













Computación serverless surgió como respuesta a los desafíos de las arquitecturas basadas en servidores tradicionales. Con serverless, los desarrolladores ya no necesitan manejar o escalar servidores manualmente. En su lugar, los proveedores de la nube se encargan del manejo de la infraestructura, lo que permite a los equipos centrarse exclusivamente en escribir y desplegar código.
Las soluciones serverless se escalan automáticamente según la demanda y ofrecen un modelo de pago por uso. Esto significa que solo pagas por los recursos que realmente utiliza tu aplicación. Este enfoque reduce significativamente la sobrecarga operativa, aumenta la flexibilidad y acelera los ciclos de desarrollo, convirtiéndolo en una opción atractiva para el desarrollo de aplicaciones modernas.
Al abstractar el manejo de servidores, las plataformas serverless te permiten concentrarte en la lógica de negocio y la funcionalidad de la aplicación. Esto lleva a despliegues más rápidos y más innovación. Las arquitecturas serverless también son basadas en eventos, lo que significa que pueden responder automáticamente a eventos en tiempo real y escalar para satisfacer las demandas de los usuarios sin intervención manual.
Tabla de Contenidos
-
Paso 3: Desarrollar las Funciones Lambda para las Operaciones CRUD
-
Paso 4: Configurar Pipeline CI/CD de Deployments Multistage para Entornos Dev y Prod
Antes de profundizar en los detalles técnicos, recorremos algunos conceptos de背景.
Conceptos importantes para comprender
Interfaz de Programación de Aplicaciones (API)
Una Interfaz de Programación de Aplicaciones (API) permite que diferentes aplicaciones de software se comuniquen e interactúen entre sí. Define los métodos y formatos de datos que las aplicaciones pueden utilizar para solicitar y intercambiar información para la integración y el intercambio de datos entre sistemas diversos.
Métodos HTTP
Los métodos HTTP o métodos de solicitud son un componente crítico de los servicios web y las API. Indican la acción deseada que se debe realizar en un recurso en una URL de solicitud dada.
Los métodos más comúnmente utilizados en las API RESTful son:
-
GET: utilizado para recuperar datos de un servidor
-
POST: envía datos, incluidos en el cuerpo de la solicitud, para crear o actualizar un recurso
-
PUT: actualiza o reemplaza un recurso existente o crea un nuevo recurso si no existe
-
DELETE: elimina los datos especificados del servidor.
Amazon API Gateway
Amazon API Gateway es un servicio completamente gestionado que facilita a los desarrolladores la creación, publicación, mantenimiento, supervisión y seguridad de APIs a gran escala. Actúa como un punto de entrada para varios APIs, gestionando y controlando las interacciones entre los clientes (como aplicaciones web o móviles) y los servicios de backend.
También ofrece varias funciones, incluyendo enrutamiento de solicitudes, seguridad, autenticación, almacenamiento en caché y limitación de velocidad que ayudan a simplificar la gestión y despliegue de APIs.
Amazon DynamoDB
DynamoDB es un servicio de base de datos NoSQL completamente gestionado diseñado para una alta escalabilidad, baja latencia y la replicación de datos en varias regiones.
DynamoDB almacena datos en un formato sin esquema, permitiendo un almacenamiento y recuperación flexible y rápida de datos estructurados y semiestructurados. Se utiliza comúnmente para construir aplicaciones escalables y responsivas en entornos basados en la nube.
Aplicación Serverless CRUD
Una aplicación serverless CRUD se refiere a la capacidad de Crear, Leer, Actualizar y Borrar datos. Sin embargo, la arquitectura y los componentes involucrados difieren de las aplicaciones tradicionales basadas en servidores.
Crear involucra agregar nuevas entradas a una tabla DynamoDB. La operación Leer recupera datos de una tabla DynamoDB. Actualizar modifica datos existentes en DynamoDB. Y la operación Borrar elimina datos de DynamoDB.
El Framework Serverless
El Framework Serverless es una herramienta de código abierto que simplifica la implementación y gestión de aplicaciones serverless en varios proveedores de nube, incluyendo AWS. Abstrae la complejidad de la provisión y gestión de la infraestructura permitiendo a los desarrolladores definir su infraestructura como código usando un archivo YAML.
El framework se encarga del despliegue, escalado y actualización de funciones serverless, APIs y otros recursos.
GitHub Actions
GitHub Actions es una potente herramienta de automatización de CI/CD que permite a los desarrolladores automatizar sus flujos de trabajo de software directamente desde su repositorio de GitHub.
Con GitHub Actions, puedes crear pipelinas personalizadas que se activen ante eventos como el envío de código, pull requests o la fusión de ramas. Estos flujos de trabajo se definen en archivos YAML dentro del repositorio y pueden realizar tareas como pruebas, construcción y despliegue de aplicaciones en varios entornos.
Postman
Postman es una popular plataforma de colaboración que simplifica el proceso de diseño, pruebas y documentación de APIs. Ofrece una interfaz amigable para que los desarrolladores creen y envíen solicitudes HTTP, prueben puntos finales de API y automatizen flujos de pruebas.
Bien, ahora que estás familiarizado con las herramientas y tecnologías que utilizaremos aquí, vamos a profundizar.
Requisitos previos
-
Node.js y npm instalados
-
AWS CLI configurado con acceso a tu cuenta de AWS
-
Una cuenta de Serverless Framework
-
El Serverlesss Framework instalado globalmente en su CLI local
El Serverlesss Framework instalado globalmente en su CLI local
Conozca a Alyx, una emprendedora que recientemente ha estado aprendiendo sobre arquitectura sin servidor. Ha leído sobre cómo es una forma potente y eficiente de construir backends para aplicaciones web, ofreciendo un enfoque más moderno para el desarrollo de aplicaciones web.
