













Per riferimento: Controlla il mio articolo precedente dove discuto dell’alta disponibilità del pool di connessioni, “Alta Disponibilità del Pool di Connessioni con CockroachDB e PgCat.”
Motivazione
Il bilanciamento del carico è un elemento chiave dell’architettura di CockroachDB. Data la sua importanza, mi piacerebbe discutere i metodi per superare le situazioni di SPOF.
Passaggi di Alto Livello
- Avviare CockroachDB e HAProxy in Docker
- Eseguire un carico di lavoro
- Dimostrare la tolleranza ai guasti
- Conclusione
Istruzioni Passo-Passo
Avviare CockroachDB e HAProxy in Docker
I have a Docker Compose environment with all of the necessary services here. Primarily, we are adding a second instance of HAProxy and overriding the ports not to overlap with the existing load balancer in the base Docker Compose file.
I am in the middle of refactoring my repo to remove redundancy and decided to split up my Compose files into a base docker-compose.yml and any additional services into their own YAML files.
lb2:
container_name: lb2
hostname: lb2
build: haproxy
ports:
- "26001:26000"
- "8082:8080"
- "8083:8081"
depends_on:
- roach-0
- roach-1
- roach-2
Per seguire, è necessario avviare l’ambiente Compose con il comando:
docker compose -f docker-compose.yml -f docker-compose-lb-high-availability.yml up -d --build
Vedrai la seguente lista di servizi:
✔ Network cockroach-docker_default Created 0.0s ✔ Container client2 Started 0.4s ✔ Container roach-1 Started 0.7s ✔ Container roach-0 Started 0.6s ✔ Container roach-2 Started 0.5s ✔ Container client Started 0.6s ✔ Container init Started 0.9s ✔ Container lb2 Started 1.1s ✔ Container lb Started
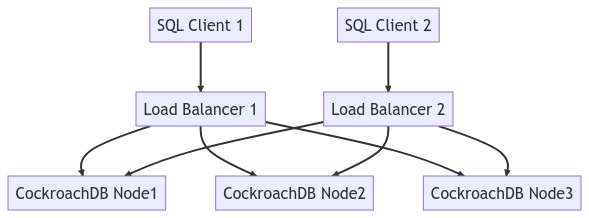
Il diagramma seguente rappresenta l’intera topologia del cluster:
Eseguire un Carico di Lavoro
A questo punto, possiamo connetterci a uno dei client e iniziare il carico di lavoro. Sto usando tpcc perché è un buon carico di lavoro per dimostrare il traffico di scrittura e lettura.
cockroach workload fixtures import tpcc --warehouses=10 'postgresql://root@lb:26000/tpcc?sslmode=disable'
Quindi possiamo avviare il carico di lavoro da entrambi i contenitori client.
- Load Balancer 1:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable'
- Load Balancer 2:
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
Vedrai un output simile a questo.
488.0s 0 1.0 2.1 44.0 44.0 44.0 44.0 newOrder 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 488.0s 0 2.0 2.1 11.0 16.8 16.8 16.8 payment 488.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel 489.0s 0 0.0 0.2 0.0 0.0 0.0 0.0 delivery 489.0s 0 2.0 2.1 15.2 17.8 17.8 17.8 newOrder 489.0s 0 1.0 0.2 5.8 5.8 5.8 5.8 orderStatus
I log per ogni istanza di HAProxy mostreranno qualcosa di simile a questo:
192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/0 28724 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:39.927] stats stats/<STATS> 0/0/816 28846 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:40.744] stats stats/<STATS> 0/0/553 28900 LR 2/2/0/0/0 0/0 192.168.160.1:60584 [27/Apr/2023:14:51:41.297] stats stats/<STATS> 0/0/1545 28898 LR 2/2/0/0/0 0/0 192.168.160.1:60582 [27/Apr/2023:14:51:39.927] stats stats/<NOSRV> -1/-1/61858 0 CR 2/2/0/0/0 0/0
HAProxy espone un’interfaccia web sul portale 8081. Poiché abbiamo due istanze di HAProxy, ho esposto la seconda istanza sul portale 8083.
