













Voor referentie: Bekijk mijn vorige artikel waar ik het heb over hoge beschikbaarheid van verbindingsgroepen, “Connection Pool High Availability With CockroachDB and PgCat.”
Motivatie
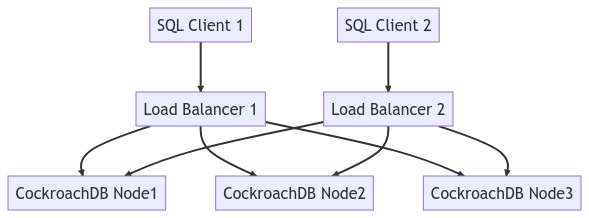
De load balancer is een kernonderdeel van de architectuur voor CockroachDB. Aangezien het van groot belang is, wil ik de methoden bespreken om scenario’s met enkelvoudige punten van falen te overwinnen.
Hoog niveau stappen
- Start CockroachDB en HAProxy in Docker
- Voer een workload uit
- Demonstreer fouttolerantie
- Conclusie
Stapsgewijze instructies
Start CockroachDB en HAProxy in Docker
I have a Docker Compose environment with all of the necessary services here. Primarily, we are adding a second instance of HAProxy and overriding the ports not to overlap with the existing load balancer in the base Docker Compose file.
I am in the middle of refactoring my repo to remove redundancy and decided to split up my Compose files into a base docker-compose.yml and any additional services into their own YAML files.
lb2:
container_name: lb2
hostname: lb2
build: haproxy
ports:
- "26001:26000"
- "8082:8080"
- "8083:8081"
depends_on:
- roach-0
- roach-1
- roach-2
Om mee te doen, moet je de omgeving met Compose starten met de volgende opdracht:
docker compose -f docker-compose.yml -f docker-compose-lb-high-availability.yml up -d --build
Je ziet de volgende lijst met diensten:
✔ Network cockroach-docker_default Created 0.0s ✔ Container client2 Started 0.4s ✔ Container roach-1 Started 0.7s ✔ Container roach-0 Started 0.6s ✔ Container roach-2 Started 0.5s ✔ Container client Started 0.6s ✔ Container init Started 0.9s ✔ Container lb2 Started 1.1s ✔ Container lb Started
Het onderstaande diagram toont de hele clustertopologie:
Voer een Workload uit
Op dit moment kunnen we verbinding maken met een van de clients en de workload initialiseren. Ik gebruik tpcc omdat het een goede workload is om schrijf- en leessporen te demonstreren.
cockroach workload fixtures import tpcc --warehouses=10 'postgresql://root@lb:26000/tpcc?sslmode=disable'
Vervolgens kunnen we de workload starten vanuit beide clientcontainers.
- Load Balancer 1:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable'
- Load Balancer 2:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
Je ziet uitvoer die op deze lijnen lijkt.
488.0s 0 1.0 2.1 44.0 44.0 44.0 44.0 newOrder 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 488.0s 0 2.0 2.1 11.0 16.8 16.8 16.8 payment 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel 489.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 delivery 489.0s 0 2.0 2.1 15.2 17.8 17.8 17.8 newOrder 489.0s 0 1.0 0.2 5.8 5.8 5.8 5.8 orderStatus
De logboeken voor elke instantie van HAProxy laten iets als dit zien:
192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/0 28724 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/816 28846 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:40.744] stats stats/<STATS> 0/0/553 28900 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:41.297] stats stats/<STATS> 0/0/1545 28898 LR 2/2/0/0/0 0/0 192.168.160.1:60582 [27/Apr/2023:14:51:39.927] stats stats/<NOSRV> -1/-1/61858 0 CR 2/2/0/0/0 0/0
HAProxy biedt een web-UI op poort 8081. Aangezien we twee instanties van HAProxy hebben, heb ik de tweede instantie geopend op poort 8083.