Ella quiere aplicar lo que ha aprendido hasta ahora sobre los fundamentos del cómputo sin servidor de AWS. Sabe que sin servidor no significa que no hay servidores involucrados; más bien, simplemente abstrae la gestión y provisión de servidores. Y ahora quiere centrarse únicamente en escribir código e implementar lógica de negocio.
Veamos cómo Alyx, dueña de una próspera cafetería, comienza a aprovechar la arquitectura sin servidor para el backend de su aplicación web.
Alyx’s Coffee Haven, una cafetería en línea, ofrece una variedad de mezclas de café y delicias para la venta. Inicialmente, Alyx administraba los pedidos y el inventario de la tienda con servicios y operaciones de hosting web tradicionales, donde manejaba varios servidores y recursos. Pero a medida que su cafetería fue creciendo en popularidad, comenzó a enfrentar un número creciente de pedidos, especialmente durante las horas pico y las promociones estacionales.
Gestionar los servidores y asegurar que la aplicación pudiera manejar el aumento de tráfico se convirtió en un desafío para Alyx. Se encontraba constantemente preocupada por la capacidad del servidor, la escalabilidad y el costo de mantener la infraestructura.
También quería introducir nuevas funciones, como recomendaciones personalizadas y programas de fidelización, pero esto se convirtió en una tarea de enormes proporciones dadas las limitaciones de su configuración tradicional.
Entonces Alyx conoció el concepto de serverless. Comparó un backend sin servidor con un camarero que prepara café automáticamente en tiempo real, sin tener que preocuparse por los intrincados detalles del proceso de preparación del café.
Emocionada por esta idea, Alyx decidió migrar el backend de su cafetería a una plataforma sin servidor mediante AWS Lambda, AWS API Gateway y Amazon DynamoDB. Esta configuración le permitirá centrarse más en crear las mezclas de café y las delicias perfectas para sus clientes.
Con serverless, cada pedido de un cliente se convierte en un evento que activa una serie de funciones sin servidor. Funciones independientes de AWS Lambda procesan los pedidos y gestionan toda la lógica empresarial entre bastidores. Por ejemplo, crea el pedido de un cliente y puede recuperarlo. También puede eliminar el pedido de alguien o actualizar el estado de un pedido.
Alyx ya no tiene que preocuparse de administrar servidores, ya que la plataforma sin servidor escala automáticamente hacia arriba y hacia abajo en función de las solicitudes de pedidos entrantes. Además, la rentabilidad de serverless es enorme para Alyx. Con un modelo de pago por uso, solo paga por el tiempo de computación real que consumen sus funciones, lo que le ofrece una solución más rentable para su negocio en crecimiento.
¡Pero no se detiene aquí! También quiere automatizar todo, desde la implementación de infraestructura hasta la actualización de su aplicación cada vez que hay un cambio nuevo. Al utilizar la Infraestructura como Código (IaC) con el Framework Serverless, puede definir toda su infraestructura en código y administrarla fácilmente.
Además de eso, configura GitHub Actions para integración continua y entrega continua (CI/CD), de modo que cualquier cambio que realice se despliegue automáticamente a través de un pipeline, ya sea una nueva característica en desarrollo o una corrección rápida para la producción.
Objetivos del tutorial
-
Configurar el entorno del Framework Serverless
-
Defina una API en el archivo YAML
-
Desarrollar funciones AWS Lambda para procesar operaciones CRUD
-
Configurar despliegues de múltiples etapas para Dev y Prod
-
Probar los pipelines Dev y Prod
-
Probar y validar las APIs Dev y Prod usando Postman
Cómo empezar: Clone el repositorio Git
Para mejorar tu comprensión y poder seguir este tutorial de manera más eficaz, haz clic aquí y clona el repositorio del proyecto de mi GitHub. Puedes hacer esto aquí . A medida que avancemos, edita los archivos según consideres necesario.
Después de clonar el repositorio, verás la presencia de varios archivos en tu carpeta, como puedes ver en la imagen de abajo. Usaremos todos estos archivos para construir nuestra API de cafetería sin servidor.
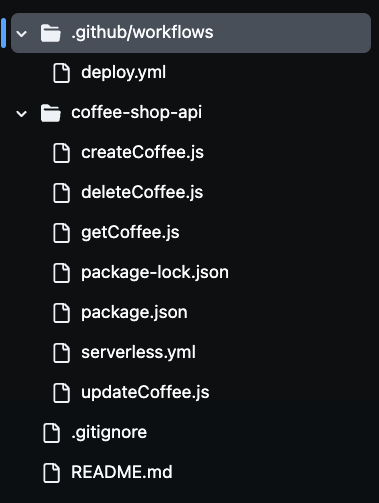
Paso 1: Configurar el Entorno del Framework Serverless
Para configurar el entorno del Framework Serverless para las despliegues automáticos, necesitarás autenticar tu cuenta del Framework Serverless a través de la interfaz de línea de comandos.
Esto requiere crear una clave de acceso que permita al pipeline CI/CD y utilizar el Framework Serverless para autenticarse de manera segura en tu cuenta sin exponer tus credenciales. Al iniciar sesión en tu cuenta Serverless y generar una clave de acceso, el pipeline puede desplegar automáticamente tu aplicación sin servidor desde el archivo de configuración de construcción.
