













Для справки: Проверьте мою предыдущую статью, где я обсуждаю высокую доступность пула соединений, “Высокая доступность пула соединений с CockroachDB и PgCat.”
Мотивация
Балансировщик нагрузки является ключевой частью архитектуры для CockroachDB. Учитывая его важность, я хотел бы обсудить методы, позволяющие преодолеть ситуации с одной точкой отказа.
Общие шаги
- Запустить CockroachDB и HAProxy в Docker
- Запустить нагрузку
- Продемонстрировать устойчивость к сбоям
- Заключение
Пошаговые инструкции
Запустить CockroachDB и HAProxy в Docker
I have a Docker Compose environment with all of the necessary services here. Primarily, we are adding a second instance of HAProxy and overriding the ports not to overlap with the existing load balancer in the base Docker Compose file.
I am in the middle of refactoring my repo to remove redundancy and decided to split up my Compose files into a base docker-compose.yml and any additional services into their own YAML files.
lb2:
container_name: lb2
hostname: lb2
build: haproxy
ports:
- "26001:26000"
- "8082:8080"
- "8083:8081"
depends_on:
- roach-0
- roach-1
- roach-2
Чтобы следовать вместе, вам нужно запустить среду Compose с помощью команды:
docker compose -f docker-compose.yml -f docker-compose-lb-high-availability.yml up -d --build
Вы увидите следующий список сервисов:
✔ Network cockroach-docker_default Created 0.0s ✔ Container client2 Started 0.4s ✔ Container roach-1 Started 0.7s ✔ Container roach-0 Started 0.6s ✔ Container roach-2 Started 0.5s ✔ Container client Started 0.6s ✔ Container init Started 0.9s ✔ Container lb2 Started 1.1s ✔ Container lb Started
Схема ниже отображает всю топологию кластера:
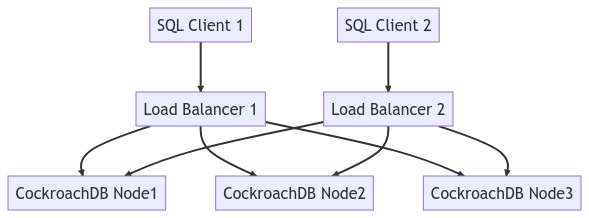
Запустить нагрузку
На данном этапе мы можем подключиться к одному из клиентов и инициализировать нагрузку. Я использую tpcc, так как это хорошая нагрузка для демонстрации записи и чтения трафика.
cockroach workload fixtures import tpcc --warehouses=10 'postgresql://root@lb:26000/tpcc?sslmode=disable'
Затем мы можем запустить нагрузку с обоих контейнеров клиентов.
- Балансировщик нагрузки 1:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable'
- Балансировщик нагрузки 2:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
Вы увидите вывод, аналогичный этому.
488.0s 0 1.0 2.1 44.0 44.0 44.0 44.0 newOrder 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 488.0s 0 2.0 2.1 11.0 16.8 16.8 16.8 payment 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel 489.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 delivery 489.0s 0 2.0 2.1 15.2 17.8 17.8 17.8 newOrder 489.0s 0 1.0 0.2 5.8 5.8 5.8 5.8 orderStatus
Логи для каждой инстанции HAProxy покажут что-то вроде этого.
192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/0 28724 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/816 28846 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:40.744] stats stats/<STATS> 0/0/553 28900 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:41.297] stats stats/<STATS> 0/0/1545 28898 LR 2/2/0/0/0 0/0 192.168.160.1:60582 [27/Apr/2023:14:51:39.927] stats stats/<NOSRV> -1/-1/61858 0 CR 2/2/0/0/0 0/0
HAProxy предоставляет веб-интерфейс на порту 8081. Так как у нас есть две инстанции HAProxy, я разместил вторую инстанцию на порту 8083.
