













לציבור: תראה את המאמר הקודם שלי שבו אני דנה באסטרטגיית גישה גבוהה לבריכת חיבורים, "Connection Pool High Availability With CockroachDB and PgCat."
השראה
מנוע התפלוגות הוא חלק מרכזי בארכיטקטורת CockroachDB. בהתחשב בחשיבותו, אני רוצה לדון בשיטות להתגברות על תרחישי SPOF.
צעדים ברמה גבוהה
- התחל את CockroachDB ו-HAProxy ב-Docker
- הרץ עבודה
- הדגים חוסן עלות
- מסקנה
הוראות צעד-אחר-צעד
התחל את CockroachDB ו-HAProxy ב-Docker
I have a Docker Compose environment with all of the necessary services here. Primarily, we are adding a second instance of HAProxy and overriding the ports not to overlap with the existing load balancer in the base Docker Compose file.
I am in the middle of refactoring my repo to remove redundancy and decided to split up my Compose files into a base docker-compose.yml and any additional services into their own YAML files.
lb2:
container_name: lb2
hostname: lb2
build: haproxy
ports:
- "26001:26000"
- "8082:8080"
- "8083:8081"
depends_on:
- roach-0
- roach-1
- roach-2
כדי לעקוב אחרינו, עליך להתחיל את סביבת ה-Compose עם הפקודה:
docker compose -f docker-compose.yml -f docker-compose-lb-high-availability.yml up -d --build
תראה את הרשימה הבאה של שירותים:
✔ Network cockroach-docker_default Created 0.0s ✔ Container client2 Started 0.4s ✔ Container roach-1 Started 0.7s ✔ Container roach-0 Started 0.6s ✔ Container roach-2 Started 0.5s ✔ Container client Started 0.6s ✔ Container init Started 0.9s ✔ Container lb2 Started 1.1s ✔ Container lb Started
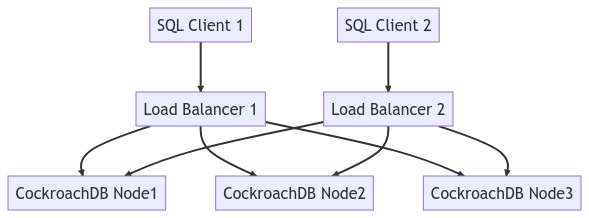
התרשים למטה מתאר את כל מבנה המבוזר:
הרץ עבודה
בשלב זה, אנו יכולים להתחבר לאחד הלקוחות ולאתחל את העבודה. אני משתמש ב-tpcc מכיוון שזו עבודה טובה להדגמת תנועת כתיבה וקריאה.
cockroach workload fixtures import tpcc --warehouses=10 'postgresql://root@lb:26000/tpcc?sslmode=disable'
ואז אנו יכולים להתחיל את העבודה משני מיכלי הלקוח.
- מנוע התפלוגות 1:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable'
- מנוע התפלוגות 2:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
תראה פלט דומה לזה.
488.0s 0 1.0 2.1 44.0 44.0 44.0 44.0 newOrder 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 488.0s 0 2.0 2.1 11.0 16.8 16.8 16.8 payment 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel 489.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 delivery 489.0s 0 2.0 2.1 15.2 17.8 17.8 17.8 newOrder 489.0s 0 1.0 0.2 5.8 5.8 5.8 5.8 orderStatus
היישומים של כל מופע של HAProxy יראו משהו כזה:
192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/0 28724 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/816 28846 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:40.744] stats stats/<STATS> 0/0/553 28900 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:41.297] stats stats/<STATS> 0/0/1545 28898 LR 2/2/0/0/0 0/0 192.168.160.1:60582 [27/Apr/2023:14:51:39.927] stats stats/<NOSRV> -1/-1/61858 0 CR 2/2/0/0/0 0/0
HAProxy מחשף ממשק אינטרנט בפורט 8081. מאחר ויש לנו שתי מופעים של HAProxy, הוצגתי את המופע השני בפורט 8083.