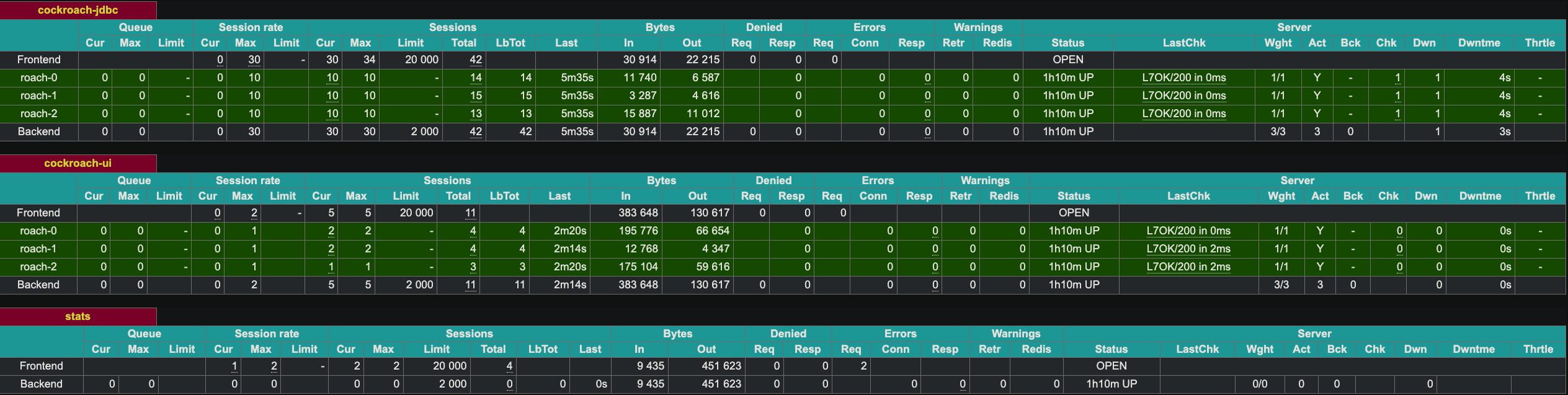
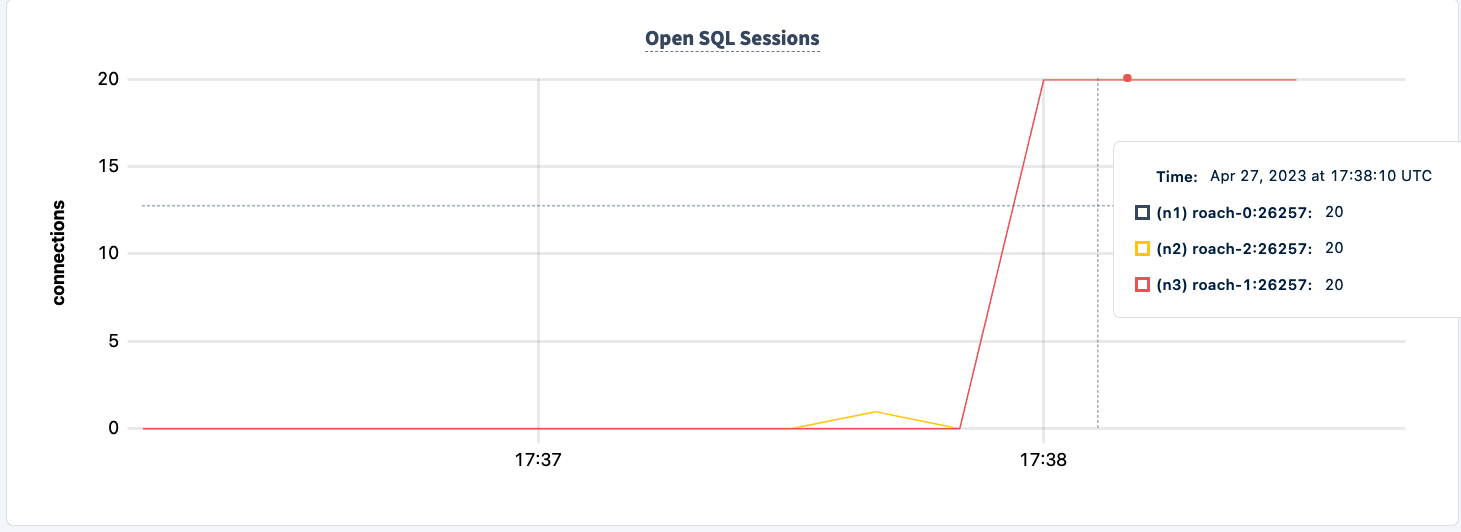
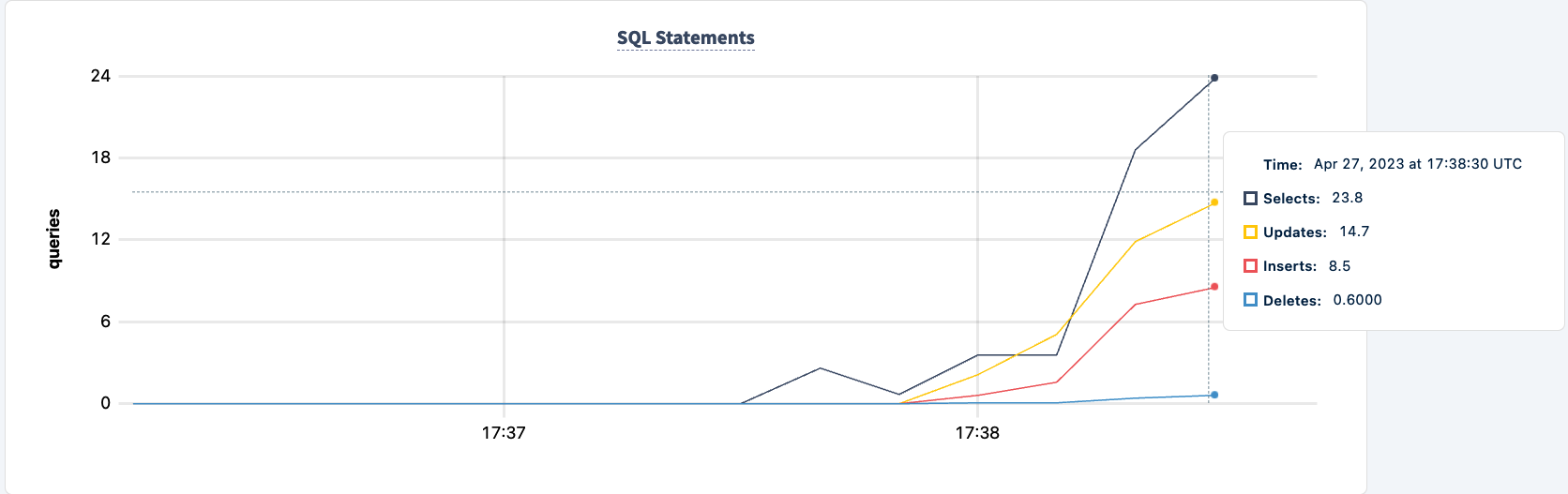
Demonstratie van Fouttolerantie
We kunnen nu de HAProxy-instanties starten om fouttolerantie te demonstreren. Laten we beginnen met instantie 1.
docker kill lb lb
Het werkbelasting zal beginnen met het produceren van foutberichten.
7 17:41:18.758669 357 workload/pgx_helpers.go:79 [-] 60 + RETURNING d_tax, d_next_o_id] W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 error preparing statement. name=new-order-1 sql= W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + UPDATE district W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + SET d_next_o_id = d_next_o_id + 1 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + WHERE d_w_id = $1 AND d_id = $2 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + RETURNING d_tax, d_next_o_id unexpected EOF 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 delivery 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 newOrder 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 payment
Onze werkbelasting draait nog steeds met behulp van de HAProxy 2-verbinding.