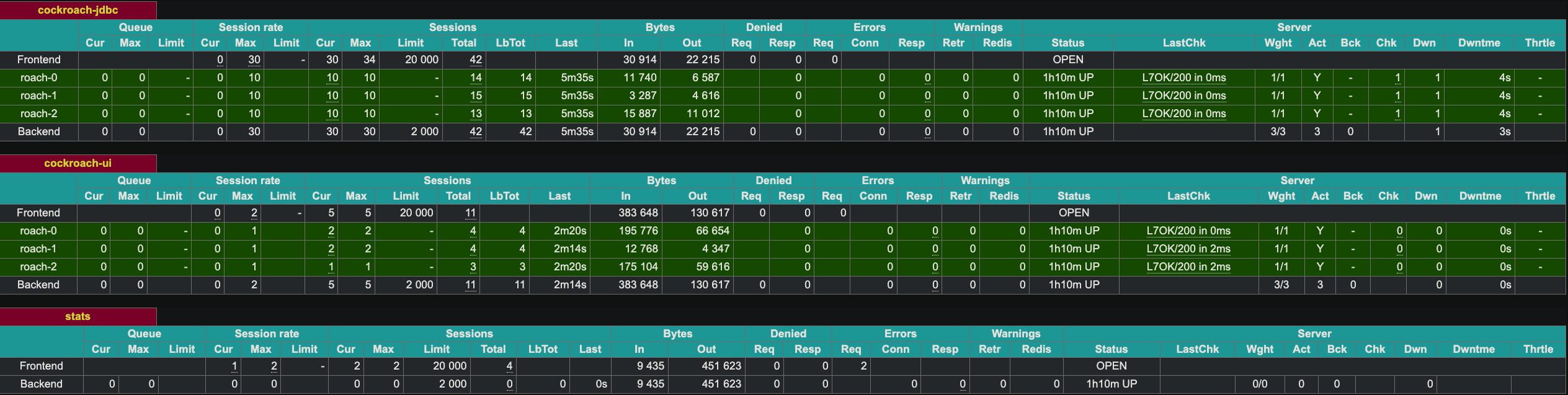
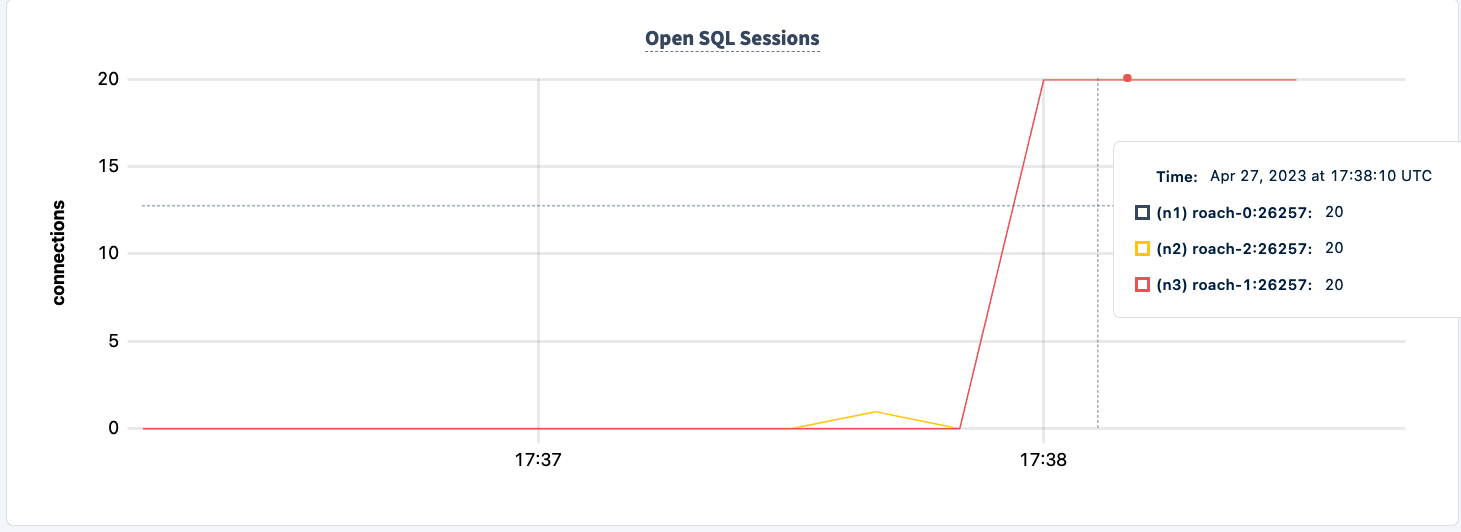
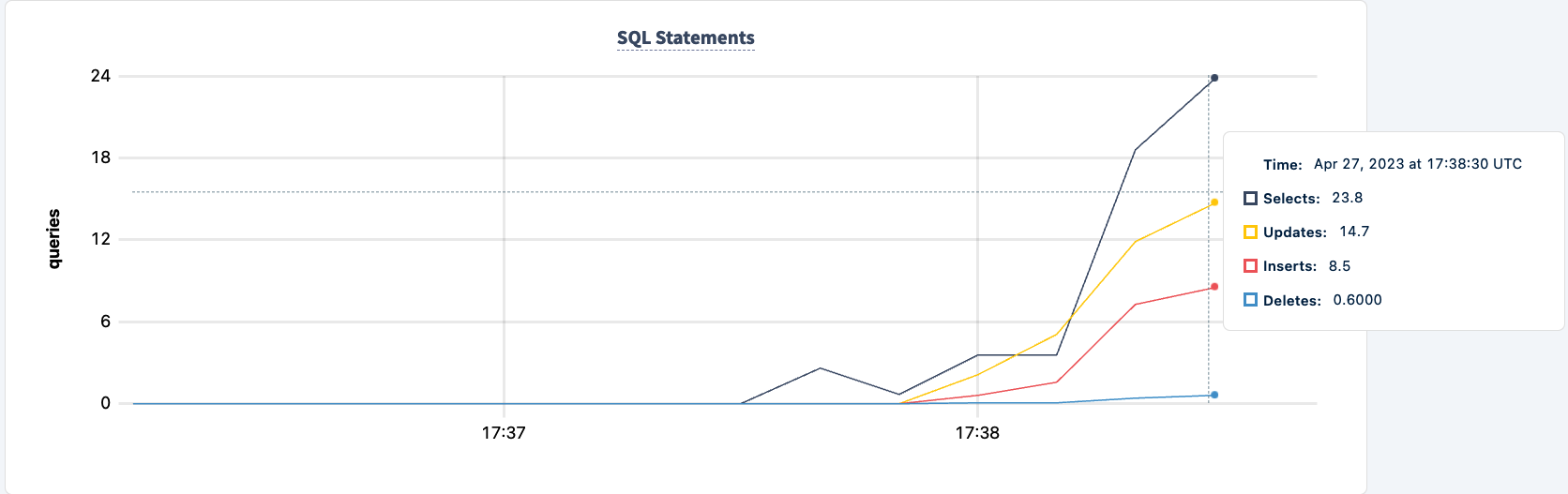
Демонстрация устойчивости к сбоям
Теперь мы можем начать завершение работы инстанций HAProxy для демонстрации устойчивости к сбоям. Начнем с инстанции 1.
docker kill lb lb
Нагрузка начнет выдавать сообщения об ошибках.
7 17:41:18.758669 357 workload/pgx_helpers.go:79 [-] 60 + RETURNING d_tax, d_next_o_id] W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 error preparing statement. name=new-order-1 sql= W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + UPDATE district W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + SET d_next_o_id = d_next_o_id + 1 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + WHERE d_w_id = $1 AND d_id = $2 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + RETURNING d_tax, d_next_o_id unexpected EOF 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 delivery 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 newOrder 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 payment
Наша нагрузка все еще работает через соединение HAProxy 2.
