













引言
模型的可解释性方法近年来日益重要,這 Directly due to the increase in model complexity and the associated lack of transparency. Model understanding is a hot topic of study and a focal area for practical applications employing machine learning across various sectors.
Captum 向学术界和开发者提供先进的技术,例如集成梯度(Integrated Gradients),使其能够轻易识别影响模型输出的元素。Captum 使 ML 研究人员更轻松地使用 PyTorch 模型构建可解释性方法。
通过更容易地识别影响模型输出的众多元素,Captum 可以帮助模型开发者创建更好的模型并修复提供意外结果的模型。
算法描述
Captum 是一个允许实现各种可解释性方法的库。可以将 Captum 的归属算法分为三大类:
- 主要归属:确定每个输入特征对模型输出的贡献。
- 層級归因:特定層中的每個神經元都被評估其對模型輸出的貢獻。
- 神經元归因:一個隱藏神經元的激活是由於評估了每個輸入特性的貢獻所決定。
以下是一個簡要 Overview,目前於 Captum 之中实施的各種主要、層次與神經元歸因方法的介绍。也包括了一個噪聲通道的描述,可以用於滑動任何歸因方法的結果。
Captum 提供指標以估計模型解釋的可靠度,及其歸因算法。目前它們提供不忠度與敏感度指標,以幫助評估解釋的準確性。
主要歸因技術
整合梯度
假設我們有深度網絡的正規表示,F: Rn → [0, 1]。
讓 x ∈ Rn 是要輸入的當前值,而 x′ ∈ Rn 是基線輸入值。
在影像網絡中,基線可能會是全黑的影像,而在文字模型中,基線可能會是零嵌入向量。
從基線 x′ 到輸入 x,我們在 Rn 中的直線路上計算所有點的梯度。通過累計這些梯度,可以生成整合梯度。整合梯度被定義為從基線 x′ 到輸入 x 的直接路上的梯度路径積分。
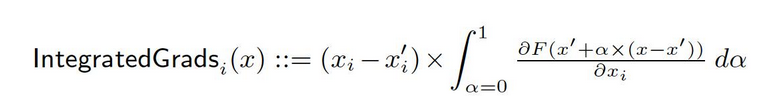
這兩種基本假设(敏感度與實現不失原型)是這個方法的基礎。請參考 原论文 以了解更多關於這些公理的資訊。
梯度SHAP
在合作博弈論中,Shapley值被用來計算梯度SHAP值,它們使用梯度方法計算。梯度SHAP在每個輸入樣本中添加多次高斯噪聲,然後在基準線和輸入之間的路徑上選擇一個隨機點來確定輸出的梯度。因此,最終的SHAP值代表梯度的預期值。*(輸入 – 基準線)。SHAP值的近似基於輸入特徵是獨立的,且解釋模型在輸入和提供的基準線之間是線性的。
DeepLIFT
可以利用 DeepLIFT(一種反傳染技藝) 將輸入變異归因於輸入與其對應參考值(或基線)之間的差異。DeepLIFT 嘗試解釋參考值 Output 之間的差異,使用輸入值之間的差異。DeepLIFT 使用乘數概念來「歸咎」單一的神經元對 Output 差異的貢獻。對於給定的輸入神經元 x 与其與參考值的差異 ∆x,以及我們希望計算其貢獻的目標神經元 t 与其與參考值的差異 ∆t,我們將乘數 m∆x∆t 定義為:
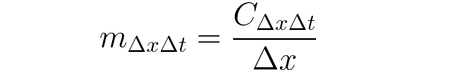
DeepLIFT SHAP
DeepLIFT SHAP 是一個以合作遊戲理論中建立的 Shapley 值為基礎的 DeepLIFT 擴展。DeepLIFT SHAP 計算每個輸入基線對的 DeepLIFT 归因,並使用基線分佈平均結果。DeepLIFT 的非線性規則有助於線性化網絡的非線性功能,並且該方法的 SHAP 值的近似也適用於線性化網絡。在這種方法中,輸入特徵也被假定为獨立的。
突出性
透過 突出性 計算輸入歸因是一個直接的過程,可產生對於輸入的輸出梯度。在輸入處使用 一阶泰勒網絡 擴展,而这些梯度就是模型線性表示中每個特性的系數。這些系數的絕對值可以用來指示一個特性的相關性。您可以在 原 Paper 中找到關於突出性方法的進一步資訊。
輸入 X 梯度
輸入 X 梯度 是显着性方法的扩展,它取output关于input的梯度並乘以input特徵值。這種方法的一個直覺考慮到一個線性模型;梯度只是每個input的係數,並且input與係數的乘積對應於特徵對線性模型output的總貢獻。
指導性反向傳播和去卷積