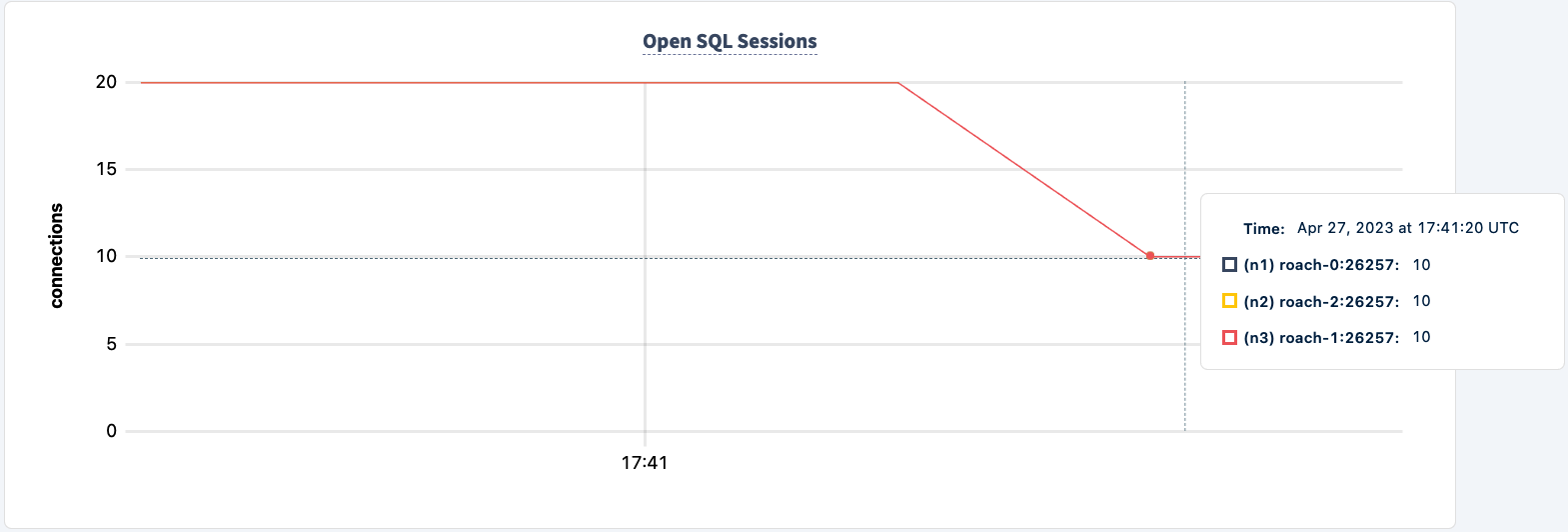
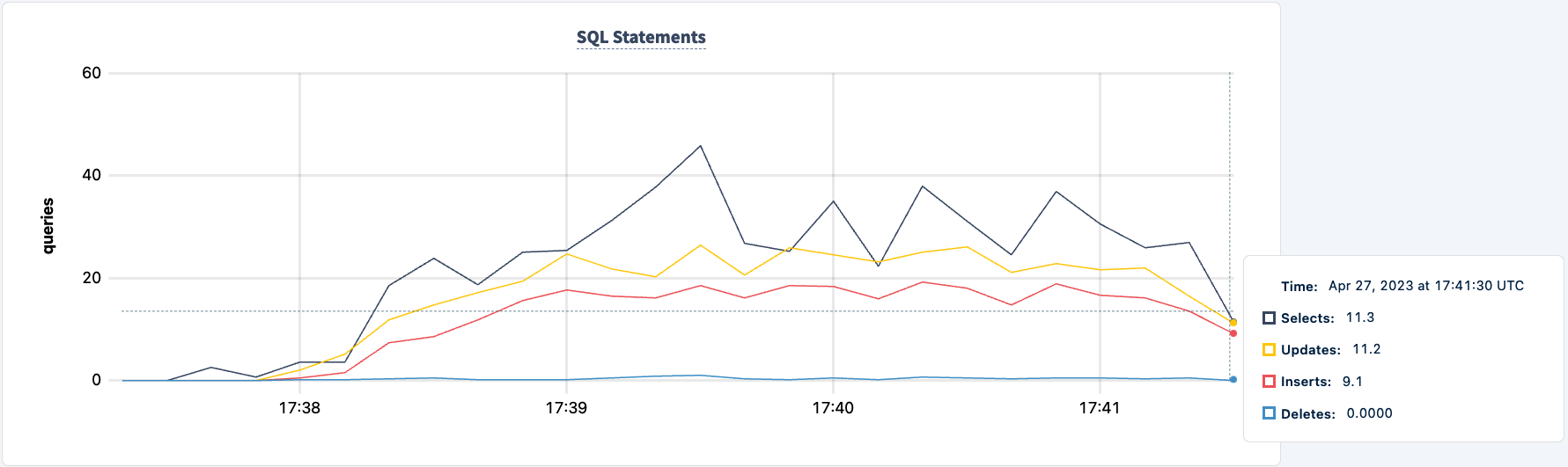
Laten we het weer opstarten:
docker start lb
Merk op dat de client opnieuw verbinding maakt en verdergaat met de werkbelasting.
