이디언트를 computute하고, 이러한 그레이디언트를 cumulate하면 integrated gradients를 생성할 수 있다. Integrated gradients는 기본값 x′에서 입력 x로 직접적인 경로를 따라 그레이디언트의 경로 积分을 의미한다.
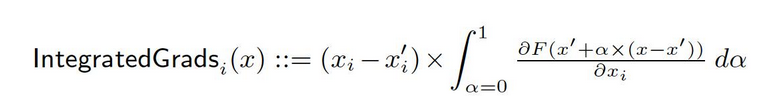
이 method의 기반이 되는 두 가지 기본 가정, sensitivity와 implementation invariance이 있다. 이러한 公理에 대해 더 많은 정보를 얻으시려면 original paper를 참조하시기 바랍니다.
Gradient SHAP
Shapley 값은 협업 게임 이론에서 사용되는 값으로, Gradient SHAP 값을 계산하는 데 사용되며, 그 값은 그라디언트 方法的に computed다. Gradient SHAP는 각 입력 샘플에 Gaussian 노이즈를 여러 번 추가하고, 그 다음에 기본 값과 입력 사이의 경로에서 임의의 지점을 선택하여 출력의 그라디언트를 deterrmine한다. 결과적으로, 最终的 SHAP 값은 그라디언트의 expected value를 represent한다. * (inputs – baselines). SHAP 값은 입력 특성이 독립적이고, 설명 모델이 입력과 공급된 기본값 사이에 linear하다는 가정에서 근사되는 것이다.
DeepLIFT
DeepLIFT(Backpropagation 기술)를 사용하여 인풋의 변화를 인풋과 일치하는 réference(또는 기준 값) 사이의 차이에 따라 지정할 수 있습니다. DeepLIFT은 기준 값으로부터 나온 인풋과 인풋의 차이를 사용하여 기준 값으로부터 나온 输出의 차이를 explain하려고 시도합니다. DeepLIFT는 곱LIeter라는 아이디어를 사용하여 결과의 차이를 인풋 신경元(neuron)에 “culpability”(责任制)를 부여하고자 합니다. 기준 값에 대한 차이가 ∆x인 give인풋 신경元 x와 결과 신경元 t(기준 값과의 차이 ∆t)에 대해 기여도를 computer하고자 하면, 곱LIeter m∆x∆t을 다음과 같이 정의합니다.
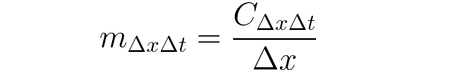
DeepLIFT SHAP
DeepLIFT SHAP는 협동 경쟁 이론에 기반한 Shapley value에 기반한 DeepLIFT 확장입니다. DeepLIFT SHAP은 각 인풋-기준 쌍에 대한 DeepLIFT 지정을 computer하고, 기준 값 분포를 사용하여 각 인풋 예의 결과를 평균ize합니다. DeepLIFT의 nonlinearity 규칙은 네트워크의 nonlinear function을 linearize하는 데 도움이 되며, SHAP value의 어떻게 사용되는가 대략 이 方法의 추정이 linearized network에도 적용되ます. 이 方法에 따라 인풋 feature는 독립적인 것으로 가정됩니다.
시각 중요도
입력 의미 분석을 통한 시각 중요도 computing는 입력에 대한 출력의 기울기를 생성하는 간단한 과정입니다. 입력에서 첫 oder Taylor series expansion를 사용하고, 기울기는 모델의 linear representation에서 각 특성의 係수입니다. 이러한 係수의 절대값을 사용하여 특성의 관련성을 나타낼 수 있습니다. 시각 중요도 방법에 대한 자세한 정보는 원본 论文에서 찾을 수 있습니다.
Input X Gradient
입력 X 그라디언트은 사aliency 접근法의 확장입니다. 입력에 대한 输出의 그라디언트를 취하고, 그 그라디언트를 입력 특징 값과 곱하는 것입니다. 이 접근法의 하나의 直観적인 의도는 直線적인 모델을 考虑하는 것입니다; 그라디언트는 각 입력에 대한 係수들뿐입니다. 입력과 係수의 곱은 특징이 直線적인 모델의 输出에 대한 전체 기여를 나타냅니다.
