













Компьютерные технологии без серверов появились как ответ на проблемы традиционных серверно-ориентированных архитектур. С технологией без серверов разработчики больше не нуждаются в ручном управлении или масштабировании серверов. Вместо этого, провайдеры облачных сервисов занимаются управлением инфраструктурой, позволяя командам сосредотачиваться исключительно на написании и развёртывании кода.
Решения без серверов автоматически масштабируются в зависимости от спроса и предлагают модель “оплата за использование”. Это означает, что вы платите только за ресурсы, которые фактически использует ваше приложение. Такой подход значительно снижает операционные издержки, увеличивает гибкость и ускоряет циклы разработки, делая его привлекательным вариантом для современного разработки приложений.
Абстракции управления сервером платформы без серверов позволяют вам сосредоточиться на бизнес-логике и функциональности приложения. Это приводит к более быстрому развёртыванию и большему инновационному потенциалу. Архитектуры без серверов также являются событийными, что означает, что они могут автоматически реагировать на реальные события в реальном времени и масштабироваться для соответствия потребностям пользователей без ручного вмешательства.
Содержание
-
Шаг 4: Настройка CI/CD-конвеера для многоступенчатых развертываний в среды разработки и производства
-
Шаг 6: Тестирование и валидация API производства и разработки с использованием Postman
Прежде чем погружаться в технические детали, мы рассмотрим некоторые ключевые концепции.
Важные концепты для понимания
Интерфейс программирования приложений (API)
Интерфейс программирования приложений (API) позволяет различным программным приложениям общаться и взаимодействовать друг с другом. Он определяет методы и форматы данных, которые приложения могут использовать для запроса и обмена информацией для интеграции и обмена данными между различными системами.
Методы HTTP
Методы HTTP или методы запроса являются критическим компонентом веб-сервисов и API. Они указывают желаемое действие, которое должно быть выполнено над ресурсом в указанном URL-адресе запроса.
Самыми широко используемыми методами в RESTful API являются:
-
GET: используется для извлечения данных с сервера
-
POST: отправляет данные, включенные в тело запроса, для создания или обновления ресурса
-
PUT: обновляет или заменяет существующий ресурс или создает новый ресурс, если он не существует
-
DELETE: удаляет указанные данные с сервера.
Amazon API Gateway
Amazon API Gateway — это полностью управляемый сервис, который позволяет разработчикам легко создавать, публиковать, поддерживать, мониторить и обеспечивать безопасность API на масштабном уровне. Он выступает в качестве входного узла для множества API, управляя и контролируя взаимодействия между клиентами (такими как веб- или мобильные приложениями) и backend-сервисами.
Кроме того, он обеспечивает различные функции, включая маршрутизацию запросов, безопасность, аутентификацию, кэширование и ограничение скорости, что помогает упростить управление и развертывание API.
Amazon DynamoDB
DynamoDB — это полностью управляемый сервис NoSQL-базы данных, спроектированный для высокой скалярности, низкойlatency и репликации данных в multiple regions.
DynamoDB хранит данные в неограниченном формате схемы, позволяя гибко и быстро хранить и извлекать структурированные и полуструктурированные данные. Он обычно используется для создания масштабируемых и реагирующих приложений в облачных средах.
Серверлясная CRUD-апликация
Серверлясная CRUD-апликация означает возможность Создание, чтение, обновление и удаление данных. Однако архитектура и компоненты,涉及involved отличаются от традиционных серверных приложений.
Создание заключается в добавлении новых записей в таблицу DynamoDB.Operция Чтение получение данных из таблицы DynamoDB. Обновление обновляет существующие данные в DynamoDB. А операция Удаление удаляет данные из DynamoDB.
Серверлясная платформа
Серверный Framework является открытым инструментом, который упрощает развёртывание и управление серверными приложениями в нескольких облачных провайдерах, включая AWS. Он абстрагирует сложности в обеспечении и управлении инфраструктурой, позволяя разработчикам определять свою инфраструктуру как код, используя файл YAML.
Фреймворк обрабатывает развёртывание, масштабирование и обновление серверных функций, API и других ресурсов.
GitHub Actions
GitHub Actions — это мощное средство автоматизации CI/CD, которое позволяет разработчикам автоматизировать свои рабочие процессы программного обеспечения непосредственно из репозитория GitHub.
С помощью GitHub Actions вы можете создавать пользовательские конвейеры, запускаемые событиями, такими как отправка кода, запросы на.pull, или слияние ветвей. Эти рабочие процессы определены в файлах YAML в репозитории и могут выполнять такие задачи, как тестирование, сборка и развёртывание приложений в различных средах.
Postman
Postman — это популярная платформа для совместной работы, которая упрощает процесс проектирования, тестирования и документирования API. Она предлагает удобный интерфейс для разработчиков для создания и отправки HTTP-запросов, тестирования конечных точек API и автоматизации рабочих процессов тестирования.
Хорошо, теперь, когда вы знакомы с инструментами и технологиями, которые мы будем использовать здесь, давайте приступим.
Предварительные условия
-
Установлен Node.js и npm
-
AWS CLI настроен с доступом к вашему аккаунту AWS
-
Аккаунт Serverless Framework
-
Serverlesss Framework глобально установлен в вашем локальном CLI
Наш пример использования
Знакомимся с Аликс, предпринимательницей, которая недавно узнала о бессерверной архитектуре. Она читала о том, что это мощный и эффективный способ создания бэкендов для веб-приложений, предлагающий более современный подход к разработке веб-приложений.