335.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 336.0s 1780 7.0 1.1 19.9 27.3 27.3 27.3 newOrder 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 orderStatus 336.0s 1780 2.0 1.0 10.5 11.0 11.0 11.0 payment 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel 337.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 337.0s 1780 7.0 1.1 21.0 32.5 32.5 32.5 ne
Het aantal uitgevoerde statements stijgt bij het succesvol verbinden van de tweede client.
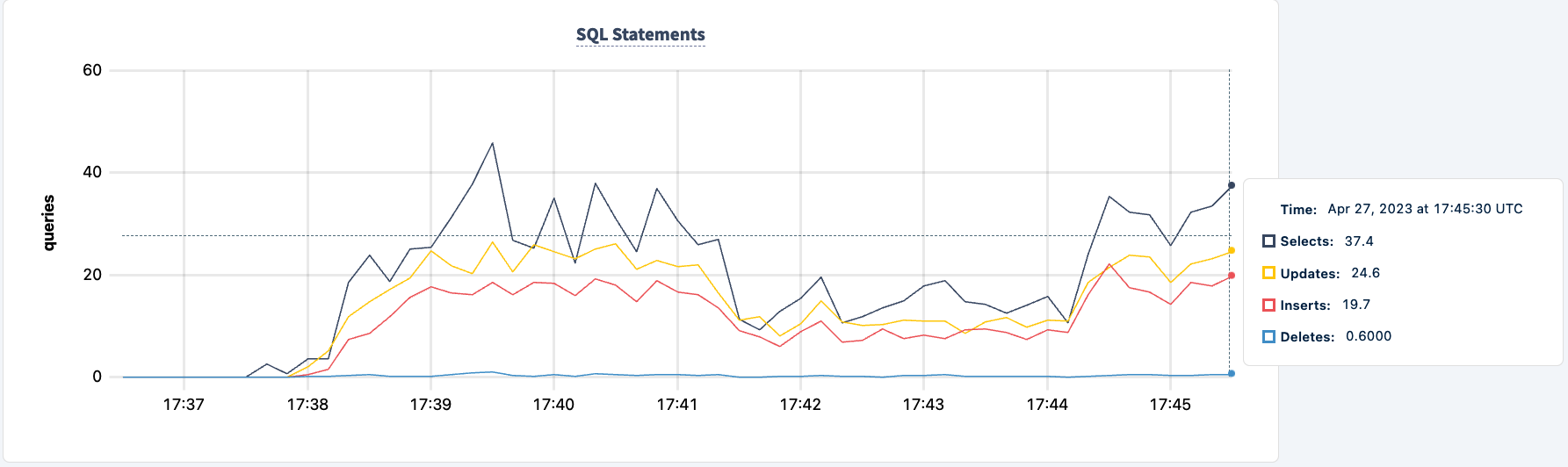
We kunnen nu hetzelfde doen met de tweede instantie. Op dezelfde manier rapporteert de werkbelasting fouten dat het de lb2 host niet kan vinden.