가이딩 백프로帕티ashing 및 디콤보닝
가이딩 백프로帕티ashing와 디콤보닝를 사용하여 그라디언트 computation을 수행합니다. 尽管 ReLU 함수의 백프로帕티ashing가 그라디언트가 음수가 아닌 Non-negative gradients only로 대체되었습니다. Guided backpropagation에서는 입력 그라디언트에 ReLU 함수를 적용하지만, deconvolution에서는 输出 그라디언트에 직접 적용합니다. convolutional networks에서 이러한 方法을 함께 사용하는 것은 일반적입니다. 그러나 다른 유형의 신경망 구조에도 사용할 수 있습니다.
가이드 GradCAM
가이드 역전파 속성은 가이드 GradCAM 속성(가이드 GradCAM)과 업샘플링된 (레이어) GradCAM 속성의 요소별 곱을 계산합니다. 속성 계산은 주어진 레이어에 대해 수행되며 입력 크기에 맞게 업샘플링됩니다. 이 기술은 주로 합성곱 신경망에 초점을 맞추고 있습니다. 그러나 입력과 공간적으로 정렬될 수 있는 모든 레이어가 제공될 수 있습니다. 일반적으로 마지막 합성곱 레이어가 제공됩니다.
특성 제거
“특성 제거“라고 알려진 기술은 속성을 계산하기 위해 각 입력 특성을 알려진 “기준선” 또는 “참조 값”(예: 0)으로 대체한 후 출력 차이를 계산하는 교란 기반 방법을 사용합니다. 입력 특성을 개별적으로 처리하는 대신 그룹화하고 제거하는 것이 더 나은 대안이며, 이는 다양한 응용 분야에서 유용할 수 있습니다. 이미지의 세그먼트를 그룹화하고 제거함으로써 해당 세그먼트의 상대적 중요도를 파악할 수 있습니다.
기능 변경
기능 변경은 배치 내에 각 특성을 случай하게 Permute 하고, 이 수정의 결과로 产出(output)의 변화(change)이나 손실(loss)를 계산하는 perturbation-based 方法입니다. 특성은 单品로 그룹化되어 있을 수 있으며, feature ablation과 마찬가지로 같은 방식으로 그룹화 할 수 있습니다. Captum에서 사용 가능한 다른 알고리즘과 대조적으로, 이 알고리즘은 다양한 인풋 예시의 배치를 사용하면서 적절한 인 tribute를 제공할 수 있는 유일한 것입니다. 다른 알고리즘은 单品의 인풋으로 대응합니다.
오clussion
오clussion는 인tribute computing에 사용되는 perturbation-based 方法으로, 지정한 기준이나 참조(baseline/reference)로 연속적인 矩形 영역을 대체하고 产出의 차이를 계산합니다. 다양한 영역(hypersquares)에 위치하는 특성의 경우, 해당 특성의 인tribute를 구할 때 输出的 차이를 평균化하여 computing합니다. 이미지와 같은 경우에 유용하며, 연속적인 矩形 영역의 픽셀들이 높은 相关性을 가지고 있을 수 있습니다.
Shapley Value Sampling
Shapley 值 이라고 불리는 의미 분할 기술은 협력 게임 이론에 기반한 것입니다. 이 기술은 입력 특성의 각 조합을 하나씩 speicified baseline에 추가하고 있을 때의 输出来의 차이를 기록하고 있습니다. 각 특성을 추가한 후 나온 输出来의 차이는 그 특성의 기여도를 나타며, 이러한 차이는 모든 조합에 대해 합쳐진 후 의미 분할을 결정합니다.
Lime
가장 널리 사용되는 interpretability 방법 중 하나로 Lime를 사용합니다. 이 방법은 입력 예시 근처의 데이터 포인트를 샘플링하고, 이 포인트에서 모델의 평가 결과를 사용하여 이해하기 쉽게 linear model과 같은 간단한 의미 분할 ‘대안’ 모델을 훈련합니다.