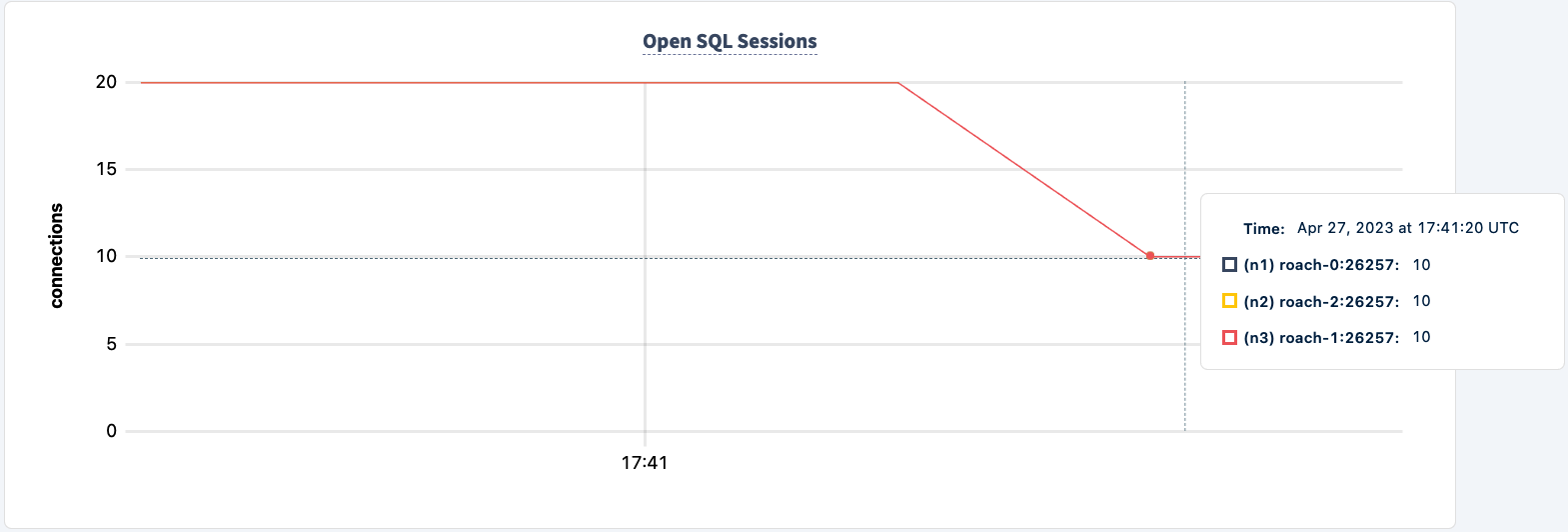
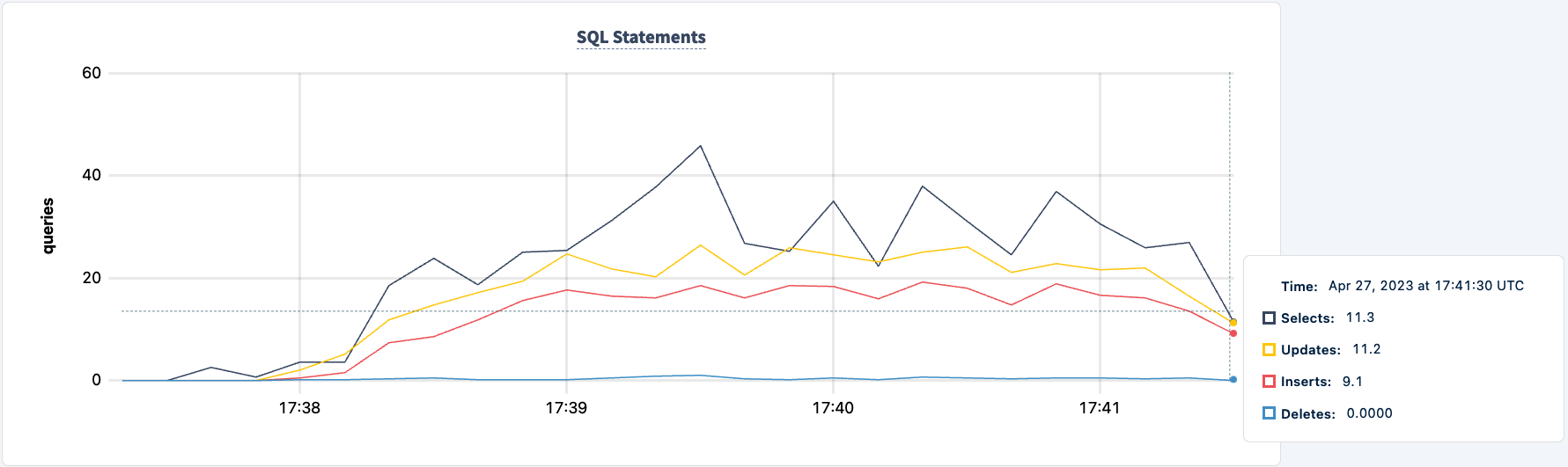
Давайте вернем его в рабочее состояние:
docker start lb
Заметьте, как клиент переподключается и продолжает работу с нагрузкой.
