













无服务器计算是对传统基于服务器架构的挑战的回应。在无服务器模式下,开发者不再需要手动管理或扩展服务器。相反,云服务提供商负责基础设施管理,使得团队能够完全专注于编写和部署代码。
无服务器解决方案根据需求自动扩展,并采用按量付费模型。这意味着你只需为你的应用程序实际使用的资源付费。这种方法显著降低了运营成本,提高了灵活性并加快了开发周期,使其成为现代应用开发的一个有吸引力的选择。
通过抽象化服务器管理,无服务器平台让你能够专注于业务逻辑和应用程序功能。这导致了更快的部署和更多的创新。无服务器架构也是事件驱动的,这意味着它们可以自动响应实时事件,并在不需要人工干预的情况下扩展以满足用户需求。
目录
-
第3步:开发CRUD操作的Lambda函数
-
创建咖啡Lambda函数
-
获取咖啡Lambda函数
-
更新咖啡Lambda函数
-
删除咖啡Lambda函数
-
在深入技术细节之前,我们将介绍一些关键背景概念。
重要概念理解
应用程序编程接口(API)
应用程序编程接口(API)允许不同的软件应用程序相互通信和交互。它定义了应用程序可以用来请求和交换信息的方法和数据格式,以实现不同系统之间的集成和数据共享。
HTTP方法
HTTP方法或请求方法是Web服务和API的关键组成部分。它们指示在给定的请求URL上对资源执行所需动作。
在RESTful API中最常用的方法有:
-
GET:用于从服务器检索数据
-
POST:将数据(包含在请求体中)发送到创建或更新资源
-
PUT:更新或替换现有资源,或如果它不存在则创建新资源
-
DELETE:从服务器上删除指定的数据。
亚马逊API网关
亚马逊API网关是一项完全托管的服务,它使开发者能够轻松地创建、发布、维护、监控和保护大规模API。它作为多个API的入口点,管理和控制客户端(如网络或移动应用程序)与后端服务之间的互动。
它还提供了各种功能,包括请求路由、安全、身份验证、缓存和速率限制,这些功能有助于简化API的管理和部署。
亚马逊DynamoDB
DynamoDB是一项完全托管的NoSQL数据库服务,旨在实现高可扩展性、低延迟和跨多个区域复制数据。
DynamoDB以无模式格式存储数据,支持灵活且快速地存储和检索结构化和半结构化数据。它通常用于构建在云环境中的可扩展和响应式应用程序。
无服务器CRUD应用程序
无服务器CRUD应用程序指的是创建、读取、更新和删除数据的能力。但是,涉及的建筑和组件与传统的基于服务器的应用程序不同。
创建涉及将新条目添加到DynamoDB表中。读取操作从DynamoDB表中检索数据。更新操作更新DynamoDB中的现有数据。而删除操作从DynamoDB中删除数据。
Serverless Framework
无服务器框架是一个开源工具,它简化了在多个云提供商(包括AWS)之间部署和管理无服务器应用程序的过程。它通过允许开发者使用YAML文件定义他们的基础设施为代码,抽象化了提供和管理基础设施的复杂性。
该框架处理无服务器函数、API和其他资源的部署、扩展和更新。
GitHub Actions
GitHub Actions是一个强大的CI/CD自动化工具,允许开发人员直接从他们的GitHub仓库自动化他们的软件工作流程。
使用GitHub Actions,您可以创建自定义管道,由代码推送、拉取请求或分支合并等事件触发。这些工作流程定义在仓库内的YAML文件中,可以执行测试、构建和将应用程序部署到各种环境等任务。
Postman
Postman是一个流行的协作平台,它简化了设计、测试和文档化API的过程。它为开发者提供了一个用户友好的界面,用于创建和发送HTTP请求、测试API端点以及自动化测试工作流程。
好的,现在您已经熟悉了我们将要使用的工具和技术,让我们开始吧。
先决条件
-
安装了Node.js和npm
-
AWS CLI配置好,可以访问您的AWS账户
-
一个Serverlesss Framework账户
-
无服务器框架已在全球范围内安装在您的本地CLI中
我们的用例
介绍一下Alyx,一个最近一直在学习无服务器架构的企业家。她阅读了关于无服务器架构是一种构建网站后端的有效和高效的方式,为网站应用程序开发提供了更现代的方法。
她想应用到目前为止所学的无服务器架构的基本原理。她知道无服务器并不意味着没有服务器参与 – 相反,它只是将服务器的管理和配置抽象化。现在她想专注于编写代码和实现业务逻辑。
让我们来看看Alyx,一家繁荣的咖啡店的店主,如何开始利用无服务器架构为她的网站后端提供支持。
Alyx的咖啡天堂是一家在线咖啡店,提供各种咖啡混合物和甜点供购买。最初,Alyx使用传统的网站托管服务和操作来管理商店的订单和库存,她处理多个服务器和资源。但随着她的咖啡店越来越受欢迎,她在高峰时段和季节性促销期间开始面临越来越多的订单。
对于Alyx来说,管理服务器并确保应用程序能够处理流量激增成为了一个挑战。她发现自己总是在担心服务器容量、可扩展性和基础设施的维护成本。