Она хочет применить то, что она узнала до сих пор об основах бессерверных вычислений AWS. Она знает, что бессерверные вычисления не означают отсутствие серверов – скорее, это просто абстрагирование от управления и предоставления серверов. И теперь она хочет сосредоточиться исключительно на написании кода и реализации бизнес-логики.
Давайте посмотрим, как Аликс, владелица процветающей кофейни, начинает использовать бессерверную архитектуру для бэкенда своего веб-приложения.
Alyx’s Coffee Haven, онлайн-магазин кофе, предлагает на продажу множество кофейных смесей и угощений. Первоначально Аликс управляла заказами и инвентарем магазина с помощью традиционных услуг веб-хостинга и операций, где она обслуживала несколько серверов и ресурсов. Но по мере роста популярности кофейни она начала сталкиваться с растущим количеством заказов, особенно в часы пик и во время сезонных акций.
Управление серверами и обеспечение того, чтобы приложение могло справиться с резким ростом трафика, стало для Аликс непростой задачей. Она постоянно беспокоилась о мощности серверов, масштабируемости и стоимости обслуживания инфраструктуры.
Кроме того, она хотела внедрить такие новые функции, как персонализированные рекомендации и программы лояльности, но это стало кажущейся непреодолимой задачей с учетом ограничений ее традиционной системы.
Затем Alyx узнала о концепции серверлесс. Она сравнила серверлесс-бэкенд с баристой, который автоматически заваривает кофе в реальном времени, не требуя от нее беспокойства о сложных деталях процесса приготовления кофе.
Воодушевленная этой идеей, Alyx решила мигрировать бэкенд своей кофейни на серверлесс-платформу, используя AWS Lambda, AWS API Gateway и Amazon DynamoDB. Эта установка позволит ей больше сосредоточиться на создании идеальных кофейных смесей и закусок для своих клиентов.
С серверлесс each заказ клиента становится событием, которое запускает серию серверлесс-функций. Отдельные AWS Lambda-функции обрабатывают заказы и занимаются всей бизнес-логикой за кадром. Например, она создает заказ клиента и может извлечь этот заказ. Она также может удалить заказ кого-то или обновить статус заказа.
Alyx больше не нужно беспокоиться о управлении серверами, так как серверлесс-платформа автоматически масштабируется вверх и вниз в зависимости от входящих запросов на заказ. Кроме того, экономичность серверлесс для Alyx огромна. С моделью оплаты по факту она платит только за фактическое время вычислений, которое ее функции потребляют, предлагая более экономически эффективное решение для ее растущего бизнеса.
Но она не останавливается на этом! Ей также нужно автоматизировать все, от развертывания инфраструктуры до обновления ее приложения при каждом новым изменении. Utilizing Infrastructure as Code (IaC) с Serverless Framework, она может определить все свои инфраструктуры в коде и управлять ими легко.
Кроме того, она устанавливает GitHub Actions для непрерывной интеграции и деployment (CI/CD), так что каждое изменение, которое она делает, автоматически развертывается через питон, независимо от того, является ли это новым функциональным особенностью в разработке или горячим исправлением для производства.
Цели Tutorial
-
Установить среду Serverless Framework
-
Определить API в YAML-файле
-
Разработать функции AWS Lambda для обработки операций CRUD
-
Настроить многостадийные деployments для Dev и Prod
-
Протестировать Dev и Prod pipelines
-
Протестировать и проверить Dev и Prod API с использованием Postman
Как начать: клонировать Git-репозиторий
Воспользуйтесь следующими указаниями, чтобы эффективно выполнить кloning проекта из моего репозитория GitHub. Можете сделать это перейдя по ссылке. При движении вперед, не стесняйтесь редактировать файлы, если это потребуется.
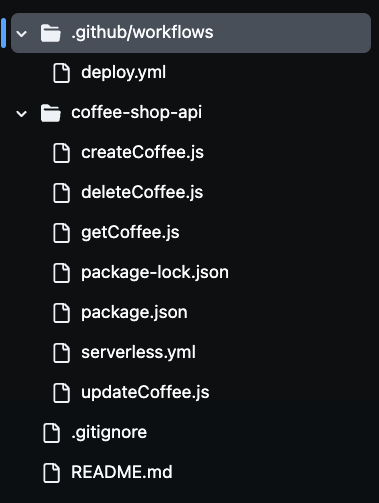
После клонирования репозитория вы заметите наличие множества файлов в вашей папке, как показано на картинке ниже. Мы будем использовать все эти файлы для создания нашего API кофейни без сервера.
Шаг 1: Настройка среды Serverless Framework
Для настройки среды Serverless Framework для автоматизированных развертываний вам нужно выполнить аутентификацию своего аккаунта Serverless Framework через CLI.
Для этого потребуется создать ключ доступа, который активирует CI/CD-пайплайн и использует Serverless Framework для безопасной аутентификации в вашем аккаунте, не раскрывая ваши учетные данные. Зайдя в свой аккаунт Serverless и сгенерировав ключ доступа, пайплайн сможет автоматически развертывать ваше безсерверное приложение из файла конфигурации сборки.
Чтобы сделать это, перейдите в свой аккаунт Serverless и навигируйтесь до раздела Ключи доступа. Нажмите на “+добавить”, назовите его SERVERLESS_ACCESS_KEY и создайте ключ.