335.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 336.0s 1780 7.0 1.1 19.9 27.3 27.3 27.3 newOrder 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 orderStatus 336.0s 1780 2.0 1.0 10.5 11.0 11.0 11.0 payment 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel 337.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 337.0s 1780 7.0 1.1 21.0 32.5 32.5 32.5 ne
Количество выполненных операций увеличивается после успешного подключения второго клиента.
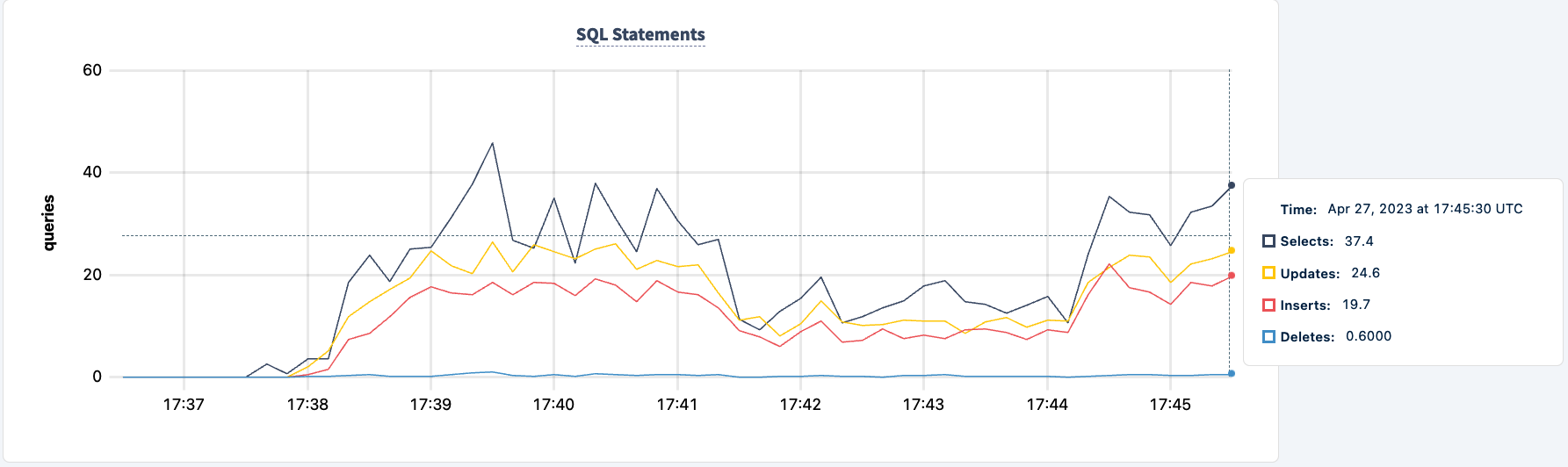
Теперь мы можем проделать то же самое со второй инстанцией. Аналогично, нагрузка сообщает об ошибках, что не может найти хост lb2.