她还想要引入个性化推荐和忠诚度计划等新功能,但在传统的设置限制下,这变成了一项艰巨的任务。
然后Alyx了解了无服务器概念。她将无服务器后端比作一个咖啡师,可以实时自动冲泡咖啡,而她无需担心咖啡制作过程的复杂细节。
受到这个想法的启发,Alyx决定将咖啡店的后端迁移到使用AWS Lambda、AWS API Gateway和Amazon DynamoDB的无服务器平台。这个设置让她可以更多地专注于为顾客制作完美的咖啡混合和点心。
借助无服务器,每个顾客的订单都成为触发一系列无服务器函数的事件。单独的AWS Lambda函数处理订单并处理所有幕后业务逻辑。例如,它创建顾客的订单并能够检索该订单。它还可以删除某人的订单或更新订单状态。
Alyx不再需要担心管理服务器,因为无服务器平台会根据传入的订单请求自动进行扩展和缩减。此外,无服务器的高成本效益对Alyx来说非常重要。采用按需付费的模式,她只需为她函数实际消耗的计算时间付费,这对于她不断增长的业务来说是一个更具成本效益的解决方案。
但她并不止步于此!她还想要自动化一切,从部署基础架构到每次有新更改时更新她的应用程序。通过使用Serverless Framework的基础设施即代码(IaC),她可以用代码定义所有的基础架构并轻松管理。
在此基础上,她设置了GitHub Actions用于持续集成和交付(CI/CD),这样她所做的每一个更改都会通过管道自动部署,无论是开发中的新功能还是生产的热修复。
教程目标
-
设置Serverless Framework环境
-
在YAML文件中定义API
-
开发AWS Lambda函数以处理CRUD操作
-
为开发和生产设置多阶段部署
-
测试开发和生产管道
-
使用Postman测试和验证开发和生产API
如何开始:克隆Git仓库
为了更好地理解和跟随本教程,请克隆我的 GitHub 上的项目仓库。你可以通过这里进行操作。在我们继续前进的过程中,可以随意修改文件。
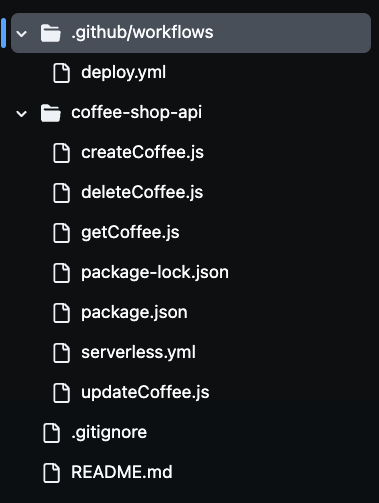
克隆仓库后,你会注意到你的文件夹中有多文件,如下图所示。我们将使用这些文件来构建我们的无服务器咖啡店API。
第一步:设置 Serverless 框架环境
为了设置用于自动化部署的 Serverless 框架环境,你需要通过 CLI 认证你的 Serverless 框架账户。
这需要创建一个访问密钥,使管道能够使用 Serverless 框架安全地认证进入你的账户,而不暴露你的凭据。通过登录你的 Serverless 账户并生成一个访问密钥,管道可以从构建配置文件中自动部署你的无服务器应用程序。
为此,前往你的 Serverless 账户并导航到访问密钥部分。点击“+添加”,命名为 SERVERLESS_ACCESS_KEY,然后创建密钥。
创建访问密钥后,请确保妥善复制和存储。你将使用这个密钥作为 GitHub 仓库中的一个秘密变量,以认证和授权你的 CI/CD 管道。
在部署过程中,它会为您提供对Serverless Framework账户的访问权限。您稍后需要将此密钥添加到您的GitHub仓库的机密中,以便您的流水线可以安全地使用它来部署无服务器资源,而无需在代码库中暴露敏感信息。
现在,让我们在severless.yaml文件中定义AWS资源作为代码。
第2步:在Serverless YAML文件中定义API
在此文件中,您将使用Serverless Framework的YAML配置来定义Coffee Shop API的核心基础设施和功能。
此文件定义了所使用的AWS服务,包括API网关、用于CRUD操作的Lambda函数以及用于数据存储的DynamoDB。
您还将配置一个IAM角色,以便Lambda函数具有与DynamoDB服务交互所需的必要权限。
API网关设置适当的HTTP方法(POST、GET、PUT 和 DELETE),以处理传入请求并触发相应的Lambda函数。
让我们来看看代码:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
serverless.yml 配置定义了Alyx的Coffee Shop API如何在AWS上的无服务器环境中运行。提供商 部分指定了应用程序将使用AWS作为云提供商,并使用 Node.js 作为运行时环境。
区域被设置为us-east-1,而stage变量允许在不同的环境(如开发和生产)之间动态部署。这意味着相同的代码可以部署到不同的环境,并且资源会相应地命名以避免冲突。
在iam部分,授权Lambda函数与DynamoDB表交互。使用${self:provider.stage}语法动态命名DynamoDB表,这样每个环境都有自己单独的资源,如开发环境的CoffeeOrders-dev和生产环境的CoffeeOrders-prod。这种动态命名有助于管理多个环境,无需为每个环境手动配置单独的表。
