













Il calcolo serverless è emergeuto come risposta ai challenge delle architetture server-based tradizionali. Con il serverless, i programmatori non devono più gestire o scalare manualmente i server. Invece, i fornitori cloud si occupano della gestione dell’infrastruttura, permettendo alle squadre di concentrarsi esclusivamente sull’ scrittura e sulla distribuzione del codice.
Le soluzioni serverless si scalano automaticamente in base alla domanda e offrono un modello a pagamento per uso. Questo significa che paghi solo per le risorse utilizzate dall’applicazione reale. Questo approcio riduce significativamente gli overhead operazionali, aumenta la flessibilità e accelera i cicli di sviluppo, rendendolo una opzione attrattiva per lo sviluppo di applicazioni moderne.
Rimuovendo la gestione del server, le piattaforme serverless ti consentono di concentrarti sulla logica aziendale e sulla funzionalità dell’applicazione. Questo porta a deploy veloci e a maggiore innovazione. Le architetture serverless sono anche event-driven, che significa che possono rispondere automaticamente agli eventi in tempo reale e scalare per soddisfare le richieste utente senza intervento manuale.
Indice
Prima di immergersi nei dettagli tecnici, passerò su alcuni concetti di base.
Concezioni importanti da comprendere
Interfaccia di programmazione dell’applicazione (API)
Un’interfaccia di programmazione dell’applicazione (API) consente a differenti applicazioni software di comunicare e interagire tra loro. Definisce i metodi e i formati dati che le applicazioni possono utilizzare per richiedere e scambiare informazioni per l’integrazione e lo scambio dati tra sistemi diversi.
Metodi HTTP
I metodi HTTP o metodi di richiesta sono un componente chiave dei web service e delle API. Indicano l’azione desiderata da eseguire sul risorsa in una data URL di richiesta.
I metodi più comunemente utilizzati in API RESTful sono:
-
GET: utilizzato per recuperare dati da un server
-
POST: invia dati, inclusi nel corpo della richiesta, per creare o aggiornare una risorsa
-
PUT: aggiorna o sostituisce una risorsa esistente o crea una nuova risorsa se non esiste
-
DELETE: elimina i dati specificati dal server.
Amazon API Gateway
Amazon API Gateway è un servizio completamente gestito che rende facile per i sviluppatori creare, pubblicare, mantenere, monitorare e proteggere API a scala. Funge da punto di entrata per molte API, gestendo e controllando le interazioni tra clienti (come applicazioni web o mobile) e servizi backend.
Fornisce inoltre varie funzioni, tra cui la routing richieste, la sicurezza, l’autenticazione, il caching e la limitazione della velocità che aiutano a semplificare la gestione e la distribuzione delle API.
Amazon DynamoDB
DynamoDB è un servizio di database NoSQL completamente gestito progettato per scalabilità elevata, latenza bassa e replica dei dati in più regioni.
DynamoDB memorizza i dati in un formato schema-less, permettendo una memorizzazione e recupero flessibili e veloci di dati strutturati e semi-strutturati. È comunemente usato per la costruzione di applicazioni scalabili e responsive in ambienti basati sul cloud.
Applicazione CRUD serverless
Un’applicazione CRUD serverless si riferisce alla capacità di Creare, Leggere, Aggiornare e Eliminare dati. Ma l’architettura e i componenti coinvolti differiscono da quelli delle applicazioni tradizionali basate su server.
Creare implica l’aggiunta di nuovi elementi a una tabella DynamoDB. L’operazione Leggere recupera i dati da una tabella DynamoDB. Aggiornare aggiorna i dati esistenti in DynamoDB. E l’operazione Eliminare elimina i dati da DynamoDB.
Il Serverless Framework
Il Serverless Framework è uno strumento open-source che semplifica la distribuzione e la gestione di applicazioni serverless su diversi fornitori cloud, incluso AWS. Permette di astrarre la complessità della provvisionazione e della gestione dell’infrastruttura consentendo ai sviluppatori di definire le loro infrastrutture come codice usando un file YAML.
Il framework gestisce la distribuzione, la scalabilità e l’aggiornamento di funzioni serverless, API e altri risorse.
GitHub Actions
GitHub Actions è un potente strumento di automazione CI/CD che permette agli sviluppatori di automatizzare i loro flussi di lavoro software direttamente dal loro repository GitHub.