После создания ключа доступа убедитесь, что скопировали и сохранили его в безопасном месте. Вы будете использовать этот ключ в качестве секретной переменной в вашем репозитории GitHub для аутентификации и авторизации вашего CI/CD-пайплайна.
Будет предоставлен доступ к вашей учетной записи Serverless Framework во время процесса развертывания. Вы добавите этот ключ в секреты репозитория GitHub позже, чтобы ваша CI/CD-пайплайн могла безопасно использовать его для развертывания серверных ресурсов без раскрытия конфиденциальной информации в вашем кодовом репозитории.
Теперь давайте определим AWS-ресурсы как код в файле serverless.yaml.
Шаг 2: Определите API в файле Serverless YAML
В этом файле вы будете определять основную инфраструктуру и функциональность API Кофейни Alyx с помощью конфигурации YAML Serverless Framework.
Этот файл определяет используемые AWS-услуги, включая API Gateway, Lambda-функции для операций CRUD и DynamoDB для хранения данных.
Вы также настроите роль IAM, чтобы Lambda-функции имели необходимые разрешения для взаимодействия с сервисом DynamoDB.
API Gateway настроен с соответствующими HTTP-методами (POST, GET, PUT и DELETE) для обработки входящих запросов и запуска соответствующих Lambda-функций.
Посмотрим на код:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
Конфигурация serverless.yml определяет, как API Кофейни Alyx будет работать в серверно-без серверной среде на AWS. Секция provider указывает, что приложение будет использовать AWS в качестве облачного провайдера, с Node.js в качестве среды выполнения.
Регион установлен на us-east-1 и переменная stage позволяет динамически распределить развертывание по различным средам, таким как dev и prod. Это означает, что тот же код может развернуться в различных средах, с ресурсами, именуемыми соответственно, для избежания конфликтов.
В разделе iam предоставляются разрешения Lambda-функциям для взаимодействия с таблицей DynamoDB. Синтаксис ${self:provider.stage} динамически именует таблицу DynamoDB, чтобы каждая среда имела свои собственные ресурсы, например, CoffeeOrders-dev для среды разработки и CoffeeOrders-prod для производственной. Эта динамическая именование помогает управлять множеством сред без необходимости вручную настраивать отдельные таблицы для каждой из них.
Раздел functions определяет четыре основных Lambda-функции, createCoffee, getCoffee, updateCoffee и deleteCoffee. Они обрабатывают CRUD-операции для API Кофейни.
Каждая функция связана с конкретным HTTP-методом в API Gateway, таким как POST, GET, PUT и DELETE. Эти функции взаимодействуют с таблицей DynamoDB, имя которой динамически формируется на основе текущего этапа.
Последний раздел resources определяет саму таблицу DynamoDB. Она настраивается с атрибутами OrderId и CustomerName, которые используются в качестве первичного ключа. Таблица настроена на использование режима оплаты по запросу, что делает ее экономически эффективной для растущего бизнеса Alyx.
Путем автоматизации развёртывания этих ресурсов с использованием Serverless Framework, Alyx может легко управлять своей инфраструктурой, освобождаясь от тяжести ручного предоставления и масштабирования ресурсов.
Шаг 3: Разработка Lambda-функций для операций CRUD
В этом шаге мы реализуем ядро логики API Кофейни Alyx, создавая Lambda-функции на JavaScript, выполняющие основные операции CRUD createCoffee, getCoffee, updateCoffee и deleteCoffee.
Эти функции используют SDK AWS для взаимодействия с сервисами AWS, в частности DynamoDB. Каждая функция будет отвечать за обработку конкретных запросов API, таких как создание заказа, получение заказов, обновление статусов заказа и удаление заказов.
Функция Create Coffee Lambda
Эта функция создаёт заказ:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
Эта Lambda-функция обрабатывает создание нового заказа на кофе в таблице DynamoDB. Сначала мы импортируем SDK AWS и инициализируем DynamoDB.DocumentClient для взаимодействия с DynamoDB. Также импортируется библиотека uuid для генерации уникальных идентификаторов заказов.
Внутри функции handler мы анализируем входящее тело запроса для извлечения информации о покупателе, такой как имя и предпочитаемый сорт кофе. Уникальный orderId генерируется с помощью uuidv4(), и эти данные подготавливаются для вставки в DynamoDB.
Параметры объекта определяют таблицу, в которой будут храниться данные, с TableName, который динамически устанавливается в значение переменной среды COFFEE_ORDERS_TABLE. Новый заказ включает поля такие как OrderId, CustomerName, CoffeeBlend и начальный статус Pending.
В блоке try код пытается добавить заказ в таблицу DynamoDB, используя метод put(). Если это успешно, функция возвращает код статуса 200 с сообщением о успехе и OrderId. Если происходит ошибка, код ее ловит и возвращает код статуса 500 вместе с сообщением об ошибке.
Функция Lambda Get Coffee
Эта функция извлекает все элементы кофе:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
Эта функция Lambda отвечает за извлечение всех заказов на кофе из таблицы DynamoDB и демонстрирует серверно-ориентированный подход к извлечению данных из DynamoDB на масштабируемом уровне.
Мы снова используем SDK AWS для инициализации экземпляра DynamoDB.DocumentClient для взаимодействия с DynamoDB. Функция handler конструирует объект params, указывая TableName, который динамически устанавливается с использованием переменной среды COFFEE_ORDERS_TABLE.
Метод scan() загружает все записи из таблицы. Если операция успешна, функция возвращает статус-код 200 и загруженные записи в формате JSON. В случае ошибки возвращается статус-код 500 и сообщение об ошибке.
