













참고: 접속 풀 고가용성에 대해 논의한 이전 기사를 확인하세요. “CockroachDB와 PgCat를 사용한 접속 풀 고가용성.”
동기
로드 밸런서는 CockroachDB의 핵심 아키텍처 요소입니다. 그 중요성 때문에 SPOF 시나리오를 극복하기 위한 방법에 대해 논의하고 싶습니다.
고도화된 단계
- Docker에서 CockroachDB와 HAProxy 시작
- 작업 부하 실행
- 고장 내성 입증
- 결론
절차 대로 지침
Docker에서 CockroachDB와 HAProxy 시작
I have a Docker Compose environment with all of the necessary services here. Primarily, we are adding a second instance of HAProxy and overriding the ports not to overlap with the existing load balancer in the base Docker Compose file.
I am in the middle of refactoring my repo to remove redundancy and decided to split up my Compose files into a base docker-compose.yml and any additional services into their own YAML files.
lb2:
container_name: lb2
hostname: lb2
build: haproxy
ports:
- "26001:26000"
- "8082:8080"
- "8083:8081"
depends_on:
- roach-0
- roach-1
- roach-2
따라가려면 다음 명령으로 컴포즈 환경을 시작해야 합니다.
docker compose -f docker-compose.yml -f docker-compose-lb-high-availability.yml up -d --build
다음 서비스 목록이 표시됩니다.
✔ Network cockroach-docker_default Created 0.0s ✔ Container client2 Started 0.4s ✔ Container roach-1 Started 0.7s ✔ Container roach-0 Started 0.6s ✔ Container roach-2 Started 0.5s ✔ Container client Started 0.6s ✔ Container init Started 0.9s ✔ Container lb2 Started 1.1s ✔ Container lb Started
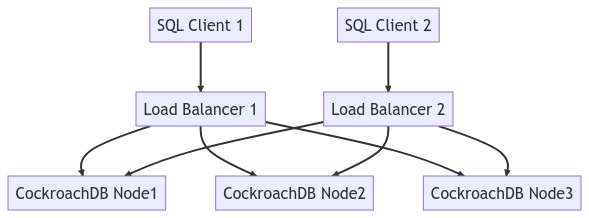
아래 다이어그램은 전체 클러스터 토폴로지를 나타냅니다.
작업 부하 실행
이 시점에서 클라이언트 중 하나에 연결하여 작업 부하를 초기화할 수 있습니다. 쓰기 및 읽기 트래픽을 보여주기에 좋은 작업 부하이기 때문에 tpcc를 사용하고 있습니다.
cockroach workload fixtures import tpcc --warehouses=10 'postgresql://root@lb:26000/tpcc?sslmode=disable'
그런 다음 두 클라이언트 컨테이너에서 작업 부하를 시작할 수 있습니다.
- 로드 밸런서 1:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable'
- 로드 밸런서 2:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
다음과 유사한 출력이 표시됩니다.