KernelSHAP
커널 SHAP는 LIME 框架을 사용하여 Shapley 값을 계산하는 기술입니다. LIME 框架을 사용하여 Shapley 값을 적效적으로 얻을 수 있습니다. 손실 函數을 설정하고, 가중치를 곱하고, 적절한 정규화 항목을 사용하여 이러한 기술을 적용합니다.
层次说明技术
层次导电性
层次导电性는 ニューロン의 활성asy 및 입력과 대응하는 연산의 부분 differentials를 조합하여 신경 자원에 대한 자신의 중요성을 더욱 详しく 이해하는 방법입니다. 隐藏的 ニューロン을 통해 Integrated Gradients (IG)의 지정방향을 확장하고자 합니다. 隐藏的 ニューロン의 전체 도전성(total conductance)는 다음과 같이 원래 논문에서 정의되어 있습니다.
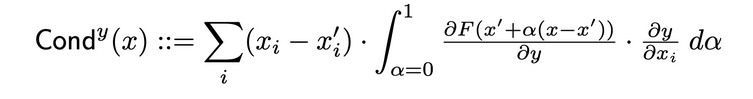
내부 영향
내부 영향을 사용하면, 기본 입력에서 제공된 입력까지의 경로沿って 그레이디언트의 정积分을 추정할 수 있습니다. 이 기술은 Layern에 대해 그레이디언트를 integrate하는 integrate Gradients를 적용하는 것과 유사합니다.
层次 그레이디언트 X 활성
层次 그레이디언트 X 활성은 네트워크의 Input X Gradient 기술의 대안으로 네트워크의 은하 层次에 대해 사용되는 것과 같습니다… 层次 요소의 활성과 지정한 层次에 대한 대상 출력의 그레이디언트를 Each element에 대해 곱하고 있습니다.
GradCAM
GradCAM는 일반적으로 마지막 卷积 层次에 적용되는 卷积 신경망 层次 지정 기술입니다. GradCAM는 지정한 层次에 대한 대상 출력의 그레이디언트를 계산하고, 각 출력 채널(출력 维 2)를 평균化하고, 각 채널의 평균 그레이디언트를 层次 활성에 곱합니다. ReLU를 출력에 적용하여 모든 채널을 통해 결과를 합한 것의 것에 대해 음수가 아닌 지정 attributions만 리턴되도록 합니다.
Neuron Attribution Techniques
Neuron 전달阻力的 연구
전달阻力는 NEURON 의 활성화와 입력과 출력 相对于 NEURON 的 부분 微分을 结合하여 NEURON의 重要性를 더 자세히 나타내는 것입니다. 특정 NEURON의 전달阻力를 결정하는 것은, 해당 NEURON을 통해 이flow of IG attribution from each input that passes through that neuron. 다음은 원본 논문의 特定 NEURON y given input attribution i 의 전달阻力 formal definition of :
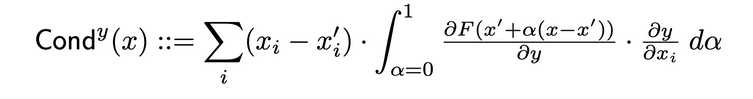
이 정의를 따르면, 읽는데 있어서 이를 참고할 필요가 있습니다. 여기서는 전달阻力의 NEURON (모든 입력 특성 중)의 합은 언제든지 해당 NEURON이 위치하고 있는 layer의 전달阻力와 같다는 것을 주의 깊게 생각하세요.
Neuron Gradient
뇌 그라디언트 접근法은 뇌 네트워크 안에 단일 뇌 신경 元자의 중요성 方法과 同等의 것입니다.
그 方法은 모델 입력에 대한 뇌 输出의 그라디언트를 간단하게 계산합니다.
이 方法, Saliency와 마찬가지로, 주어진 입력에서 뇌의 输出을 首}(zero-th) oder Taylor 확장을 하고 있다고 생각할 수 있으며, 그 경로는 모델의 直列 表現에 있는 각 특징의 값에 대한 계수로 해석할 수 있습니다.
