













A computação serverless surgiu como uma resposta aos desafios das arquiteturas tradicionais baseadas em servidores. Com o serverless, os desenvolvedores não precisam mais gerenciar ou escalar servidores manualmente. Em vez disso, os provedores de nuvem cuidam do gerenciamento da infraestrutura, permitindo que as equipes se concentrem apenas em escrever e implantar código.
As soluções serverless escalam automaticamente com base na demanda e oferecem um modelo de pagamento conforme o uso. Isso significa que você paga apenas pelos recursos que sua aplicação realmente utiliza. Essa abordagem reduz significativamente a sobrecarga operacional, aumenta a flexibilidade e acelera os ciclos de desenvolvimento, tornando-a uma opção atraente para o desenvolvimento de aplicações modernas.
Ao abstrair o gerenciamento de servidores, as plataformas serverless permitem que você se concentre em lógica de negócios e na funcionalidade da aplicação. Isso leva a implantações mais rápidas e maior inovação. As arquiteturas serverless também são orientadas por eventos, o que significa que elas podem responder automaticamente a eventos em tempo real e escalar para atender às demandas dos usuários sem intervenção manual.
Índice
Antes de mergulhar nos detalhes técnicos, vamos repassar alguns conceitos chave de fundo.
Conceitos Importantes para Entender
Interface de Programação de Aplicações (API)
Uma API permite que aplicações de software diferentes se comuniquem e interajam entre si. Ela define os métodos e formatos de dados que as aplicações podem usar para solicitarem e trocarem informação para integração e compartilhamento de dados entre sistemas diversos.
Métodos HTTP
Métodos HTTP ou métodos de solicitação são um componente crítico de serviços web e APIs. Eles indicam a ação desejada para ser executada em um recurso em uma URL de solicitação dada.
Os métodos mais comumente usados em APIs RESTful são:
-
GET: usado para recuperar dados de um servidor
-
POST: envia dados, incluídos no corpo da solicitação, para criar ou atualizar um recurso
-
PUT: atualiza ou substitui um recurso existente ou cria um novo recurso se ele não existir
-
DELETE: exclui os dados especificados do servidor.
Gateway da API do Amazon
Amazon API Gateway é um serviço gerenciado integralmente que facilita para os desenvolvedores criar, publicar, manter, monitorar e segurar APIs em escala. Ele atua como ponto de entrada para múltiplas APIs, gerenciando e controlando as interações entre clientes (como aplicações web ou móveis) e serviços backend.
Ele também fornece várias funções, incluindo roteamento de solicitação, segurança, autenticação, cache e limitação de taxa, que ajudam a simplificar o gerenciamento e implantação de APIs.
Amazon DynamoDB
DynamoDB é um serviço de banco de dados NoSQL gerenciado integralmente projetado para altas escalas, baixas latências e replicação de dados em várias regiões.
DynamoDB armazena dados em um formato sem esquema, permitindo o armazenamento e recuperação flexíveis e rápidos de dados estruturados e semi-estruturados. É comumente usado para construir aplicações escaláveis e responsivas em ambientes baseados em nuvem.
Aplicação CRUD sem Servidor
Uma aplicação CRUD sem servidor se refere à capacidade de Criar, Ler, Atualizar e Excluir dados. Mas a arquitetura e componentes envolvidos diferem das aplicações tradicionais baseadas em servidores.
Criar envolve adicionar novas entradas a uma tabela DynamoDB. A operação Ler recupera dados de uma tabela DynamoDB. Atualizar atualiza dados existentes em DynamoDB. E a operação Excluir exclui dados de DynamoDB.
O Framework Serverless
O Serverless Framework é uma ferramenta de código aberto que simplifica a implantação e o gerenciamento de aplicações sem servidores em vários provedores de nuvem, incluindo AWS. Ele abstrai a complexidade da provisionação e do gerenciamento de infraestrutura, permitindo que os desenvolvedores defina sua infraestrutura como código usando um arquivo YAML.
O framework gerencia a implantação, a escalada e a atualização de funções sem servidor, APIs e outros recursos.
GitHub Actions
GitHub Actions é uma potente ferramenta de automação CI/CD que permite que os desenvolvedores automatiquem seus fluxos de trabalho de software diretamente de seu repositório GitHub.
Com GitHub Actions, você pode criar pipelines personalizados disparados por eventos como envios de código, pull requests ou fusões de branch. Estes fluxos de trabalho são definidos em arquivos YAML no repositório e podem executar tarefas como testes, builds e implantações de aplicações em vários ambientes.
Postman
Postman é uma popular plataforma de colaboração que simplifica o processo de projeto, teste e documentação de APIs. Ele oferece uma interface amigável para os desenvolvedores criarem e enviarem solicitações HTTP, testarem pontos finais de API e automatizar fluxos de teste.
Bem, agora que você está familiarizado com as ferramentas e tecnologias que usaremos aqui, vamos mergulhar.
Pré-requisitos
-
Node.js e npm instalados
-
AWS CLI configurado com acesso a sua conta AWS
-
Uma conta do Serverlesss Framework
-
Serverlesss Framework instalado globalmente na sua CLI local
Nosso Caso de Uso
Conheça Alyx, uma empresária que recentemente começou a aprender sobre arquitetura serverless. Ela leu sobre como é uma maneira poderosa e eficiente de construir backends para aplicações web, oferecendo uma abordagem mais moderna ao desenvolvimento de aplicações web.
Elle quer aplicar o que aprendera até agora sobre os fundamentos de computação serverless do AWS. Ela sabe que “serverless” não significa que não há servidores envolvidos – antes, ele apenas abstrai a gestão e a provisionação de servidores. E agora ela quer se concentrar exclusivamente em escrever código e implementar lógica de negócios.