梯度計算是通過指導性反向傳播和去卷積進行的,儘管ReLU函數的反向傳播被覆蓋,以便只反向傳播非負梯度。雖然在指導性反向傳播中對輸入梯度應用ReLU函數,但在去卷積中直接對輸出梯度應用ReLU函數。通常將這些方法與卷積網絡一起使用,但它們也可以用於其他類型的神經網絡結構。
導向GradCAM
導向反向傳播歸因 compute the element-wise product of guided GradCAM attributions (導向GradCAM) with upsampled (層) GradCAM attributions. 歸因計算是對於一個給定的層進行,並將其上采样以符合輸入大小。這種技術主要關注卷積神經網絡。然而,任何可以與輸入在空間上對齊的層都可能被提供。通常,最後一個卷積層被提供。
特徵消融
為了計算歸因,一種稱為“特徵消融”的技術使用一種扰動基礎的方法,在計算輸出差異前將每個輸入特徵的“基線”或“參考值”(如0)替換。將輸入特徵分组消融是這樣做的更好選擇,並且许多不同的應用都可以從這中受益。通過將圖像的分段進行分组消融,我們可以確定分段的相對重要性。
特點置换
特點置换是一種基於擾動的方法,其中每個特點在一批中隨機置换,並計算由此修改引起的輸出(或損失)的變化。特點也可以像特點消除一樣grouped together,而不是單獨進行。請注意,與Captum中可用的其他算法相比,當此算法提供給一批多個輸入例證時,它可能是唯一能提供正確歸屬的算法。其他算法只需要一個輸入例證。
遮蔽
遮蔽是一種基於擾動的方法來計算歸屬,將每個連續的长方形區域置換為給定的基线/參考值,並計算輸出的差異。對於位于多個區域(超長方體)中的特點,將對應的輸出差異平均以計算該特點的歸屬。遮蔽在圖像等情況下最有用,因為在这种情况下,連續長方形區域中的像素很可能高度相關。
Shapley 值采样
「Shapley 值」是一種基於合作遊戲理論的歸因技術。此技術会对輸入特性的每種排序逐一添加到一個指定的基线中。在添加每個特性後Output的差異代表了它的貢獻,這些差異會 across所有排序求和以決定歸因。
Lime
最广泛使用的解釋性方法之一是Lime,它通過在一個輸入示例周圍采样數據點並使用在这些點的模型評估來訓練一個可解释的替代表型,如一個線性模型。
KernelSHAP
Kernel SHAP 是一種使用 LIME 框架來計算 Shapley 值的技術。透過設定損失函數、權重 kernel 以及恰當的正則化項,Shapley 值可以在 LIME 框架中更有效地獲得。
層次歸因技術
層次導電性
層次導電性是一種通過結合神經元的活躍度以及神經元對輸入的偏導數和輸出對神經元的偏導數,來建立神經元重要性的更全面的照片的方法。透過隐藏的神經元,導電性在 Integrated Gradients(IG)的歸因流上建立。隐藏神經元 y 的總導電性如下在 原 Paper 中定義:
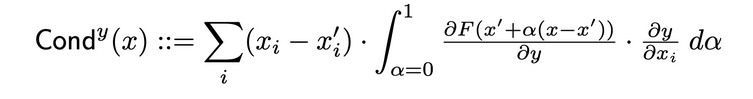
內部影響
使用內在建模,可以估計從基線輸入到提供的輸入之間路徑上的梯度積分。這技術與應用 Integrated Gradients 類似,涉及對層(而非輸入)積分。
層梯度X激活
層梯度X激活是網絡中對於網絡隱藏層的 Input X Gradient 技巧的對應…
它將層元素的激活與目標輸出對指定層的梯度逐元素相乘。
GradCAM
GradCAM 是一種通常應用於最後一個卷積層的卷積神經網絡層归因技巧。GradCAM 計算指定層的目標輸出的梯度,平均每個輸出通道(輸出維度 2),並將每個通道的平均梯度乘以層激活。在結果 across all channels 應用 ReLU 以確保從所有通道的結果之和中返回只有非負歸屬。
的神經元歸因技術
神經元導電性
導電性將神經元活躍度與輸入與神經元之間的偏微分以及輸出與神經元之間的偏微分結合,提供一個更全面的神經元相關性描繪。要確定某個神經元的導電性,就要檢查從每個通過該神經元的輸入而来的IG歸因流。以下是用於給定輸入歸因 i 的神經元 y 的導電性的原始論文正式定義 :
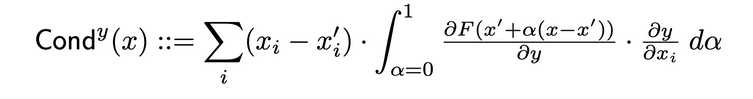
根據這個定義,应注意,總結一個神經元(跨所有輸入特徵)的導電性總是等於該特定神經元所在層的導電性。
的神經元梯度
神經梯度方法是网络上单个神经元显著性方法的等价物。
它简单地计算了神经元输出相对于模型输入的梯度。
这种方法,如同显著性方法,可以被视为在给定输入处对神经元输出进行一阶泰勒展开,其中梯度对应于模型线性表示中每个特征的系数。
神經綜合梯度
可以使用一种称为“神經綜合梯度”的技术,估计从基线输入到感兴趣输入路径上特定神经元的输入梯度的积分。假设输出仅仅是所识别的神经元的输出,积分梯度与该方法等价。您可以在原始论文這裡找到有关综合梯度方法的更多信息。
神經梯度SHAP
神经元GradientSHAP是与特定神經元相對應的GradientSHAP。神经元GradientSHAP多次向每個輸入樣本中添加高斯噪音,選擇基準線與輸入之間的隨機點,並計算目標神經元對每個隨機選擇點的導數。生成的SHAP值接近預測導數值 *。(輸入 – 基準線)。
神經元DeepLIFT SHAP
使用基準線的分佈,DeepLIFT SHAP算法為每個輸入-基準線對計算神經元DeepLIFT归因,並將生成的歸因結果平均於每個輸入例子中。
噪聲通道
噪聲通道 是一種可以與其他方法並用的归因技術。噪聲通道多次計算归因,每次向輸入中添加高斯噪音,然後根據選擇的類型合并結果。以下支持以下噪聲通道類型:
- Smoothgrad: 返回采樣歸屬的平均值。使用高斯核平滑指定的歸屬技術是此過程的近似。
- Smoothgrad 平方:返回平方采樣歸屬的平均值。
- Vargrad: 返回采樣歸屬的方差。
度量
不忠度
不忠度 衡量的是模型解釋在輸入干擾量的量度上與預測函數對這些輸入干擾量的變化之間的平均平方誤差。不忠度的定義如下:
從知名歸屬技術(如整合梯度)來看,這是在計算上更高效且對Sensitivy-n概念的擴展。後者分析了归屬總和與預測函數在輸入及其定義基線上的差值的相關性。
敏感度
敏感度,其定義為使用蒙特卡洛採樣基礎近似,對微小輸入 perturabtions 所做的解釋變化程度,以下是其量度方式:

預設情況下,我們從一個 L-Infinity 球體的子空間中採樣,並用來近似敏感度,使用者可以更改球的半徑和採樣函數。
預訓練 ResNet 模型的模型解釋
本教程將展示如何對選擇的圖像上的預訓練 ResNet 模型使用模型解釋方法,並通過覆蓋圖像上的每個像素來可视化各自的 attributions。在這個教程中,我們將使用解釋算法 Integrated Gradients、GradientShape、Layer GradCAM 和 Occlusion 的 Attribution。
在開始之前,您必須有一個 Python 環境,包括以下內容:
- Python 3.6 或更高版本
- PyTorch 1.2 或更高版本(建議使用最新版本)
- TorchVision 0
- .6 或更高版本(建議使用最新版本)
- Captum(建議使用最新版本)
根據您是使用 Anaconda 還是 pip 虛擬環境,以下命令將助您設定 Captum:
使用 conda:
conda install pytorch torchvision captum -c pytorch
使用 pip:
pip install torch torchvision captum
我們來導入庫。
import torch
import torch.nn.functional as F
from PIL import Image
import os
import json
import numpy as np
from matplotlib.colors import LinearSegmentedColormap
import os, sys
import json
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import torchvision
from torchvision import models
from torchvision import transforms
from captum.attr import IntegratedGradients
from captum.attr import GradientShap
from captum.attr import Occlusion
from captum.attr import LayerGradCam
from captum.attr import NoiseTunnel
from captum.attr import visualization as viz
from captum.attr import LayerAttribution
載入預訓練的 Resnet 模型並將其設置為評估模式
model = models.resnet18(pretrained=True)
model = model.eval()
ResNet 是在 ImageNet 數據集上進行訓練的。在記憶體中下載並讀取 ImageNet 數據集類別/標籤清單。
wget -P $HOME/.torch/models https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
labels_path = os.getenv("HOME") + '/.torch/models/imagenet_class_index.json'
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
現在我們已經完成了模型,可以下載圖片進行分析了。

您的圖片文件夾必須包含 cat.jpg 文件。如您所見,Image.open() 打開並識別給定的圖像文件,而 np.asarry() 將其轉化為數組。
test_img = Image.open('path/cat.jpg')
test_img_data = np.asarray(test_img)
plt.imshow(test_img_data)
plt.show()
在以下的代碼中,我們將為圖像定義變換器和歸一化函數。為了訓練我們的 ResNet 模型,我們使用了 ImageNet 數據集,這要求圖像必須是特定大小,並且通道數據已經歸一化到特定的值範圍。transforms.Compose() 將幾個變換組合在一起,而 transforms.Normalize() 則將張量圖像的均值和標準差進行歸一化。
# 模型期望是224x224 3-color 影像
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224), #crop the given tensor image at the center
transforms.ToTensor()
])
# ImageNet 标准化
transform_normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
img = Image.open('path/cat.jpg')
transformed_img = transform(img)
input = transform_normalize(transformed_img)
#unsqueeze 會返回一個在新的張量中在指定的位置插入大小為一的維度的新張量。
input = input.unsqueeze(0)
現在,我們將預測輸入影像的類別。可以問的問題是,“我們的模型認為這張影像代表什麼?”
# 呼叫我們的模型
output = model(input)
## 應用 softmax() 函數
output = F.softmax(output, dim=1)
# torch.topk 會返回給定輸入張量在給定維度上最大的 k個元素。這裡的 K 是 1
prediction_score, pred_label_idx = torch.topk(output, 1)
pred_label_idx.squeeze_()
# 將預測標籤轉化為字典 key-values 對,將它轉化為字符串以取得預測標籤
predicted_label = idx_to_labels[str(pred_label_idx.item())][1]
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
Output:
Predicted: tabby ( 0.5530276298522949 )
ResNet 認為我們的貓影像呈現實際的貓得到了確認。那麼什麼讓模型認為這是一張貓的影像呢?為了獲得這個問題的答案,我們將請教 Captum。
Integrated Gradients 整合梯度
Captum 中各種特徵歸因技巧之一的 Integrated Gradients。Integrated Gradients 通過估計模型輸出對輸入的梯度積分,為每個輸入特徵授予相關分數。
在我們的案例中,我們將取輸出向量的特定部件 – 表示模型對其選擇類型的信心的那個 – 並使用集成梯度來找出輸入圖像的哪些方面對此輸出有所貢獻。這將使我們能夠確定產生此結果時圖像的哪些部分最重要。
獲得集成梯度的重要度映射後,我們將使用Captum捕獲的視覺化工具為重要度映射提供一个清晰易懂的表示。
集成梯度將確定模型對於预测類型pred_label_idx的輸出對於輸入圖像像素沿從黑色圖像到我們輸入圖像的路徑的梯度積分的總和。
print('Predicted:', predicted_label, '(', prediction_score.squeeze().item(), ')')
#創建集成梯度對象並獲取屬性