뇌 통합 그라디언트
“뇌 통합 그라디언트” 이라는 기술을 사용하여 기본 입력에서부터 관심 있는 입력까지 경로 全过程에 대한 입력 그라디언트의 곱에 따라 뇌 전체의 integrate를 추정할 수 있습니다. integrate 그라디언트는 이 方法의 输出来历이 단순히 식별된 뇌의 것인 것을 가정하여 同等의 것입니다. 통합 그라디언트 方法의 자세한 정보는 원래 论文 여기에서 찾을 수 있습니다.
뇌 그라디언트 SHAP
Neuron GradientSHAP은 특정 ニューロン의 GradientSHAP의 同等である。Neuron GradientSHAPは各入力サンプルにガウスノイズを何度も足して、基準値と入力値の間の路径上の乱数の点を選び、目标ニューロンが各選んだ乱数の点に対する勾配を計算する。計算されるSHAP値は、予測勾配値*(inputs – baselines)に似ている。
Neuron DeepLIFT SHAP
Neuron DeepLIFT SHAPは特定のニューロンに対するDeepLIFTの同等である。基数の分布を使用して、DeepLIFT SHAPアルゴリズムは各入力-基数の对に対するニューロン DeepLIFT属性を計算し、各入力例に対する平均属性を計算する。
Noise Tunnel
Noise Tunnelは他の方法と並行して使用できる属性技術である。ノイズトンネルは何度も属性を計算し、各回は入力にガウスノイズを足して、選ばれた種類に基づいて結果を結合する。以下のノイズトンネルの種類がサポートされている。
- Smoothgrad: 샘플 지정 지표의 평균이 리턴되며, 가우시안 kernel을 사용하여 지정 지표를 평滑하는 과정은 이 과정의 근사치로 정의되며,
- Smoothgrad Squared: 샘플 지정 지표의 제곱의 평균이 리턴되며,
- Vargrad: 샘플 지정 지표의 方差이 리턴되며,
Metrics
Infidelity
Infidelity는 입력 perturbation의 magitude에 대한 모델 explaination과 예측자 함수가 이러한 입력 perturbation에 대한 변화를 분석하는 과정을 평균 제곱誤差로 衡量하며, 다음과 같이 정의되며,
Integrated Gradient과 같은 잘 알려진 지정 기술에서는 Sensitivy-n이라는 과정을 더 이상 计算机적으로 효율적이고 확장적인 개념으로 정의하며, 后者는 지정 지표의 합과 예측자 함수의 입력과 정의된 기본 line의 차이에 대한 상관 관계를 분석한다.
Sensitivity
인식도는 蒙特卡洛采样기반 근사로 toy input perturbations에 대한 설명 변화 도畿을 나타내는 지수입니다. 인식도는 다음과 같은 방법으로 측정되며:

기본적으로는 L-Infinity 공体内의 하위 공간에서 기본 반지름을 사용하여 인식도를 근사합니다. 사용자는 공体内의 반지름과 샘플 함수를 변경할 수 있습니다.
Pretrained ResNet Model의 모델 이해
이 튜토리얼에서는 선택된 이미지에 적용되는 모델 이해 方法을 보여줍니다. 이미지에 的重叠 한 것처럼 각 픽셀의 인과关系을 보여줍니다. 이 튜토리얼에서는 Integrated Gradients, GradientShape, Layer GradCAM과 Occlusion을 사용하여 이해 알고리즘을 적용합니다.
시작하기 전에, 다음과 같은 Python 환경이 필요합니다:
- Python 버전 3.6 또는 更高
- PyTorch 버전 1.2 또는 更高 (最新 버전을 推奨합니다)
- TorchVision 버전 0
- .6 또는 更高 (最新 버전을 推奨합니다)
- Captum (最新 버전을 推奨합니다)
Anaconda 또는 pip 가상 환경을 사용하는 것에 따라 다음 명령어를 사용하여 Captum을 설정할 수 있습니다:
conda를 사용하여 :
conda install pytorch torchvision captum -c pytorch
`pip` 를 사용하여 :
pip install torch torchvision captum
라이브러리를 導入하겠습니다.