0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:48:28.239032 403 workload/pgx_helpers.go:79 [-] 188 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host] I230427 17:48:28.267355 357 workload/pgx_helpers.go:79 [-] 189 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host]
En we kunnen de daling in het aantal uitgevoerde statements waarnemen.
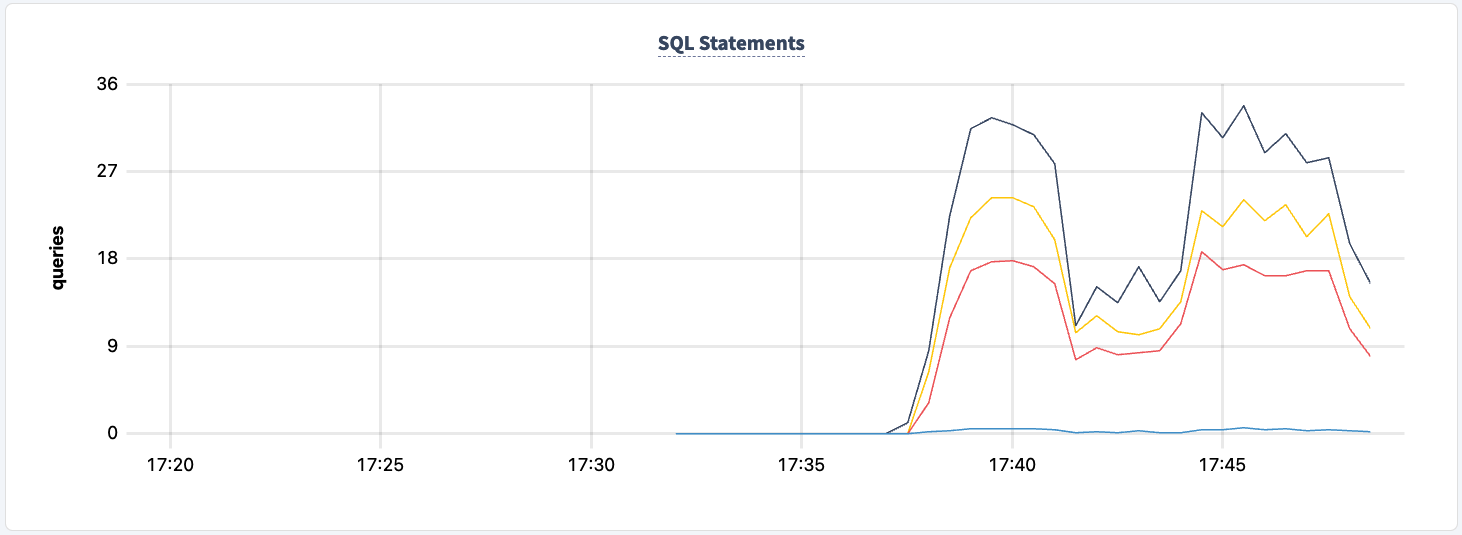
We kunnen het weer opstarten:
docker start lb2
Een ding dat we kunnen verbeteren, is het starten van de werkbelasting met beide verbindingsstrings. Dit zal ervoor zorgen dat elke client kan terugvallen op de andere instantie van pgurl, zelfs wanneer een van de HAProxy-instanties uitvalt. Wat we moeten doen is beide clients stoppen en opnieuw starten met beide verbindingsstrings.
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable' 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
I am going to do that one client at a time so that the workload does not exit completely.