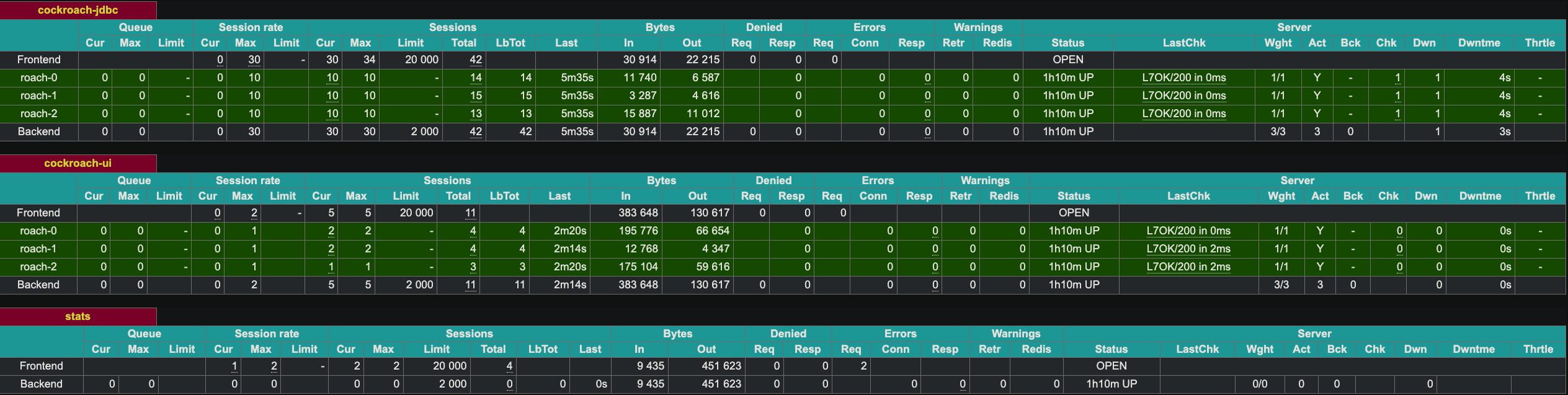
הפצת עמידות לכשלים
כעת נוכל להתחיל בסיום מופעי HAProxy כדי להדגים עמידות לכשלים. בואו נתחיל עם מופע 1.
docker kill lb lb
העבודה תתחיל ליצור הודעות שגיאה.
7 17:41:18.758669 357 workload/pgx_helpers.go:79 [-] 60 + RETURNING d_tax, d_next_o_id] W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 error preparing statement. name=new-order-1 sql= W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + UPDATE district W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + SET d_next_o_id = d_next_o_id + 1 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + WHERE d_w_id = $1 AND d_id = $2 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + RETURNING d_tax, d_next_o_id unexpected EOF 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 delivery 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 newOrder 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 payment
העבודה שלנו עדיין פועלת באמצעות חיבור HAProxy 2.