Обновление кофе Lambda-функции
Эта функция обновляет элемент кофе по его ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
Эта Lambda-функция обрабатывает обновление статуса определенного заказа кофе в таблице DynamoDB.
Функция handler извлекает order_id, new_status и customer_name из тела запроса. Затем она создает объект params, чтобы указать имя таблицы и primary key для заказа (utilizando OrderId и CustomerName). UpdateExpression устанавливает новый статус заказа.
В блоке try код пытается обновить заказ в DynamoDB с использованием метода update(). Естественно, если это успешно, функция возвращает статус-код 200 с сообщением о успехе. Если происходит ошибка, она захватывает ошибку и возвращает статус-код 500 с сообщением об ошибке.
Удаление кофе Lambda-функции
Эта функция удаляет элемент кофе по его ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
Лямбда-функция удаляет конкретный заказ на кофе из таблицы DynamoDB. В функции-обработчике код анализирует тело запроса для извлечения order_id и customer_name. Эти значения используются в качестве первичного ключа для идентификации элемента, который должен быть удален из таблицы. Объект params указывает имя таблицы и ключ для удаляемого элемента.
В блоке try код пытается удалить заказ из DynamoDB, используя метод delete(). Если это удастся, он снова возвращает код состояния 200 с сообщением о успехе, указывая, что заказ был удален. Если произойдет ошибка, код ее ловит и возвращает код состояния 500 вместе с сообщением об ошибке.
Теперь, когда мы объяснили каждую лямбда-функцию, давайте настроим многоступенчатый CI/CD-пайплайн.
Шаг 4: Настройте многоступенчатые развертывания CI/CD-пайплайна для сред окружения Dev и Prod
Чтобы настроить секреты AWS в вашем репозитории GitHub, сначала перейдите к настройкам репозитория. Выберите Settings в правом верхнем углу, затем в левом нижнем углу выберите Secrets and variables.

Далее, нажмите на Actions, как показано на картинке ниже:
Там выберите New repository secret для создания секретов.
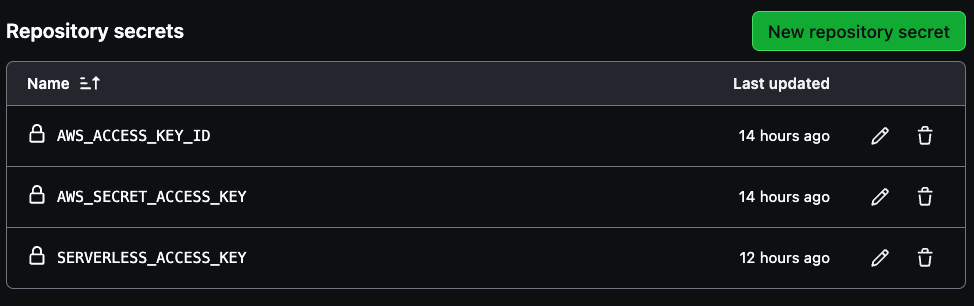
Требуется создать три секрета для вашего пайплайна: AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY и SERVERLESS_ACCESS_KEY.
Используйте учетные данные ключа доступа к AWS для первых двух переменных, а затем сохраненный ранее серверный ключ доступа для создания SERVERLESS_ACCESS_KEY. Эти секреты будут безопасно аутентифицировать вашу CI/CD конвейер, как показано на изображении ниже.
Убедитесь, что ваша основная ветка называется “main,” так как она будет являться веткой производства. Затем создайте новую ветку под названием “dev” для работы над разработкой.
Вы также можете создавать ветки, специфичные для функций, например, “dev/feature,” для более детальной разработки. GitHub Actions будет использовать эти ветки для автоматической развертки изменений, где dev представляет среду разработки, а main представляет производство.
Эта стратегия ветвления позволяет вам эффективно управлять CI/CD конвейером, разворачивая новые изменения кода при каждом слиянии во ветки dev или prod.
Как использовать GitHub Actions для развертывания файла YAML
Чтобы автоматизировать процесс развертывания для API Кофейни, вы будете использовать GitHub Actions, который интегрируется с вашим репозиторием GitHub.
Этот конвейер развертывания активируется при каждом отправлении кода в ветки main или dev. Конфигурируя развертывания для специфических сред, вы обеспечите, что обновления ветки dev разворачиваются в среду разработки, в то время как изменения ветки main активируют развертывания в производственной среде.
Теперь давайте рассмотрим код:
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
Сonfigурация YAML GitHub Actions автоматизирует процесс развёртывания Coffee Shop API на AWS с использованием Serverless Framework. Рабочий процесс запускается при любом push изменений в основной или dev ветки.
Он начинается с проверки кода репозитория, затем устанавливает Node.js с версией 20.x, чтобы соответствовать рантайму, используемому Lambda-функциями. После этого он устанавливает зависимости проекта, перемещаясь в каталог coffee-shop-api и выполняя npm install.
Рабочий процесс также устанавливает Serverless Framework глобально, что позволяет использовать CLI серверлесс для развёртывания. В зависимости от того, какая ветка обновлена, рабочий процесс условно разворачивает в соответствующей среде.
Если изменения push-ятся в dev ветку, он разворачивает в dev стадию. Если в основную ветку, он разворачивает в prod стадию. Команды развёртывания, npx serverless deploy --stage dev или npx serverless deploy --stage prod, выполняются в каталоге coffee-shop-api.
Для безопасного развёртывания рабочий процесс использует учетные данные AWS и ключ доступа Serverless из переменных среды, сохранённых в GitHub Secrets. Это позволяет CI/CD-пайплайну аутентифицироваться с AWS и Serverless Framework без экспозиции конфиденциальной информации в репозитории.
Теперь мы можем приступить к тестированию пайплайна.
Шаг 5: Тестирование Dev и Prod пайплайнов.
Первым делом тебе нужно убедиться, что основной (prod) ветвь называется “main“. Затем создай ветвь dev, назвав ее “dev“. Как только ты внесешь какие-либо действительные изменения в ветвь dev, сохраняй их, чтобы запустить конвейер GitHub Actions. Это автоматически развернет обновленные ресурсы в среду разработки. После того, как ты все проверишь в dev, ты можешь объединить ветвь dev с основной ветвью.
Объединение изменений в основной ветви также автоматически запускает конвейер развертывания для производственной среды. Таким образом, все необходимые обновления применяются, и ресурсы производства развертываются гладко.
Ты можешь отслеживать процесс развертывания и просматривать подробные журналы каждого запуска GitHub Actions, переходя на вкладку “Actions” в своем репозитории GitHub.
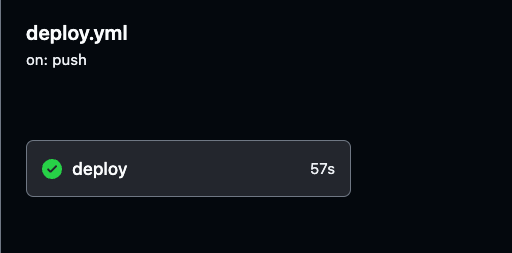
Журналы предоставляют информацию о каждом шаге конвейера, помогая тебе убедиться, что все работает как ожидалось.
Ты можешь выбрать любой запуск сборки, чтобы просмотреть подробные журналы для развертывания среды разработки и производственной среды, чтобы отслеживать прогресс и убедиться, что все идет гладко.
Перейди к конкретному запуску сборки в GitHub Actions, как показано на изображении ниже. Там ты можешь просмотреть подробности выполнения и результаты для конвейеров разработки или производства.

Убедись, что ты тщательно протестировал обе среды разработки и производства, чтобы подтвердить успешное выполнение конвейера.
Шаг 6: Тестируй и валидируй API Prod и Dev с использованием Postman.
Сейчас, когда API и ресурсы развернуты и настроены, нам нужно найти уникальные конечные точки API (URL-адреса), сгенерированные AWS, чтобы начать отправлять запросы для тестирования функциональности.
Эти URL могут тестировать функциональность API просто путем их вставки в веб-браузер. URL API находятся в выводе результатов вашего CI/CD сборки.
Чтобы получить их, перейдите к журналам GitHub Actions, выберите успешную сборку последнего окружения и нажмите развернуть, чтобы проверить подробности развертывания сгенерированных конечных точек API.
Нажмите на этап Развернуть на AWS для выбранного окружения (Prod или Dev) в журналах GitHub Actions. Там вы найдете сгенерированный URL API.
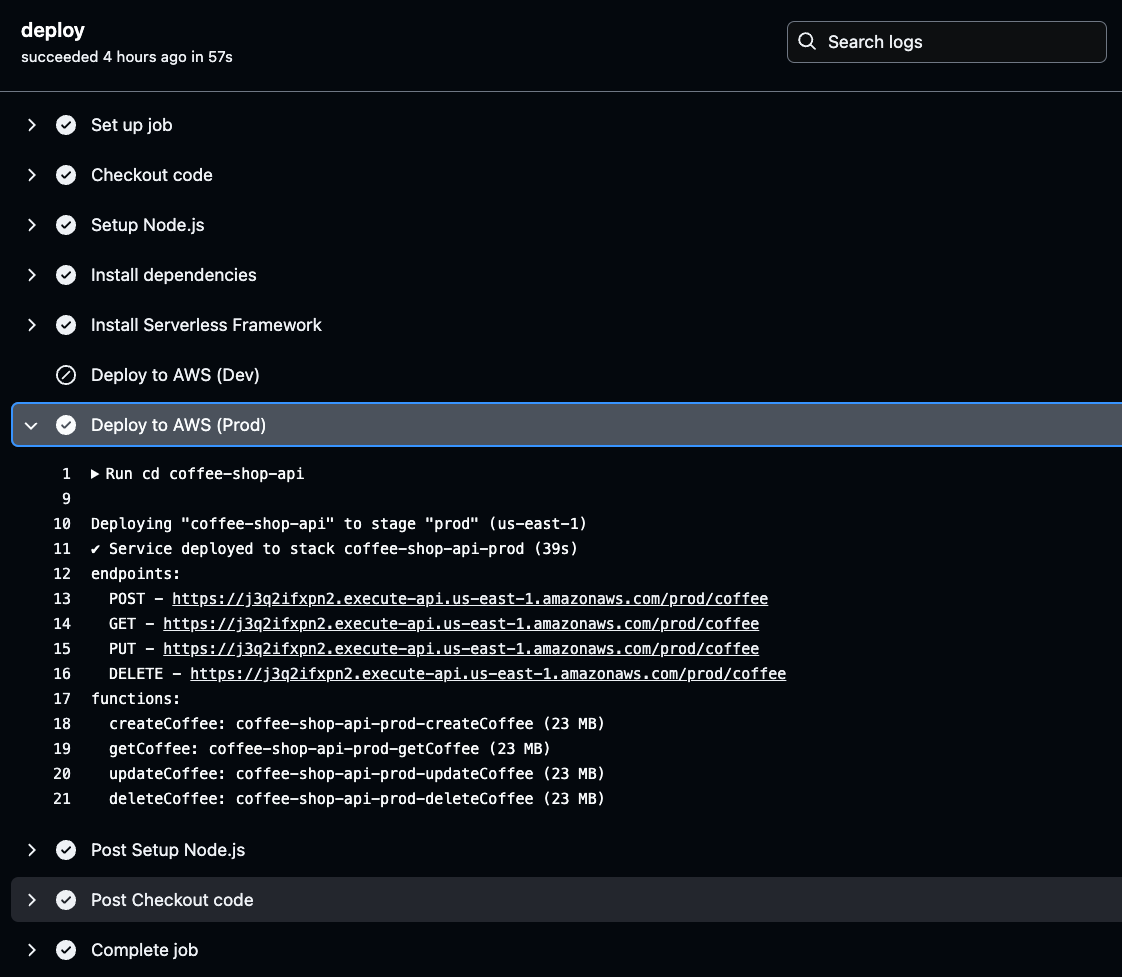
Скопируйте и сохраните этот URL, так как он понадобится при тестировании функциональности вашего API. Этот URL является вратами для подтверждения того, что развернутый API работает как ожидается.
Теперь скопируйте один из сгенерированных URL API и вставьте его в ваш браузер. Вы увидите пустой массив или список в ответе. Это фактически подтверждает, что API функционирует правильно, и что вы успешно извлекаете данные из таблицы DynamoDB.
Хотя список пуст, он указывает, что API может подключаться к базе данных и возвращать информацию.
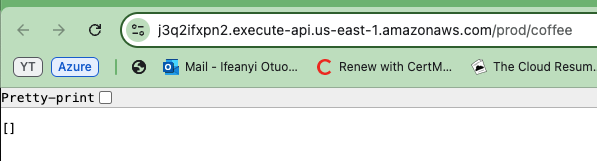
Чтобы убедиться, что ваш API работает в обоих окружениях, повторите шаги для другого окружения API (Prod и Dev).
Для более тщательных тестов мы будем использовать Postman, чтобы протестировать все методы API: Create, Read, Update и Delete, и выполнить эти тесты как для разрабатываемой, так и для производственной среды.
Чтобы протестировать метод GET, используйте Postman, чтобы отправить GET-запрос на концепт API с помощью URL. Вы получите тот же ответ, пустую корзину заказов кофе, как показано внизу картинки ниже. Это подтверждает способность API успешно извлекать данные, как показано на картинке ниже.