0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:48:28.239032 403 workload/pgx_helpers.go:79 [-] 188 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host] I230427 17:48:28.267355 357 workload/pgx_helpers.go:79 [-] 189 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host]
И мы можем наблюдать спад в количестве выполненных операций.
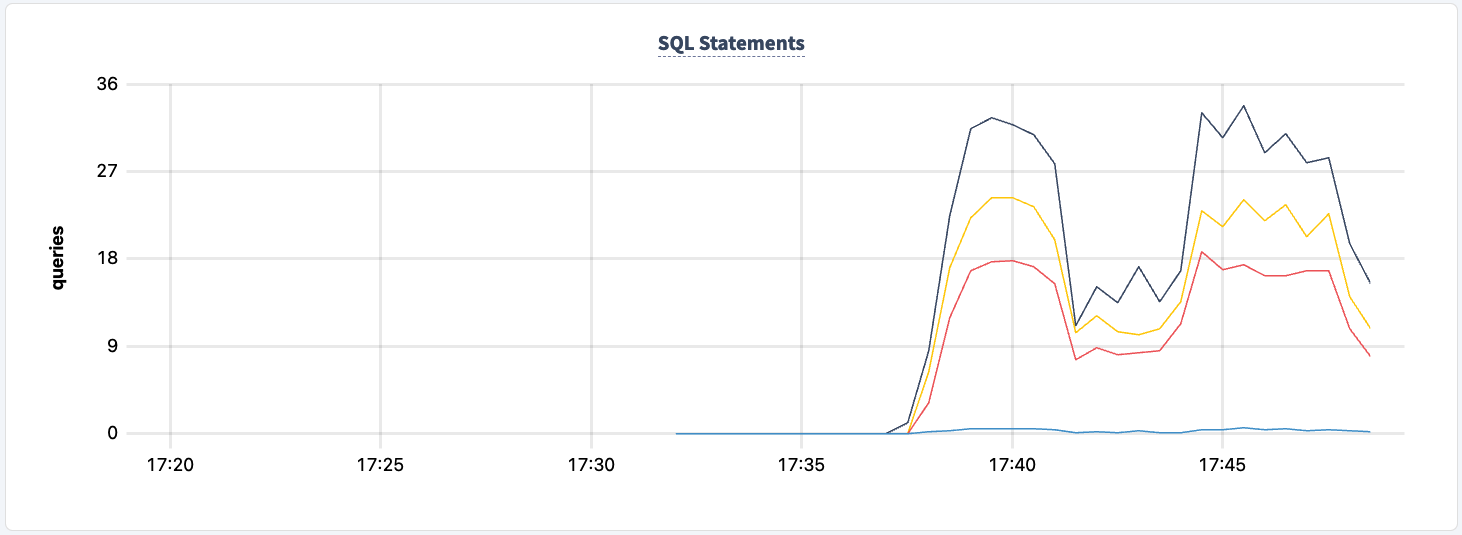
Мы можем вернуть его в рабочее состояние:
docker start lb2
Одно из улучшений, которое мы можем внести, это запуск нагрузки с обеими строками подключения. Это позволит каждому клиенту переключаться на другую инстанцию pgurl, даже если одна из инстанций HAProxy вышла из строя. Нам нужно будет остановить обоих клиентов и перезапустить их с обеими строками подключения.
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable' 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
I am going to do that one client at a time so that the workload does not exit completely.