Para hacer esto, vaya a tu cuenta Serverless y navegue hasta la sección de Claves de Acceso. Haga clic en “+agregar”, nombre la clave de acceso SERVERLESS_ACCESS_KEY, y luego cree la clave.
Una vez creada tu clave de acceso, asegúrate de copiar y almacenarla de manera segura. Usarás esta clave como variable secreta en tu repositorio de GitHub para autenticar y autorizar tu pipeline CI/CD.
Proporcionará acceso a tu cuenta de Serverless Framework durante el proceso de despliegue. Añadirás esta clave a los secretos de tu repositorio de GitHub más adelante, para que tu pipeline pueda usarla de forma segura para desplegar los recursos serverless sin exponer información sensible en tu base de código.
Ahora, vamos a definir los recursos de AWS como código en el archivo severless.yaml.
Paso 2: Definir la API en el archivo YAML sin servidor
En este archivo, definirá la infraestructura y la funcionalidad principales de la API Coffee Shop mediante la configuración YAML del marco sin servidor.
Este archivo define los servicios de AWS que se utilizan, incluidos API Gateway, funciones Lambda para operaciones CRUD y DynamoDB para el almacenamiento de datos.
También configurará un rol de IAM para que las funciones de Lambda tengan los permisos necesarios para interactuar con el servicio DynamoDB.
La puerta de enlace de API se configura con los métodos HTTP adecuados (POST, GET, PUT y DELETE) para gestionar las solicitudes entrantes y activar las funciones de Lambda correspondientes.
Vamos a ver el código:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
La configuración serverless.yml define cómo se ejecutará la API Coffee Shop de Alyx en un entorno sin servidor en AWS. La sección provider especifica que la aplicación utilizará AWS como proveedor de la nube, con Node.js como entorno de ejecución.
La región está configurada a us-east-1 y la variable stage permite el despliegue dinámico a través de diferentes entornos, como dev y prod. Esto significa que el mismo código se puede implementar en diferentes entornos, con recursos nombrados en consecuencia para evitar conflictos.
En la sección iam, se otorgan permisos a las funciones Lambda para interactuar con la tabla DynamoDB. La sintaxis ${self:provider.stage} nombra dinámicamente la tabla DynamoDB, de manera que cada entorno tenga sus propios recursos separados, como CoffeeOrders-dev para el entorno de desarrollo y CoffeeOrders-prod para producción. Este nombrado dinámico ayuda a gestionar varios entornos sin tener que configurar manualmente tablas separadas para cada uno.
La sección functions define las cuatro funciones Lambda centrales, createCoffee, getCoffee, updateCoffee y deleteCoffee. Estas manejan las operaciones CRUD para la API de la Tienda de Café.
Cada función está conectada a un método HTTP específico en la API Gateway, como POST, GET, PUT y DELETE. Estas funciones interactúan con la tabla DynamoDB que se nombra dinámicamente basándose en la etapa actual.
La última sección resources define la propia tabla DynamoDB. Configura la tabla con los atributos OrderId y CustomerName, que se utilizan como clave principal. La tabla se configura para utilizar un modo de facturación por solicitud, lo que resulta efectivo para el creciente negocio de Alyx.
Por automatizar la implementación de estos recursos utilizando el marco Serverless, Alyx puede administrar fácilmente su infraestructura, liberándola de la carga de provisionar y escalar recursos manualmente.
Paso 3: Desarrollar las funciones Lambda para operaciones CRUD
En este paso, implementamos la lógica central de la API de la Tienda de Café de Alyx creando funciones Lambda con JavaScript que realizan las operaciones CRUD esenciales createCoffee, getCoffee, updateCoffee y deleteCoffee.
Estas funciones utilizan la SDK de AWS para interactuar con los servicios de AWS, particularmente DynamoDB. Cada función será responsable de manejar solicitudes de API específicas, como crear un pedido, recuperar pedidos, actualizar estados de pedidos y eliminar pedidos.
Función Lambda Create Coffee
Esta función crea un pedido:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
Esta función Lambda maneja la creación de un nuevo pedido de café en la tabla DynamoDB. Primero importamos la SDK de AWS e inicializamos un DynamoDB.DocumentClient para interactuar con DynamoDB. También se importa la biblioteca uuid para generar IDs de pedido únicos.
Dentro de la función handler, parseamos el cuerpo de la solicitud entrante para extraer información del cliente, como el nombre del cliente y la mezcla de café preferida. Se genera un orderId único usando uuidv4() y esta información se prepara para insertar en DynamoDB.
El objeto params define la tabla donde se almacenarán los datos, con TableName establecido dinámicamente en el valor de la variable de entorno COFFEE_ORDERS_TABLE. El nuevo pedido incluye campos como OrderId, CustomerName, CoffeeBlend, y un estado inicial de Pending.
En el bloque try, el código intenta agregar el pedido a la tabla DynamoDB usando el método put(). Si tiene éxito, la función devuelve un código de estado 200 con un mensaje de éxito y el OrderId. Si hay un error, el código lo captura y devuelve un código de estado 500 junto con un mensaje de error.
Función Lambda Get Coffee
Esta función recupera todos los artículos de café:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
Esta función Lambda es responsable de recuperar todos los pedidos de café de una tabla DynamoDB y ejemplifica un enfoque sin servidor para recuperar datos de DynamoDB de manera escalable.
De nuevo usamos el SDK de AWS para inicializar una instancia de DynamoDB.DocumentClient para interactuar con DynamoDB. La función handler construye el objeto params, especificando la TableName, que se establece dinámicamente usando la variable de entorno COFFEE_ORDERS_TABLE.