Чтобы фактически создать заказ, попробуем протестировать метод POST. Use Postman again to make a POST request to the API endpoint, providing the customer’s name and coffee blend in the request body, as show below :
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
Ответ будет сообщением о успешном создании с уникальным OrderId заказа.
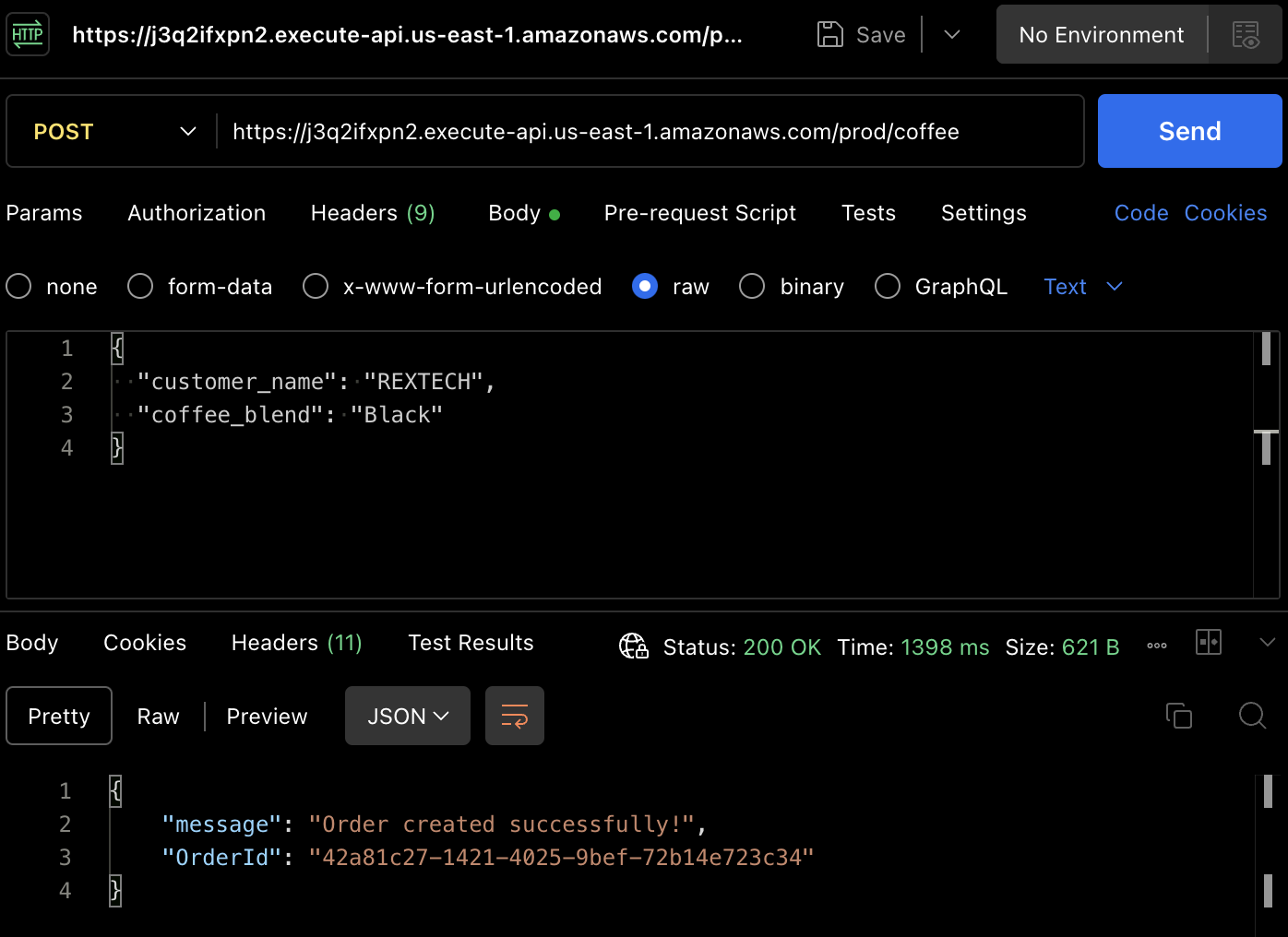
Проверьте, что новый заказ был сохранен в таблице DynamoDB, просмотряте товары в специфической таблице среды:

Чтобы протестировать метод PUT, сделайте PUT-запрос к концепту API, указав предыдущий ID заказа и новый статус заказа в теле запроса, как показано ниже :
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
Ответ будет сообщением о успешном обновлении заказа с OrderId заказа.
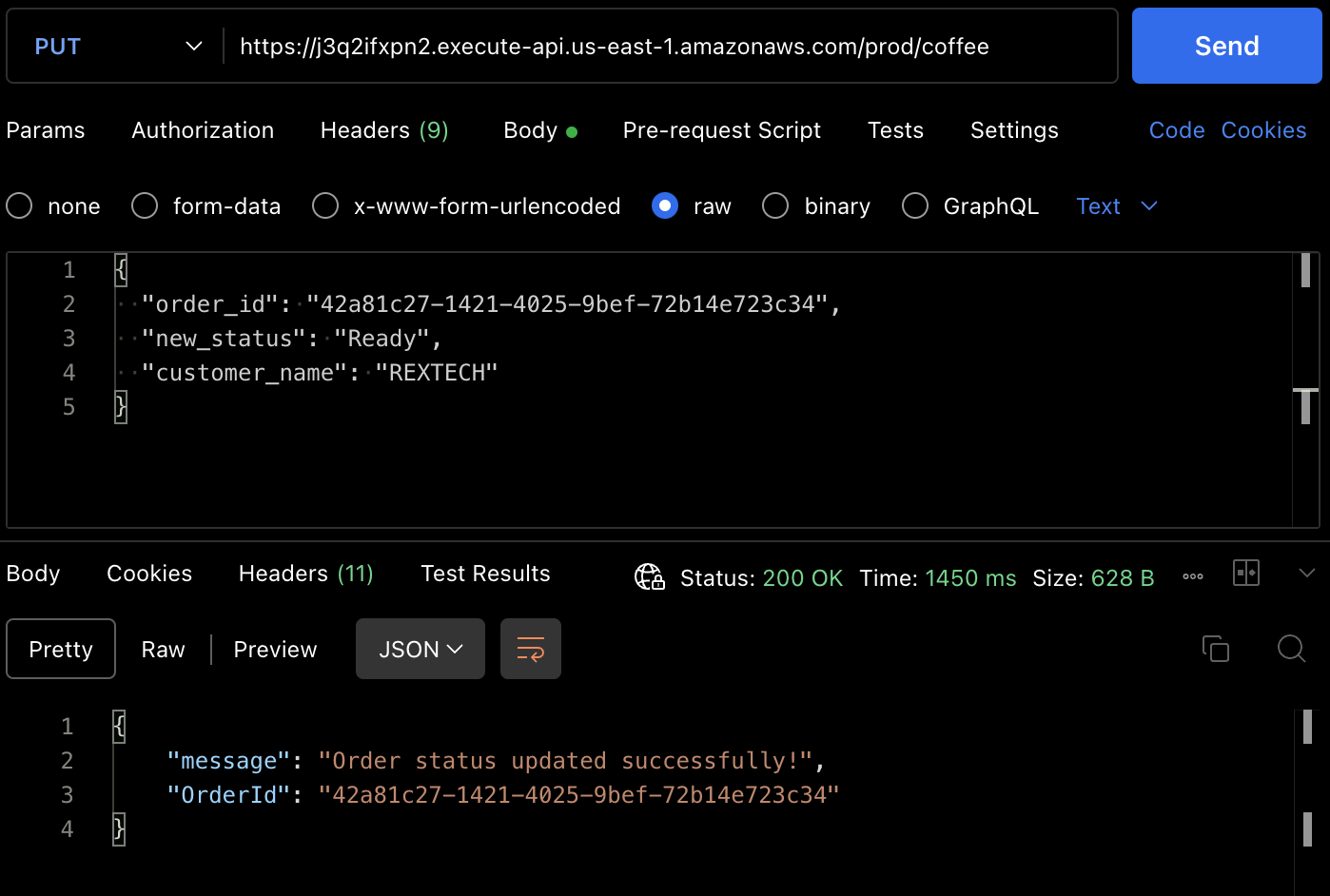
Вы также можете проверить, что статус заказа был обновлен из элемента таблицы DynamoDB.