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
이전에 트레이닝 된 ResNet 모델을 로드하고 평가 모드로 settings
model = models.resnet18(pretrained=True)
model = model.eval()
ResNet은 ImageNet 데이터셋에 기반해 트레이닝 되었습니다. 메모리에 ImageNet 데이터셋 클azz / 레이블 목록을 다운로드하고 읽습니다.
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
이제 모델이 완성되었으므로 분석을 위해 이미지를 다운로드 할 수 있습니다. 저의 경우, 고양이 이미지를 선택했습니다.

您的 이미지 폴더는 cat.jpg 파일을 포함해야 합니다. 아래에서 我们可以 see, Image.open() 는 주어진 이미지 파일을 여는 것과 식별하는 것을 하고, np.asarry() 는 그것을 어레이로 변환합니다.
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
아래 코드에서, 이미지에 대한 전이 및 정규화 함수를 정의 할 것입니다. 우리의 ResNet 모델을 트레이닝 할 때, ImageNet 데이터셋을 사용하므로 이미지가 특정 크기로 들어가야 하며, 채널 데이터가 지정된 값 범위로 정규화되어야 합니다. transforms.Compose() 는 여러 전이를 하나로 组み立て고, transforms.Normalize() 는 평균과 標準편차로 텐서 이미지를 정규화합니다.
# 모델 기대치는 224x224 3-color 이미지입니다.
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# ImageNet 정규화
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
# unsqueeze는 지정한 위치에 사이즈가 하나 있는 新的 텐서를 돌려주는 것입니다.
input = input.unsqueeze(0)
이제, 우리는 입력 이미지의 claSS를 예측할 것입니다. 질문은 “우리의 모델이 이 이미지가 represent 하는 것을 어떻게 생각하는지?”라고 할 수 있습니다.
# 우리의 모델을 호출합니다.
output = model(input)
## softmax() 함수를 적용합니다.
output = F.softmax(output, dim=1)
# torch.topk는 주어진 입력 텐서沿着 given 维度返回 k 个最大的元素。 K 는 1입니다.
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
# 예측 레이블로 钥值对的 사전을 만들고, 그것을 문자열로 바꾼 다음 예측 레이abel을 얻습니다.
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
output:
Predicted: tabby ( 0.5530276298522949 )
ResNet이 우리의 猫 이미지가 실제 猫을 表현하는 것을 생각하는 것이 확인되었습니다. 그러나 이 이미지가 猫의 이미지인지 어떻게 모델이 생각하는지는? 이 질문에 대한 정답을 얻기 위해서, Captum을 consUltation 하겠습니다.
Integrated Gradients 를 사용한 특징 기여도
Captum의 다양한 특징 기여도 기술 중 하나는 Integrated Gradients입니다. Integrated Gradients는 모델의 출력에 대한 입력의 기울기들의 积分을 사용하여 입력 특성에 대한 相关性 점수를 评测합니다.
우리의 경우, 우리는 출력 벡터의 특정 구성 요소를 취할 것입니다. 모델이 선택한 카테고리에 대한 신뢰도를 나타내는 것 – 그리고 통합 그라디언트를 사용하여 입력 이미지의 어떤 측면이 이 출력에 기여했는지 알아냅니다. 이것은 이미지의 어떤 부분이 이 결과를 생성하는 데 가장 중요한지 결정할 수 있도록 할 것입니다.
통합 그라디언트에서 중요도 맵을 얻은 후에, 우리는 Captum에 의해 캡처된 시각화 도구를 사용하여 중요도 맵에 대한 명확하고 이해할 수 있는 묘사를 제공할 것입니다.
통합 그라디언트는 예측된 클래스 pred_label_idx에 대한 모델의 출력에 대한 그래디언트의積分을 결정합니다. 입력 이미지 픽셀에 대한 경로를 따라 검은 이미지에서 입력 이미지까지입니다.