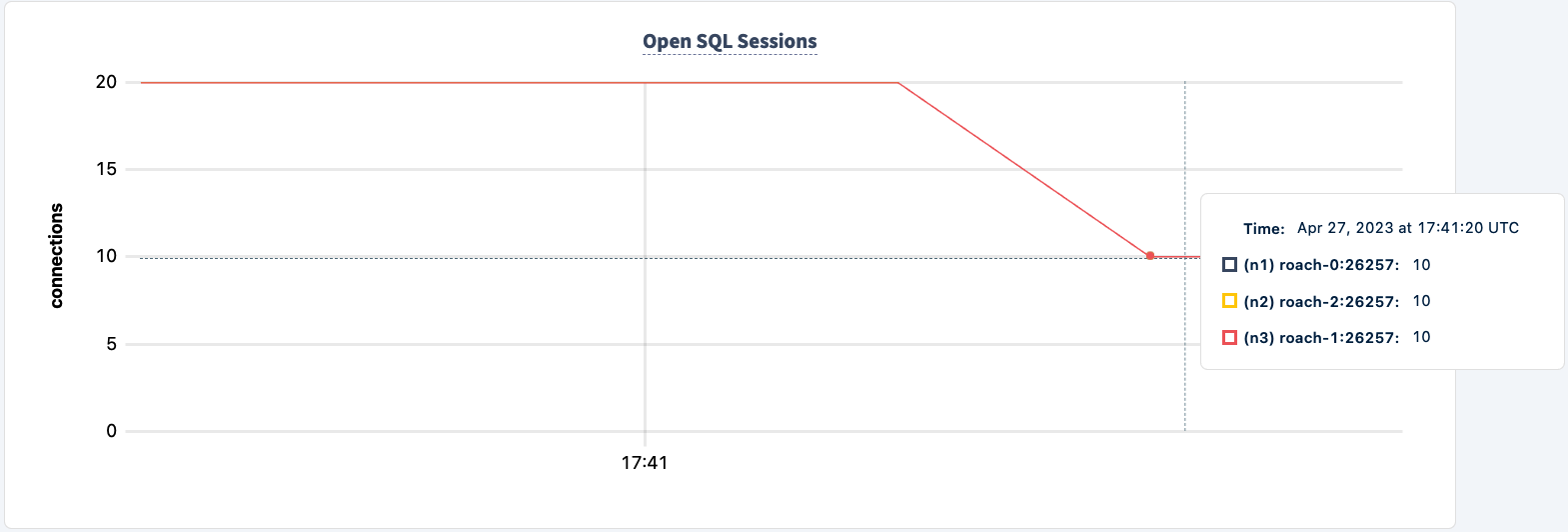
בואו נחזיר אותו לתחום:
docker start lb
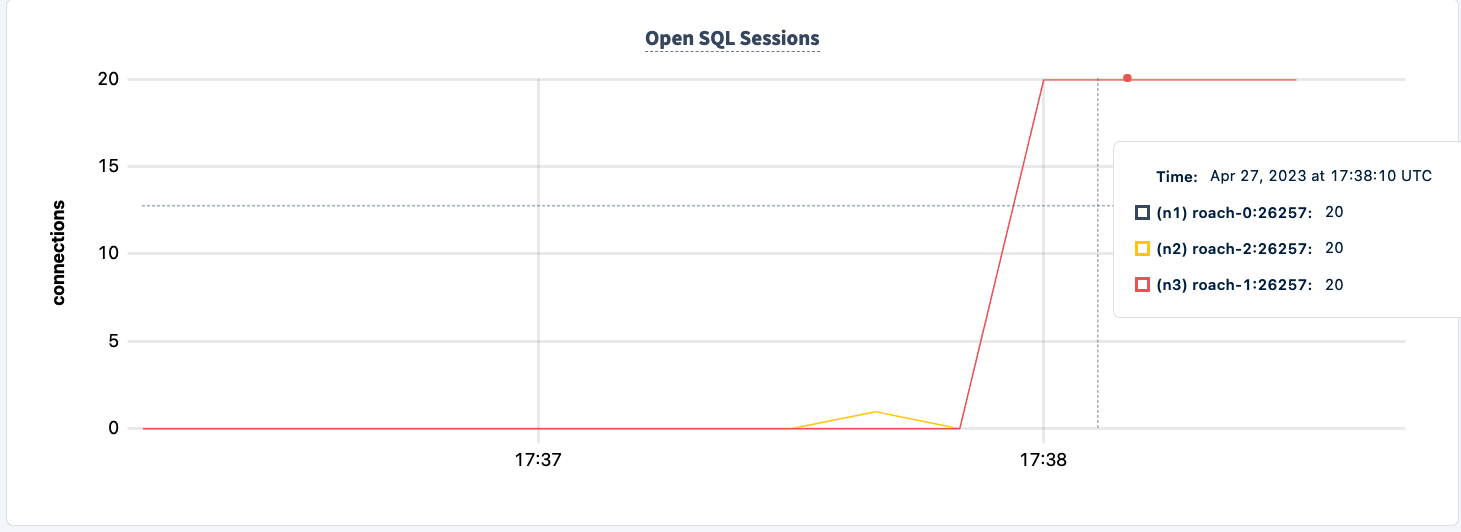
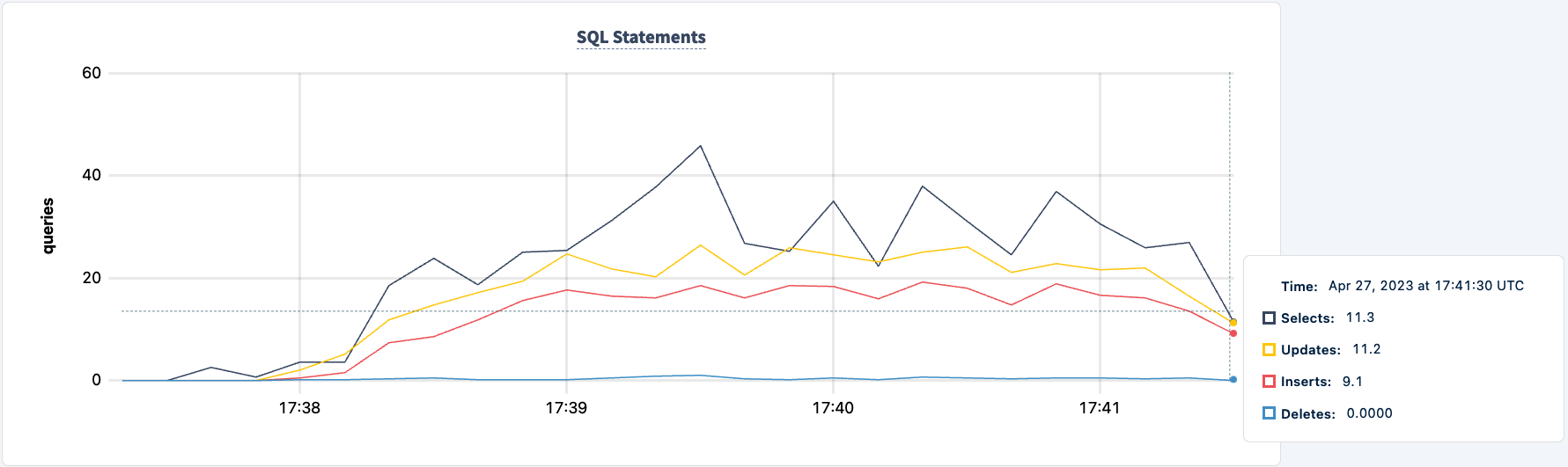
שימו לב שהלקוח מתחבר מחדש וממשיך עם העבודה.
335.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 336.0s 1780 7.0 