Vamos ver como Alyx, dona de um crescente café, começa a aproveitar a arquitetura serverless para o backend da sua aplicação web.
O Alyx’s Coffee Haven, um café online, oferece uma variedade de misturas de café e bolos para venda. Inicialmente, Alyx gerenciou as ordens e o estoque do seu estabelecimento com serviços de hospedagem web tradicionais e operações, onde ela gerenciou vários servidores e recursos. Mas conforme o seu café ganhou popularidade, ela começou a enfrentar um número crescente de pedidos, especialmente durante as horas de pico e promoções sazonais.
Gerenciar os servidores e assegurar que a aplicação pudesse suportar o aumento de tráfego tornou-se um desafio para Alyx. Ela encontrou-se constantemente preocupada com a capacidade dos servidores, a escalabilidade e o custo de manutenção da infraestrutura.
Elle também queria introduzir novos recursos como recomendações personalizadas e programas de fidelidade, mas isso se tornou uma tarefa assustadora diante das limitações de sua configuração tradicional.
Alyx aprendeu sobre o conceito de serverless. Ela comparou um backend serverless a um barista que faz café em tempo real automaticamente, sem ela ter que se preocupar com os detalhes intrincados do processo de preparo do café.
Excitada com esta ideia, Alyx decidiu migrar o backend da sua cafeteria para uma plataforma serverless usando AWS Lambda, AWS API Gateway e Amazon DynamoDB. Esta configuração permitirá que ela se concentre mais em criar as melhores misturas de café e guloseimas para seus clientes.
Com o serverless, cada pedido do cliente se torna um evento que aciona uma série de funções serverless. Funções AWS Lambda separadas processam os pedidos e gerenciam toda a lógica de negócios por trás das cenas. Por exemplo, cria o pedido de um cliente e consegue recuperar esse pedido. Também pode excluir o pedido de alguém ou atualizar o status de um pedido.
Alyx já não precisa se preocupar com a gestão de servidores, pois a plataforma serverless escala automaticamente para cima e para baixo com base nas solicitações de pedidos recebidas. Além disso, a eficiência de custo do serverless é enorme para Alyx. Com um modelo de pagamento à medida, ela só paga pelo tempo de computação real que suas funções consomem, oferecendo-lhe uma solução mais eficiente para o seu negócio crescente.
Mas ela não para aí! Ela também quer automatizar tudo, desde a implantação da infraestrutura até a atualização de sua aplicação sempre que houver um novo cambio. Utilizando a Infraestrutura como Código (IaC) com o Serverless Framework, ela pode definir toda sua infraestrutura em código e gerenciá-la facilmente.
Além disso, ela configura GitHub Actions para integração e entrega contínuos (CI/CD), para que todos os cambios que ela faz sejam implantados automaticamente através de um pipeline, quer seja um novo recurso em desenvolvimento ou um hot fix para a produção.
Objetivos do Tutorial
-
Configurar o ambiente do Serverless Framework
-
Definir uma API no arquivo YAML
-
Desenvolver funções AWS Lambda para processar operações CRUD
-
Configurar deployments de múltiplas fases para Dev e Prod
-
Testar os pipelines Dev e Prod
-
Testar e validar APIs Dev e Prod usando Postman
Como começar: Clonar o Repositório Git
Para melhorar sua compreensão e deixar você seguir o tutorial com maior eficácia, vá à frente e clonar o repositório do projeto do meu GitHub. Você pode fazer isso navegando até aqui. Enquanto avançamos, sinta-se à vontade para editar os arquivos conforme necessário.
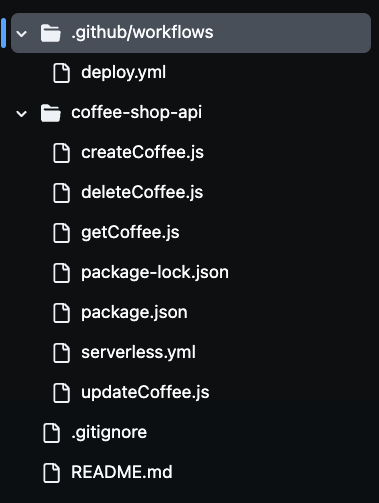
Após clonar o repositório, você notará a presença de vários arquivos na sua pasta, como mostrado na imagem abaixo. Nós usaremos todos esses arquivos para construir nossa API de cafeteria sem servidor.
Passo 1: Configurar o Ambiente do Serverless Framework
Para configurar o ambiente do Serverless Framework para implantações automatizadas, você precisará autenticar sua conta do Serverless via CLI.
Isso requer a criação de uma chave de acesso que permite o pipeline CI/CD e utiliza o Serverless Framework para se autenticar de forma segura em sua conta sem expor suas credenciais. Assinando na sua conta do Serverless e gerando uma chave de acesso, o pipeline pode implantar sua aplicação sem servidor automaticamente a partir do arquivo de configuração de build.
Para isso, vá para sua conta do Serverless e navegue até a seção de Chaves de Acesso. Clique em “+adicionar”, nomeie-a SERVERLESS_ACCESS_KEY, e então crie a chave.
Uma vez que você criou sua chave de acesso, certifique-se de copiá-la e armazená-la de forma segura. Você usará essa chave como variável secreta em seu repositório do GitHub para autenticar e autorizar seu pipeline CI/CD.
O mesmo fornecerá acesso à sua conta do Framework Serverless durante o processo de implantação. Você adicionará essa chave ao segredo do repositório do GitHub mais tarde, para que sua pipeline possa usá-la de forma segura para implantar recursos serverless sem expor informações sensíveis no seu código-fonte.