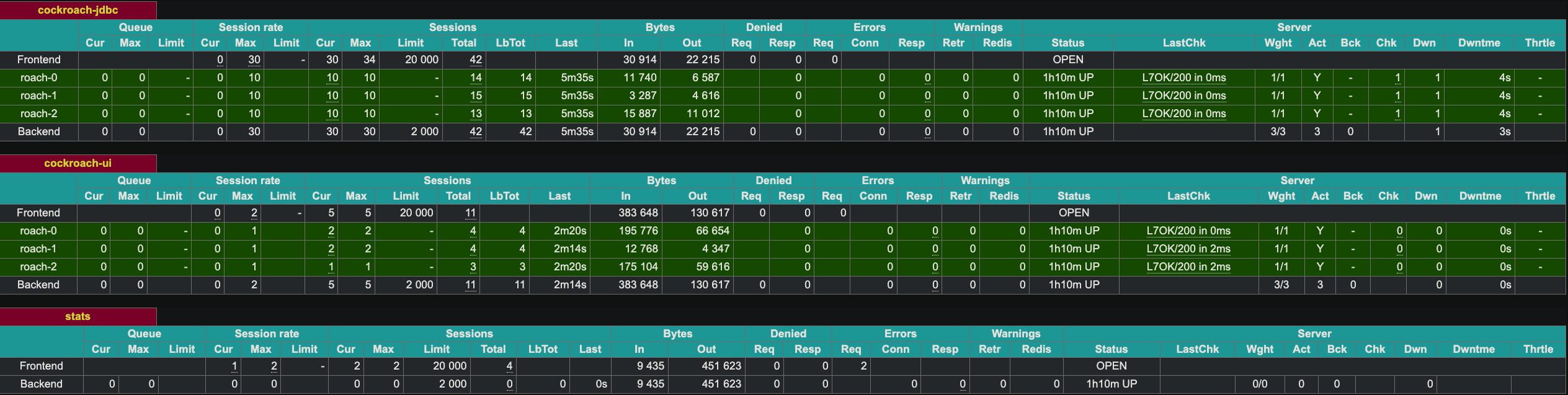
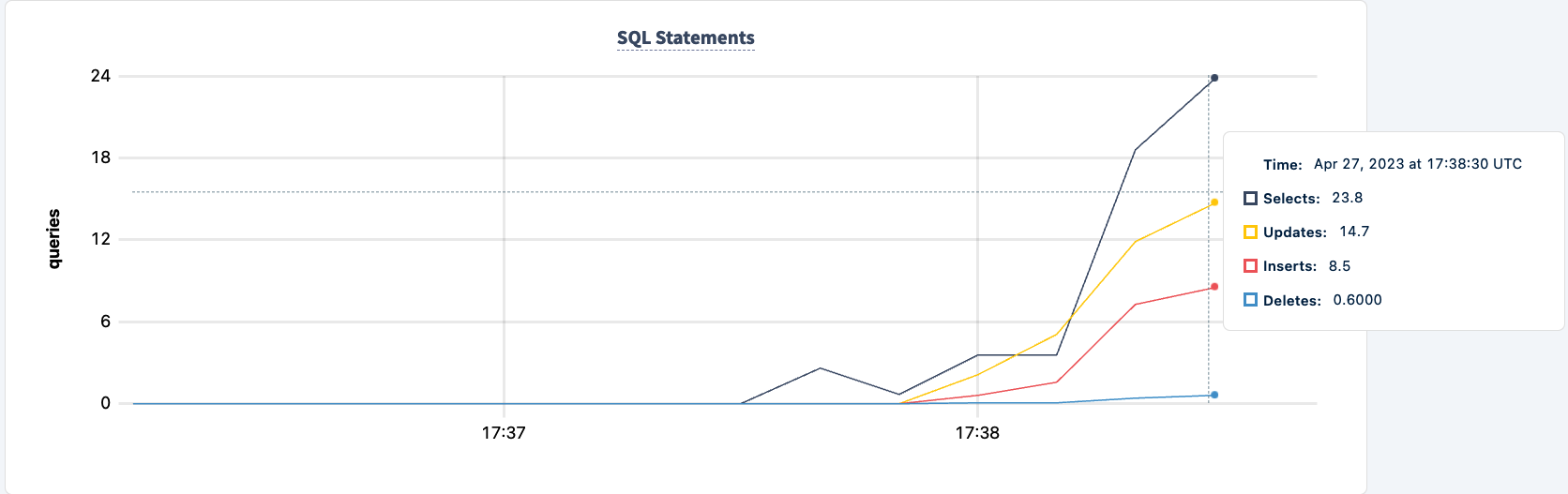
Dimostrazione di tolleranza ai guasti
Ora possiamo iniziare a terminare le istanze di HAProxy per dimostrare la tolleranza ai guasti. Iniziamo con l’istanza 1.
docker kill lb lb
Il carico di lavoro inizierà a produrre messaggi di errore.