1.1 19.9 27.3 27.3 27.3 newOrder 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 orderStatus 336.0s 1780 2.0 1.0 10.5 11.0 11.0 11.0 payment 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel 337.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 337.0s 1780 7.0 1.1 21.0 32.5 32.5 32.5 ne
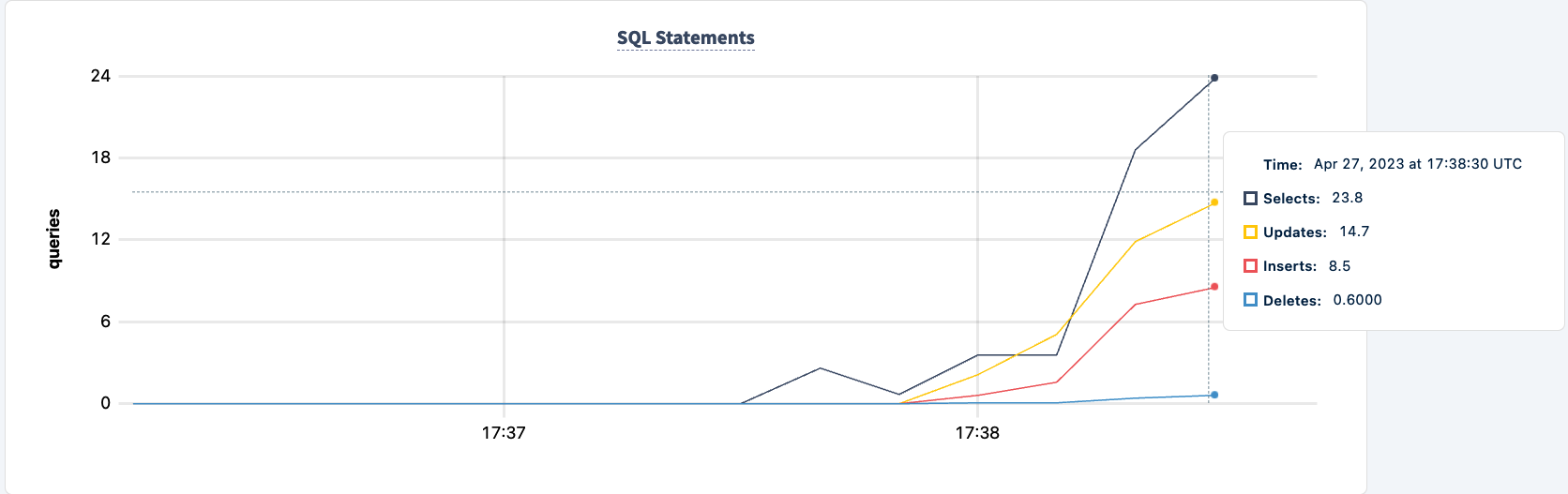
מספר ההצהרות שנבצעו עולה כאשר הלקוח השני מתחבר בהצלחה.
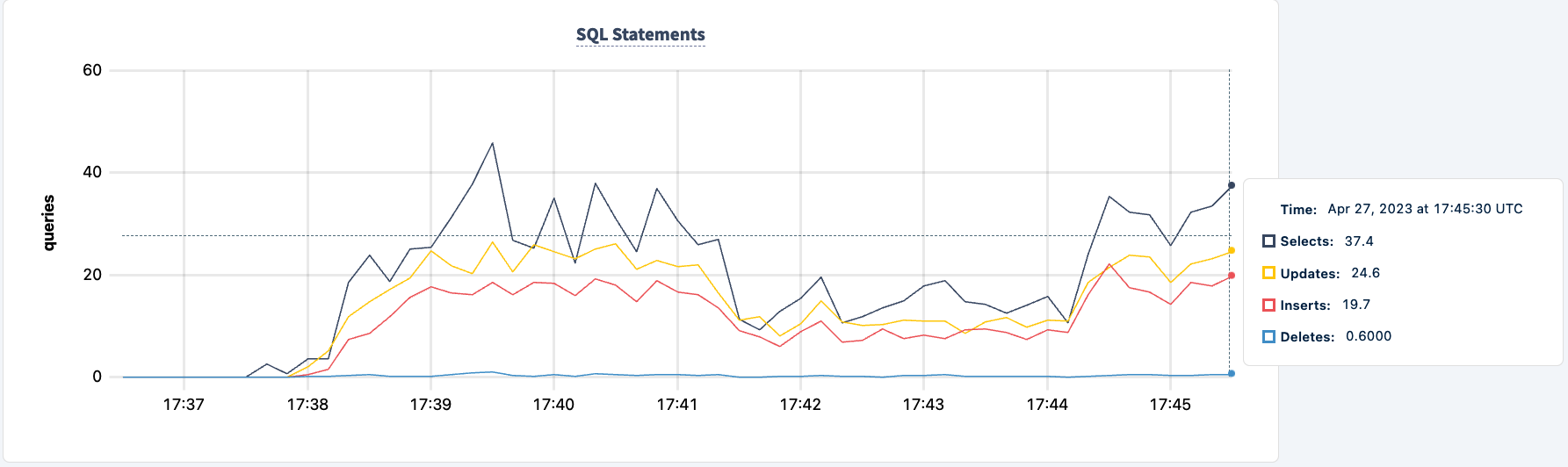
כעת נוכל לעשות את אותו הדבר עם המופע השני. באופן דומה, העבודה מדווחת על שגיאות שהיא לא יכולה למצוא את ה-lb2 host.