El método scan() recupera todos los elementos de la tabla. De nuevo, si la operación es exitosa, la función devuelve un código de estado de 200 junto con los elementos recuperados en formato JSON. En caso de error, se devuelve un código de estado de 500 junto con un mensaje de error.
Actualizar función de Café Lambda
Esta función actualiza un elemento de café por su ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
Esta función Lambda maneja la actualización del estado de un pedido de café específico en la tabla DynamoDB.
La función handler extrae order_id, new_status, y customer_name del cuerpo de la solicitud. Luego, construye el objeto params para especificar el nombre de la tabla y la clave primaria para el pedido (usando OrderId y CustomerName). La UpdateExpression establece el nuevo estado del pedido.
En el bloque try, el código intenta actualizar el pedido en DynamoDB utilizando el método update(). Por supuesto, si es exitoso, la función devuelve un código de estado de 200 con un mensaje de éxito. Si se produce un error, se atrapa el error y se devuelve un código de estado de 500 junto con un mensaje de error.
Función de eliminación de Café Lambda
Esta función elimina un elemento de café por su ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
The Lambda function deletes a specific order of café from the table DynamoDB. En la función handler, el código analiza el cuerpo de la solicitud para extraer el order_id y el customer_name. Estos valores se utilizan como clave primaria para identificar el artículo a eliminar de la tabla. El objeto params especifica el nombre de la tabla y la clave del artículo a eliminar.
En el bloque try, el código intenta eliminar la orden de DynamoDB usando el método delete(). Si tiene éxito, vuelve a retornar un código de estado 200 con un mensaje de éxito, indicando que se eliminó la orden. Si ocurre un error, el código lo captura y retorna un código de estado 500 junto con un mensaje de error.
Ahora que hemos explicado cada función Lambda, Preparemos una canalización CI/CD multietapa.
Paso 4: Configurar despliegues multietapa de la canalización CI/CD para entornos de desarrollo y producción
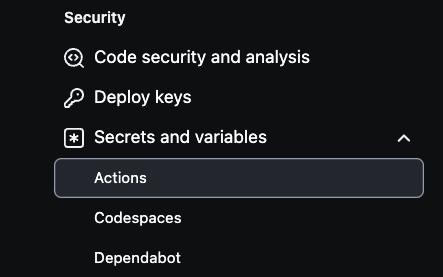
Para configurar secretos de AWS en su repositorio de GitHub, primero navegue a la configuración del repositorio. Seleccione Settings en la parte superior derecha, luego vaya a la parte inferior izquierda y seleccione Secrets and variables.

A continuación, haga clic en Actions como se muestra en la imagen a continuación:
Desde allí, seleccione New repository secret para crear secretos.
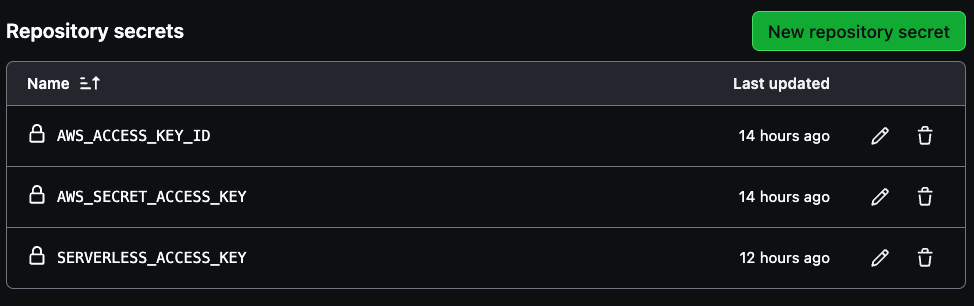
Se necesitan tres secretos para crear en su canalización, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, y SERVERLESS_ACCESS_KEY.
Utiliza las credenciales de acceso de tu cuenta AWS para las primeras dos variables y luego la clave de acceso serverless previamente guardada para crear la SERVERLESS_ACCESS_KEY. Estos secretos autenticarán seguramente tu pipeline CI/CD como se ve en la imagen de abajo.
Asegúrate de que tu rama principal se llame “main”, ya que esto será la rama de producción. A continuación, crea una nueva rama llamada “dev” para trabajos de desarrollo.
También puedes crear ramas específicas para funciones, como “dev/feature”, para un desarrollo más granular. GitHub Actions usará estas ramas para desplegar cambios automáticamente, con dev representando el entorno de desarrollo y main representando la producción.
Estrategia de división de ramas que permite administrar el pipeline CI/CD de manera eficiente, desplegando nuevos cambios en código cada vez que haya una fusión en cualquiera de los entornos de desarrollo o producción.
Cómo Usar GitHub Actions para Desplegar el Archivo YAML
Para automatizar el proceso de despliegue de la API del Café, utilizarás GitHub Actions, que integra con tu repositorio de GitHub.
Este pipeline de despliegue se activa cada vez que se envía código a las ramas main o dev. Configurando despliegues específicos para entornos, asegurarás que actualizaciones en la rama dev se despliegan en el entorno de desarrollo, mientras que cambios en la rama main disparan despliegues de producción.
Ahora, veamos el código:
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
La configuración de GitHub Actions en YAML es lo que automatiza el proceso de despliegue de la API de la Tienda de Café a AWS utilizando el Serverless Framework. El flujo de trabajo se activa cada vez que se envían cambios a las ramas principal o dev.
Comienza revisando el código del repositorio, luego configura Node.js con la versión 20.x para que coincida con el tiempo de ejecución utilizado por las funciones Lambda. Después de eso, instala las dependencias del proyecto navegando al directorio coffee-shop-api y ejecutando npm install.