488.0s 0 1.0 2.1 44.0 44.0 44.0 44.0 newOrder 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 488.0s 0 2.0 2.1 11.0 16.8 16.8 16.8 payment 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel 489.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 delivery 489.0s 0 2.0 2.1 15.2 17.8 17.8 17.8 newOrder 489.0s 0 1.0 0.2 5.8 5.8 5.8 5.8 orderStatus
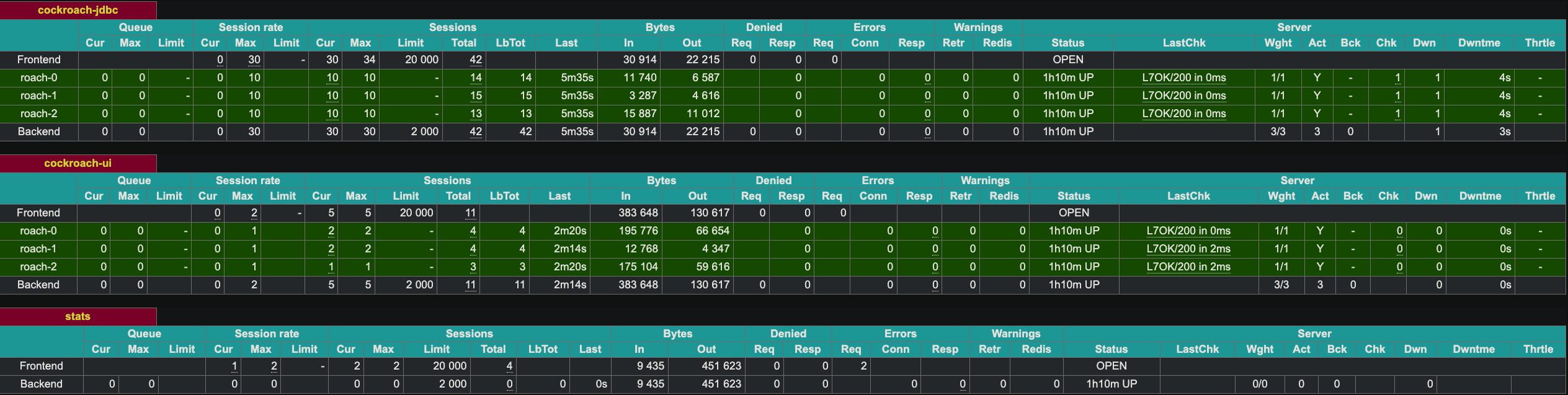
HAProxy의 각 인스턴스에 대한 로그는 다음과 같은 내용을 보여줍니다.
192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/0 28724 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/816 28846 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:40.744] stats stats/<STATS> 0/0/553 28900 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:41.297] stats stats/<STATS> 0/0/1545 28898 LR 2/2/0/0/0 0/0 192.168.160.1:60582 [27/Apr/2023:14:51:39.927] stats stats/<NOSRV> -1/-1/61858 0 CR 2/2/0/0/0 0/0
HAProxy는 포트 8081에서 웹 UI를 공개합니다. HAProxy의 두 번째 인스턴스는 포트 8083에서 공개했습니다.
고장 허용 시연
이제 HAProxy 인스턴스를 종료하여 고장 허용 기능을 시연할 수 있습니다. 인스턴스 1부터 시작하겠습니다.
docker kill lb lb
작업이 오류 메시지를 생성하기 시작합니다.
7 17:41:18.758669 357 workload/pgx_helpers.go:79 [-] 60 + RETURNING d_tax, d_next_o_id] W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 error preparing statement. name=new-order-1 sql= W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + UPDATE district W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + SET d_next_o_id = d_next_o_id + 1 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + WHERE d_w_id = $1 AND d_id = $2 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + RETURNING d_tax, d_next_o_id unexpected EOF 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 delivery 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 newOrder 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 payment
작업은 여전히 HAProxy 2 연결을 사용하여 실행되고 있습니다.