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
통합 그라디언트 객체를 생성하고 속성을 가져옵니다.
integrated_gradients = IntegratedGradients(model)
알고리즘에 출력 대상 할당을 요청합니다.
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
출력:
Predicted: tabby ( 0.5530276298522949 )
이미지와 함께 가는 속성들을 확인해 보겠습니다. 속성들을 이미지 위에 겹쳐서 표시합니다. Captum이 제공하는 visualize_image_attr() 메서드는 속성 데이터의 표시를 사용자의 선호도에 맞게 조정할 수 있는 여러 가지 가능성을 제공합니다. 여기서, 우리는 사용자 지정 Matplotlib 색상 맵( LinearSegmentedColormap() 참조)을 전달합니다.
# customs colormap 사용하여 결과 시각화
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
# 比較为目的に原始的な画像を表示するために visualize_image_attr 助手関数を使用して可视化
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
Output:
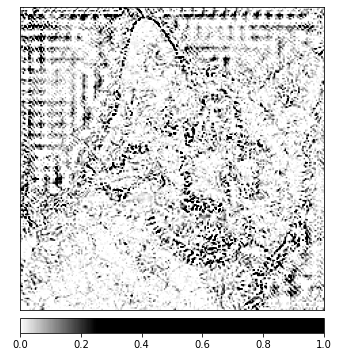
上記の画像において、私たちが表示した領域で、Integrated Gradients アルゴリズムが最も強い信号を与えていることが気づけるはずです。
次に、Integrated Gradientsを使用して属性を計算し、それらをnoise tunnelによって作成されたいくつかの画像に柔らかく適用します。后者は入力にGaussianノイズを加え、標準偏差が1の場合であり、10倍(nt_samples=10)です。smoothgrad_sq手法は、noise tunnelによって、smoothgrad_sqの値がsmoothgrad_sqになることができます。これはnt_samplesのノイズサンプルの属性の平均のスカラー値です。visualize_image_attr_multiple()は、特定のサインの属性値(ポジティブ、ネガティブ、絶対値、またはすべて)を正規化し、選択されたモードを使用してmatplotlibの図に表示します。
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
Output:

上の画像で、モデルが猫の頭を焦点にしていることがわかります。
우리는 GradientShap을 사용해서 끝낼 수 있습니다. GradientShap는 SHAP 값을 computute하는 其中一个 gradient approach를 사용하며 전역적인 행동을 이해하는 좋은 도구입니다. 모델의 예측을 参照 샘플 분포를 사용하여 설명하는 선형 설명 모델입니다. arbitrarily selected input 가 input과 기본 값 사이에서 기본 값을 任意하게 선택하여 기대값이 결정됩니다.
기본 값은 제공된 기본 값 분포에서 arbitrary하게 선택됩니다.
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# 이미지의 기본 분포 정의
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
Output:

Layer Attribution with Layer GradCAM
Your model’s hidden layer activities can be related to the features of your input through Layer Attribution.
We will use an algorithm for layer attribution to investigate the activity of one of the convolutional layers within our model.
GradCAM is responsible for computing the gradients of the target output with respect to the specified layer. These gradients are then averaged for each output channel (dimension 2 of output), and the layer activations are multiplied by the average gradient for each channel.
The results are summed across all channels. Since the activity of convolutional layers often maps spatially to the input, GradCAM attributions are frequently upsampled and used to mask the input. GradCAM is explicitly developed for convolutional neural networks (convnets). Layer attribution is set up in the same way as input attribution, except that you must provide a hidden layer inside the model that you want to analyze, in addition to the model. Similar to what was discussed before, when we call attribute(), we indicate the target class of interest.
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
To make a more accurate comparison between the input image and this attribution data, we will upsample it with the help of the function interpolate(), located in the LayerAttribution base class.