Con GitHub Actions, è possibile creare pipeline personalizzati attivati da eventi come il push di codice, richieste di pull o il merge di branch. Questi flussi di lavoro sono definiti in file YAML all’interno del repository e possono eseguire compiti come testare, compilare e distribuire applicazioni in varie ambientazioni.
Postman
Postman è una popolare piattaforma di collaborazione che semplifica il processo di progettazione, testing e documentazione di API. Offre un’interfaccia utente amichevole per i sviluppatori per creare e inviare richieste HTTP, testare gli endpoint API e automatizzare i flussi di test.
Ok, ora che sei familiarizzato con gli strumenti e tecnologie che userai qui, ci immersiamo.
Prerequisiti
-
Node.js e npm installati
-
AWS CLI configurato con accesso al tuo account AWS
-
Un account Serverlesss Framework
-
Serverlesss Framework installato globalmente nella tua CLI locale
Nostro Use Case
Conosci Alyx, un’imprenditrice che di recente ha iniziato a studiare l’architettura serverless. Ha letto molto sulla sua potenza e efficienza nell’costruzione di backend per applicazioni web, offrendo un approcio moderno alla developmen- to delle applicazioni web.
Ha deciso di applicare ciò che ha imparato finora riguardo ai fondamenti dell’architettura serverless AWS. Sa che serverless non significa che non ci sono server coinvolti – piuttosto, semplicemente nasconde la gestione e la provvisional- ienza dei server. E ora vuole concentrarsi solamente sulla scrittura del codice e sull’implementazione della logica aziendale.
Scopriamo come Alyx, la proprietaria di un fiorente negozio di caffè, comincia a sfruttare l’architettura serverless per il backend della sua applicazione web.
Il Nido del Caffè di Alyx, un negozio online di caffè, offre una gamma di miscelazioni di caffè e dolci per la vendita. Inizialmente, Alyx gestiva i ordini e l’inventario del negozio con servizi di hosting web tradizionali e operazioni, in cui si occupava di molti server e risorse. Ma con il crescere della popolarità del suo negozio di caffè, iniziò a ricevere un numero sempre maggiore di ordini, specialmente durante le ore di punta e le promozioni stagionali.
Gestire i server e assicurarsi che l’applicazione potesse gestire il traffico in aumento divenne una sfida per Alyx.si trovava costantemente preoccupata per la capacità del server, la scalabilità e il costo della manutenzione dell’infrastruttura.
Lei anche voleva introdurre nuove funzionalità come raccomandazioni personalizzate e programmi fedeli, ma questo diventò una sfida impegnativa a causa delle limitazioni del suo setup tradizionale.
Poi Alyx ha appreso del concetto di backend serverless. Ha paragonato un backend serverless ad un barista che automaticamente preparerà il caffè in tempo reale, senza che lei debba preoccuparsi dei dettagli intrighiuti del processo di preparazione del caffè.
Incantata da questa idea, Alyx ha deciso di migrare il backend del suo negozio di caffè su una piattaforma serverless utilizzando AWS Lambda, AWS API Gateway e Amazon DynamoDB. Questa configurazione le permetterà di focalizzarsi più sulla creazione di perfette miscelazioni e dolci per i suoi clienti.
Con il serverless, ogni ordine del cliente diventa un evento che attiva una serie di funzioni serverless. Separate funzioni AWS Lambda processano gli ordini e gestiscono tutta la logica aziendale dietro le quinte. Per esempio, creano un ordine del cliente e sono in grado di recuperare quell’ordine. Possono anche eliminare un ordine o aggiornare lo stato di un ordine.
Alyx non deve più preoccuparsi della gestione dei server, poiché la piattaforma serverless si scalerà automaticamente in base alle richieste di ordini in ingresso. Anche l’efficienza costosa del serverless è immensa per Alyx. Con un modello a pagamento per uso, pagha solo per il tempo di calcolo reale consumato dalle sue funzioni, offrendole una soluzione più economica per il suo business in crescita.
Ma non si ferma qui! Vuole anche automatizzare tutto, dalla distribuzione dell’infrastruttura all’aggiornamento dell’applicazione ogni volta che c’è una nuova modifica. Utilizzando Infrastructure as Code (IaC) con il Serverless Framework, può definire tutta la sua infrastruttura nel codice e gestirla facilmente.
Inoltre, configura le azioni GitHub per l’integrazione e la distribuzione continua (CI/CD), in modo che ogni modifica apportata venga distribuita automaticamente attraverso una pipeline, sia che si tratti di una nuova funzionalità in fase di sviluppo o di una correzione a caldo per la produzione.