functions部分定义了四个核心Lambda函数:createCoffee、getCoffee、updateCoffee和deleteCoffee。这些函数处理咖啡店API的CRUD操作。
每个函数都与API网关中的特定HTTP方法相关联,如POST、GET、PUT和DELETE。这些函数与根据当前阶段动态命名的DynamoDB表交互。
最后的resources部分定义了DynamoDB表本身。它使用属性OrderId和CustomerName设置表,这些属性用作主键。表被配置为使用按请求付费的计费模式,这对于Alyx日益增长的业务来说是非常划算的。
通过使用Serverless Framework自动化部署这些资源,Alyx可以轻松管理她的基础设施,使她摆脱了手动配置和扩展资源的负担。
步骤3:开发用于CRUD操作的Lambda函数
在这一步中,我们通过使用JavaScript创建Lambda函数来实现Alyx咖啡店API的核心逻辑,执行基本的CRUD操作createCoffee,getCoffee,updateCoffee和deleteCoffee。
这些函数使用AWS SDK与AWS服务交互,特别是DynamoDB。每个函数将负责处理特定的API请求,如创建订单、检索订单、更新订单状态和删除订单。
创建咖啡Lambda函数
这个函数用于创建一个订单:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
这个Lambda函数处理在DynamoDB表中创建新的咖啡订单。首先我们导入AWS SDK并初始化一个DynamoDB.DocumentClient以与DynamoDB交互。还导入了uuid库以生成唯一的订单ID。
在handler函数内部,我们解析传入的请求体以提取客户信息,例如顾客的姓名和喜欢的咖啡混合。使用uuidv4()生成唯一的orderId,并准备将此数据插入到DynamoDB中。
参数对象定义了存储数据的表格,其中TableName动态设置为环境变量COFFEE_ORDERS_TABLE的值。新订单包括诸如OrderId、CustomerName、CoffeeBlend等字段,以及初始状态Pending。
在try块中,代码尝试使用put()方法将订单添加到DynamoDB表格中。如果成功,函数返回状态码200和成功消息以及OrderId。如果出现错误,代码捕获错误并返回500状态码和错误消息。
获取咖啡Lambda函数
此函数检索所有咖啡项目:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
这个Lambda函数负责从DynamoDB表中检索所有咖啡订单,并展示了在可扩展的方式下从DynamoDB检索数据的服务器端方法。
我们再次使用AWS SDK初始化一个DynamoDB.DocumentClient实例来与DynamoDB交互。handler函数构建params对象,指定动态使用COFFEE_ORDERS_TABLE环境变量设置的TableName。
scan()方法从表中检索所有项。如果操作成功,该函数将返回状态码200,并附上以JSON格式检索到的项。如果发生错误,将返回500状态码和错误消息。
更新咖啡Lambda函数
此函数通过其ID更新咖啡项:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
此Lambda函数处理在DynamoDB表中更新特定咖啡订单状态的操作。
handler函数从请求体中提取order_id、new_status和customer_name。然后构造params对象以指定表名和订单的主键(使用OrderId和CustomerName)。UpdateExpression设置订单的新状态。
在try块中,代码尝试使用update()方法在DynamoDB中更新订单。当然,如果成功,函数将返回状态码200和成功消息。如果发生错误,它将捕获错误并返回500状态码和错误消息。
删除咖啡Lambda函数
此函数通过其ID删除咖啡项:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
Lambda函数从DynamoDB表中删除特定的咖啡订单。在处理函数中,代码解析请求体以提取order_id和customer_name。这些值用作识别要从中删除项目的键。params对象指定了要删除的项目的表名和键。
在try块中,代码尝试使用delete()方法从DynamoDB中删除订单。如果成功,它再次返回一个200状态码和成功消息,表示订单已被删除。如果发生错误,代码会捕获它,并返回一个500状态码和一个错误消息。
现在我们已经解释了每个Lambda函数,让我们为开发和生产环境设置一个多阶段的CI/CD管道。
第4步:为Dev和Prod环境设置多阶段CI/CD管道部署
要 在你的GitHub仓库中设置AWS密钥,首先导航到仓库的设置。在顶部的右上角选择Settings,然后转到左下角选择Secrets and variables.

接下来,点击Actions,如下图所示:
从那里,选择New repository secret来创建密钥。
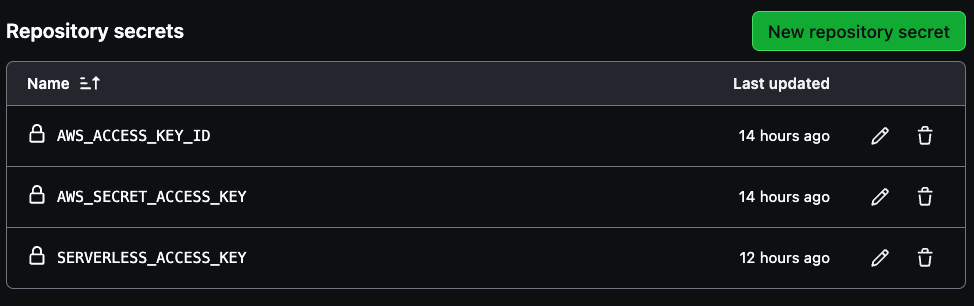
你的管道需要创建三个密钥AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY和SERVERLESS_ACCESS_KEY。
请使用您的AWS账户访问密钥凭证为前两个变量提供凭据,然后使用之前保存的服务器无访问密钥创建 `SERVERLESS_ACCESS_KEY`。这些密钥将安全地验证您的CI/CD流水线,如下图所示。`
`请确保您的默认分支命名为“`main”,因为这将作为生产分支。接下来,创建一个名为“`dev”的新分支用于开发工作。`
`您还可以创建特定功能的分支,例如“`dev/feature”,以实现更细粒度的开发。GitHub Actions将使用这些分支自动部署更改,其中`dev`代表开发环境,`main`代表生产环境。`
`这种分支策略使您能够高效地管理CI/CD流水线,只要有代码合并到dev或prod环境,就会部署新的代码更改。`
`如何使用GitHub Actions部署YAML文件`
`为了自动化Coffee Shop API的部署过程,您将使用与GitHub仓库集成的GitHub Actions。`
`此部署流水线在推送到main或dev分支时触发。通过配置环境特定的部署,您将确保dev分支的更新部署到开发环境,而main分支的变化触发生产部署。`
`现在,让我们回顾一下代码:
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
GitHub Actions 的 YAML 配置使用 Serverless Framework 自动化 Coffee Shop API 部署到 AWS 的过程。该工作流在推送到主分支或 dev 分支时触发。
它首先检出仓库的代码,然后设置 Node.js 20.x 版本以匹配 Lambda 函数使用的运行时。之后,它会通过导航到 coffee-shop-api 目录并运行 npm install 来安装项目依赖。
工作流还全局安装了 Serverless Framework,使得可以使用 serverless CLI 进行部署。根据哪个分支更新,工作流有条件地部署到适当的环境。
如果更改推送到 dev 分支,它将部署到 dev 阶段。如果推送到主分支,它将部署到 prod 阶段。部署命令 npx serverless deploy --stage dev 或 npx serverless deploy --stage prod 在 coffee-shop-api 目录中执行。
为了安全部署,工作流通过 GitHub Secrets 中存储的环境变量访问 AWS 凭证和 Serverless 访问密钥。这使得 CI/CD 管道可以在不暴露仓库中敏感信息的情况下与 AWS 和 Serverless Framework 进行身份验证。
现在,我们可以继续测试管道。
步骤 5:测试 Dev 和 Prod 管道
首先,你需要确认主(prod)分支的名称是“main”。然后创建一个名为“dev”的dev分支。一旦你在dev分支上进行了任何有效的更改,就提交这些更改以触发GitHub Actions流水线。这将自动将更新后的资源部署到开发环境。在dev环境中验证一切后,你可以将dev分支合并到主分支。
将更改合并到主分支也将自动触发生产环境的部署流水线。这样,所有必要的更新都被应用,生产资源可以无缝部署。
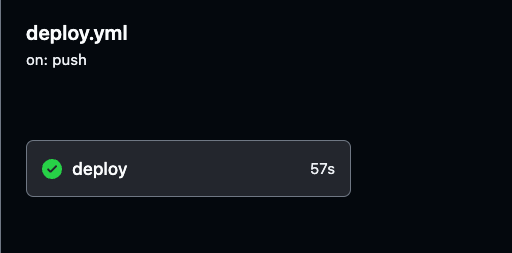
您可以通过导航到您GitHub仓库中的Actions标签来监控部署过程和查看每次GitHub Actions运行的详细日志。
日志提供了流水线的每个步骤的可见性,帮助您验证一切是否按预期工作。
您可以选择任何构建运行来查看开发和生产环境部署的详细日志,以便跟踪进度并确保一切顺利运行。
导航到GitHub Actions中的特定构建运行,如下图所示。在那里,您可以查看开发或生产管道的执行详细信息和结果。

请确保彻底测试开发和生产环境,以确认流水线成功执行。
第6步:使用Postman测试和验证prod和dev API。
现在,API和资源已经部署和配置完毕,我们需要找到AWS生成的唯一API端点(URL),以开始请求以测试功能。
这些URL可以通过简单地将它们粘贴到网页浏览器中来测试API功能。API URL可以在您的CI/CD构建的输出结果中找到。
要检索它们,请导航到GitHub Actions日志,选择最新环境的成功构建,然后点击deploy以查看生成的API端点的部署详细信息。
在GitHub Actions日志中,点击所选环境(Prod或Dev)的Deploy to AWS阶段。一旦进入,您将找到生成的API URL。
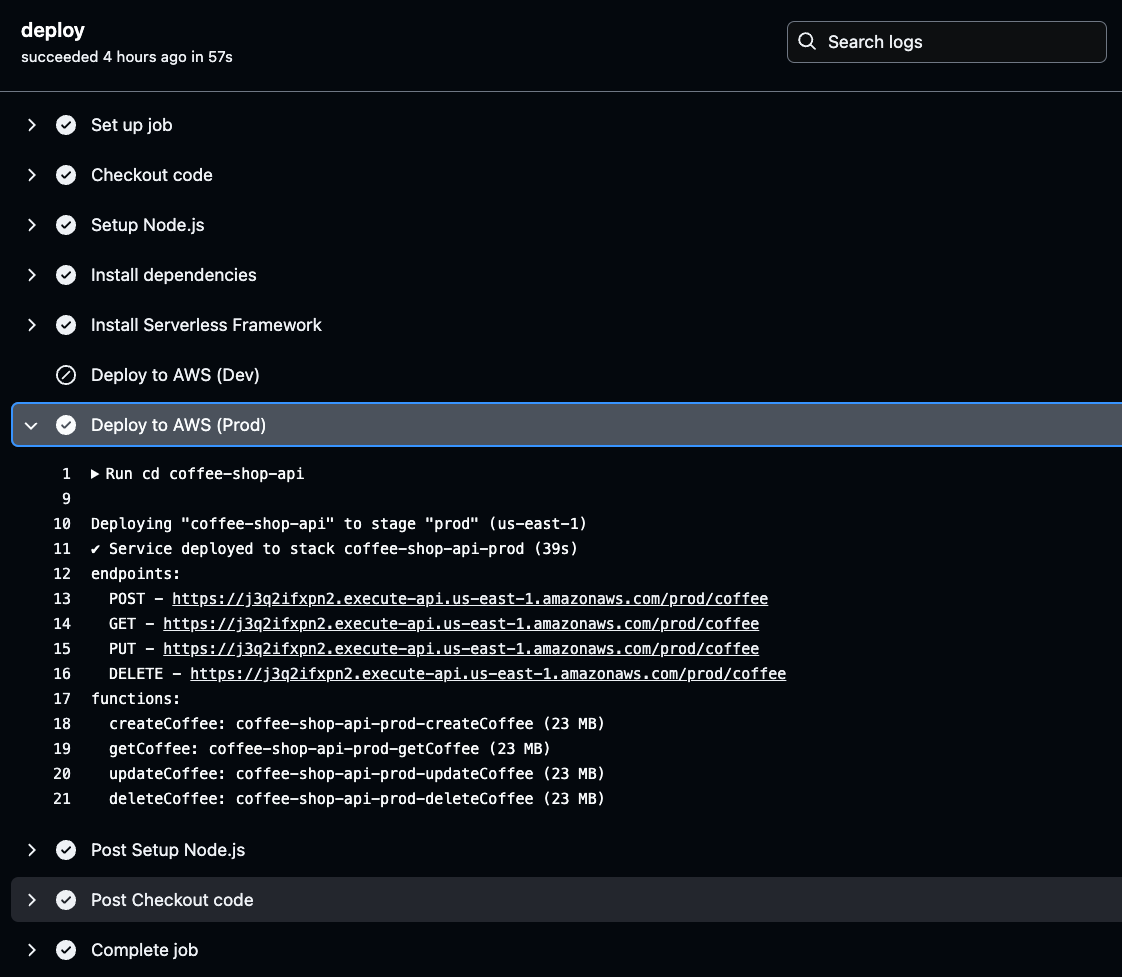
复制并保存此URL,因为在测试API功能时需要使用它。这个URL是验证已部署的API按预期工作的入口。
现在,复制一个生成的API URL并将其粘贴到您的浏览器中。您将在响应中看到一个空数组或列表。这实际上确认了API功能正常,并且您正在成功地从DynamoDB表中检索数据。
即使列表为空,这也表明API可以连接到数据库并返回信息。
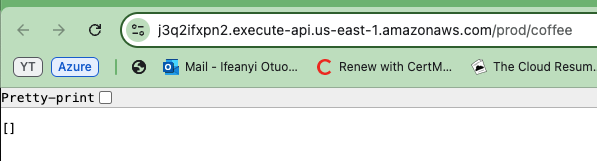
要验证您的API在两个环境中都能正常工作,请为另一个API环境(Prod和Dev)重复这些步骤。
我们将使用Postman测试所有的API方法,创建、读取、更新和删除,并对开发和生产环境进行这些测试。
为了测试GET方法,使用Postman向API端点的URL发送GET请求。您将收到相同的响应,如下图中所示的一个空咖啡订单列表。这证实了API成功检索数据的能力。

为了实际创建一个订单,让我们测试POST方法。再次使用Postman向API端点发起POST请求,并在请求正文中提供客户姓名和咖啡混合品种,如下所示:
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
响应将是一个成功消息,其中包含新订单的唯一OrderId。
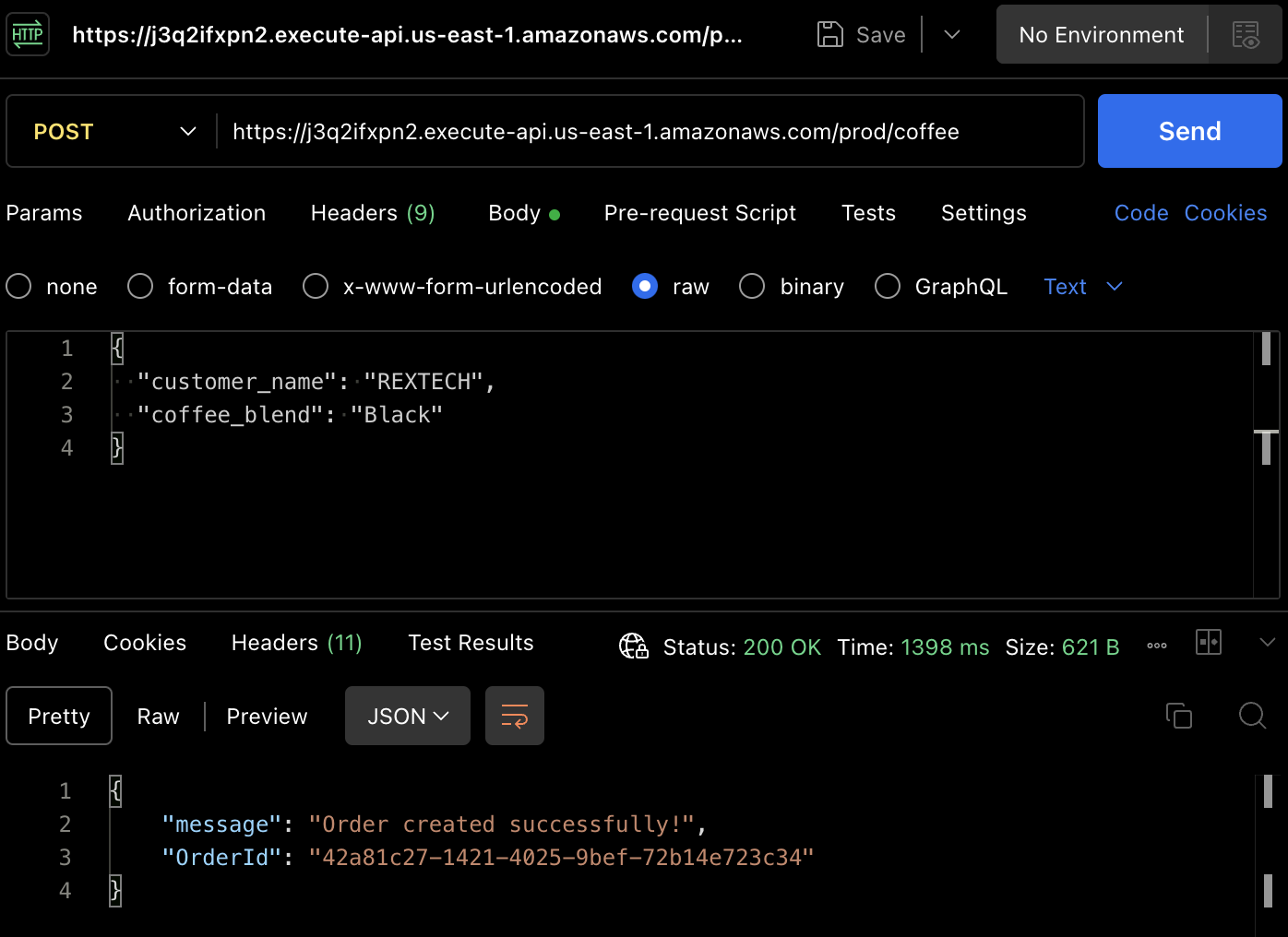
通过查看特定环境的表中项目,验证新订单是否已保存到DynamoDB表中:

为了测试PUT方法,向API端点发起PUT请求,并在请求正文中提供先前的订单ID和新的订单状态,如下所示:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
响应将是一个成功的订单更新消息,其中包含放置订单的OrderId。