Agora, vamos definir os recursos AWS como código no arquivo severless.yaml.
Passo 2: Defina o API no Arquivo YAML Serverless
Neste arquivo, você definirá a infraestrutura e funcionalidade básicas da API do Café Shop usando a configuração YAML do Framework Serverless.
Este arquivo define os serviços AWS em uso, incluindo o API Gateway, funções Lambda para operações CRUD e DynamoDB para armazenamento de dados.
Você também configurará um papel IAM para que as funções Lambda tenham as permissões necessárias para interagir com o serviço DynamoDB.
O API Gateway está configurado com métodos HTTP (POST, GET, PUT e DELETE) para lidar com solicitações de entrada e disparar as funções Lambda correspondentes.
Vamos ver o código:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
A configuração serverless.yml define como a API do Café Shop de Alyx vai funcionar em um ambiente serverless no AWS. A seção provider especifica que o aplicativo vai usar AWS como provedor de nuvem, com Node.js como o ambiente de execução runtime.
A região está definida para us-east-1 e a variável stage permite a implantação dinâmica em diferentes ambientes, como dev e prod. Isso significa que o mesmo código pode implantar em diferentes ambientes, com recursos sendo nomeados de acordo para evitar conflitos.
Na seção iam, permissões são concedidas às funções Lambda para interagir com a tabela DynamoDB. A sintaxe ${self:provider.stage} nomeia dinamicamente a tabela DynamoDB, para que cada ambiente tenha seus próprios recursos separados, como CoffeeOrders-dev para o ambiente de desenvolvimento e CoffeeOrders-prod para a produção. Esse nomeamento dinâmico ajuda a gerenciar múltiplos ambientes sem configurar tabelas separadas manualmente para cada um.
A seção functions define as quatro funções básicas Lambda, createCoffee, getCoffee, updateCoffee e deleteCoffee. Essas gerenciam as operações CRUD para a API do Café.
Cada função está conectada a um método HTTP específico na API Gateway, como POST, GET, PUT e DELETE. Essas funções interagem com a tabela DynamoDB que é nomeada dinamicamente com base no estágio atual.
A última seção resources define a própria tabela DynamoDB. Ela configura a tabela com os atributos OrderId e CustomerName, que são usados como chave primária. A tabela é configurada para usar o modelo de cobrança por pedido, tornando-a eficiente financeiramente para o crescimento do negócio de Alyx.
Ao automatizar a implantação desses recursos usando o Framework Serverless, Alyx consegue gerenciar sua infraestrutura com facilidade, livrando-se do encargo de provisionar e dimensionar recursos manualmente.
Passo 3: Desenvolver as Funções Lambda para Operações CRUD
Neste passo, implementamos a lógica central do API do Café da Alyx criando funções Lambda com JavaScript que realizam as operações básicas CRUD createCoffee, getCoffee, updateCoffee e deleteCoffee.
Essas funções usam o AWS SDK para interagir com os serviços da AWS, particularmente com DynamoDB. Cada função será responsável por tratar determinados pedidos de API, como criar um pedido, recuperar pedidos, atualizar status de pedidos e excluir pedidos.
Função Lambda Criar Café
Esta função cria um pedido:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
Esta função Lambda trata da criação de um novo pedido de café na tabela DynamoDB. Primeiro importamos o AWS SDK e inicializamos um DynamoDB.DocumentClient para interagir com DynamoDB. A biblioteca uuid também é importada para gerar IDs de pedido únicos.
Dentro da função handler, nós parseamos o corpo do pedido de entrada para extrair informações do cliente, como o nome do cliente e a mistura de café preferida. Um ID de pedido único orderId é gerado usando uuidv4() e esses dados são preparados para inserção na DynamoDB.
O objeto params define a tabela onde os dados serão armazenados, com TableName definido de forma dinâmica para o valor da variável de ambiente COFFEE_ORDERS_TABLE. O novo pedido inclui campos como OrderId, CustomerName, CoffeeBlend, e um status inicial de Pending.
No bloco try, o código tenta adicionar o pedido à tabela DynamoDB usando o método put(). Se bem sucedido, a função retorna um código de status de 200 com uma mensagem de sucesso e o OrderId. Se houver um erro, o código o captura e retorna um código de status de 500 juntamente com uma mensagem de erro.
Função Get Coffee Lambda
Esta função recupera todos os itens de café:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
Esta função Lambda é responsável por recuperar todos os pedidos de café de uma tabela DynamoDB e exemplifica uma abordagem sem servidor para recuperar dados de DynamoDB de forma escalável.
Novamente, usamos o AWS SDK para inicializar uma instância de DynamoDB.DocumentClient para interagir com DynamoDB. A função handler constrói o objeto params, especificando o TableName, que é definido de forma dinâmica usando a variável de ambiente COFFEE_ORDERS_TABLE.
O método scan() recupera todos os itens da tabela. novamente, se a operação for bem-sucedida, a função retorna um código de status 200 juntamente com os itens recuperados no formato JSON. Em caso de erro, um código de status 500 e uma mensagem de erro são retornados.
Atualizar função de café Lambda
Esta função atualiza um item de café por meio de seu ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
Esta função Lambda trata de atualizar o status de um pedido de café específico na tabela DynamoDB.
A função handler extrai o order_id, new_status e customer_name do corpo da requisição. Então, ela constrói o objeto params para especificar o nome da tabela e a chave primária para o pedido (usando OrderId e CustomerName). A UpdateExpression define o novo status do pedido.
No bloco de try, o código tenta atualizar o pedido no DynamoDB usando o método update(). Novamente, claro, se bem-sucedida, a função retorna um código de status de 200 com uma mensagem de sucesso. Se ocorrer um erro, ela pega o erro e retorna um código de status de 500 juntamente com uma mensagem de erro.
Excluir função de café Lambda
Esta função exclui um item de café por meio de seu ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
A função Lambda elimina um pedido de café específico da tabela DynamoDB. Na função de handler, o código analisa o corpo da requisição para extrair o order_id e o customer_name. Esses valores são usados como chave primária para identificar o item a ser excluído da tabela. O objeto params especifica o nome da tabela e a chave para o item a ser excluído.
No bloco try, o código tenta excluir o pedido de DynamoDB usando o método delete(). Se bem sucedido, novamente ele retorna um código de status 200 com uma mensagem de sucesso, indicando que o pedido foi excluído. Caso ocorra um erro, o código captura-o e retorna um código de status 500 junto de uma mensagem de erro.
Agora que explicamos cada função Lambda, vamos configurar um pipeline CI/CD de fases múltiplas.
Passo 4: Configurar deployments de pipeline de fases múltiplas para ambientes Dev e Prod
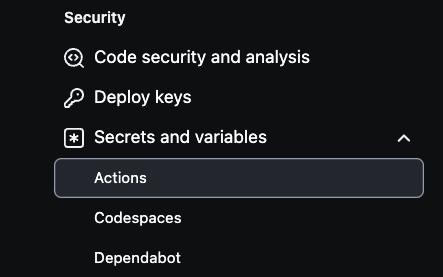
Para configurar segredos AWS em seu repositório GitHub, primeiro vá para as configurações do repositório. Selecione Settings no canto superior direito, em seguida, vá para o lado inferior esquerdo e selecione Secrets and variables.

A seguir, clique em Actions como visto na imagem abaixo:
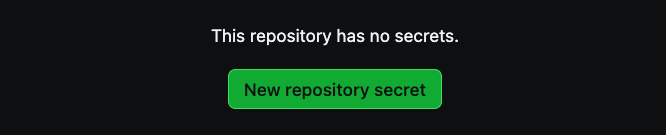
A partir daí, selecione New repository secret para criar segredos.
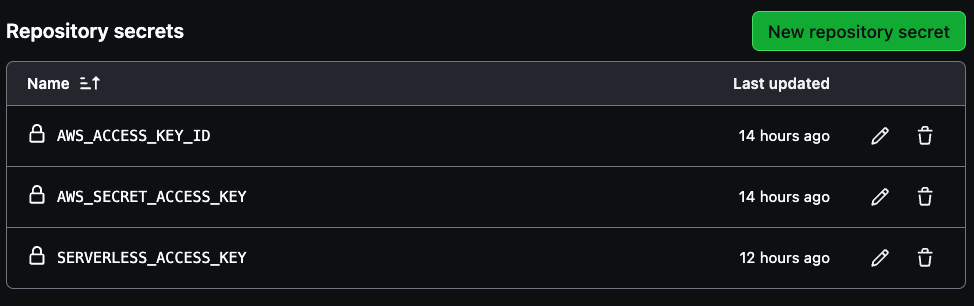
São necessários três segredos para criar para seu pipeline, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, e SERVERLESS_ACCESS_KEY.
Use as credenciais de acesso da sua conta AWS para as duas primeiras variáveis e, em seguida, a chave de acesso serverless anteriormente salva para criar o SERVERLESS_ACCESS_KEY. Estes segredos autenticarão seguramente seu pipeline CI/CD como visto na imagem abaixo.
Certifique-se de que sua branch principal seja nomeada “main“, pois isso servirá como a branch de produção. Em seguida, crie uma nova branch chamada “dev” para trabalho de desenvolvimento.
Você também pode criar branches específicos de funcionalidade, como “dev/feature“, para desenvolvimento mais granular. As Ações do GitHub usarão essas branches para implantar mudanças automaticamente, com dev representando o ambiente de desenvolvimento e main representando a produção.
Estratégia de branching que permite gerenciar o pipeline CI/CD eficientemente, implantando novas mudanças de código sempre que houver uma mescla para ambientes de dev ou prod.
Como Usar as Ações do GitHub para Implantar o Arquivo YAML
Para automatizar o processo de implantação para a API do Café, você utilizará as Ações do GitHub, que integra-se com o seu repositório GitHub.
Este pipeline de implantação é disparado sempre que o código é empurrado para as branchs main ou dev. Configurando implantações específicas de ambiente, você garantirá que atualizações na branch dev sejam implantadas no ambiente de desenvolvimento, enquanto mudanças na branch main disparam implantações de produção.
Agora, vamos revisar o código:
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
A configuração YAML do GitHub Actions é o que automatiza o processo de implantação da API do Café da Loja para o AWS usando o Serverless Framework. O fluxo de trabalho é disparado toda vez que há mudanças enviadas para as branches principal ou de desenvolvimento.
Ele começa verificando o código do repositório, depois configura o Node.js com a versão 20.x para se adequar à versão de runtime usada pelas funções Lambda. Depois disso, instala as dependências do projeto navegando até o diretório coffee-shop-api e executando npm install.
O fluxo de trabalho também instala o Serverless Framework globalmente, permitindo que a CLI serverless seja usada para implantações. Dependendo de qual branch é atualizada, o fluxo de trabalho implanta condicionalmente para o ambiente apropriado.
Se as mudanças são enviadas para a branch de desenvolvimento, elas são implantadas para a estação de desenvolvimento. Se são enviadas para a branch principal, elas são implantadas para a estação de produção. Os comandos de implantação, npx serverless deploy --stage dev ou npx serverless deploy --stage prod são executados dentro do diretório coffee-shop-api.
Para uma implantação segura, o fluxo de trabalho acessa as credenciais AWS e a chave de acesso Serverless via variáveis de ambiente armazenadas em Segredos do GitHub. Isso permite que o pipeline CI/CD se autentique com AWS e o Serverless Framework sem expor informações sensíveis no repositório.
Agora, podemos prosseguir para testar o pipeline.
Passo 5: Teste o Pipeline Dev e Prod
Primeiro, você precisará verificar se o branch principal (prod) é chamado “main“. Em seguida, crie um branch de desenvolvimento chamado “dev“. Assim que fizer alterações válidas no branch dev, faça o commit para acionar o pipeline do GitHub Actions. Isso implantará automaticamente os recursos atualizados no ambiente de desenvolvimento. Após verificar tudo no dev, você pode então mesclar o branch dev no branch principal.
Mesclar alterações no branch principal também aciona automaticamente o pipeline de implantação para o ambiente de produção. Desta forma, todas as atualizações necessárias são aplicadas e os recursos de produção são implantados sem problemas.
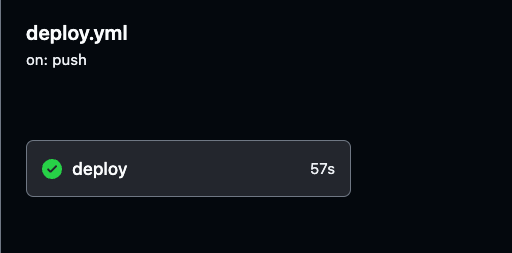
Você pode monitorar o processo de implantação e revisar logs detalhados de cada execução do GitHub Actions navegando até a aba Actions no seu repositório GitHub.
Os logs fornecem visibilidade de cada etapa do pipeline, ajudando a verificar que tudo está funcionando conforme o esperado.
Você pode selecionar qualquer execução de build para revisar logs detalhados tanto para as implantações do ambiente de desenvolvimento quanto de produção, assim você pode acompanhar o progresso e garantir que tudo esteja funcionando sem problemas.
Navegue até a execução específica de build no GitHub Actions, conforme demonstrado na imagem abaixo. Lá, você pode visualizar os detalhes de execução e resultados para os pipelines de desenvolvimento ou produção.

Certifique-se de testar minuciosamente os ambientes de desenvolvimento e produção para confirmar a execução bem-sucedida do pipeline.
Passo 6: Teste e Valide APIs de Prod e Dev usando Postman
Agora que as APIs e recursos foram implantados e configurados, precisamos localizar os pontos finais únicos (URLs) de API gerados por AWS para começar a fazer solicitudes para testar funcionalidade.
esses URLs podem testar a funcionalidade da API simplesmente colando-os the em um navegador web. Os URLs das APIs são encontrados nos resultados de saída do seu build CI/CD.
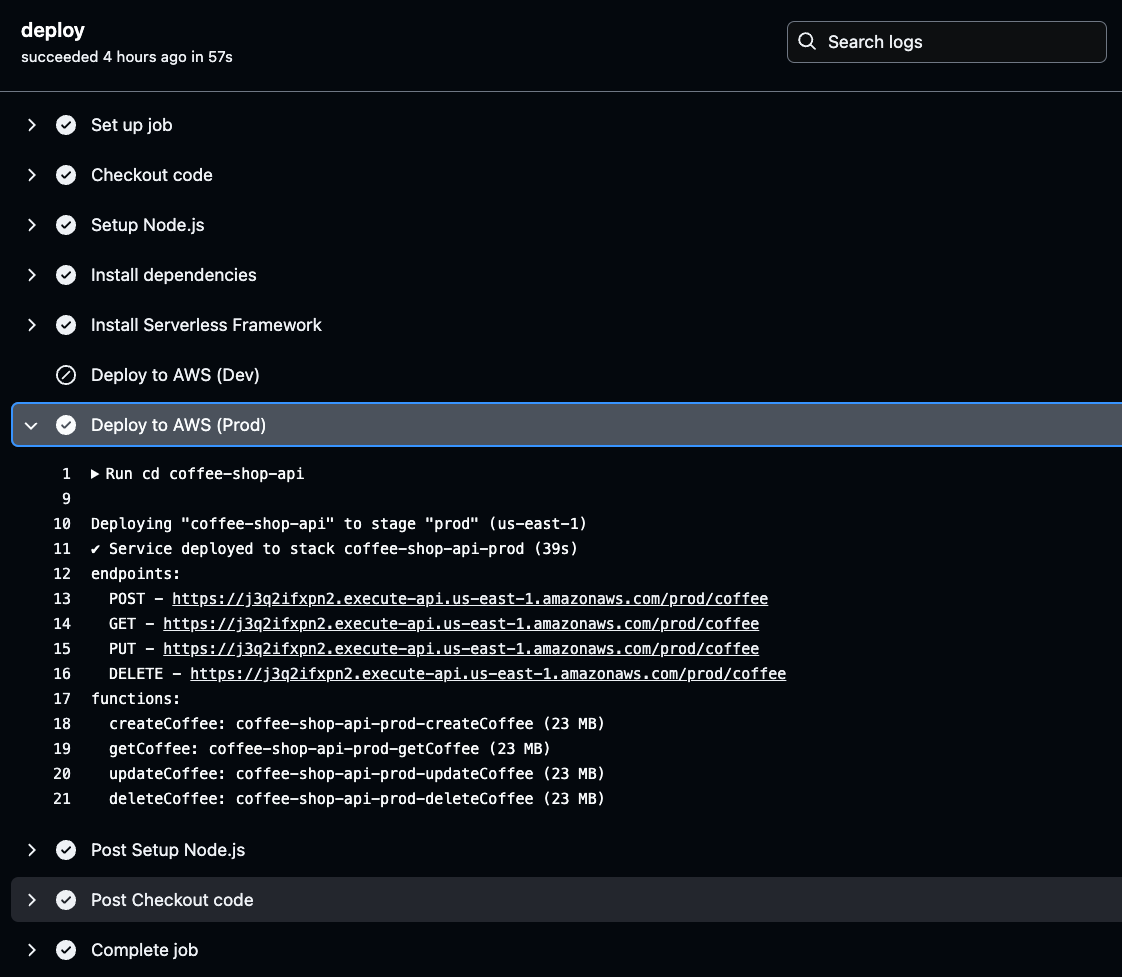
Para recuperá-los, navegue até os logs das ações do GitHub, selecione o build bem-sucedido da ambiente mais recente e clique em deploy para verificar os detalhes de implantação dos pontos finais de API gerados.