0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:48:28.239032 403 workload/pgx_helpers.go:79 [-] 188 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host] I230427 17:48:28.267355 357 workload/pgx_helpers.go:79 [-] 189 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host]
ואנו יכולים להבחין בירידה במספר ההצהרות.
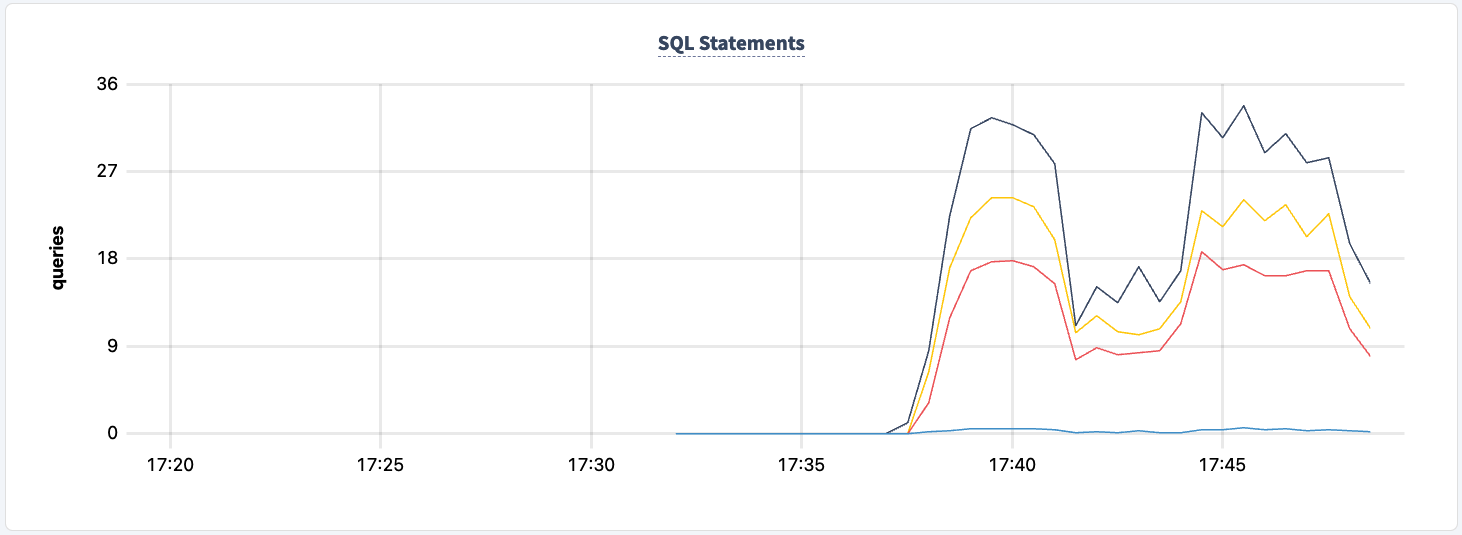
אנו יכולים להחזיר אותו לתחום:
docker start lb2
דבר אחד שנוכל לשפר הוא להתחיל את העבודה עם שני מחרוזות חיבור. זה יאפשר לכל לקוח להתחדש בחזרה למופע אחר של pgurl גם כשאחד ממופעי HAProxy מופסק. מה שעלינו לעשות הוא להפסיק את שני הלקוחות ולהתחיל מחדש עם שתי מחרוזות החיבור.
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable' 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
I am going to do that one client at a time so that the workload does not exit completely.