El flujo de trabajo también instala el Serverless Framework globalmente, permitiendo que el CLI de serverless se use para los despliegues. Dependiendo de qué rama se actualice, el flujo de trabajo despliega condicionalmente en el entorno apropiado.
Si los cambios se envían a la rama dev, se despliega a la etapa dev. Si se envían a la rama principal, se despliega a la etapa prod. Los comandos de despliegue, npx serverless deploy --stage dev o npx serverless deploy --stage prod se ejecutan dentro del directorio coffee-shop-api.
Para un despliegue seguro, el flujo de trabajo accede a las credenciales de AWS y a la clave de acceso de Serverless a través de variables de entorno almacenadas en GitHub Secrets. Esto permite que la pipeline CI/CD se autentique con AWS y el Serverless Framework sin exponer información sensible en el repositorio.
Ahora, podemos proceder a probar la pipeline.
Paso 5: Probar las pipelines de Dev y Prod.
Primero, necesitarás verificar que la rama principal (prod) se llama “main”. Luego crea una rama de desarrollo llamada “dev”. Una vez que hagas cualquier cambio válido en la rama de desarrollo, confímalos para activar el pipeline de GitHub Actions. Esto desplegará automáticamente los recursos actualizados en el entorno de desarrollo. Después de verificar todo en dev, puedes fusionar la rama de desarrollo con la rama principal.
La fusión de cambios en la rama principal también activa automáticamente el pipeline de despliegue para el entorno de producción. De este modo, se aplican todas las actualizaciones necesarias y los recursos de producción se despliegan sin problemas.
Puedes monitorear el proceso de despliegue y revisar los registros detallados de cada ejecución de GitHub Actions navegando a la pestaña Actions en tu repositorio de GitHub.
Los registros proporcionan visibilidad en cada paso del pipeline, ayudándote a verificar que todo funciona como se espera.
Puedes seleccionar cualquier ejecución de compilación para revisar los registros detallados para ambos despliegues del entorno de desarrollo y de producción, para que puedas rastrear el progreso y asegurarte de que todo se está ejecutando sin problemas.
Navega a la ejecución específica de la compilación en GitHub Actions, como se muestra en la imagen a continuación. Allí, puedes ver los detalles de ejecución y resultados tanto para los pipelines de desarrollo como de producción.

Asegúrate de probar a fondo tanto el entorno de desarrollo como el de producción para confirmar la ejecución exitosa del pipeline.
Paso 6: Probar y validar las API de Prod y Dev usando Postman.
Una vez que las APIs y los recursos estén desplegados y configurados, necesitamos localizar los puntos finales de API únicos (URLs) generados por AWS para comenzar a realizar solicitudes y probar la funcionalidad.
Estas URLs pueden probar la funcionalidad de la API simplemente pegándolas en un navegador web. Las URLs de la API se encuentran en los resultados de salida de su build de CI/CD.
Para recuperarlas, navegue a los registros de GitHub Actions, seleccione la compilación exitosa más reciente del entorno, y haga clic en deploy para verificar los detalles del despliegue de los puntos finales de API generados.
Haga clic en la etapa Deploy to AWS para el entorno seleccionado (Prod o Dev) en sus registros de GitHub Actions. Una vez allí, encontrará la URL de la API generada.
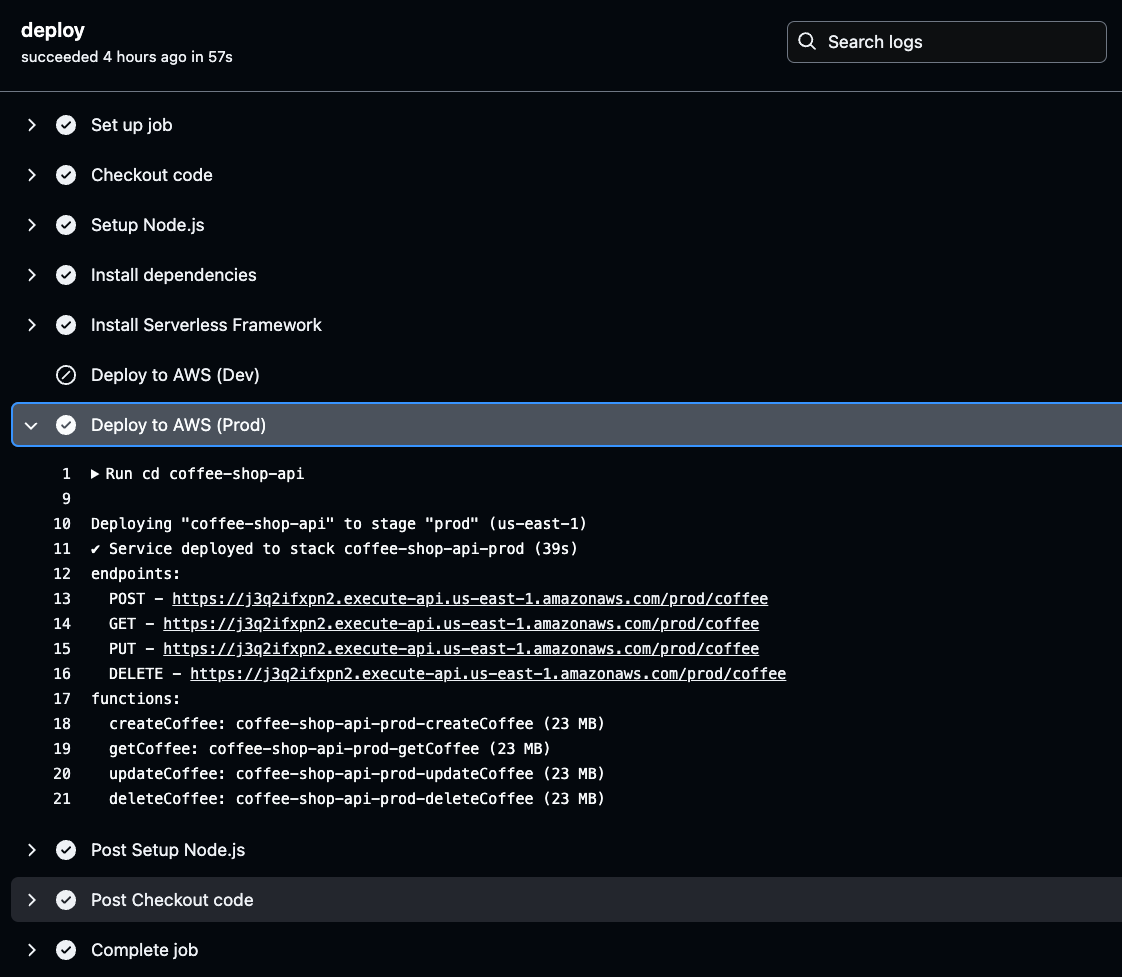
Copie y guárdese esta URL, ya que será necesaria para probar la funcionalidad de su API. Esta URL es su puerta de enlace para verificar que la API desplegada funciona como se espera.