Чтобы протестировать метод DELETE, используйте Postman, чтобы сделать DELETE-запрос, указав предыдущий ID заказа и имя клиента в теле запроса, как показано ниже:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
Заказ успешно удален.
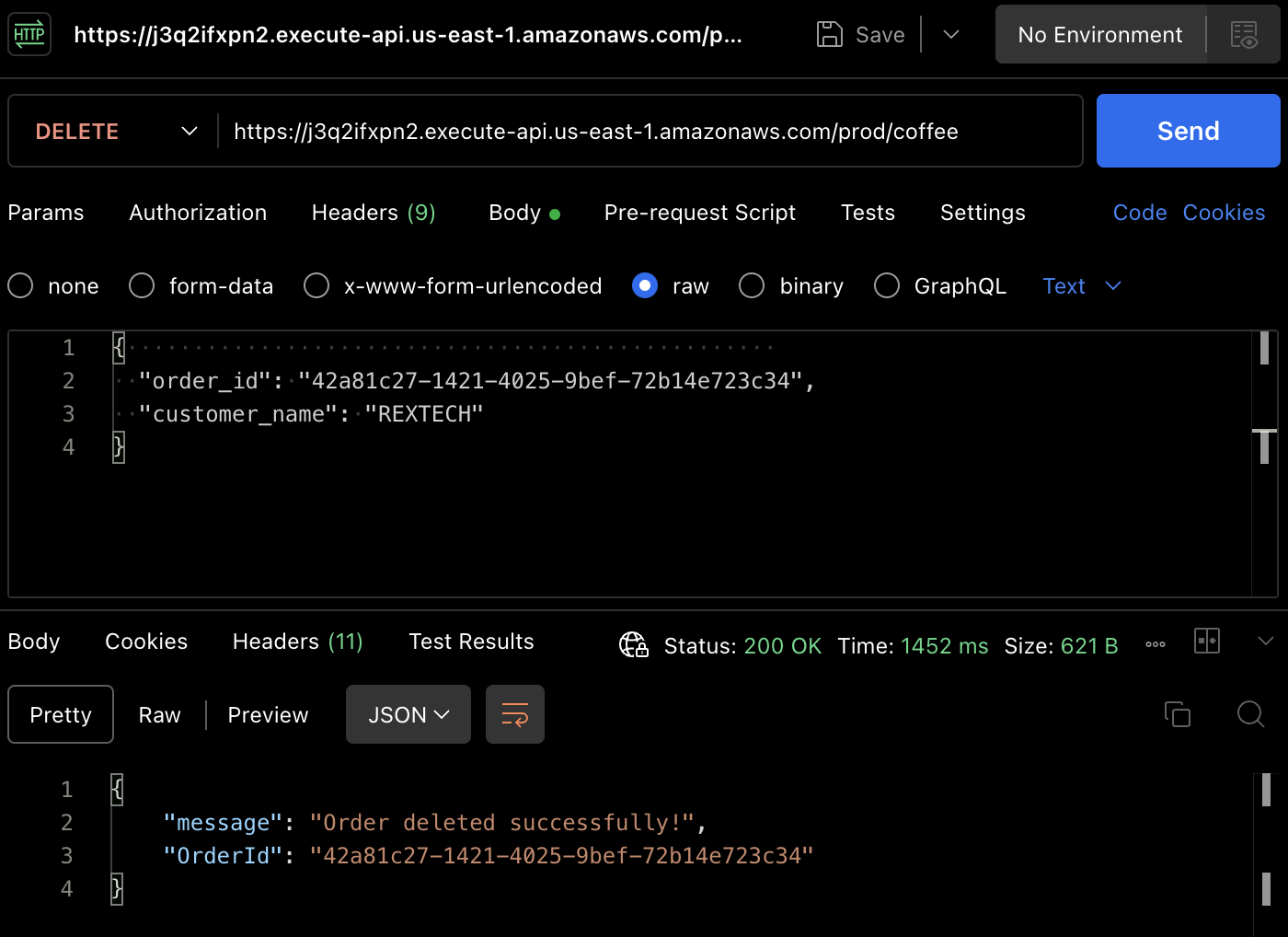
Еще раз проверьте, что заказ был удален из таблицы DynamoDB.

Заключение
Итак, это все – поздравляем! Вы успешно прошел все шаги. Мы создали безсерверную REST API, которая поддерживает CRUD- (Create, Read, Update, Delete) функциональность с использованием API Gateway, Lambda, DynamoDB, Serverless Framework и Node.js, а также автоматизации развертывания одобренных изменений кода с помощью Github Actions.
Если вы дошел до этого места, спасибо за прочтение! надеемся, что это было вам полезно.
Ifeanyi Otuonye – 6X AWS Certified Cloud Engineer, специалист в области DevOps, технического письма и инструкторских навыков как технический инструктор. Его мотивирует нетерпение учиться и развиваться и он преуспевает в коллективных рабочих ситуациях. перед тем как перейти на облачные технологии, он провел шесть лет в качестве профессионального бегуна на счетной дорожке.
В начале 2022 года он стратегически выбрал цель стать Cloud/DevOps Engineer через самостоятельное изучение и присоединение к 6-месячному ускоренному облачному программе.
В мае 2023 года он достиг этой цели и получил свой первый пост Cloud Engineer и теперь намерен оказать поддержку другим людям на их пути к облакам.
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/