7 17:41:18.758669 357 workload/pgx_helpers.go:79 [-] 60 + RETURNING d_tax, d_next_o_id] W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 error preparing statement. name=new-order-1 sql= W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + UPDATE district W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + SET d_next_o_id = d_next_o_id + 1 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + WHERE d_w_id = $1 AND d_id = $2 W230427 17:41:18.758737 357 workload/pgx_helpers.go:123 [-] 61 + RETURNING d_tax, d_next_o_id unexpected EOF 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 delivery 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 newOrder 142.0s 3 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 142.0s 3 0.0 2.2 0.0 0.0 0.0 0.0 payment
Il nostro carico di lavoro continua a funzionare utilizzando la connessione HAProxy 2.
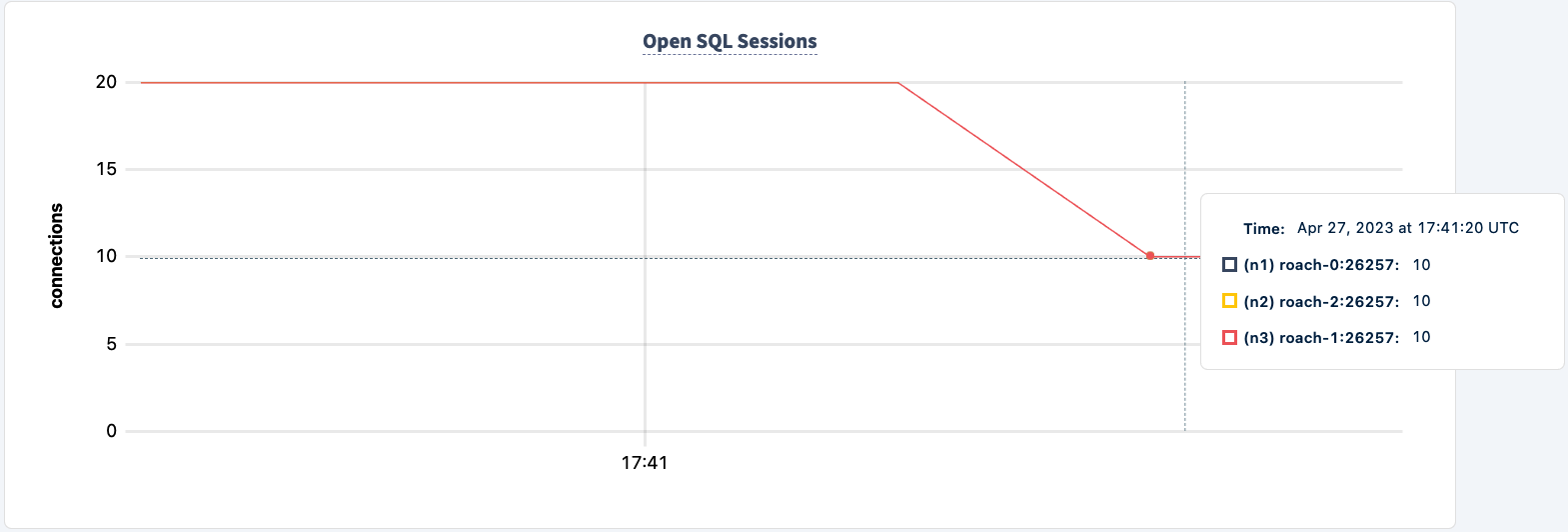
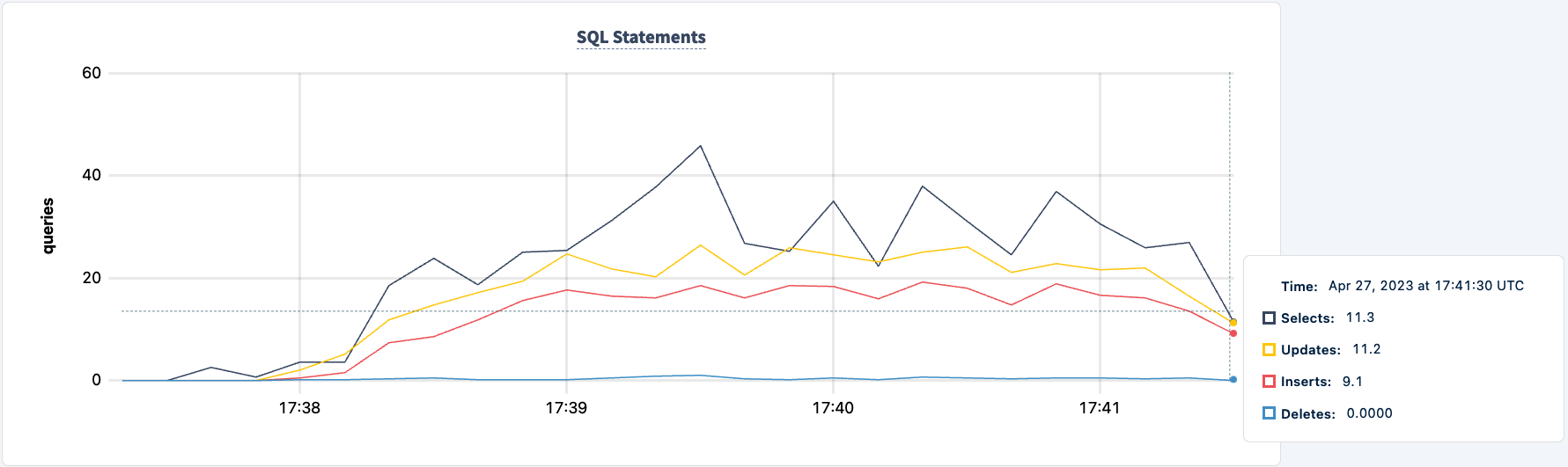
Riprendiamolo:
docker start lb
Nota che il client si riconnette e continua con il carico di lavoro.
335.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 336.0s 1780 7.0 1.1 19.9 27.3 27.3 27.3 newOrder 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 orderStatus 336.0s 1780 2.0 1.0 10.5 11.0 11.0 11.0 payment 336.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 stockLevel 337.0s 1780 0.0 0.1 0.0 0.0 0.0 0.0 delivery 337.0s 1780 7.0 1.1 21.0 32.5 32.5 32.5 ne
Il numero di istruzioni eseguite aumenta quando il secondo client si connette correttamente.
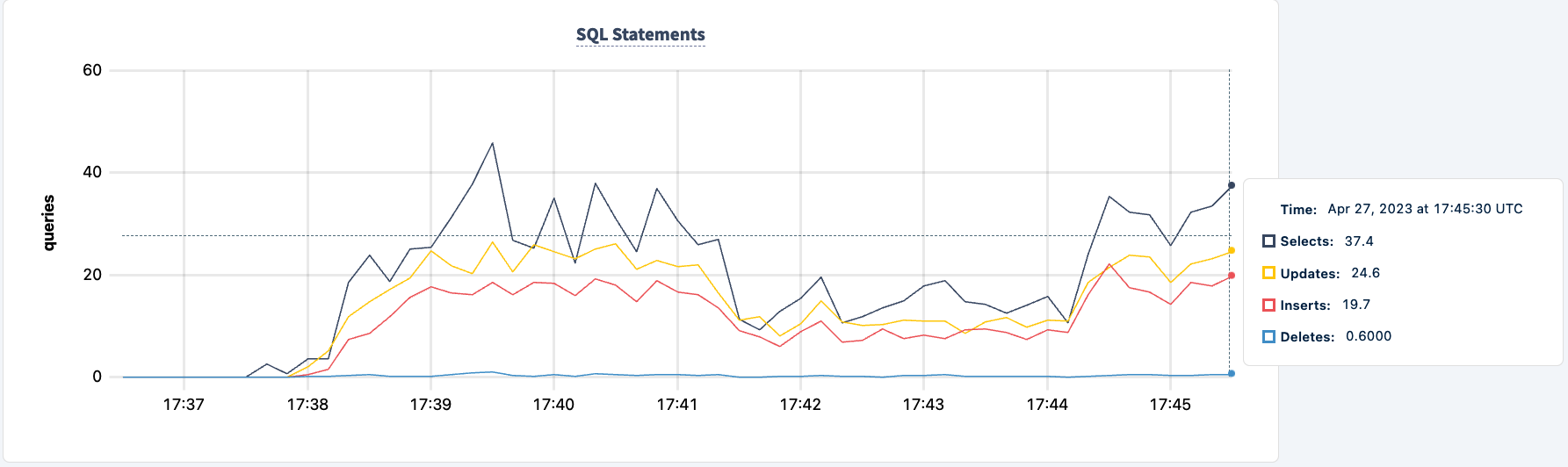
Ora possiamo fare lo stesso con la seconda istanza. Allo stesso modo, il carico di lavoro segnala errori perché non riesce a trovare il host lb2.