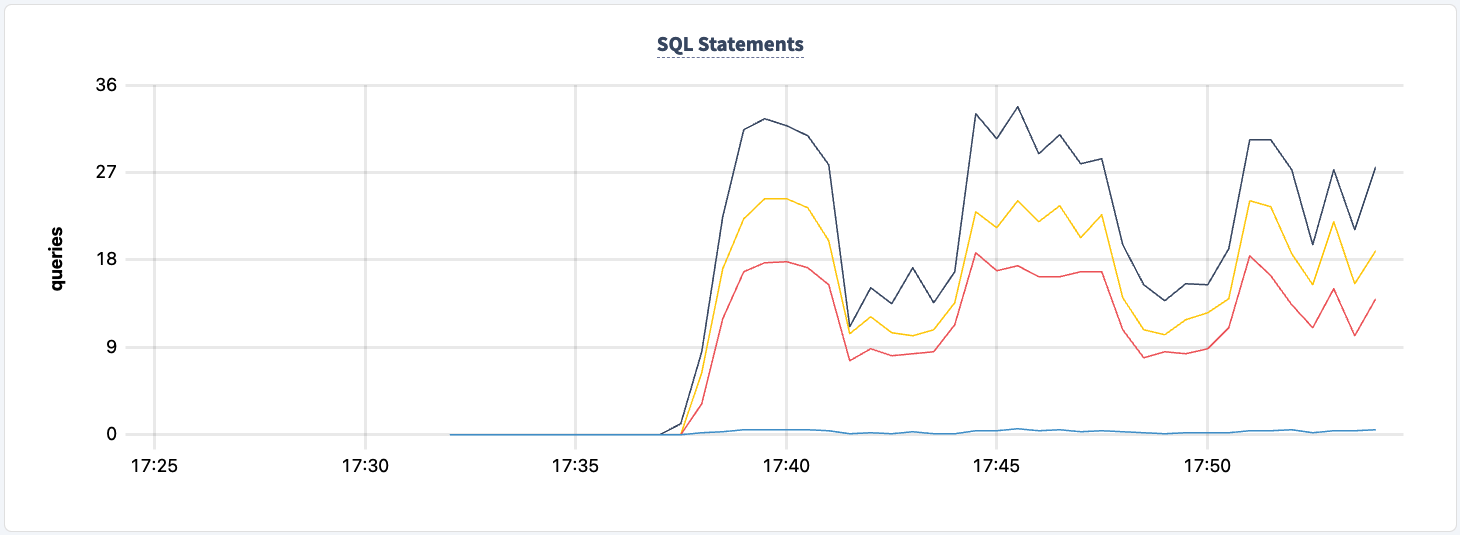
Ни в один момент этого эксперимента мы не теряли возможности читать/писать в кластер. Давайте снова отключим одну из инстанций HAProxy и посмотрим на воздействие.
docker kill lb lb
I’m now seeing errors across both clients, but both clients are still executing.
.817268 1 workload/cli/run.go:548 [-] 85 error in stockLevel: lookup lb on 127.0.0.11:53: no such host _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 delivery 156.0s 49 1.0 2.1 31.5 31.5 31.5 31.5 newOrder 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 156.0s 49 1.0 2.0 12.1 12.1 12.1 12.1 payment 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:55:58.558209 354 workload/pgx_helpers.go:79 [-] 86 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.698731 346 workload/pgx_helpers.go:79 [-] 87 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.723643 386 workload/pgx_helpers.go:79 [-] 88 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.726639 370 workload/pgx_helpers.go:79 [-] 89 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.789717 364 workload/pgx_helpers.go:79 [-] 90 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.841283 418 workload/pgx_helpers.go:79 [-] 91 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host]
Мы можем вернуть ее в рабочее состояние и заметить, как нагрузка восстанавливается.