Clique no estágio Deploy to AWS para o ambiente selecionado (Prod ou Dev) em seus logs de ações do GitHub. Uma vez lá, você encontrará o URL de API gerado.
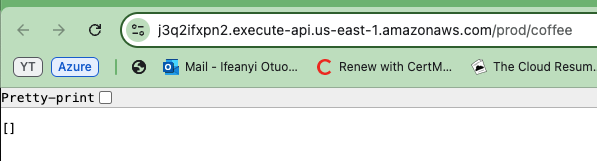
Copie e salve este URL, pois será necessário quando testar a funcionalidade da sua API. Este URL é sua porta de entrada para verificar se a API implantada funciona conforme esperado.
Agora copie um dos URLs de API gerados e coloque-o em seu navegador. Você verá uma matriz vazia ou lista exibida na resposta. Isto atualmente confirma que a API está funcionando corretamente e que você está obtendo dados com sucesso da tabela DynamoDB.
Apesar de a lista estar vazia, ela indica que a API pode se conectar ao banco de dados e retornar informações.
Para verificar se sua API funciona em ambas as ambientações, repita os passos para o outro ambiente de API (Prod e Dev).
Para testes mais abrangentes, usaremos o Postman para testar todos os métodos de API, Criar, Ler, Atualizar e Excluir, e realizaremos esses testes tanto para o ambiente de desenvolvimento quanto para o ambiente de produção.