0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:48:28.239032 403 workload/pgx_helpers.go:79 [-] 188 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host] I230427 17:48:28.267355 357 workload/pgx_helpers.go:79 [-] 189 pgx logger [error]: connect failed logParams=map[err:lookup lb2 on 127.0.0.11:53: no such host]
E possiamo osservare la diminuzione del conteggio delle istruzioni.
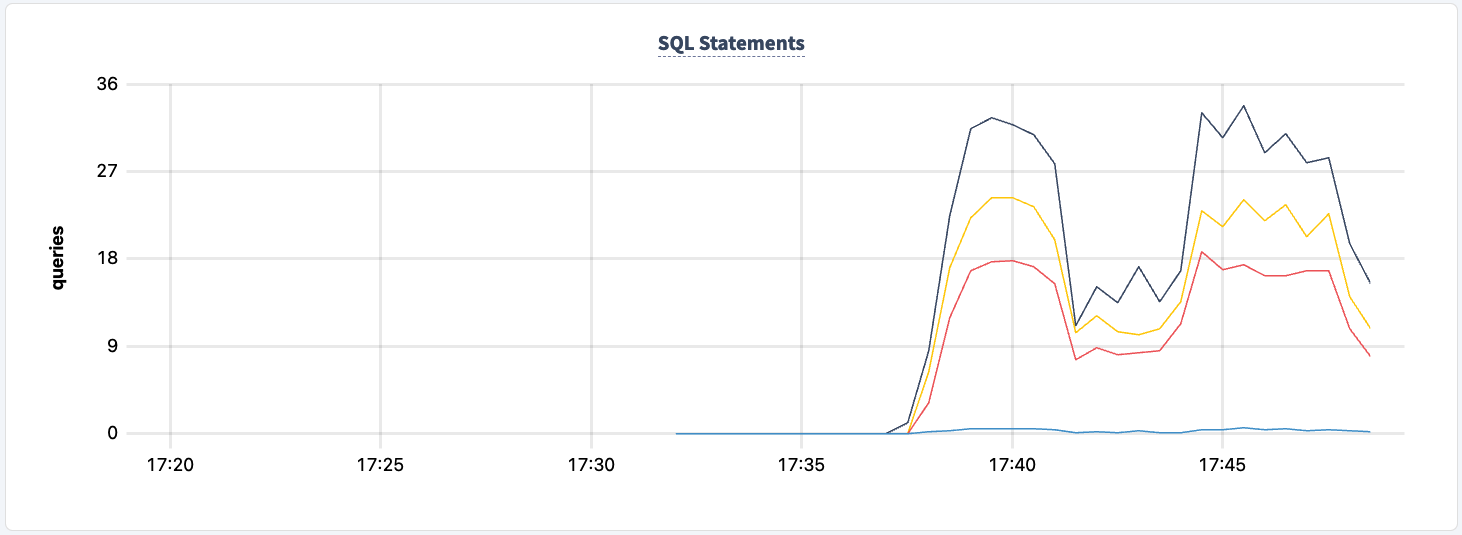
Possiamo riportarlo su:
docker start lb2
Una cosa che possiamo migliorare è avviare il carico di lavoro con entrambe le stringhe di connessione. Permetterà a ciascun client di ricadere sull’altra istanza di pgurl anche quando una delle istanze di HAProxy è spenta. Quello che dobbiamo fare è interrompere entrambi i client e riavviare con entrambe le stringhe di connessione.
cockroach workload run tpcc --duration=120m --concurrency=3 --max-rate=1000 --tolerate-errors --warehouses=10 --conns 30 --ramp=1m --workers=100 'postgresql://root@lb:26000/tpcc?sslmode=disable' 'postgresql://root@lb2:26000/tpcc?sslmode=disable'
I am going to do that one client at a time so that the workload does not exit completely.