Obiettivi del tutorial
-
Impostare l’ambiente Serverless Framework
-
Definire un’API nel file YAML
-
Sviluppare funzioni AWS Lambda per elaborare operazioni CRUD
-
Impostare deployment multi-stage per Dev e Prod
-
Testare le pipeline Dev e Prod
-
Testare e validare le API Dev e Prod usando Postman
Come iniziare: Clonare il repository Git
Per poter seguire questo tutorial in modo efficace, fate clonare il repository del progetto da mio GitHub. Potete farlo andando qui. Mentre procederemo, fate自由に modificare i file se vi sembrano necessarie.
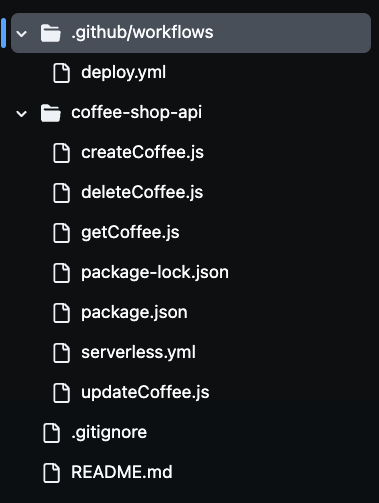
Dopo aver clonato il repository, notererete la presenza di molti file nella vostra cartella, come vedete nell’immagine qui sotto. Utilizzeremo tutti questi file per costruire la nostra API serverless del caffè.
Step 1: Impostare l’ambiente Serverless Framework
Per impostare l’ambiente Serverless Framework per le distribuzioni automatizzate, dovete autenticare il vostro account Serverless via CLI.
Questo richiede la creazione di una chiave d’accesso che abilita il pipeline CI/CD e utilizza il Serverless Framework per autenticarsi in sicurezza nel vostro account senza esporre le vostre credenziali. Signinando nel vostro account Serverless e generando una chiave d’accesso, il pipeline può distribuire automaticamente il vostro applicazione serverless dalla configurazione di build.
Per fare questo, vai al vostro account Serverless e navigare alla sezione Chiavi d’accesso. Cliccate su “+aggiungi”, chiamatela SERVERLESS_ACCESS_KEY, quindi create la chiave.
Una volta creata la vostra chiave d’accesso, fate in modo di copiarla e conservarla in sicurezza. Utilizzerete questa chiave come variabile segreta nel vostro repository GitHub per autenticare e autorizzare il vostro pipeline CI/CD.
Fornerà l’accesso al tuo account Serverless Framework durante il processo di distribuzione. Inserirai questa chiave nel repository segreto di GitHub in un secondo momento, così che il tuo pipeline possa utilizzarla in sicurezza per distribuire le risorse serverless senza esporre informazioni sensibili nel tuo codebase.
Ora, definiamo le risorse AWS come codice nel file severless.yaml.
Step 2: Definisci l’API nel file Serverless YAML
In questo file, definirai l’infrastruttura e la funzionalità principale dell’API del Caffè Shop utilizzando la configurazione YAML del Serverless Framework.
Questo file definisce i servizi AWS in uso, incluso API Gateway, funzioni Lambda per operazioni CRUD e DynamoDB per il salvataggio dei dati.
Anche qui configurerai un ruolo IAM così che le funzioni Lambda abbiano i permessi necessari per interagire con il servizio DynamoDB.
L’API Gateway è impostato con metodi HTTP appropriati (POST, GET, PUT, e DELETE) per gestire le richieste in entrata e attivare le funzioni Lambda corrispondenti.
Vediamo il codice:
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
La configurazione serverless.yml definisce come l’API del Caffè Shop di Alyx sarà gestita in un ambiente serverless su AWS. La sezione provider specifica che l’applicazione userà AWS come provider cloud, con Node.js come ambiente di runtime.
La regione è impostata su us-east-1 e la variabile stage consente la distribuzione dinamica in ambienti differenti, come dev e prod. Ciò significa che lo stesso codice può essere distribuito in ambienti diversi, con risorse che assumono nomi corrispondenti per evitare conflitti.
Nella sezione iam, sono concessi permessi alle funzioni Lambda per interagire con la tabella DynamoDB. La sintassi ${self:provider.stage} dà un nome dinamico alla tabella DynamoDB, in modo che ogni ambiente abbia le sue risorse separate, come CoffeeOrders-dev per l’ambiente di sviluppo e CoffeeOrders-prod per la produzione. Questo nome dinamico aiuta a gestire multipli ambienti senza configurare manualmente separate tabelle per ognuno.