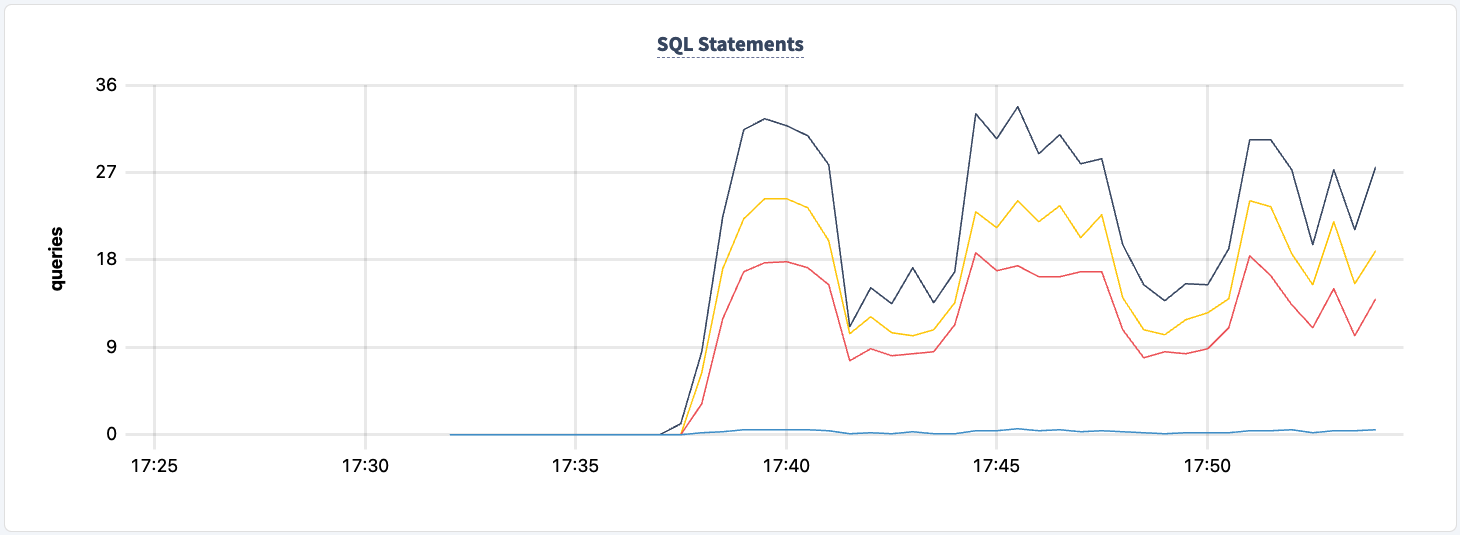
Op geen enkel moment in dit experiment hebben we de mogelijkheid verloren om te lezen/schrijven naar en van het cluster. Laten we opnieuw een van de HAProxy-instanties uitschakelen en de impact bekijken.
docker kill lb lb
I’m now seeing errors across both clients, but both clients are still executing.
.817268 1 workload/cli/run.go:548 [-] 85 error in stockLevel: lookup lb on 127.0.0.11:53: no such host _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 delivery 156.0s 49 1.0 2.1 31.5 31.5 31.5 31.5 newOrder 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 156.0s 49 1.0 2.0 12.1 12.1 12.1 12.1 payment 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:55:58.558209 354 workload/pgx_helpers.go:79 [-] 86 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.698731 346 workload/pgx_helpers.go:79 [-] 87 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.723643 386 workload/pgx_helpers.go:79 [-] 88 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.726639 370 workload/pgx_helpers.go:79 [-] 89 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.789717 364 workload/pgx_helpers.go:79 [-] 90 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.841283 418 workload/pgx_helpers.go:79 [-] 91 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host]
We kunnen het weer opstarten en merk op dat de werkbelasting herstelt.