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
Output:
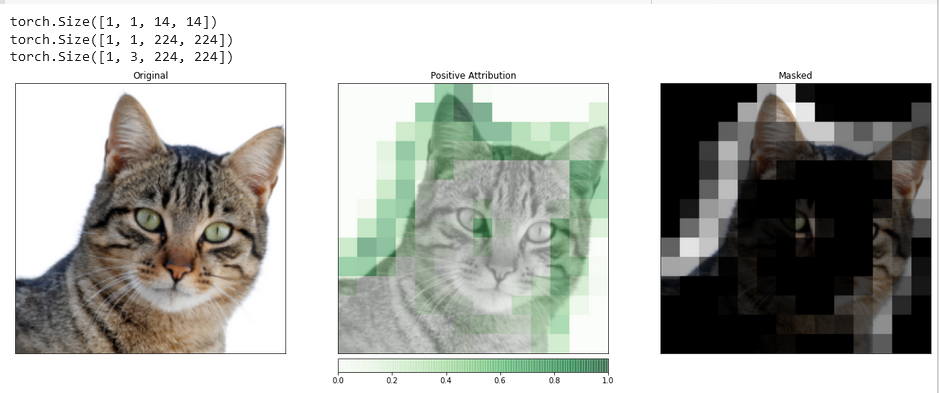
Visualizations such as this one can provide you with unique insights into how your hidden layers respond to the input you provide.
특성 의미 지정 방법
渐变기반 방법은 모델을 직접적으로 입력에 대한 产出의 변화를 계산하여 이해하는 것에 도움이 됩니다. perturbation-based attribution이라고 知られ고 있는 기술은 이러한 문제를 더 직관적으로 해결하기 위해 입력을 수정하는 것을 사용하며, 이러한 변화가 产出에 어떻게 영향을 미치는지 수량적으로 quantify하는 것입니다. 이러한 전략 중 하나는 occlusion라고 불립니다.
이것은 입력 이미지의 일부를 替え어 이 변화가 产出에 일어나는 신호에 어떻게 영향을 미치는지 분석하는 것입니다.
次に、occlusion 의미 지정을 구성할 것입니다. convolutional neural network의 구성과 유사하게, 대상 영역의 크기와 stride 長さ를 선택할 수 있으며, 이것은 개별 측정의 간격을 결정합니다.
我们 visualize_image_attr_multiple() 함수를 사용하여 Occlusion 의미 지정의 결과를 보여줍니다. 이 함수는 각 영역에 대한 积极과 Negative 의미 지정의 heat map을 보여주고 원본 이미지에 积极 의미 지정 영역을 마스킹합니다.
마스킹은 우리의 猫 사진에서 모델이 “猫-like” 특성을 가장 잘 인식한 영역을 시각적으로 잘 보여줍니다.
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
产出:
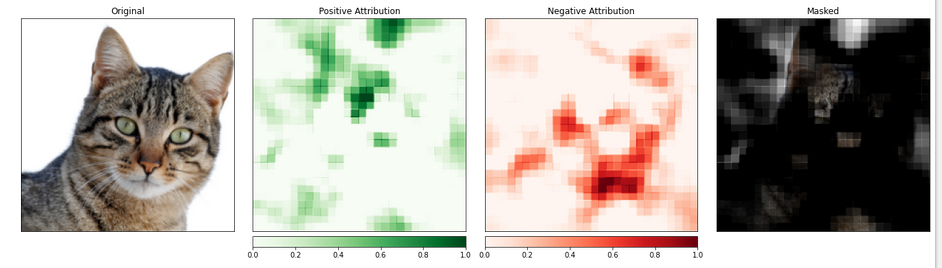
猫이 들어가는 이미지 부분은 중요도가 높게 보입니다.
결론
Captum은 다양하고 간단한 PyTorch용 모델 이해성 라이브러리로, 특정 ニューроン과 层次이 예측에 어떻게 영향을 미치는지 이해하기 위한 최첨단 기술을 제공합니다.
主要有効性 기술, 层次的有効性 기술, ニューロン的有効性 기술 三种 主要な 归因 기술을 갖추고 있습니다.
参考文献
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf