













Serverloser Rechnungsumfang ist eine Reaktion auf die Herausforderungen traditioneller serverbasierter Architekturen. Bei serverloser Berechnung müssen Entwickler nicht mehr manuell Server verwalten oder skalieren. Stattdessen übernehmen Cloud-Anbieter die Infrastrukturverwaltung, was Teams dazu freigibt, sich ausschließlich auf das Schreiben und das Bereitstellen von Code zu konzentrieren.
Serverlose Lösungen erweitern sich automatisch auf Bedarf und bieten ein tarifmäßiges Modell. Dies bedeutet, dass Sie nur für die Ressourcen zahlen, die Ihre Anwendung tatsächlich verwendet. Dieser Ansatz verringert die Betriebskosten erheblich, erhöht Flexibilität und beschleunigt die Entwicklungszyklen, was ihn zu einer attraktiven Option für moderne Anwendungsentwicklung macht.
Durch die Abstraktion der Serververwaltung ermöglichen Serverlos-Plattformen Ihnen, sich auf Geschäftslogik und Anwendungsfunktionen zu konzentrieren. Dies führt zu schnelleren Bereitstellungen und mehr Innovation. Serverlose Architekturen sind auch eventbasiert, was bedeutet, dass sie automatisch auf Ereignisse in Echtzeit reagieren und ohne manuelle Intervention auf die Bedürfnisse der Benutzer skalieren können.
Inhaltsverzeichnis
-
Schritt 2: Definieren Sie die API in der Serverless YAML-Datei
-
Schritt 3: Entwicklung der Lambda-Funktionen für CRUD-Operationen
-
Schritt 4: Richten Sie CI/CD-Pipeline-Multi-Phasen-Deployments für Dev- und Prod-Umgebungen ein
-
Schritt 6: Testen und Validieren Sie Prod- und Dev-APIs mit Postman
Bevor wir uns in die technischen Details vertiefen, werden wir einige wesentliche Hintergrundkonzepte durchgehen.
Wichtige Konzepte verstehen
Anwendungsschnittstellenschnittstelle (API)
Eine Anwendungsschnittstelle (API) ermöglicht es verschiedenen Softwareanwendungen, miteinander zu kommunizieren und zu interagieren. Sie definiert die Methoden und Datenformate, die Anwendungen verwenden können, um Informationen abzufragen und auszutauschen, um Integration und Datenfreigabe zwischen verschiedenen Systemen zu ermöglichen.
HTTP-Methoden
HTTP-Methoden oder Anfragemethoden sind ein kritischer Bestandteil von Webdiensten und APIs. Sie zeigen die gewünschte Aktion an, die an einer Ressource in einer bestimmten Anfrage-URL durchgeführt werden soll.
Die am häufigsten verwendeten Methoden in RESTful-APIs sind:
-
GET: wird verwendet, um Daten von einem Server abzurufen
-
POST: sendet Daten, die im Body der Anfrage enthalten sind, um eine Ressource zu erstellen oder zu aktualisieren
-
PUT: aktualisiert oder ersetzt eine vorhandene Ressource oder erstellt eine neue Ressource, falls sie nicht existiert
-
DELETE: löscht die angegebenen Daten vom Server.
Amazon API Gateway
Amazon API Gateway ist ein vollständig verwaltetes Service, der Entwicklern erleichtert, auf Skala APIs zu erstellen, zu veröffentlichen, zu pflegen, zu überwachen und zu sichern. Es fungiert als Einstiegspunkt für mehrere APIs, verwaltet und steuert die Interaktionen zwischen Clients (wie Web- oder Mobileanwendungen) und Backend-Diensten.
Es bietet außerdem verschiedene Funktionen an, einschließlich Anfragerouting, Sicherheit, Authentifizierung, Caching und Rate Limiting, die die Verwaltung und den Einsatz von APIs vereinfachen.
Amazon DynamoDB
DynamoDB ist ein vollständig verwaltetes NoSQL-Datenbankdienst, der für hohe Skalierbarkeit, niedrige Latenzzeiten und die Replikation von Daten über mehrere Regionen konzipiert wurde.
DynamoDB speichert Daten in einem schemafreien Format, was eine flexible und schnelle Speicherung und Abrufung von strukturierten und semistrukturierten Daten ermöglicht. Es wird häufig für das Aufbauen skalierbarer und reaktionsfähiger Anwendungen in cloudbasierten Umgebungen verwendet.
Serverlose CRUD-Anwendung
Eine serverlose CRUD-Anwendung bezieht sich auf die Fähigkeit, zu Erstellen, zu Lesen, zu Aktualisieren und zu Löschen von Daten. Die Architektur und Komponenten unterscheiden sich jedoch von traditionellen serverbasierten Anwendungen.
Erstellen beinhaltet das Hinzufügen neuer Einträge zu einer DynamoDB-Tabelle. Die Lesen-Operation ruft Daten aus einer DynamoDB-Tabelle ab. Aktualisieren aktualisiert vorhandene Daten in DynamoDB. Und die Löschen-Operation löscht Daten aus DynamoDB.
Das Serverless Framework
Der Serverless Framework ist ein Open-Source-Tool, das das Bereitstellen und die Verwaltung von serverlosen Anwendungen über mehrere Cloud-Anbieter, einschließlich AWS, vereinfacht. Es abstractiert die Komplexität der Infrastrukturbereitstellung und -verwaltung, indem Entwickler ihre Infrastruktur als Code mittels eines YAML-Dateis verwalten können.
Das Framework übernimmt die Bereitstellung, Skalierung und Aktualisierung von serverlosen Funktionen, APIs und anderen Ressourcen.
GitHub Actions
GitHub Actions ist ein leistungsstarkes CI/CD-Automatisierungstool, das Entwicklern erlaubt, ihre Software-Workflows direkt aus ihrem GitHub-Repository zu automatisieren.
Mit GitHub Actions können Sie benutzerdefinierte Pipelines erzeugen, die durch Ereignisse wie Code-Pushes, Pull-Request oder Branch-Fusionen ausgelöst werden. Diese Workflows werden in YAML-Dateien innerhalb des Repositories definiert und können Aufgaben wie Testing, Building und Bereitstellen von Anwendungen in verschiedenen Umgebungen durchführen.
Postman
Postman ist eine populäre Collaboration-Plattform, die das Design, Testen und Dokumentieren von APIs vereinfacht. Es bietet Entwicklern eine benutzerfreundliche Oberfläche, um HTTP-Anfragen zu erstellen und zu senden, API-Endpunkte zu testen und Test-Workflows zu automatisieren.
Na ja, nun dass Sie mit den Tools und Technologien vertraut sind, die wir hier verwenden werden, lassen Sie uns beginnen.
Voraussetzungen
-
Node.js und npm installiert
-
AWS CLI mit Zugriff auf Ihr AWS-Konto konfiguriert
-
Ein Serverlesss Framework-Konto
-
Serverless Framework global in Ihrer lokalen CLI installiert
Unser Use-Case
Meet Alyx, eine Unternehmerin, die sich kürzlich mit serverloser Architektur beschäftigt hat. Sie hat darüber gelesen, wie es eine leistungsstarke und effiziente Methode zum Bau von Backends für Webanwendungen ist und einen moderneren Ansatz zur Webentwicklung bietet.
Sie möchteapply, was sie bisher über die Grundlagen der AWS serverlosen Rechnung gelernt hat. Sie weiß, dass „serverlos“ nicht bedeutet, dass es keine Server gibt – vielmehr abstrahiert es lediglich die Verwaltung und Bereitstellung von Servern. Und jetzt möchte sie sich ausschließlich auf das Schreiben von Code und die Implementierung von Geschäftslogik konzentrieren.
Sehen wir uns an, wie Alyx, die Inhaberin eines florierenden Kaffeeladens, beginnt, serverlose Architektur für das Backend Ihrer Webanwendung zu nutzen.
Alyx’s Coffee Haven, ein Online-Kaffeeladen, bietet eine Reihe von Kaffeeblends und Snacks zum Verkauf an. Zunächst verwaltete Alyx die Bestellungen und den Bestand des Ladens mit traditionellen Webhosting-Diensten und Operationen, wo sie mehrere Server und Ressourcen handhabte. Doch als ihr Kaffeeladen in Popularität gewann, begann sie, eine zunehmende Anzahl von Bestellungen zu erhalten, besonders während der Spitzenzeiten und saisonalen Aktionen.
Die Verwaltung der Server und die Sicherstellung, dass die Anwendung den Ansturm auf den Traffic bewältigen konnte, wurde eine Herausforderung für Alyx. Sie fand sich ständig mit der Sorge um Serverkapazität, Skalierbarkeit und die Kosten für den Unterhalt der Infrastruktur beschäftigt.
Sie wollte auch neue Funktionen wie personalisierte Empfehlungen und Treueprogramme einführen, aber dies erwies sich aufgrund der Einschränkungen ihrer traditionellen Einrichtung als schwierige Aufgabe.
Dann erfährt Alyx vom Konzept des Serverless. Sie vergleicht ein serverloses Backend mit einem Barista, der Kaffee in Echtzeit automatisch zubereitet, ohne dass sie sich um die komplizierten Details des Kaffeeherstellungsprozesses kümmern muss.
Begeistert von dieser Idee beschließt Alyx, das Backend ihres Kaffeehauses auf eine serverlose Plattform mit AWS Lambda, AWS API Gateway und Amazon DynamoDB zu migrieren. Diese Einrichtung ermöglicht es ihr, sich mehr auf die perfekten Kaffee-Mischungen und Leckereien für ihre Kunden zu konzentrieren.
Mit Serverless wird jede Bestellung eines Kunden zu einem Ereignis, das eine Reihe von serverlosen Funktionen auslöst. Separate AWS Lambda-Funktionen verarbeiten die Bestellungen und übernehmen die gesamte Geschäftslogik im Hintergrund. Zum Beispiel erstellt es eine Kundenbestellung und kann diese Bestellung abrufen. Es kann auch eine Bestellung löschen oder den Status einer Bestellung aktualisieren.
Alyx muss sich nicht mehr um das Management von Servern kümmern, da die serverlose Plattform automatisch skalierbar ist und sich anhand eingehender Bestellanfragen hoch- und herunterskaliert. Auch die Kosteneffizienz von Serverless ist für Alyx enorm. Mit einem Pay-as-you-go-Modell bezahlt sie nur für die tatsächlich von ihren Funktionen verbrauchte Rechenzeit und bietet ihr eine kostengünstigere Lösung für ihr wachsendes Unternehmen.
Aber das ist nicht alles! Sie will auch alles automatisieren, von der Infrastrukturbereitstellung bis zum Update ihrer Anwendung, wenn es einen neuen Änderungsvorschlag gibt. Durch die Nutzung von Infrastruktur als Code (IaC) mit dem Serverless Framework kann sie ihre gesamte Infrastruktur in Code definieren und leicht verwalten.
Darüber hinaus setzt sie GitHub Actions für den kontinuierlichen Integrations- und Delivery-Prozess (CI/CD) ein, so dass jeder von ihr vorgenommene Änderung automatisch ein Pipeline durchläuft, egal ob es sich dabei um eine neue Funktion in der Entwicklung oder um einen Hotfix für die Produktion handelt.
Ziele des Tutorials
-
Einrichten des Serverless Framework-Umfelds
-
API in der YAML-Datei definieren
-
Entwickeln von AWS Lambda-Funktionen zur Verarbeitung von CRUD-Operationen
-
Einrichten von mehreren Stufen für Entwicklung (Dev) und Produktion (Prod)
-
Testen der Pipelines für Dev und Prod
-
Testen und Validieren der Dev- und Prod-APIs mit Postman
Anleitung zum Start: Klonen des Git-Repositories
durchgehen Sie hier . Wenn wir fortsetzen, bearbeiten Sie die Dateien frei, wie es notwendig erscheint.
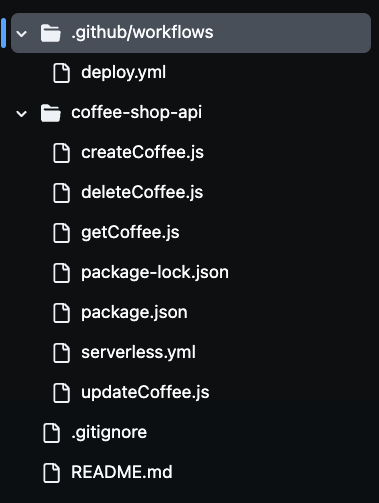
Nach dem Klonen des Repositorys werden Sie bemerken, dass mehrere Dateien in Ihrem Ordner vorhanden sind, wie Sie in dem nachfolgenden Bild sehen können. Wir werden alle diese Dateien verwenden, um unsere serverlose Kaffeetasse API zu bauen.
Schritt 1: Richten Sie die Serverless Framework-Umgebung ein
Um die Serverless Framework-Umgebung für automatisierte Deployments einzurichten, müssen Sie Ihr Serverless Framework-Konto über die CLI authentifizieren.
Dafür ist die Erstellung eines Zugriffsschlüssels erforderlich, der die CI/CD-Pipeline aktiviert und das Serverless Framework verwendet, um sicher in Ihrem Konto zu authentifizieren, ohne Ihre Anmeldedaten preiszugeben. Wenn Sie sich in Ihrem Serverless-Konto anmelden und einen Zugriffsschlüssel generieren, kann die Pipeline Ihre serverlose Anwendung automatisch aus der Build-Konfigurationsdatei deployen.
Gehen Sie dazu in Ihrem Serverless-Konto zu der Sektion Zugriffsschlüssel. Klicken Sie auf „+hinzufügen“, nennen Sie ihn SERVERLESS_ACCESS_KEY und erstellen Sie dann den Schlüssel.
Sobald Sie Ihren Zugriffsschlüssel erstellt haben, kopieren Sie ihn sicher auf und speichern Sie ihn. Sie werden diesen Schlüssel als geheime Variable in Ihrem GitHub-Repository verwenden, um Ihre CI/CD-Pipeline zu authentifizieren und zu autorisieren.
Es wird Zugriff auf Ihr Serverless Framework-Konto während des Deployment-Prozesses bereitstellen. Sie werden diesen Schlüssel später zu Ihrem GitHub-Repositorys geheimen hinzufügen, sodass Ihr Pipeline ihn sicher verwenden kann, um serverlose Ressourcen ohne die Veröffentlichung von sensiblen Informationen in Ihrer Basis-Code zu部署.
Jetzt definieren wir die AWS-Ressourcen als Code im severless.yaml Datei.
Schritt 2: Definieren Sie die API im Serverless YAML-Datei
In dieser Datei definieren Sie den Kern der Infrastruktur und der Funktionalität der Coffee Shop API mit dem YAML-Konfiguration des Serverless Framework.
Diese Datei definiert die verwendeten AWS-Dienste, einschließlich der API Gateway, Lambda-Funktionen für CRUD-Operationen und DynamoDB für Datenspeicherung.
Sie werden auch eine IAM-Rolle konfigurieren, sodass die Lambda-Funktionen die notwendigen Berechtigungen haben, um mit dem DynamoDB-Dienst zu interagieren.
Die API Gateway ist mit angemessenen HTTP-Methoden (POST, GET, PUT und DELETE) eingerichtet, um auf eingehende Anfragen zu reagieren und die entsprechenden Lambda-Funktionen auszulösen.
Lassen Sie uns die Code anschauen:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
Die serverless.yml -Konfiguration definiert, wie Alyx‘ Coffee Shop API in einem serverlessen Umfeld auf AWS ausgeführt wird. Der Abschnitt provider gibt an, dass die Anwendung AWS als Cloud-Anbieter verwenden wird, mit Node.js als Laufzeitumgebung.
Der Region ist us-east-1 zugewiesen und die Variable stage ermöglicht die dynamische Bereitstellung in verschiedenen Umgebungen, wie z.B. dev und prod. Dies bedeutet, dass dasselbe Code in verschiedene Umgebungen deployiert werden kann, wobei die Ressourcen entsprechend benannt werden, um Konflikte zu vermeiden.
Im Abschnitt iam werden Lambda-Funktionen Berechtigungen zugewiesen, um mit der DynamoDB-Tabelle zu interagieren. Die Syntax ${self:provider.stage} benennt dynamisch die DynamoDB-Tabelle, so dass jede Umgebung ihre eigenen separate Ressourcen hat, wie z.B. CoffeeOrders-dev für die Entwicklungsumgebung und CoffeeOrders-prod für die Produktionsumgebung. Diese dynamische Benennung hilft bei der Verwaltung mehrerer Umgebungen ohne manuelle Konfiguration separater Tabellen für jede einzulösen.
Der Abschnitt functions definiert die vier Kern-Lambda-Funktionen createCoffee, getCoffee, updateCoffee und deleteCoffee. Diese verwalten die CRUD-Operationen für die Coffee Shop API.
Jede Funktion ist mit einem bestimmten HTTP-Methode in der API Gateway verbunden, wie z.B. POST, GET, PUT und DELETE. Diese Funktionen interagieren mit der DynamoDB-Tabelle, die dynamisch basierend auf der aktuellen Phase benannt wird.
Der letzte Abschnitt resources definiert die DynamoDB-Tabelle selbst. Er setzt die Tabelle mit den Attributen OrderId und CustomerName auf, die als Primärschlüssel verwendet werden. Die Tabelle ist so eingerichtet, dass sie ein Verrechnungsmodus mit Pay-per-Request verwendet, was für Alyx‘ wachsendes Geschäft kostengünstig ist.
Durch die Automatisierung der Bereitstellung dieser Ressourcen mithilfe des Serverless Framework kann Alyx leicht ihre Infrastruktur verwalten und sich vom lastigen Prozess der manuellen Bereitstellung und Skalierung von Ressourcen befreien.
Schritt 3: Entwicklung der Lambda-Funktionen für CRUD-Operationen
In diesem Schritt implementieren wir die Kernlogik von Alyx‘ Café-API durch die Erstellung von Lambda-Funktionen mit JavaScript, die die grundlegenden CRUD-Operationen createCoffee, getCoffee, updateCoffee und deleteCoffee durchführen.
Diese Funktionen verwenden das AWS SDK, um mit AWS-Diensten zu interagieren, insbesondere mit DynamoDB. Jede Funktion wird für die Verarbeitung bestimmter API-Anfragen verantwortlich sein, wie z.B. das Erstellen eines Auftrags, das Abrufen von Aufträgen, die Aktualisierung der Statusarten von Aufträgen und das Löschen von Aufträgen.
Create Coffee Lambda-Funktion
Diese Funktion erstellt einen Auftrag:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
Diese Lambda-Funktion verwaltet die Erstellung eines neuen Kaffeeauftrags in der DynamoDB-Tabelle. Zuerst importieren wir das AWS SDK und initialisieren einen DynamoDB.DocumentClient, um mit DynamoDB zu interagieren. Die Bibliothek uuid wird ebenfalls importiert, um eindeutige Auftrags-IDs zu generieren.
Innerhalb der handler Funktion parsen wir den eingehenden Anfragebody, um Kundeninformationen zu extrahieren, wie z.B. den Kundennamen und die bevorzugte Kaffeeblendung. Ein eindeutiges orderId wird mit uuidv4() generiert und diese Daten werden für die Einfügung in DynamoDB vorbereitet.
Objekt definiert die Tabelle, in der die Daten gespeichert werden, mit TableName, die dynamisch auf den Wert der Umgebungsvariable COFFEE_ORDERS_TABLE gesetzt wird. Der neue Auftrag enthält Felder wie OrderId, CustomerName, CoffeeBlend und einen anfänglichen Status von Pending.
Im try-Block versucht der Code, den Auftrag mithilfe der put()-Methode zur DynamoDB-Tabelle hinzuzufügen. Bei Erfolg gibt die Funktion einen Statuscode von 200 mit einer Erfolgsnachricht und der OrderId zurück. Wenn es einen Fehler gibt, fängt der Code ihn ab und gibt einen Statuscode von 500 zusammen mit einer Fehlermeldung zurück.
Get Coffee Lambda-Funktion
Diese Funktion ruft alle Kaffeeprodukte ab:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
Diese Lambda-Funktion ist verantwortlich für das Abrufen aller Kaffeeaufträge aus einer DynamoDB-Tabelle und demonstriert einen serverlosen Ansatz zum Abrufen von Daten aus DynamoDB auf skalierbare Weise.
Wir verwenden erneut die AWS SDK, um eine DynamoDB.DocumentClient-Instanz zu initialisieren, um mit DynamoDB zu interagieren. Die handler-Funktion konstruiert das params-Objekt, indem sie die TableName angibt, die mithilfe der COFFEE_ORDERS_TABLE-Umgebungsvariable dynamisch festgelegt wird.
Die scan() Methode ruft alle Elemente aus der Tabelle ab. Wenn die Operation erfolgreich ist, gibt die Funktion einen Statuscode von 200 zurück zusammen mit den abgerufenen Elementen im JSON-Format. Im Falle eines Fehlers wird ein 500 Statuscode und eine Fehlermeldung zurückgegeben.
Aktualisieren der Coffee Lambda-Funktion
Diese Funktion aktualisiert ein Kaffeeprodukt anhand seiner ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
Diese Lambda-Funktion verwaltet die Aktualisierung des Status eines spezifischen Kaffeeraubays in der DynamoDB-Tabelle.
Die handler Funktion extrahiert die order_id, new_status und customer_name aus dem Anfragekörper. Anschließend konstruiert sie das params Objekt, um den Tabellennamen und den Primärschlüssel für die Bestellung anzugeben (unter Verwendung von OrderId und CustomerName). Die UpdateExpression setzt den neuen Status der Bestellung.
Im try Block versucht der Code, die Bestellung in DynamoDB mithilfe der update() Methode zu aktualisieren. Wenn dies erfolgreich ist, gibt die Funktion natürlich einen Statuscode von 200 mit einer Erfolgsmeldung zurück. Wenn ein Fehler auftritt, fängt er den Fehler ab und gibt einen 500 Statuscode zusammen mit einer Fehlermeldung zurück.
Löschen der Coffee Lambda-Funktion
Diese Funktion löscht ein Kaffeeprodukt anhand seiner ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
Die Lambda-Funktion löscht einen bestimmten Kaffeeauftrag aus der DynamoDB-Tabelle. In der Handler-Funktion liest der Code den Request-Body aus, um die order_id und customer_name zu extrahieren. Diese Werte werden als Primärschlüssel verwendet, um das zu löschende Element in der Tabelle zu identifizieren. Das params-Objekt gibt den Tabellennamen und den Schlüssel für das zu löschende Element an.
Im try-Block versucht der Code, den Auftrag aus DynamoDB mithilfe der delete()-Methode zu löschen. Wenn dies erfolgreich ist, wird erneut ein 200-Statuscode mit einer Erfolgsmeldung zurückgegeben, die anzeigt, dass der Auftrag gelöscht wurde. Wenn ein Fehler auftritt, fängt der Code ihn ab und gibt einen 500-Statuscode zusammen mit einer Fehlermeldung zurück.
Nun, da wir jede Lambda-Funktion erklärt haben, richten wir ein mehrstufiges CI/CD-Pipeline ein.
Schritt 4: Einrichten von CI/CD-Pipeline Mehrphasen-Deployments für Dev- und Prod-Umgebungen
Um AWS-Sicherheitsinformationen in Ihrem GitHub-Repository einzurichten, navigieren Sie zunächst zu den Einstellungen des Repositorys. Wählen Sie oben rechts Einstellungen und dann unten links Sicherheitsinformationen und Variablen.

Als nächstes klicken Sie auf Aktionen, wie unten gezeigt:
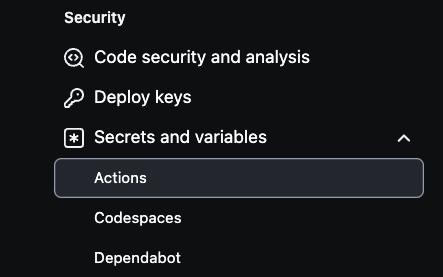
Dort wählen Sie Neue Repository-Sicherheit, um Sicherheitsinformationen zu erstellen.
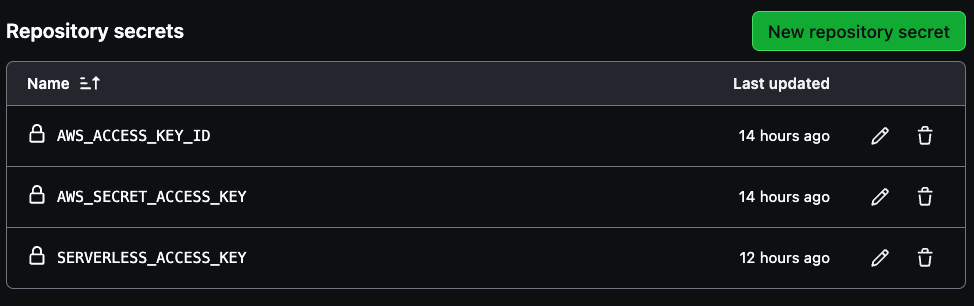
Es werden drei Sicherheitsinformationen für Ihre Pipeline benötigt: AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY und SERVERLESS_ACCESS_KEY.
Nutzen Sie Ihre AWS-Zugangskey-Zugangsdaten für die ersten beiden Variablen und dann den serverlosen Zugangskey, der zuvor gespeichert wurde, um den SERVERLESS_ACCESS_KEY zu erstellen. Diese Geheimnisse werden Ihre CI/CD-Pipeline sicher authentifizieren, wie im Bild unten zu sehen.
Stellen Sie sicher, dass Ihr Hauptzweig „main“ heißt, da dies der Produktionszweig sein wird. Als nächstes erstellen Sie einen neuen Zweig namens „dev“ für Entwicklungsarbeiten.
Sie können auch branch-spezifische Funktionen wie „dev/feature“ für eine detailliertere Entwicklung erstellen. GitHub Actions verwendet diese Zweige, um Änderungen automatisch zu deployen, wobei dev die Entwicklungsumgebung und main die Produktion darstellt.
Diese Branching-Strategie ermöglicht es Ihnen, die CI/CD-Pipeline effizient zu verwalten und neue Codeänderungen zu deployen, wenn es einen Merge in die dev- oder prod-Umgebung gibt.
So verwenden Sie GitHub Actions, um die YAML-Datei zu deployen
Um den Deploymentsprozess für die Coffee Shop API zu automatisieren, nutzen Sie GitHub Actions, das mit Ihrem GitHub-Repository integriert ist.
Diese Deployment-Pipeline wird ausgelöst, wenn Code in die main- oder dev-Zweige gepusht wird. Durch die Konfiguration von umgebungsspezifischen Deploymenten stellen Sie sicher, dass Updates zum dev-Zweig in die Entwicklungsumgebung deployen und Änderungen am main-Zweig Produktionsdeployments auslösen.
Jetzt, lass uns den Code überprüfen:
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
Der GitHub Actions YAML-Konfiguration ist es, die den Deployment-Prozess der Coffee Shop API auf AWS mit dem Serverless Framework automatisiert. Der Workflow wird ausgelöst, wenn Änderungen auf der Haupt- oder Entwicklungsbranch gepusht werden.
Er beginnt mit dem Herunterladen des Codes des Repositories und setzt Node.js mit der Version 20.x ein, um die Laufzeit zu entsprechen, die von den Lambda-Funktionen verwendet wird. Anschließend installiert er die Projektabhängigkeiten, indem er zum Verzeichnis coffee-shop-api navigiert und npm install ausführt.
Der Workflow installiert auch das Serverless Framework global, was es dem serverless CLI erlaubt, für die Deployments zu verwendet werden. Je nachdem, auf welcher Branch die Änderungen aktualisiert werden, deployt der Workflow bedingt in die entsprechende Umgebung.
Wenn die Änderungen auf der Entwicklungsbranch gepusht werden, wird es in die Entwicklungsstufe deployt. Wenn sie auf der Hauptbranch gepusht werden, wird es in die Produktivstufe deployt. Die Deployment-Befehle npx serverless deploy --stage dev oder npx serverless deploy --stage prod werden innerhalb des coffee-shop-api-Verzeichnisses ausgeführt.
Für eine sichere Deployment nutzt der Workflow AWS-Anmeldeinformationen und den Serverless-Zugriffsschlüssel mittels von GitHub Secrets gespeicherter Umgebungsvariablen. Dies ermöglicht es dem CI/CD-Pipeline, mit AWS und dem Serverless Framework zu authentifizieren, ohne sensible Informationen im Repository zu verwirren.
Nun können wir mit der Testung des Pipelines fortfahren.
Schritt 5: Testen der Entwicklungs- und Produktivpipelines
Du musst zuerst sicherstellen, dass die Haupt-Branch (prod) „main“ heißt. Dann erstelle einen Dev-Branch namens „dev„. Sobald du Änderungen am Dev-Branch vornimmst, committest diese, um den GitHub Actions-Pipeline auszulösen. Dadurch werden die aktualisierten Ressourcen automatisch in die Entwicklungsumgebung.deployed. Nachdem du alles in Dev überprüft hast, kannst du den Dev-Branch in den Main-Branch mergen.
Das Mergen von Änderungen in den Main-Branch löst auch automatisch die Deployments-Pipeline für die Produktionsumgebung aus. Auf diese Weise werden alle notwendigen Updates angewendet und die Produktionsressourcen nahtlos deployt.
Du kannst den Deploymentsprozess überwachen und detaillierte Logs jeder GitHub Actions-Ausführung einsehen, indem du auf den Tab „Actions“ in deinem GitHub-Repository navigierst.
Die Logs geben Einblick in jeden Schritt der Pipeline und helfen dir zu überprüfen, ob alles wie erwartet funktioniert.
Du kannst jeden Build-Lauf auswählen, um detaillierte Logs für die Deployment der Entwicklungsumgebung und der Produktionsumgebung zu überprüfen, um den Fortschritt zu verfolgen und sicherzustellen, dass alles flüssig läuft.
Navigiere zu dem spezifischen Build-Lauf in GitHub Actions, wie unten in dem Bild gezeigt. Dort kannst du die Ausführungsdetails und Ergebnisse für entweder die Entwicklung oder die Produktionspipelines einsehen.

Stelle sicher, dass du sowohl die Entwicklungsumgebung als auch die Produktionsumgebung gründlich testest, um die erfolgreiche Ausführung der Pipeline zu bestätigen.
Schritt 6: Teste und validiere die Prod- und Dev-APIs mit Postman.
Jetzt, da die APIs und Ressourcen bereitgestellt und konfiguriert sind, müssen wir die eindeutigen API-Endpunkte (URLs) von AWS finden, um Anfragen zur Überprüfung der Funktionalität zu stellen.
Diese URLs können die API-Funktionalität testen, indem sie einfach in einen Webbrowser eingefügt werden. Die API-URLs finden Sie in den Ausgaberesultaten Ihres CI/CD-Builds.
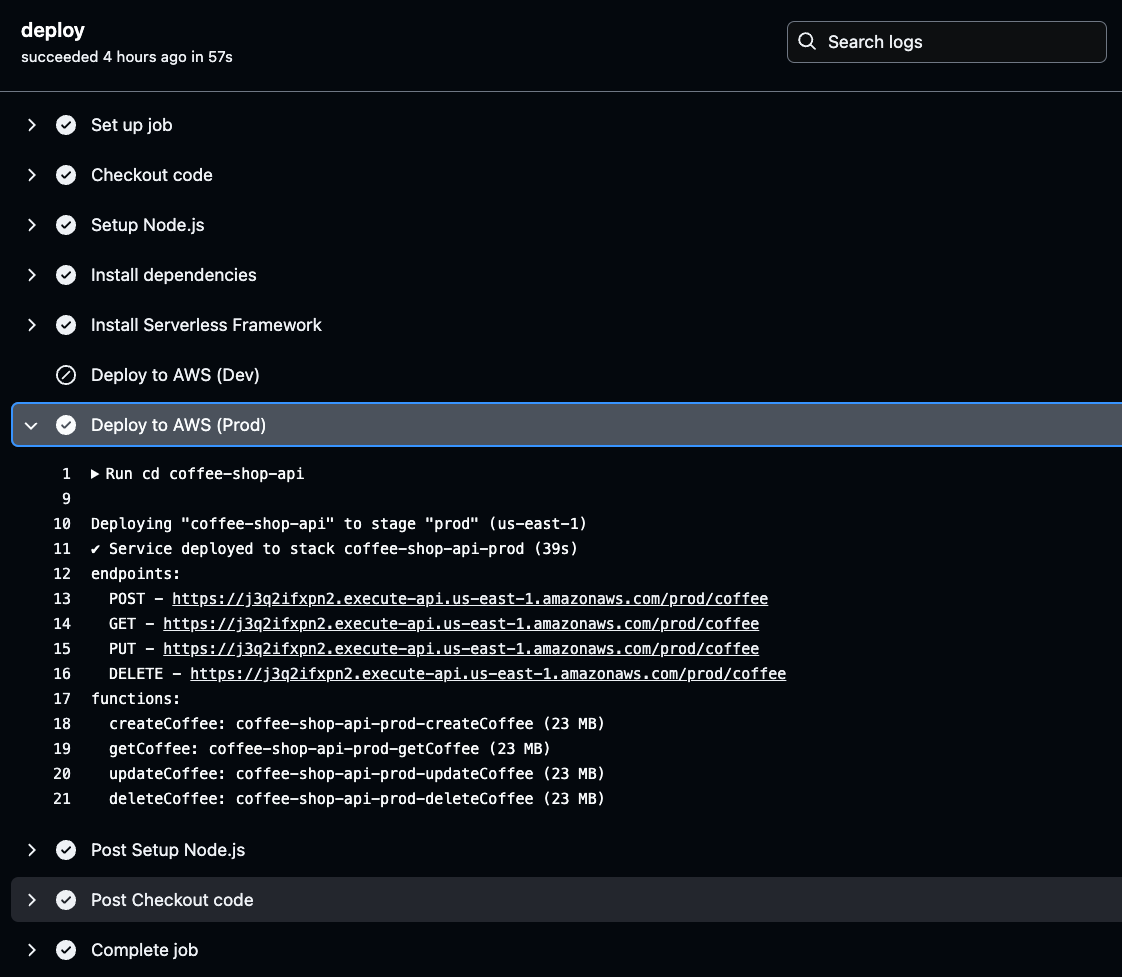
Um sie abzurufen, navigieren Sie zu den GitHub Actions-Protokollen, wählen Sie den erfolgreichsten Build der neuesten Umgebung aus und klicken Sie auf deploy, um die Bereitstellungsdetails für die generierten API-Endpunkte zu überprüfen.
Klicken Sie auf die Stufe Deploy to AWS für die ausgewählte Umgebung (Prod oder Dev) in Ihren GitHub Actions-Protokollen. Dort finden Sie die generierte API-URL.
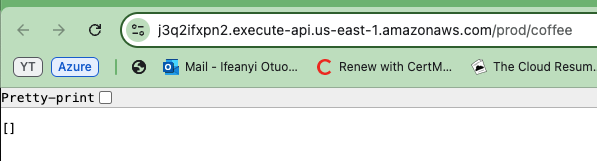
Kopieren und speichern Sie diese URL, da sie zum Testen der Funktionalität Ihrer API benötigt wird. Diese URL ist Ihr Zugangspunkt, um sicherzustellen, dass die bereitgestellte API wie erwartet funktioniert.
Kopieren Sie nun eine der generierten API-URLs und fügen Sie sie in Ihren Browser ein. Sie werden ein leeres Array oder eine leere Liste in der Antwort sehen. Dies bestätigt tatsächlich, dass die API korrekt funktioniert und dass Sie Daten aus der DynamoDB-Tabelle erfolgreich abrufen.
Auch wenn die Liste leer ist, zeigt dies an, dass die API eine Verbindung zur Datenbank herstellen und Informationen zurückgeben kann.
Um zu überprüfen, dass Ihre API in beiden Umgebungen funktioniert, wiederholen Sie die Schritte für die andere API-Umgebung (Prod und Dev).
Für eine umfassendere Testung werden wir Postman verwenden, um alle API-Methoden Create, Read, Update und Delete zu testen und diese Tests sowohl für die Entwicklungsumgebung als auch für die Produktionsumgebung durchzuführen.
Um die GET-Methode zu testen, verwenden Sie Postman, um einen GET-Anfrage an die API-Endpunkt mit der URL zu senden. Sie erhalten dieselbe Antwort, eine leere Liste von Kaffeebestellungen, wie unten im Bild zu sehen ist. Dies bestätigt die Fähigkeit der API, Daten erfolgreich abzurufen, wie im Bild unten dargestellt.

Um tatsächlich eine Bestellung zu erstellen, testen wir die POST-Methode. Verwenden Sie Postman erneut, um einen POST-Anfrage an die API-Endpunkt zu senden und geben Sie im Anfragebody den Kundennamen und den Kaffeeblend an, wie unten gezeigt:
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
Die Antwort wird ein erfolgreiches Meldung mit einer eindeutigen Bestellnummer der platzierten Bestellung sein.
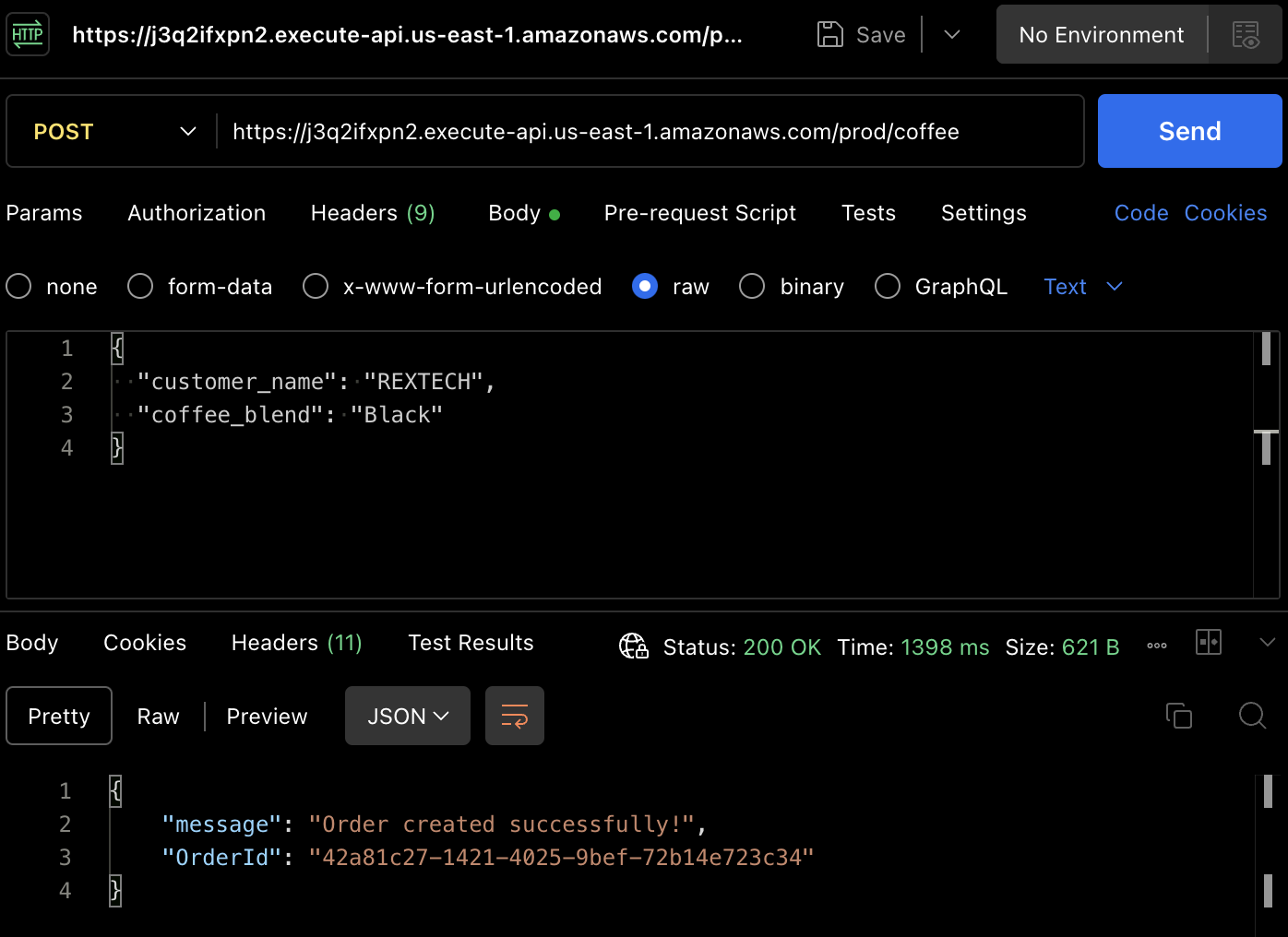
Prüfen Sie, ob die neue Bestellung in der DynamoDB-Tabelle gespeichert wurde, indem Sie die Elemente in der spezifischen Tabelle für die Umgebung überprüfen:

Um die PUT-Methode zu testen, senden Sie eine PUT-Anfrage an die API-Endpunkt, indem Sie die vorherige Bestellnummer und einen neuen Bestellstatus im Anfragebody angeben, wie unten gezeigt:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
Die Antwort wird ein erfolgreiches Update-Meldung mit der Bestellnummer der platzierten Bestellung sein.
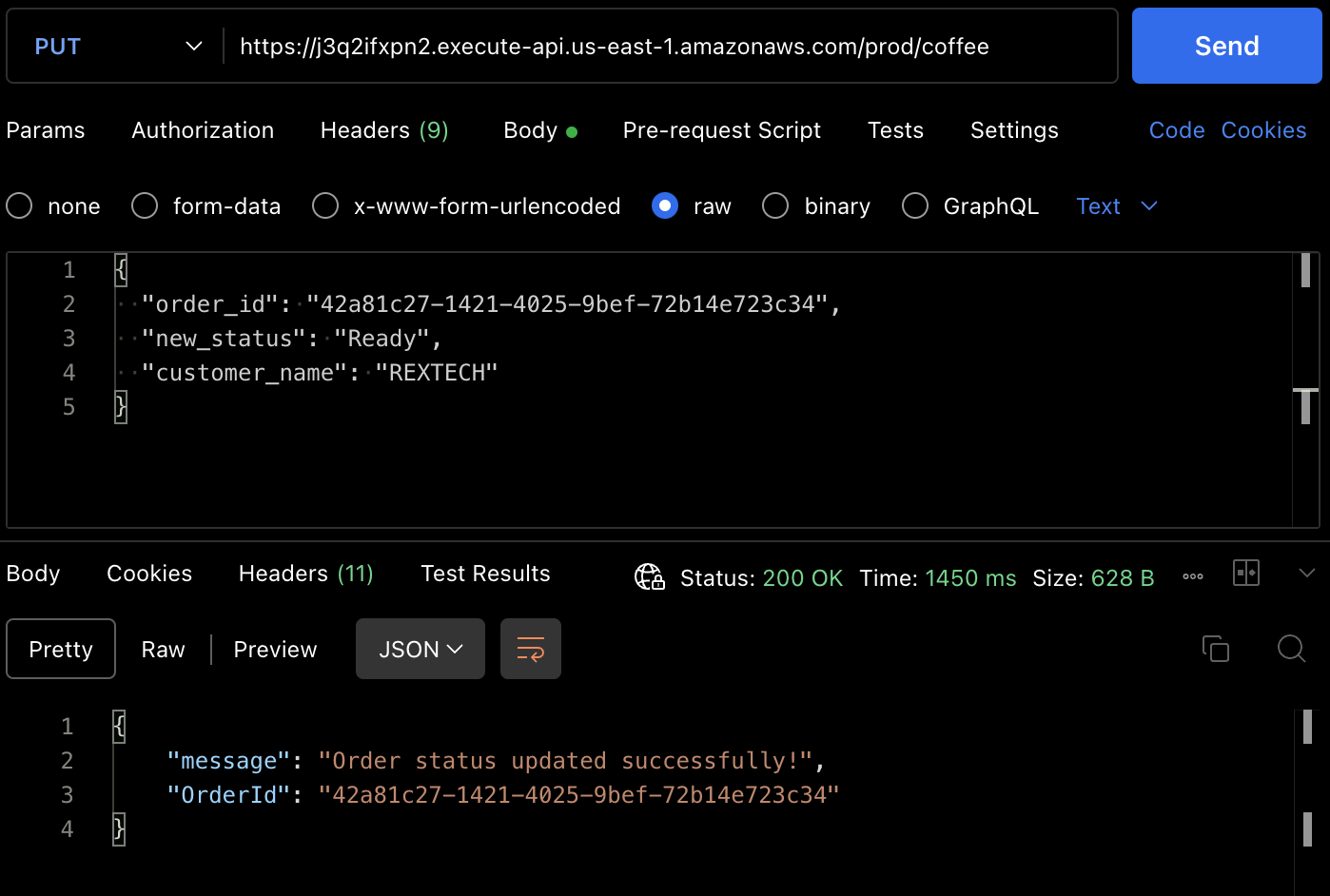
Sie können auch überprüfen, dass der Bestellstatus von der DynamoDB-Tabelle geändert wurde.