integrated_gradients = IntegratedGradients(model)
#要求算法將我們的輸出目標分配給
attributions_ig = integrated_gradients.attribute(input, target=pred_label_idx, n_steps=200)
輸出:
Predicted: tabby ( 0.5530276298522949 )
讓我們通過將後者叠加在圖像上來查看圖像及其隨附的歸屬。Captum提供的visualize_image_attr()方法提供了一系列可能性,以便根據您的喜好自定義歸屬數據的展示方式。在此,我們傳入一個自定義的Matplotlib顏色映射(見LinearSegmentedColormap())。
#結果可视化自訂色彩映射
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
#使用visualize_image_attr助手方法進行可视化,以供比較原始影像
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
Output:
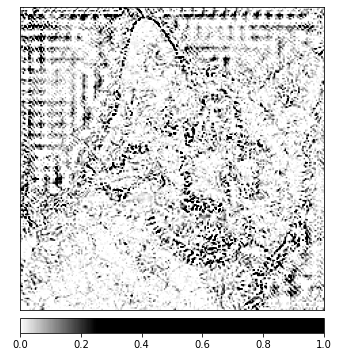
您應該能在我們上面展示的影像中注意到,Integrated Gradients算法給我们的最强信號就是围绕著影像中的猫的区域。
讓我們通過使用Integrated Gradients來計算归因,然後在由noise tunnel生成的几张图像中平滑它们。
後者通過添加標準差為一的高斯噪音來修改輸入,進行10次修改(nt_samples=10)。smoothgrad_sq方法是noise tunnel用来使归因在所有nt_samples噪聲样本上一致的方法。
smoothgrad_sq的值是nt_samples样本上平方归因的平均值。visualize_image_attr_multiple()通过归一化指定符號的归因值(正面、負面、絕對值或所有)来可视化给定图像的归因,然后使用选择的模式在matplotlib圖形中显示它们。
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(input, nt_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)
Output:

从上面的图片中,我可以看到模型集中在猫的头部。
我們最後來使用GradientShap。GradientShap是一個梯度方法,可用來計算SHAP值,它也是一個了解全局行為的絕佳工具。它是一個線性解釋模型,通過使用參考樣本的分布來解釋模型的預測。它為在輸入和基線之間的隨機選取的輸入 determination 预期梯度。基線從提供的基線分布中隨機選擇。
torch.manual_seed(0)
np.random.seed(0)
gradient_shap = GradientShap(model)
# 基線圖像分布的定義
rand_img_dist = torch.cat([input * 0, input * 1])
attributions_gs = gradient_shap.attribute(input,
n_samples=50,
stdevs=0.0001,
baselines=rand_img_dist,
target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_gs.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "absolute_value"],
cmap=default_cmap,
show_colorbar=True)
Output:

層級分配與層級GradCAM
您可以將模型內隐藏層的活動與輸入的特徵相關聯,並通過層歸因(Layer Attribution)來幫助您做到這一點。
我們將應用層歸因算法來調查模型中包含的其中一个卷積層的活動。
GradCAM负责計算目標輸出對於指定層的梯度。這些梯度然後對於每個輸出通道(輸出的維度2)進行平均,並將層激活與每個通道的平均梯度相乘。
結果跨所有通道求和。由於卷積層的活動通常在空間上對應於輸入,因此GradCAM歸因通常会上采样並用於遮罩輸入。值得注意的是GradCAM是专门為卷積神經網絡(convnets)開發的。層歸因的設定方式與輸入歸因相同,不同的是除了模型外,您還必須提供模型內您想要分析的隱藏層。與之前討論的一樣,當我們呼叫attribute()時,我們指定了感興趣的目標類別。