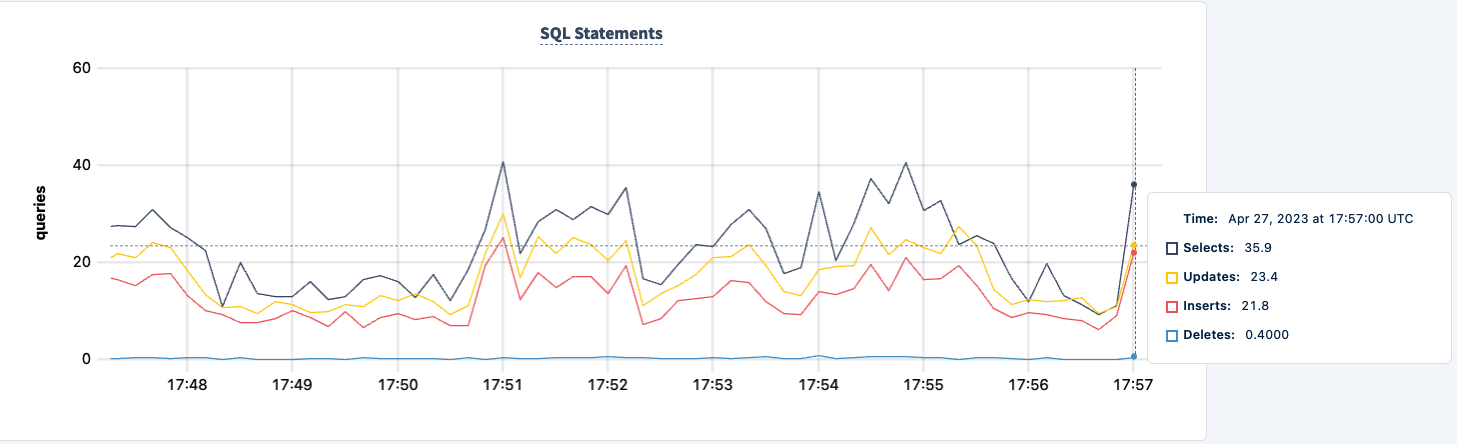
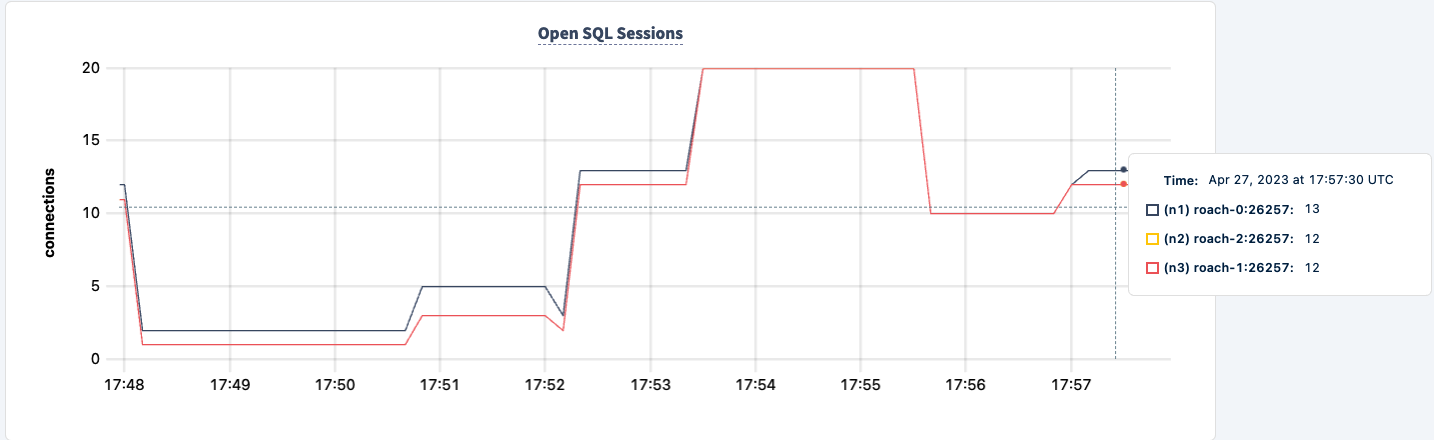
Заключение
На протяжении эксперимента мы не потеряли возможность читать и записывать в базу данных. Были падения трафика, но это ожидаемо. Урок здесь заключается в обеспечении высокодоступной конфигурации, где клиенты могут видеть несколько соединений.
Source:
https://dzone.com/articles/load-balancer-high-availability-with-cockroachdb-a