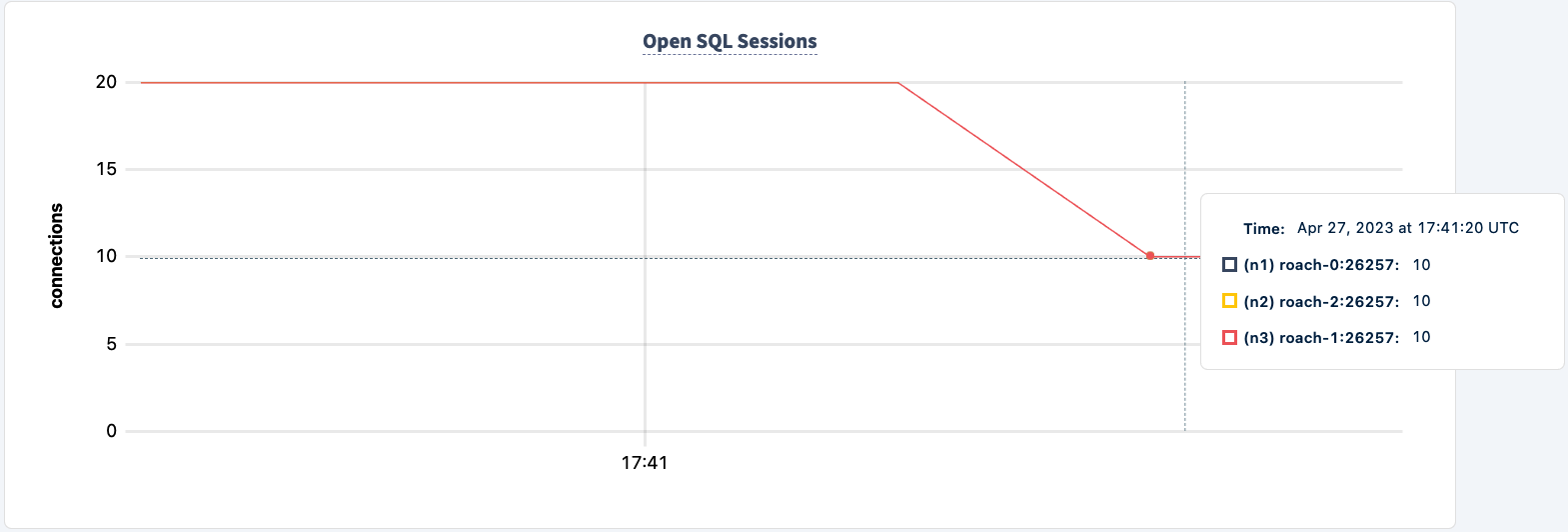
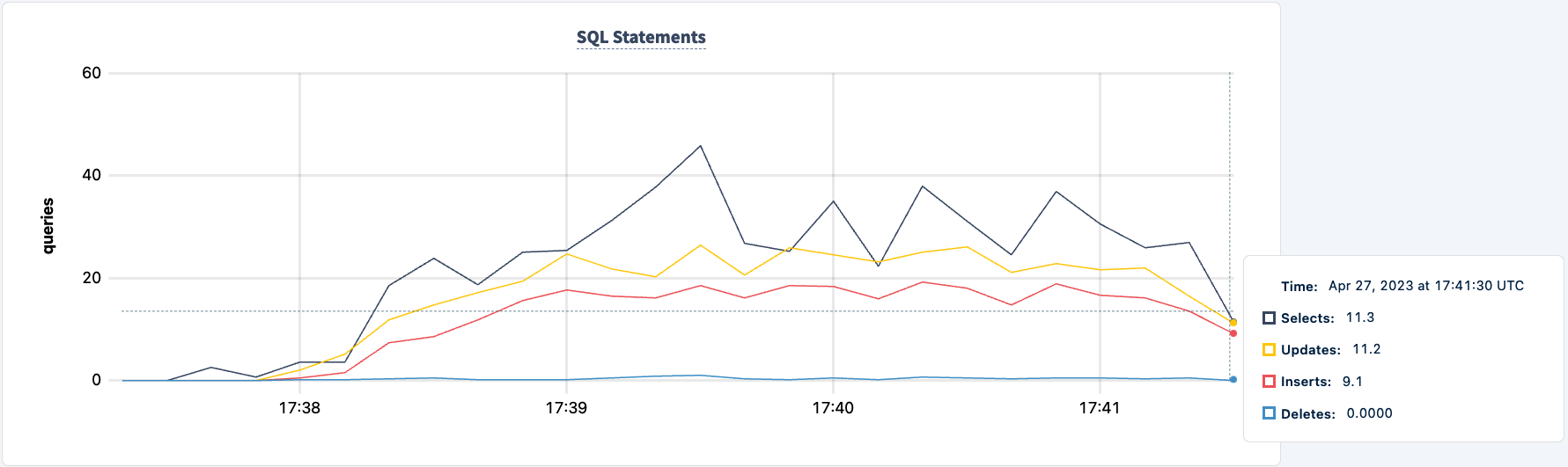
다시 시작하겠습니다:
docker start lb
클라이언트가 재연결되어 작업을 계속합니다.
335.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 336.0s 1780 7.0 1.1 19.9 27.3 27.3 27.3 newOrder 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 orderStatus 336.0s 1780 2.0 1.0 10.5 11.0 11.0 11.0 payment 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel 337.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 337.0s 1780 7.0 1.1 21.0 32.5 32.5 32.5 ne
두 번째 클라이언트가 성공적으로 연결되면 실행된 문 수가 증가합니다.
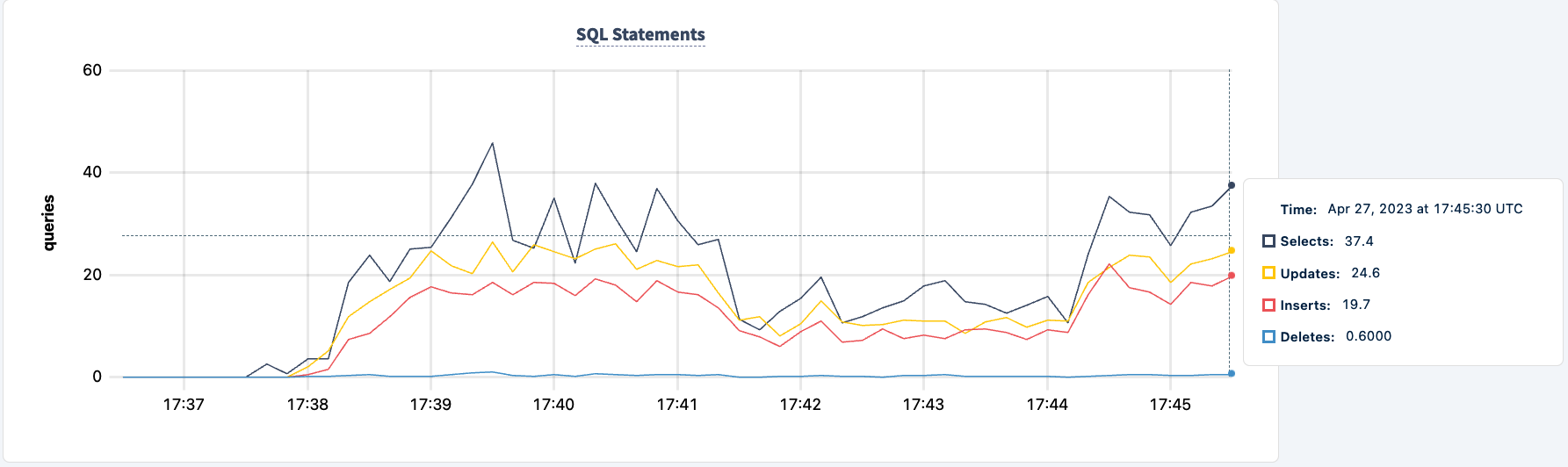
이제 두 번째 인스턴스에 대해서도 동일한 작업을 수행할 수 있습니다. 마찬가지로 작업이 lb2 호스트를 찾을 수 없다고 오류 보고합니다.
0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:48:28.239032 403 workload/pgx_helpers.go:79 [-] 188 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host] I230427 17:48:28.267355 357 workload/pgx_helpers.go:79 [-] 189 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host]
문 개수의 감소를 관찰할 수 있습니다.