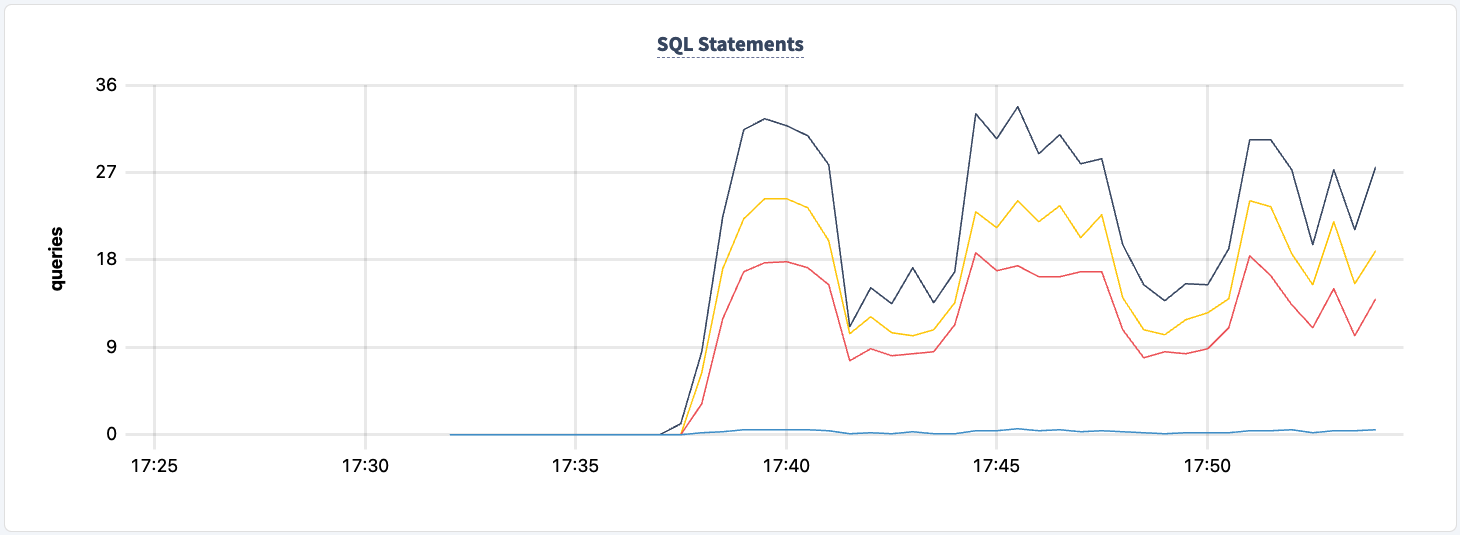
בשום שלב בניסוי זה לא איבדנו את היכולת לקרוא/לכתוב לגדר וממנו. בואו נכבה את אחד ממופעי HAProxy שוב ונראה את ההשפעה.
docker kill lb lb
I'm now seeing errors across both clients, but both clients are still executing.
.817268 1 workload/cli/run.go:548 [-] 85 error in stockLevel: lookup lb on 127.0.0.11:53: no such host _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 delivery 156.0s 49 1.0 2.1 31.5 31.5 31.5 31.5 newOrder 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 156.0s 49 1.0 2.0 12.1 12.1 12.1 12.1 payment 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:55:58.558209 354 workload/pgx_helpers.go:79 [-] 86 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.698731 346 workload/pgx_helpers.go:79 [-] 87 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.723643 386 workload/pgx_helpers.go:79 [-] 88 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.726639 370 workload/pgx_helpers.go:79 [-] 89 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.789717 364 workload/pgx_helpers.go:79 [-] 90 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.841283 418 workload/pgx_helpers.go:79 [-] 91 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host]
אנו יכולים להחזיר אותו לתחום ולשים לב שהעבודה מתאוששת.