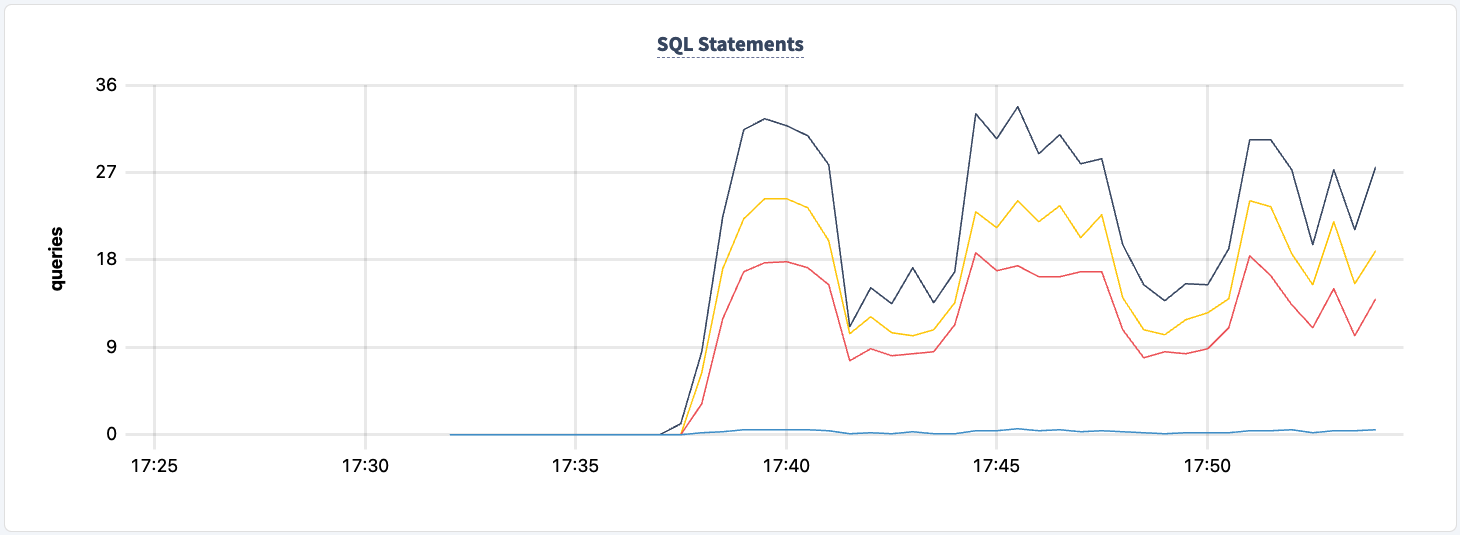
In nessun momento di questo esperimento abbiamo perso la capacità di leggere/scrivere da e verso il cluster. Spegniamo di nuovo una delle istanze di HAProxy e vediamo l’impatto.
docker kill lb lb
I’m now seeing errors across both clients, but both clients are still executing.
.817268 1 workload/cli/run.go:548 [-] 85 error in stockLevel: lookup lb on 127.0.0.11:53: no such host _elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms) 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 delivery 156.0s 49 1.0 2.1 31.5 31.5 31.5 31.5 newOrder 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 orderStatus 156.0s 49 1.0 2.0 12.1 12.1 12.1 12.1 payment 156.0s 49 0.0 0.2 0.0 0.0 0.0 0.0 stockLevel I230427 17:55:58.558209 354 workload/pgx_helpers.go:79 [-] 86 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.698731 346 workload/pgx_helpers.go:79 [-] 87 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.723643 386 workload/pgx_helpers.go:79 [-] 88 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.726639 370 workload/pgx_helpers.go:79 [-] 89 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.789717 364 workload/pgx_helpers.go:79 [-] 90 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host] I230427 17:55:58.841283 418 workload/pgx_helpers.go:79 [-] 91 pgx logger [error]: connect failed logParams=map[err:lookup lb on 127.0.0.11:53: no such host]
Possiamo riportarlo su e notare il recupero del carico di lavoro.