La sezione functions definisce le quattro funzioni Lambda principali, createCoffee, getCoffee, updateCoffee e deleteCoffee. Queste si occupano delle operazioni CRUD dell’API del negozio del caffè.
Ogni funzione è collegata a un metodo HTTP specifico dell’API Gateway, come POST, GET, PUT e DELETE. queste funzioni interagiscono con la tabella DynamoDB che è denominata dinamicamente in base all’attuale stage.
L’ultima sezione resources definisce la tabella DynamoDB stessa. Si impostano la tabella con gli attributi OrderId e CustomerName, che sono usati come chiave primaria. La tabella è configurata per usare un sistema di fatturazione a richiesta, rendendola efficiente per il business in crescita di Alyx.
Automatizzando la distribuzione di questi risorse utilizzando il Serverless Framework, Alyx può gestire facilmente la sua infrastruttura, liberandosi dalla necessità di provvedere manualmente e scalare risorse.
Step 3: Sviluppare le Funzioni Lambda per le Operazioni CRUD
In questo step, implementiamo la logica di base dell’API del Negozio di Caffè di Alyx creando funzioni Lambda con JavaScript che eseguono le operazioni CRUD essenziali createCoffee, getCoffee, updateCoffee e deleteCoffee.
these functions use the AWS SDK to interact with AWS services, especially DynamoDB. Each function will be responsible for handling specific API requests, such as creating an order, retrieving orders, updating order statuses, and deleting orders.
Create Coffee Lambda function
This function creates an order:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order created successfully!', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not create order: ${error.message}` })
};
}
};
This Lambda function handles the creation of a new coffee order in the DynamoDB table. First we import the AWS SDK and initialize a DynamoDB.DocumentClient to interact with DynamoDB. The uuid library is also imported to generate unique order IDs.
Inside the handler function, we parse the incoming request body to extract customer information, such as the customer’s name and preferred coffee blend. A unique orderId is generated using uuidv4() and this data is prepared for insertion into DynamoDB.
L’oggetto params definisce la tabella in cui verranno memorizzati i dati, con TableName impostato dinamicamente sul valore dell’variabile di ambiente COFFEE_ORDERS_TABLE. Il nuovo ordine include campi come OrderId, CustomerName, CoffeeBlend, e un stato iniziale di Pending.
Nel blocco try, il codice tenta di aggiungere l’ordine alla tabella DynamoDB utilizzando il metodo put(). Se la operazione è riuscita, la funzione restituisce un codice di stato di 200 con un messaggio di successo e l’OrderId. In caso di errore, il codice lo cattura e restituisce un codice di stato di 500 insieme a un messaggio di errore.
Get Coffee Lambda function
Questa funzione recupera tutti gli articoli del caffè:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not retrieve orders: ${error.message}` })
};
}
};
Questa funzione Lambda è responsabile del recupero di tutti gli ordini di caffè da una tabella DynamoDB ed illustra un approcio serverless per il recupero di dati da DynamoDB in un modo scalabile.
Ancora una volta, usiamo l’SDK AWS per inizializzare un’istanza di DynamoDB.DocumentClient per interagire con DynamoDB. La funzione handler costruisce l’oggetto params, specificando il TableName, che è impostato dinamicamente utilizzando l’variabile di ambiente COFFEE_ORDERS_TABLE.
La scan() metodo recupera tutti gli elementi dalla tabella. Di nuovo, se l’operazione è riuscita, la funzione restituisce un codice di stato di 200 insieme agli elementi recuperati in formato JSON. In caso di errore, viene restituito un codice di stato 500 e un messaggio di errore.
Aggiorna la funzione Coffee Lambda
Questa funzione aggiorna un elemento del caffè tramite il suo ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order status updated successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not update order: ${error.message}` })
};
}
};
Questa funzione Lambda gestisce l’aggiornamento dello stato di un ordine di caffè specifico nella tabella DynamoDB.
La funzione handler estrae order_id, new_status, e customer_name dal body della richiesta. Poi costruisce l’oggetto params per specificare il nome della tabella e la chiave primaria per l’ordine (utilizzando OrderId e CustomerName). L’UpdateExpression imposta lo nuovo stato dell’ordine.
Nel blocco try, il codice tenta di aggiornare l’ordine in DynamoDB utilizzando il metodo update(). Di nuovo, se riuscito, la funzione restituisce un codice di stato di 200 con un messaggio di successo. Se si verifica un errore, si cattura l’errore e viene restituito un codice di stato 500 insieme a un messaggio di errore.