Um die DELETE-Methode zu testen, verwenden Sie Postman, um eine DELETE-Anfrage zu senden, und geben Sie die vorherige Bestellnummer und den Kundennamen im Anfragebody an, wie unten gezeigt:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
Es wurde eine erfolgreiche Löschung einer Bestellung mit der Bestellnummer zurückgegeben.
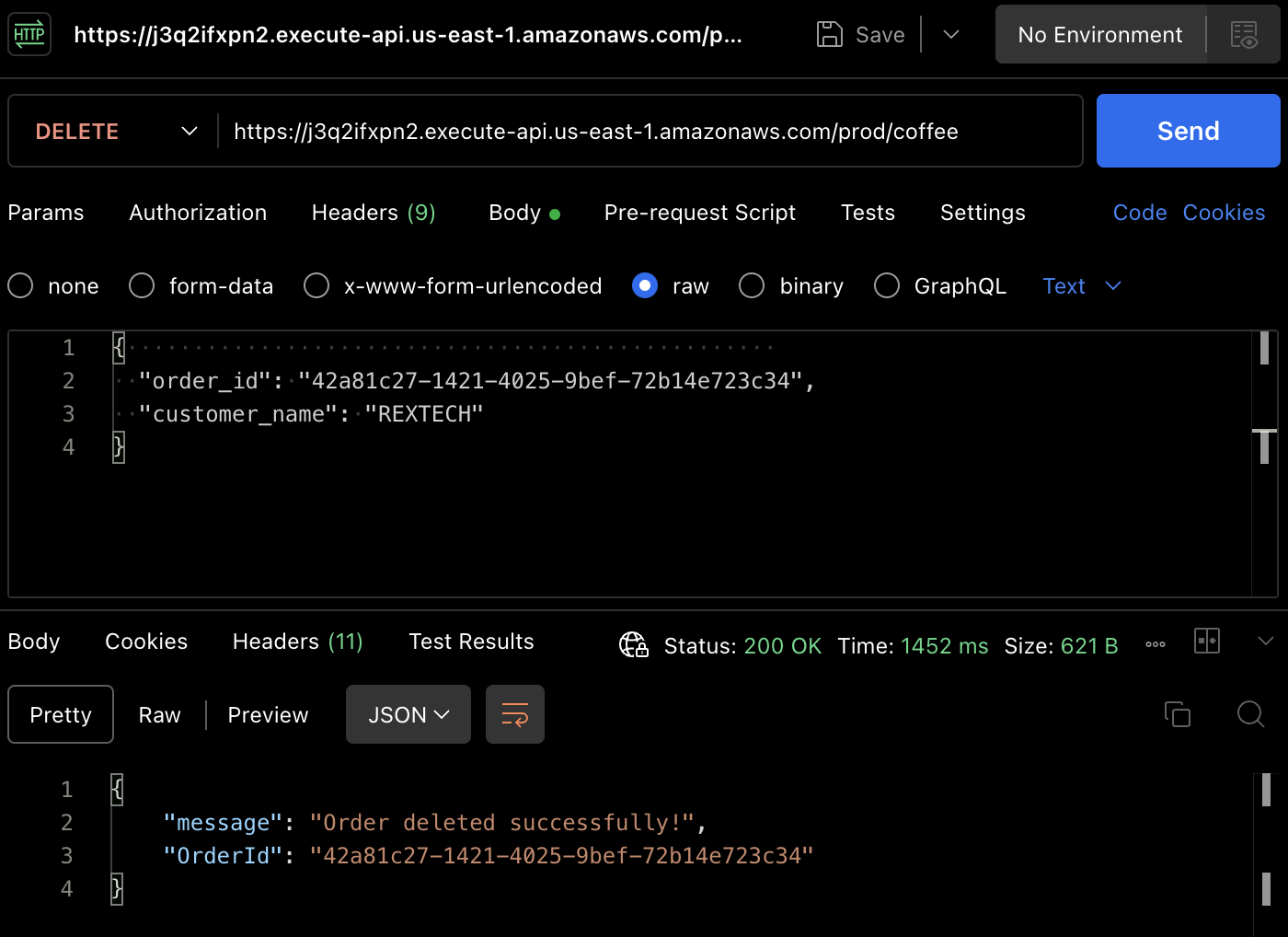
Wiederholt können Sie überprüfen, dass die Bestellung in der DynamoDB-Tabelle gelöscht wurde.

Schlussfolgerung
Das ist alles – Glückwunsch! Sie haben erfolgreich alle Schritte abgeschlossen. Wir haben ein serverloses REST-API erstellt, das CRUD-Funktionalität (Erstellen, Lesen, Aktualisieren, Löschen) unterstützt und mit API Gateway, Lambda, DynamoDB, Serverless Framework und Node.js umgesetzt, automatisierte Bereitstellung von genehmigten Codeänderungen mit Github Actions.
Wenn Sie bis hierher gekommen sind, vielen Dank für Ihre Lesung! Ich hoffe, es hat Ihnen gefallen.
Ifeanyi Otuonye ist ein 6x AWS Certified Cloud Engineer mit Fachkenntnissen in DevOps, technischer Schreibweise und Lehrerfahrung als technischer Dozent. Er ist von seiner Begeisterung zu lernen und sich zu entwickeln motiviert und thrivt in kollaborativen Umgebungen. Vor dem Übergang zum Cloud Computing war er sechs Jahre lang professioneller Leichtathlet.
Anfang 2022 begann er strategisch mit einer Mission, Cloud/DevOps-Ingenieur zu werden, durch Selbststudium und durch das Beitreten eines sechsmonatigen beschleunigten Cloud-Programms.
Im Mai 2023 erreichte er dieses Ziel und erhielt seinen ersten Cloud-Ingenieurposten und hat nun eine weitere persönliche Mission gesetzt, andere Individuen auf ihrem Weg ins Cloud zu unterstützen.
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/