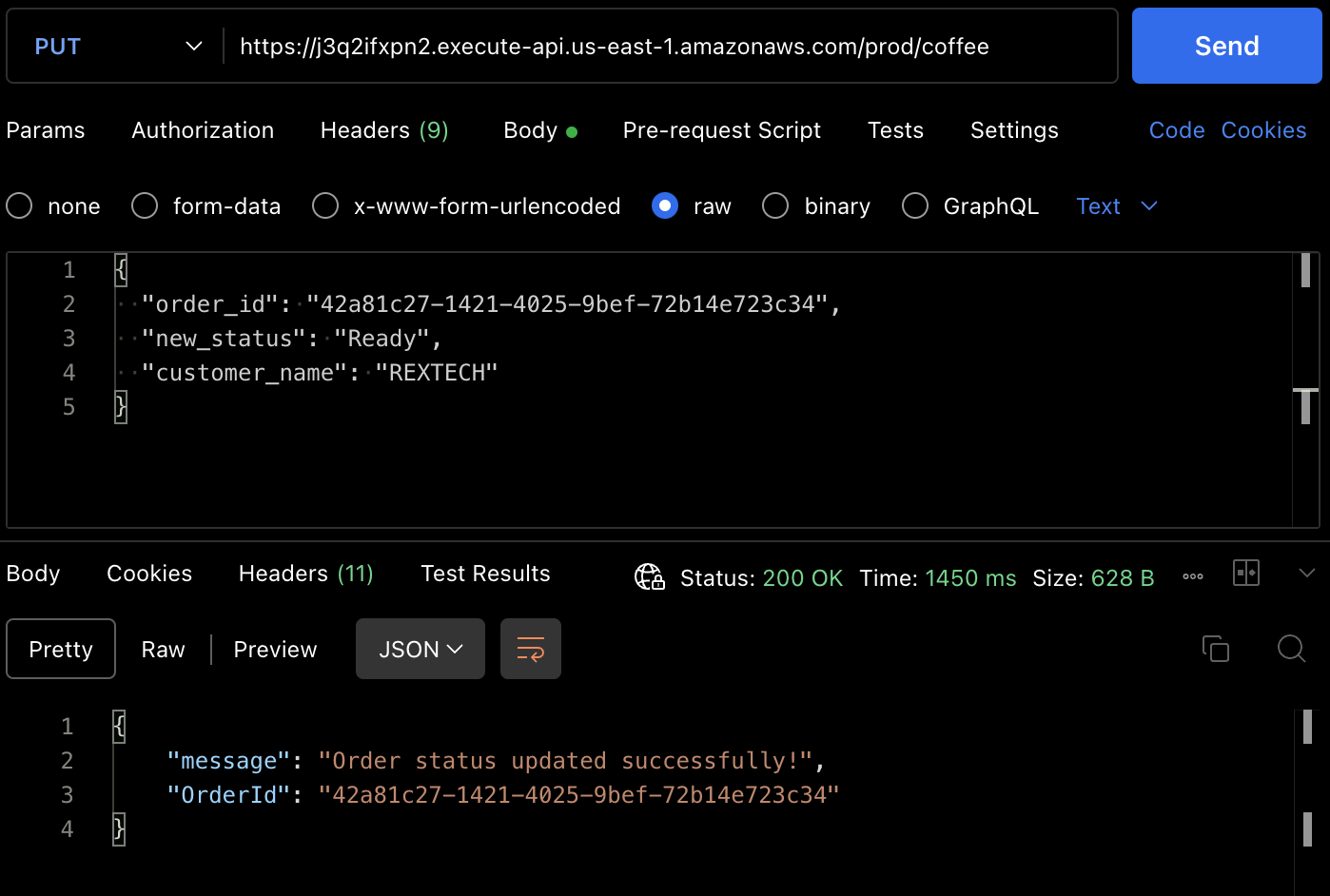
您还可以从DynamoDB表项中验证订单状态是否已更新。

为了测试DELETE方法,使用Postman发起DELETE请求,并在请求正文中提供先前的订单ID和客户姓名,如下所示:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
订单已成功删除,删除的订单号为所下的订单号。
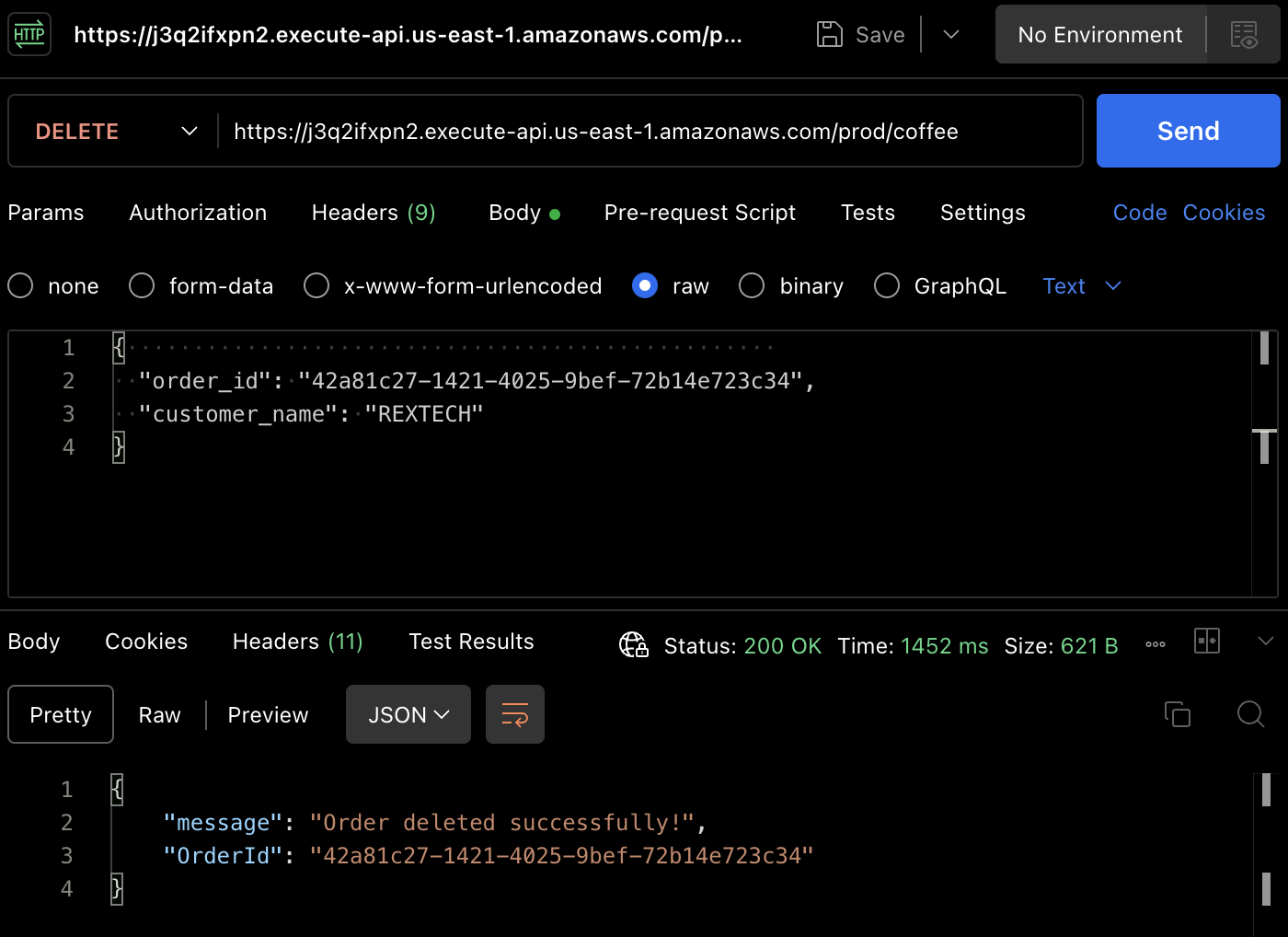
再次,您可以在DynamoDB表中验证订单是否已删除。

结论
就是这样——祝贺您!您已成功完成所有步骤。我们使用API网关、Lambda、DynamoDB、Serverless Framework和Node.js构建了一个支持CRUD(创建、读取、更新、删除)功能的无服务器REST API,并通过Github Actions自动化部署经批准的代码更改。
如果您读到这里,感谢您的阅读!我希望这对您有所帮助。
伊费尼亚·奥图恩叶是一名6次获得AWS认证的云工程师,擅长DevOps、技术写作和在技术讲师职位上的教学专业知识。他渴望学习和开发,并在协作环境中蓬勃发展。在转向云计算之前,他作为一名职业田径运动员度过了六年。
在2022年初,他策略性地开始了一个通过自学和加入一个为期六个月的加速云计算项目成为云/DevOps工程师的任务。
2023年5月,他实现了这个目标,并获得了他的第一个云工程职位,现在他已设定另一个个人任务,帮助其他人在云计算之旅上获得力量。
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/