Ahora copie una de las URLs de la API generadas y péguela en su navegador. Verá un arreglo vacío o lista mostrada en la respuesta. Esto realmente confirma que la API está funcionando correctamente y que está recuperando con éxito datos de la tabla DynamoDB.
Incluso aunque la lista esté vacía, indica que la API puede conectarse a la base de datos y devolver información.
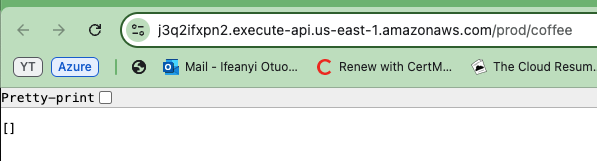
Para verificar que su API funciona en ambos entornos, repita los pasos para el otro entorno de API (Prod y Dev).
Utilizaremos Postman para probar todos los métodos de la API, Crear, Leer, Actualizar y Eliminar, y realizaremos estas pruebas tanto en entornos de desarrollo como de producción.
Para probar el método GET, use Postman para enviar una solicitud GET al punto final de la API mediante la URL. Recibirá la misma respuesta, una lista vacía de pedidos de café como se ve en la parte inferior de la imagen de abajo. Esto confirma la capacidad de la API para recuperar datos exitosamente, como se muestra en la imagen de abajo.