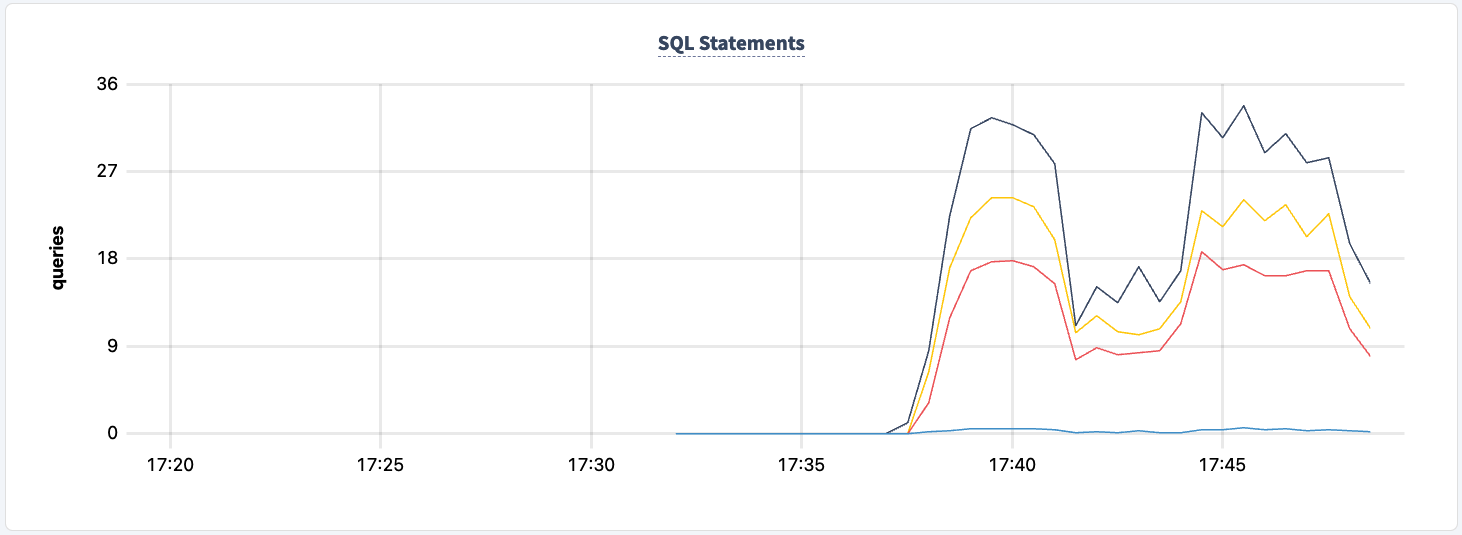
다시 시작할 수 있습니다:
docker start lb2
개선할 수 있는 한 가지는 두 개의 연결 문자열로 작업을 시작하는 것입니다. 하나의 HAProxy 인스턴스가 다운되어도 각 클라이언트가 pgurl의 다른 인스턴스로 장애 복구할 수 있게 해줍니다. 해야 할 일은 두 클라이언트를 모두 중지하고 두 개의 연결 문자열로 다시 시작하는 것입니다.
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable' 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
I am going to do that one client at a time so that the workload does not exit completely.