layer_gradcam = LayerGradCam(model, model.layer3[1].conv2)
attributions_lgc = layer_gradcam.attribute(input, target=pred_label_idx)
_ = viz.visualize_image_attr(attributions_lgc[0].cpu().permute(1,2,0).detach().numpy(),
sign="all",
title="Layer 3 Block 1 Conv 2")
為了使輸入圖像與歸因數據之間進行更精確的比較,我們將使用interpolate()函數上采样,該函數位於LayerAttribution基類中。
upsamp_attr_lgc = LayerAttribution.interpolate(attributions_lgc, input.shape[2:])
print(attributions_lgc.shape)
print(upsamp_attr_lgc.shape)
print(input.shape)
_ = viz.visualize_image_attr_multiple(upsamp_attr_lgc[0].cpu().permute(1,2,0).detach().numpy(),
transformed_img.permute(1,2,0).numpy(),
["original_image","blended_heat_map","masked_image"],
["all","positive","positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Masked"],
fig_size=(18, 6))
Output:
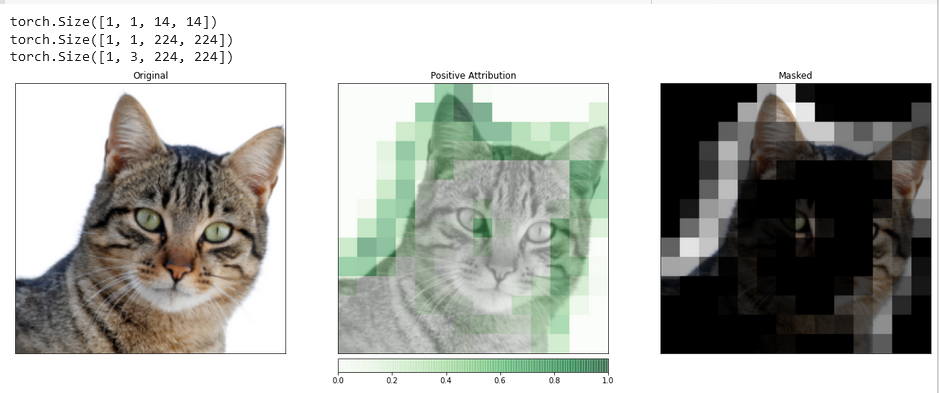
這種類型的可视化有潛力為您提供關於模型隱藏層如何對您提供的輸入做出反應的独特見解。
特徵归因與遮蔽
基於梯度的方法有助於了解模型,即直接計算輸入變化和輸出之間的變化。
被人稱為遮蔽基礎归因的技術,以更直接的方式解决这个问题,通过对输入进行修改来量化这种变化对输出的影响。其中一种策略被称为遮蔽。
它涉及替換輸入圖像的片段,並分析這種變化如何影響輸出产生的信號。
在以下内容中,我们将配置遮蔽归因。就像卷積神經網絡的配置一樣,您可以選擇目標區域的大小和步長長度,這決定了个别測量之間的間隔。
我们将使用visualize_image_attr_multiple()函数来查看我们的遮蔽归因结果。这个函数将显示每个区域的正负归因的热图,并用正归因区域遮盖原始图像。
遮盖提供了一个非常启发性的视角,展示了模型认为最有“猫样”的区域。
occlusion = Occlusion(model)
attributions_occ = occlusion.attribute(input,
target=pred_label_idx,
strides=(3, 8, 8),
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map", "heat_map", "masked_image"],
["all", "positive", "negative", "positive"],
show_colorbar=True,
titles=["Original", "Positive Attribution", "Negative Attribution", "Masked"],
fig_size=(18, 6)
)
输出:
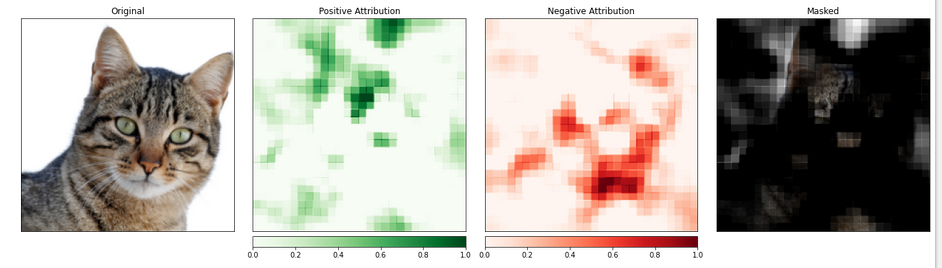
包含猫的部分似乎被赋予了更高的优先级。
結論
Captum 是一個用於 PyTorch 的模型的模型解釋性庫,具有多才多藝和簡單的特點。它提供了了解特定神經元和層如何影響預測的最先进技術。
它有三種主要類型的歸因技術:主要的歸因技術、層歸因技術和神經元歸因技術。
參考文献
https://pytorch.org/tutorials/beginner/introyt/captumyt.html
https://gilberttanner.com/blog/interpreting-pytorch-models-with-captum/
https://arxiv.org/pdf/1805.12233.pdf
https://arxiv.org/pdf/1704.02685.pdf