Para realmente crear un pedido, probemos el método POST. Vuelva a usar Postman para realizar una solicitud POST al punto final de la API, proporcionando el nombre del cliente y la mezcla de café en el cuerpo de la solicitud, como se muestra a continuación :
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
La respuesta será un mensaje de éxito con un OrderId único del pedido realizado.
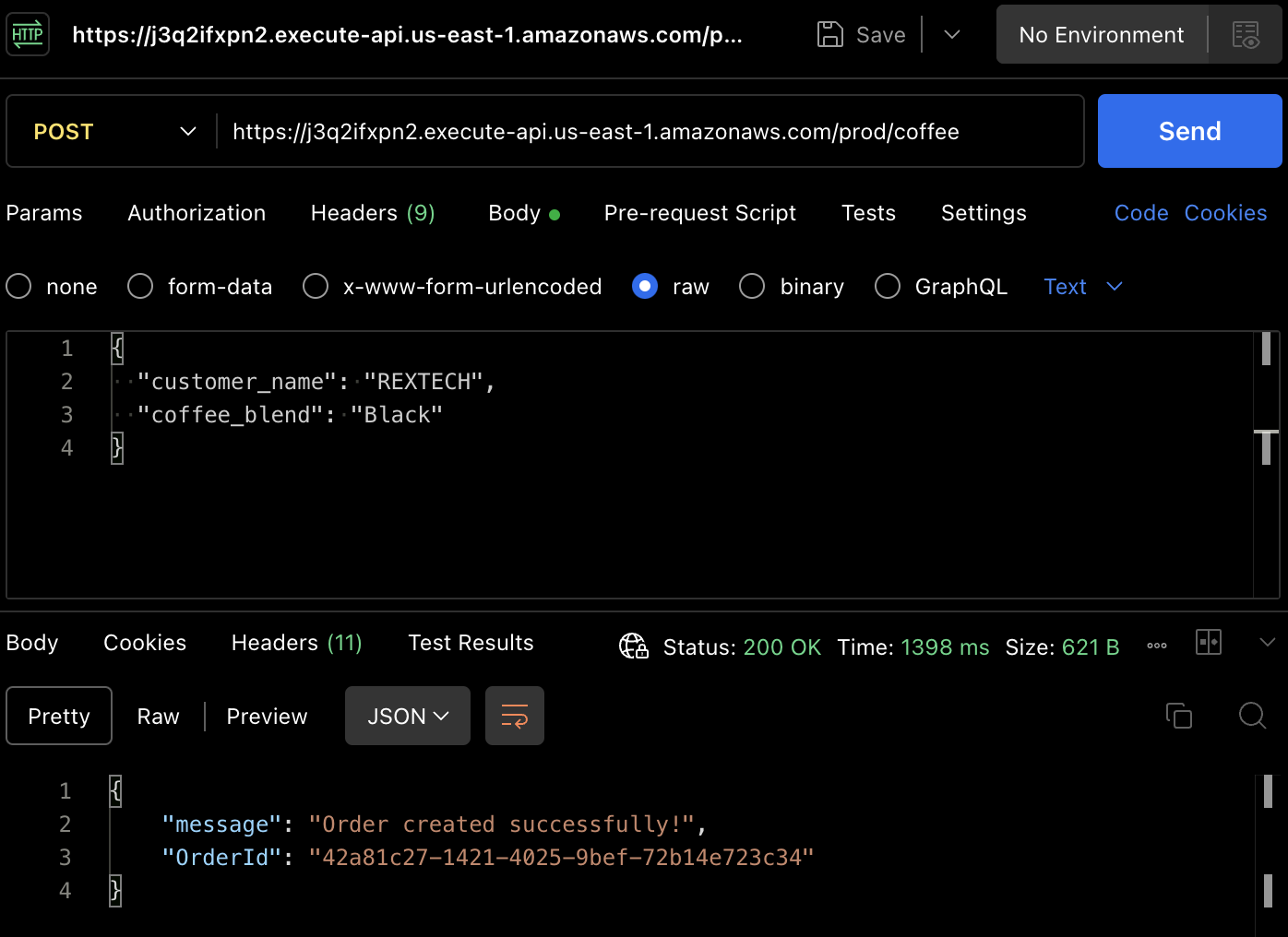
Verifique que el nuevo pedido se guardó en la tabla DynamoDB revisando los artículos en la tabla específica de los entornos :

Para probar el método PUT, realice una solicitud PUT al punto final de la API proporcionando el ID del pedido anterior y un nuevo estado del pedido en el cuerpo de la solicitud, como se muestra a continuación :
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
La respuesta será un mensaje de actualización exitosa del pedido con el OrderId del pedido realizado.
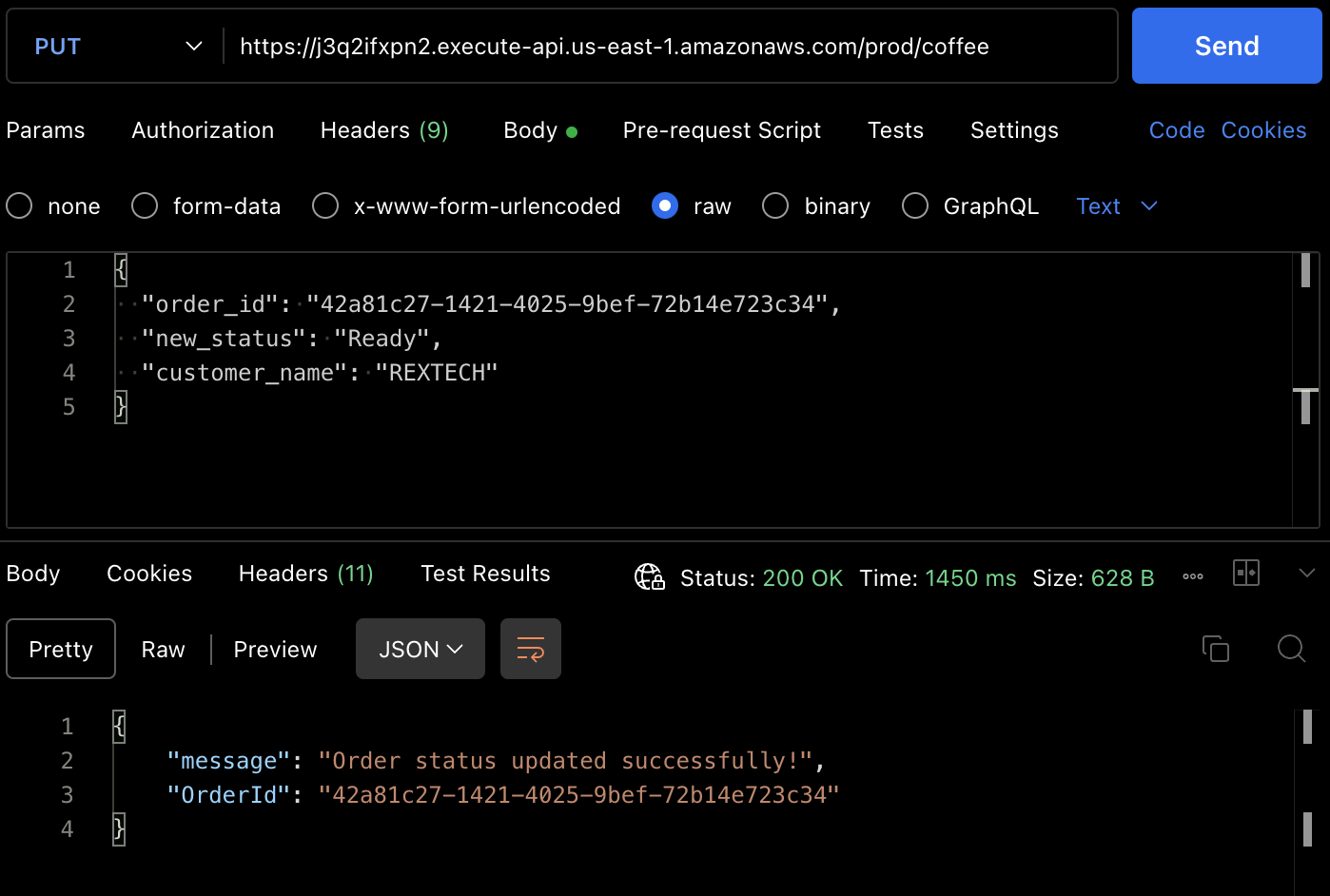
También puede verificar que el estado del pedido se actualizó a partir del artículo de la tabla DynamoDB.