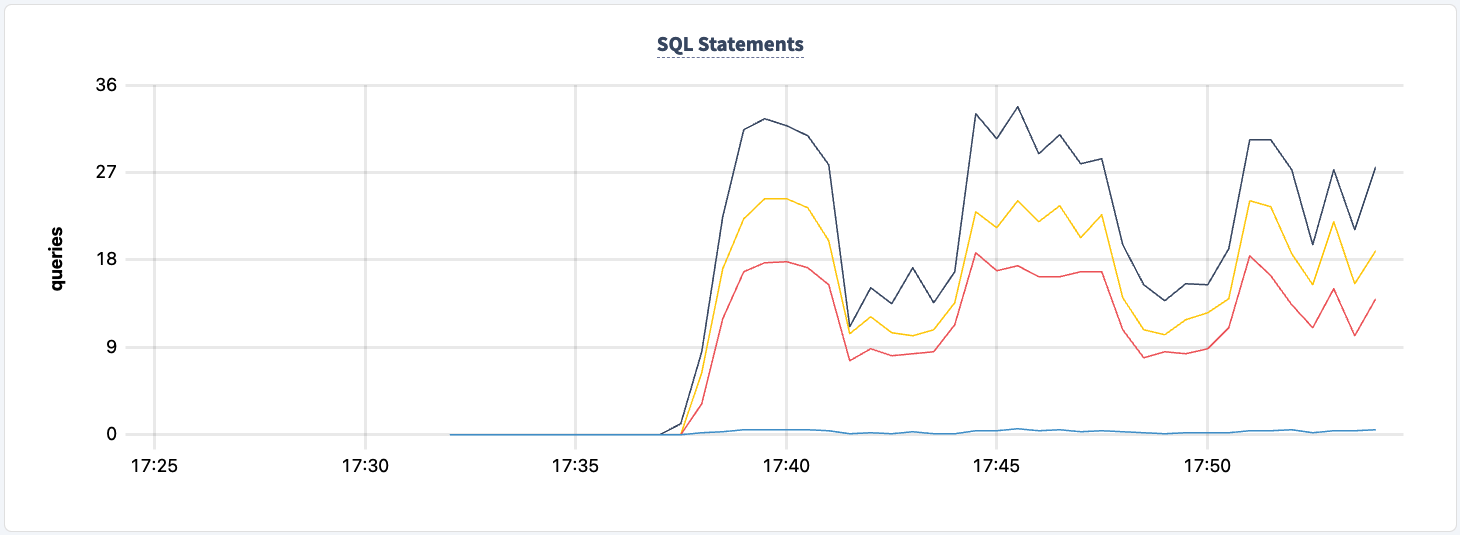
이 실험의 어느 시점에서도 클러스터와의 읽기/쓰기 기능을 잃지 않았습니다. HAProxy 인스턴스 중 하나를 다시 종료하여 영향을 살펴보겠습니다.
docker kill lb lb
I’m now seeing errors across both clients, but both clients are still executing.
.817268 1 workload/cli/run.go:548 [-] 85 error in stockLevel: lookup lb on 127.0.0.11:53: no such host _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 delivery 156.0s 49 1.0 2.1 31.5 31.5 31.5 31.5 newOrder 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 156.0s 49 1.0 2.0 12.1 12.1 12.1 12.1 payment 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:55:58.558209 354 workload/pgx_helpers.go:79 [-] 86 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.698731 346 workload/pgx_helpers.go:79 [-] 87 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.723643 386 workload/pgx_helpers.go:79 [-] 88 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.726639 370 workload/pgx_helpers.go:79 [-] 89 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.789717 364 workload/pgx_helpers.go:79 [-] 90 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.841283 418 workload/pgx_helpers.go:79 [-] 91 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host]
다시 시작하면 작업이 복구되는 것을 확인할 수 있습니다.