Para testar o método GET, use o Postman para enviar uma solicitação GET para o ponto final da API usando a URL. Você receberá a mesma resposta, uma lista vazia de pedidos de café como mostrado no fundo da imagem abaixo. Isto confirma a capacidade da API de recuperar dados com sucesso, como mostrado na imagem abaixo.

Para criar realmente um pedido, vamos testar o método POST. Use o Postman novamente para fazer uma solicitação POST para o ponto final da API, fornecendo o nome do cliente e a mistura de café no corpo da solicitação, conforme mostrado abaixo:
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
A resposta será uma mensagem de sucesso com um OrderId único do pedido feito.
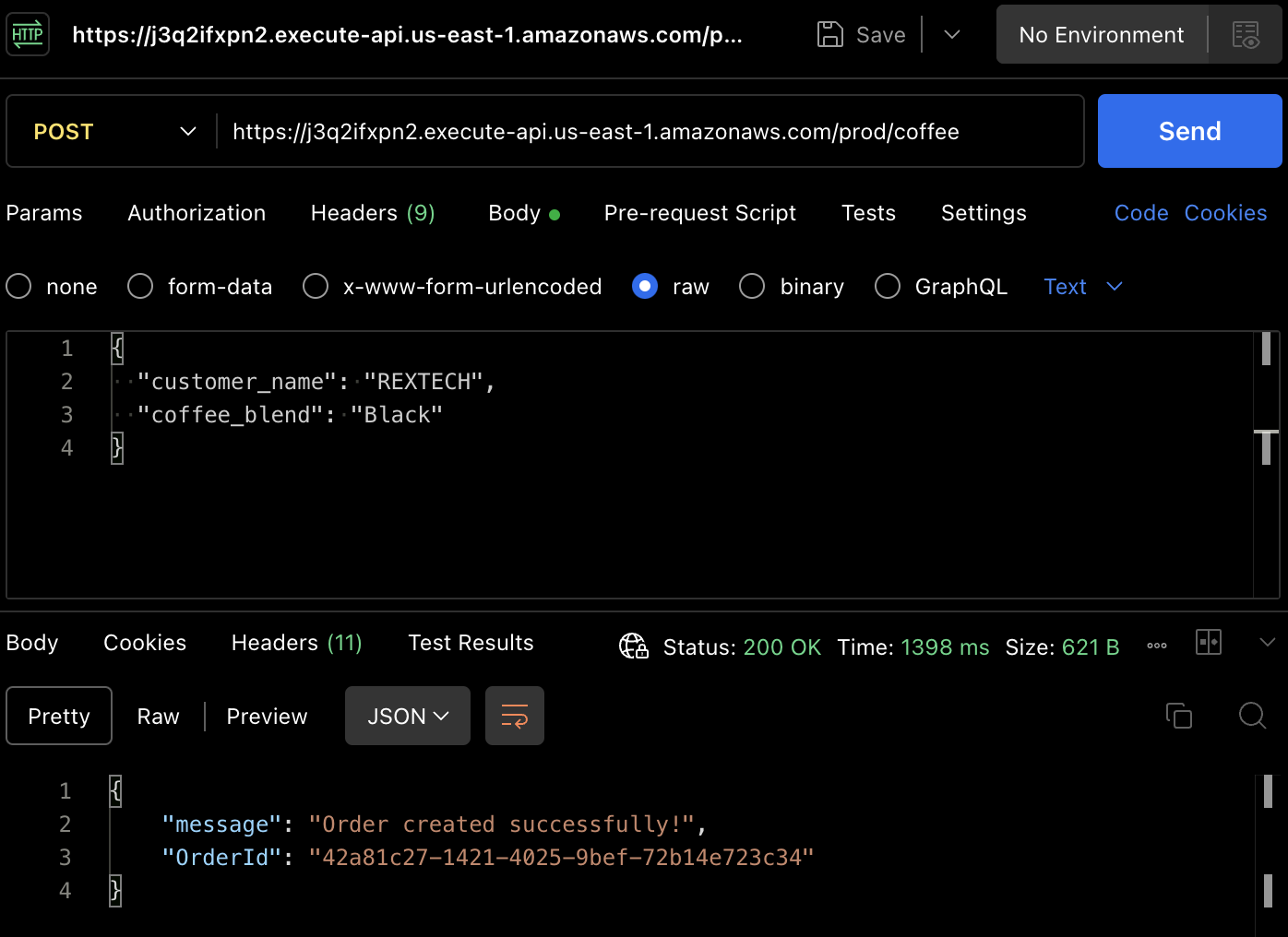
Verifique se o novo pedido foi salvo na tabela DynamoDB revisando os itens na tabela específica do ambiente:

Para testar o método PUT, faça uma solicitação PUT no ponto final da API fornecendo o ID do pedido anterior e um novo status do pedido no corpo da solicitação, conforme mostrado abaixo:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
A resposta será uma mensagem de atualização de pedido bem-sucedida com o OrderId do pedido feito.
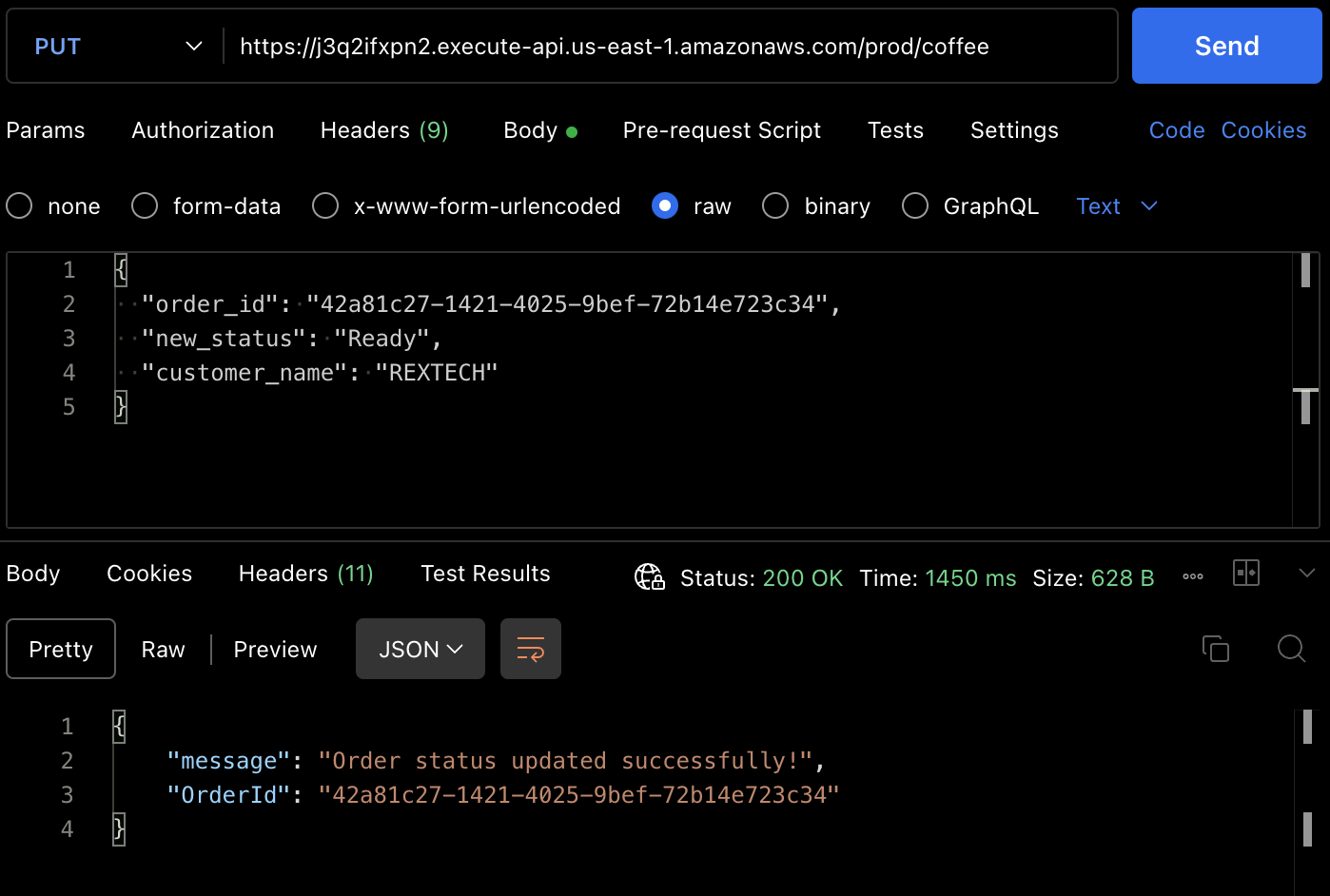
Você também pode verificar que o status do pedido foi atualizado a partir do item da tabela DynamoDB.