Para probar el método DELETE, usando Postman, realice una solicitud DELETE proporcionando el ID del pedido anterior y el nombre del cliente en el cuerpo de la solicitud, como se muestra a continuación:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
El mensaje será una confirmación de eliminación de pedido exitosa con el ID del pedido del pedido realizado.
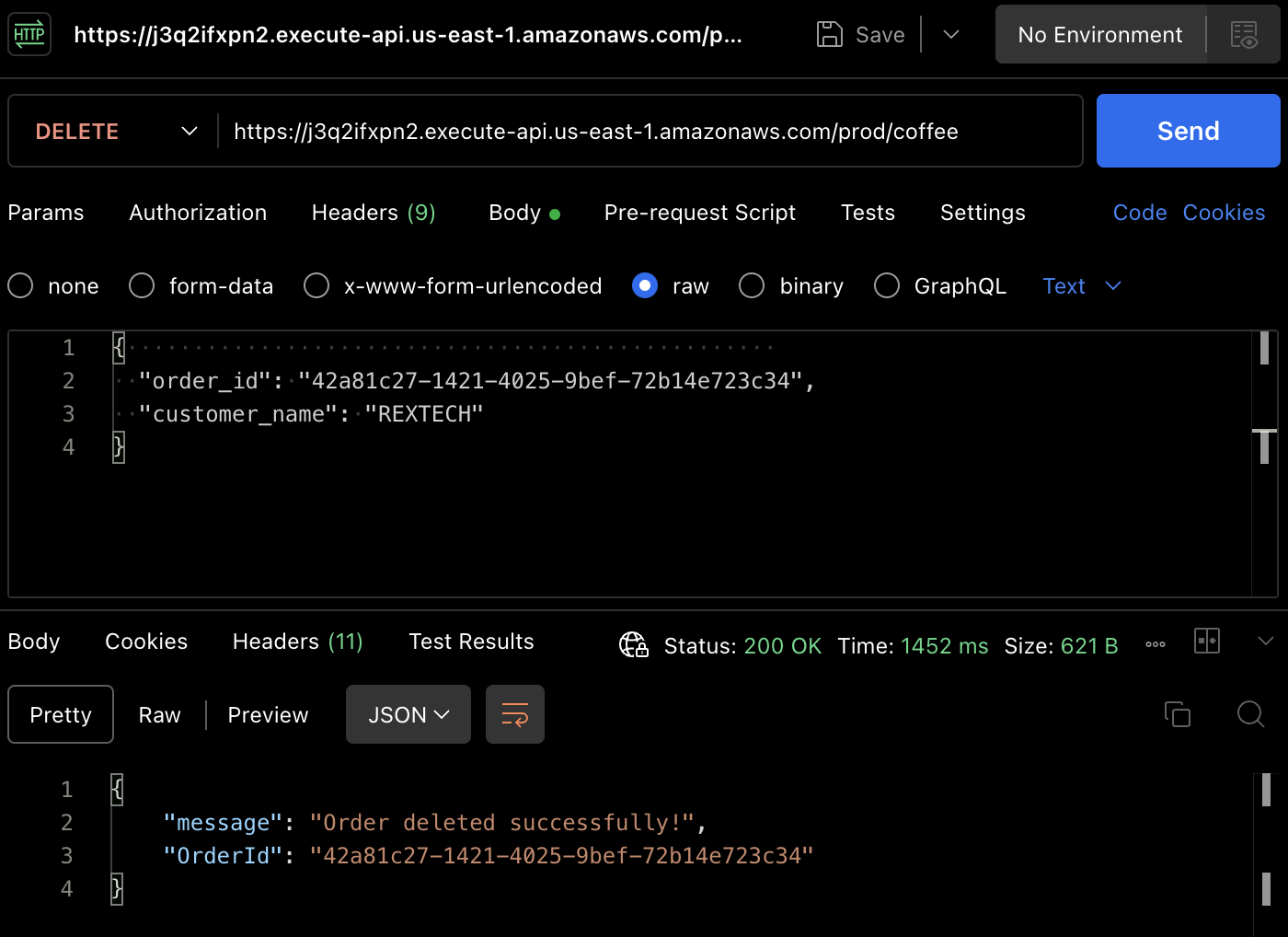
De nuevo, puedes verificar que el pedido ha sido eliminado en la tabla DynamoDB.

Conclusión
¡Eso es todo – felicitaciones! Has completado con éxito todos los pasos. Hemos construido una API REST sin servidor que soporta funcionalidad CRUD (Crear, Leer, Actualizar, Eliminar) con API Gateway, Lambda, DynamoDB, Serverless Framework y Node.js, automatizando la implementación de cambios de código aprobados con Github Actions.
Si has llegado hasta aquí, gracias por leer! Espero que te haya resultado útil.
Ifeanyi Otuonye es un Ingeniero de Nube de AWS Certificado 6X habilidoso en DevOps, Escritura Técnica y experiencia instructiva como Instructor Técnico. Está motivado por su ansia de aprender y desarrollar y se destaca en entornos colaborativos. Antes de pasar a la Nube, pasó seis años como atleta profesional de Atletismo.
Al comienzo de 2022, emprendió estratégicamente una misión para convertirse en un Ingeniero de Nube/DevOps a través del estudio autodidacta y la participación en un programa acelerado de Nube de 6 meses.
En mayo de 2023, logró esa meta y consiguió su primer papel de Ingeniería en la Nube y ha establecido ahora otra misión personal para empoderar a otras personas en su camino hacia la Nube.
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/