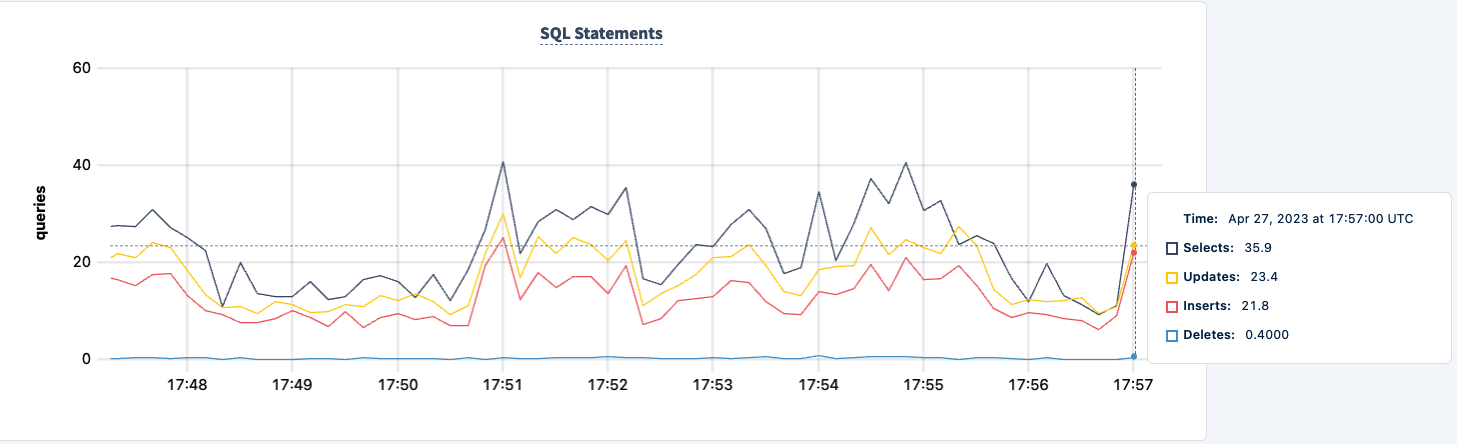
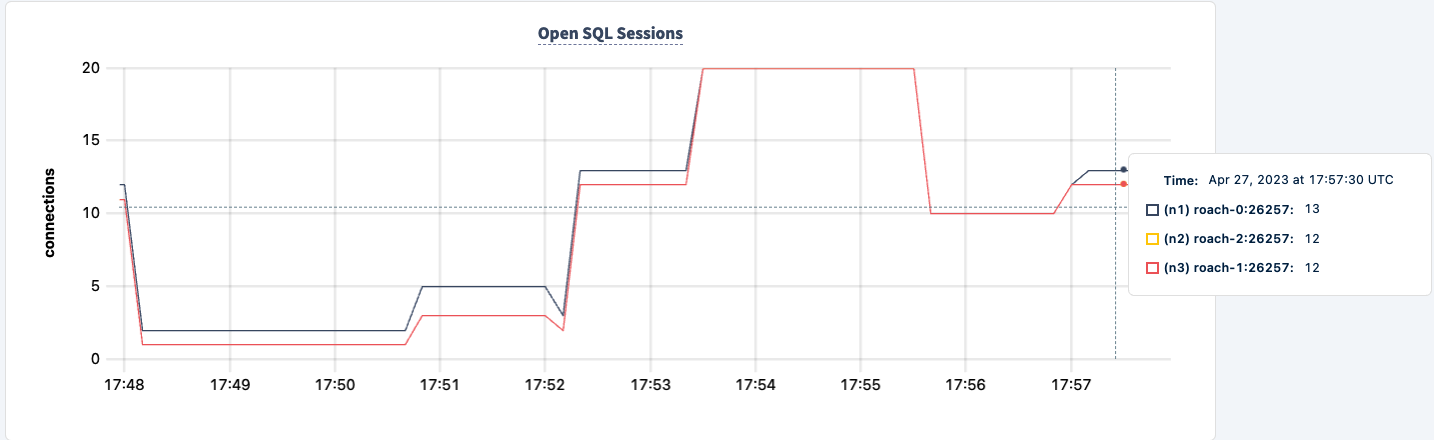
결론
실험 전반에 걸쳐 데이터베이스에 대한 읽기와 쓰기 기능을 잃지 않았습니다. 트래픽이 감소한 경우도 있었지만, 이는 예상되는 현상입니다. 여기서의 교훈은 클라이언트가 여러 연결을 볼 수 있는 고가용성 구성을 제공하는 것입니다.
Source:
https://dzone.com/articles/load-balancer-high-availability-with-cockroachdb-a