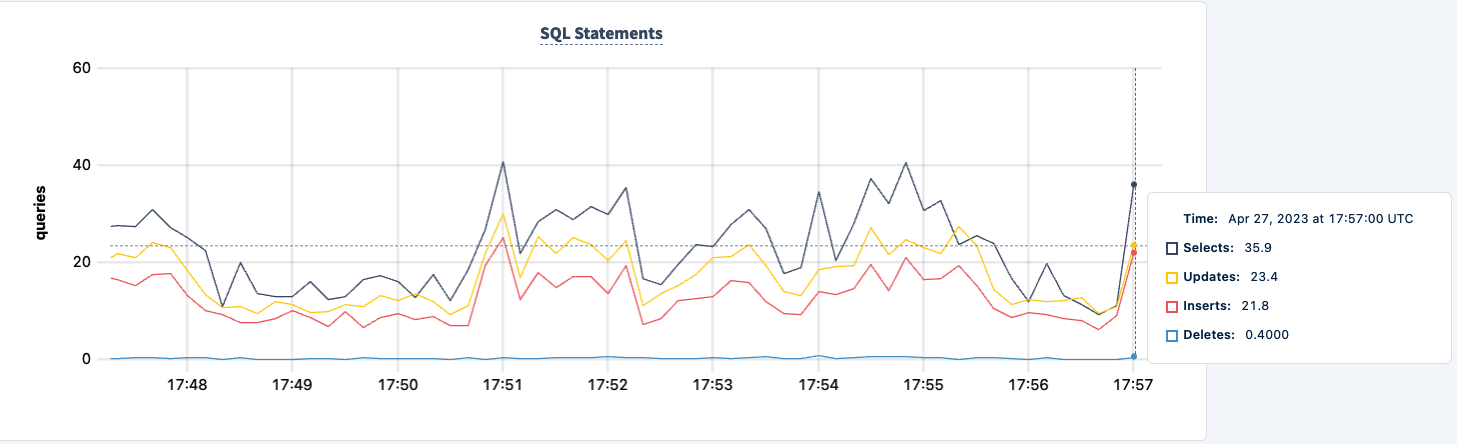
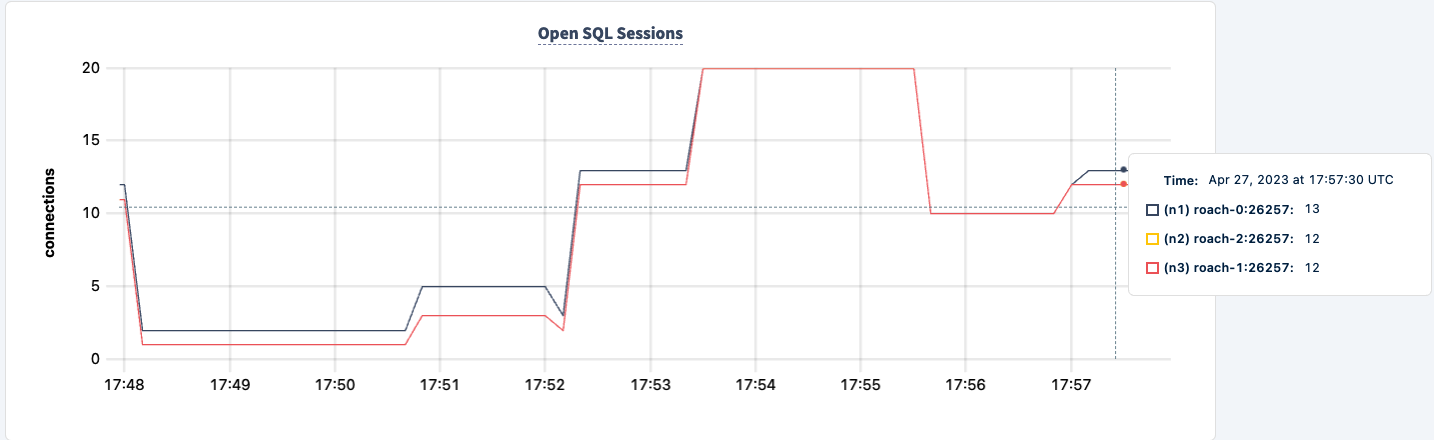
Conclusione
Durante l’esperimento, non abbiamo perso la capacità di leggere e scrivere nel database. Ci sono state fluttuazioni nel traffico, ma ciò è previsto. La lezione qui è fornire una configurazione altamente disponibile dove i client possono vedere più connessioni.
Source:
https://dzone.com/articles/load-balancer-high-availability-with-cockroachdb-a