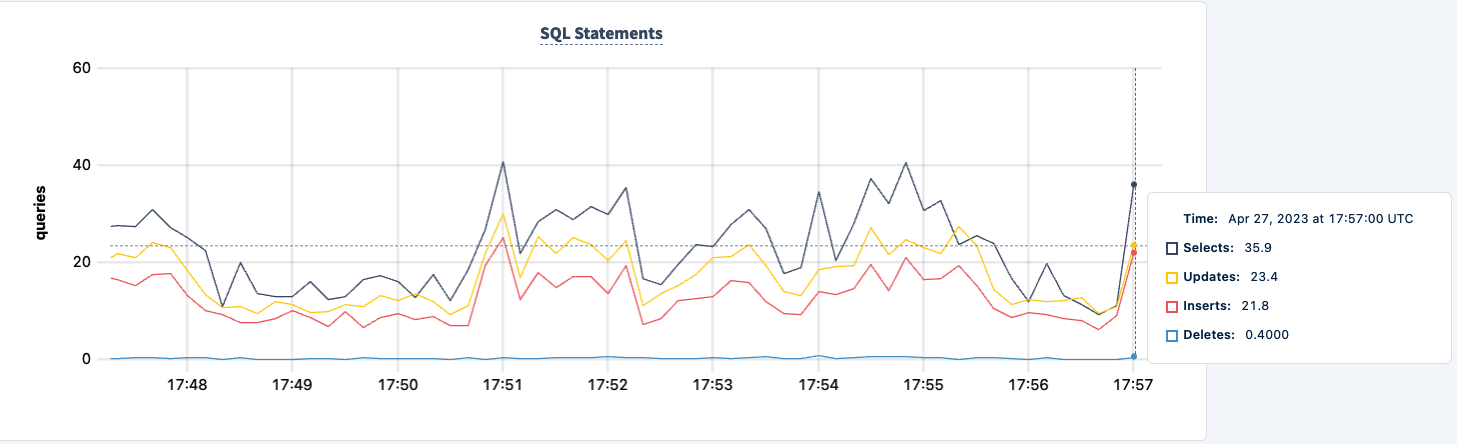
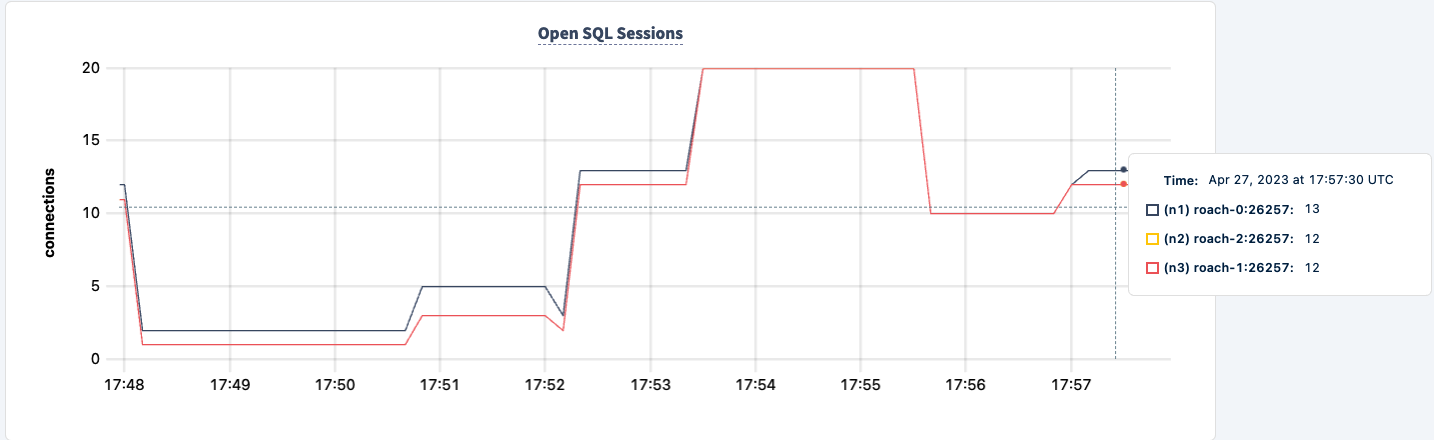
Conclusie
Gedurende het experiment hebben we de mogelijkheid om te lezen en schrijven naar de database niet verloren. Er waren wel pieken en dalen in het verkeer, maar dat is verwacht. De les hier is het bieden van een zeer beschikbare configuratie waarbij clients meerdere verbindingen kunnen zien.
Source:
https://dzone.com/articles/load-balancer-high-availability-with-cockroachdb-a