Para testar o método DELETE, use o Postman para fazer uma solicitação DELETE fornecendo o ID do pedido anterior e o nome do cliente no corpo da solicitação, conforme mostrado abaixo:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
Você vai receber uma mensagem de sucesso com a exclusão de ordem com o ID da ordem colocada.
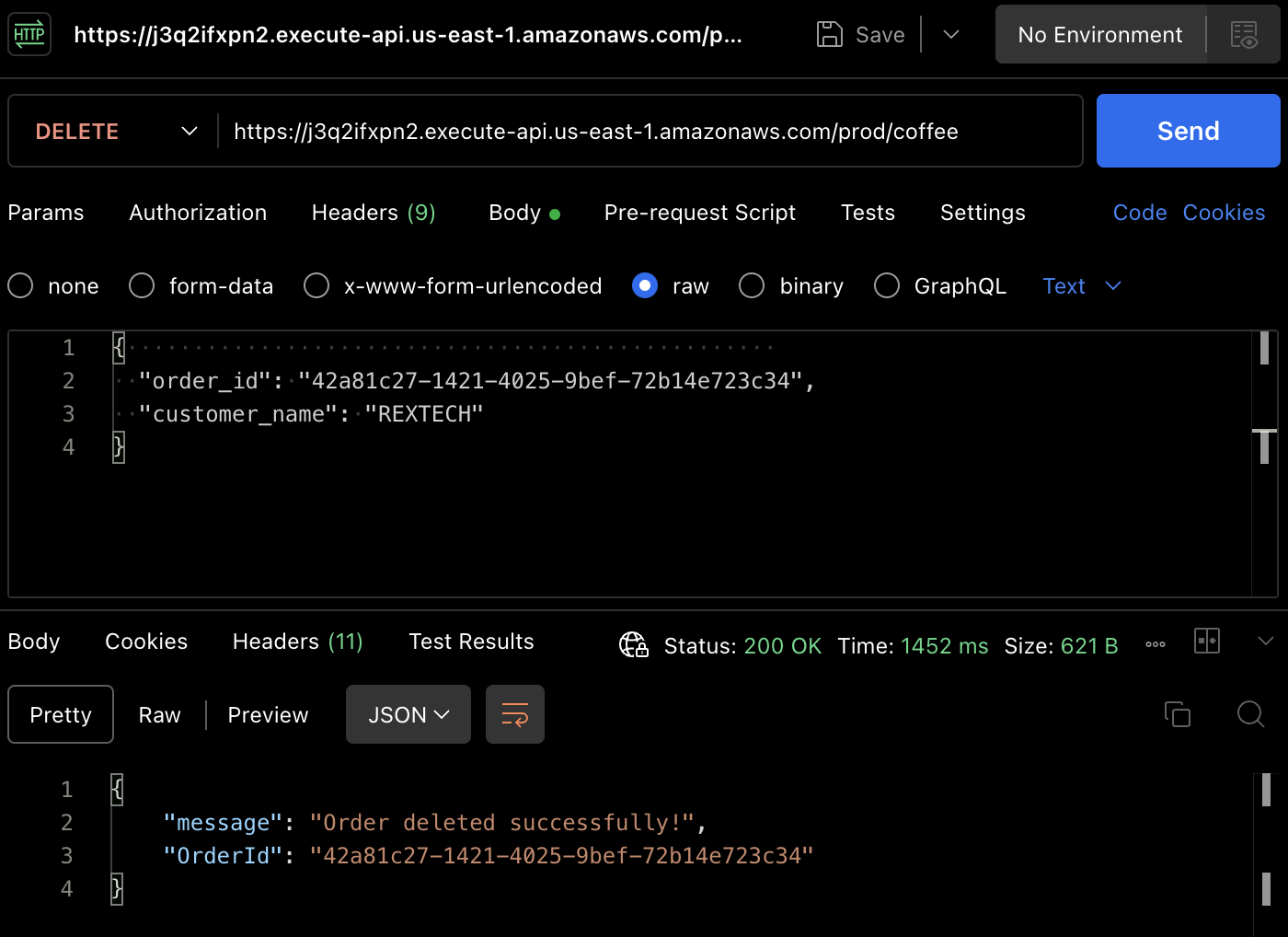
Novamente, você pode verificar que a ordem foi excluída na tabela DynamoDB.

Conclusão
É assim – parabéns! Você concluiu com sucesso todos os passos. Nós construímos uma API REST sem servidor que suporta funcionalidades CRUD (Criar, Ler, Atualizar, Excluir) com API Gateway, Lambda, DynamoDB, Serverless Framework e Node.js, automatizando a implantação de mudanças de código aprovadas com Github Actions.
Se você chegou até aqui, obrigado por ler! Espero que fosse útil para você.
Ifeanyi Otuonye é um engenheiro de cloud AWS certificado 6X habilitado em DevOps, escrita técnica e habilidades de instrução como instrutor técnico. Ele é motivado pela sua paixão por aprender e desenvolver e progrede em ambientes colaborativos. Antes de passar para a nuvem, ele passou seis anos como atleta profissional de atletismo.
No início de 2022, ele embarcou estratégicamente em uma missão de ser um engenheiro de Cloud/DevOps através de estudos autônomos e ao se juntar a um programa acelerado de Cloud de 6 meses.
Em maio de 2023, ele concluiu esse objetivo e obteve seu primeiro papel de engenharia de cloud e agora definiu outro objetivo pessoal para empower outras pessoas em sua jornada para a nuvem.
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/