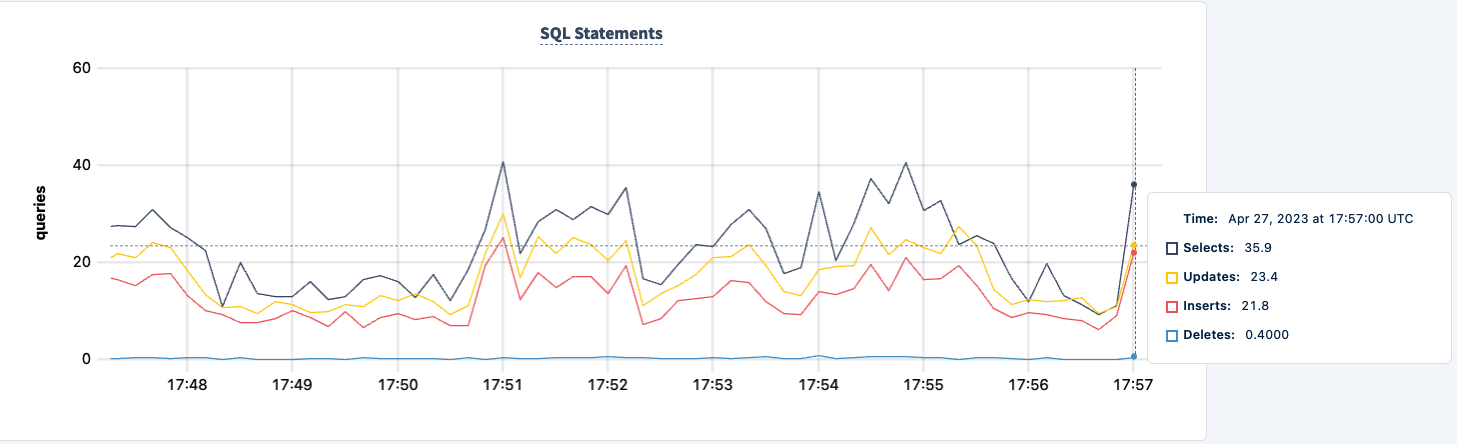
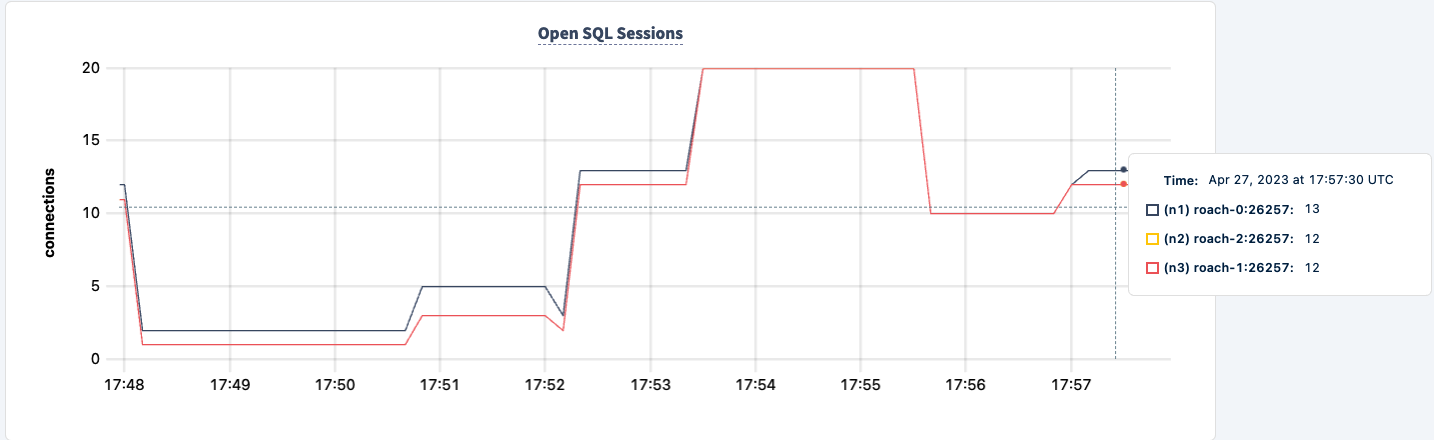
מסקנה
במהלך הניסוי, לא אבדנו את היכולת לקרוא ולכתוב למסד הנתונים. היו שפירים בזרם התנועה, אך זה צפוי. הלקח כאן הוא מתן תצורה בעלת זמינות גבוהה שבה לקוחות יכולים לראות קישורים מרובים.
Source:
https://dzone.com/articles/load-balancer-high-availability-with-cockroachdb-a