Elimina la funzione Coffee Lambda
Questa funzione elimina un elemento del caffè tramite il suo ID:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Order deleted successfully!', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Could not delete order: ${error.message}` })
};
}
};
La funzione Lambda elimina un ordine di caffè specifico dalla tabella DynamoDB. Nella funzione di gestione, il codice analizza il corpo della richiesta per estrarre il order_id e il customer_name. Questi valori vengono utilizzati come chiave primaria per identificare l’elemento da eliminare dalla tabella. L’oggetto params specifica il nome della tabella e la chiave per l’elemento da eliminare.
Nel blocco try, il codice tenta di eliminare l’ordine da DynamoDB utilizzando il metodo delete(). Se riuscito, restituisce di nuovo un codice di stato 200 con un messaggio di successo, indicando che l’ordine è stato eliminato. Se si verifica un errore, il codice lo cattura e restituisce un codice di stato 500 insieme a un messaggio di errore.
Ora che abbiamo spiegato ogni funzione Lambda, andiamo a configurare una pipeline CI/CD multi-stagio.
Step 4: Impostare pipeline CI/CD multi-stagio per ambienti di sviluppo e produzione
Per impostare le risorse segrete di AWS nel tuo repository GitHub, prima naviga alle impostazioni del repository. Seleziona Settings in alto a destra, poi vai in basso a sinistra e seleziona Secrets and variables.

Successivamente, clicca su Actions come visto nell’immagine seguente:
Da li, seleziona New repository secret per creare i segreti.
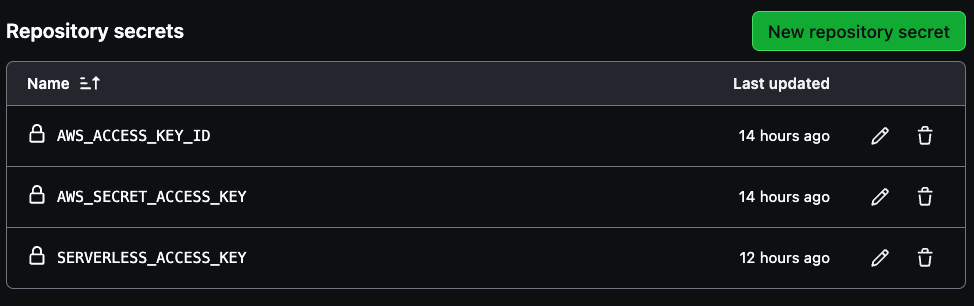
Sono necessari tre segreti per creare la tua pipeline, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, e SERVERLESS_ACCESS_KEY.
Utilizza le credenziali dell’accesso della tua account AWS per le prime due variabili e poi il serverless access key precedentemente salvato per creare la SERVERLESS_ACCESS_KEY. Questi segreti autenticheranno sicuramente il tuo CI/CD pipeline come illustrato nell’immagine sottostante.
Assicurati che la tua branch principale sia chiamata “main,” in quanto questa servirà come branch di produzione. Successivamente, crea una nuova branch chiamata “dev” per il lavoro di sviluppo.
Puoi anche creare branch specifici per funzionalità, come “dev/feature,” per un sviluppo più granulare. GitHub Actions userà queste branch per distribuire automaticamente i cambiamenti, con dev che rappresenta l’ambiente di sviluppo e main che rappresenta la produzione.
Questa strategia di branching consente di gestire il pipeline CI/CD in maniera efficiente, distribuendo nuovi cambiamenti nel codice ogni volta che viene effettuato un merge in entrambe le environment dev o prod.
Come usare GitHub Actions per distribuire il file YAML
Per automatizzare il processo di distribuzione per l’API del Coffee Shop, userai GitHub Actions, che integra il tuo repository GitHub.
Questo pipeline di distribuzione viene attivato ogni volta che il codice viene spinto sulle branch main o dev. Configurando le distribuzioni specifiche per l’ambiente, ti assiculerai che aggiornamenti alla branch dev vengano distribuiti nell’environment di sviluppo, mentre i cambiamenti alla branch main triggeranno le distribuzioni in produzione.
Adesso, rivediamo il codice:
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
La configurazione YAML di GitHub Actions è ciò che automatizza il processo di deploy dell’API del Coffee Shop su AWS utilizzando il Serverless Framework. Il workflow viene attivato ogni volta che vengono pushate modifiche alle branch principale o dev.
Inizia facendo il checkout del codice del repository, quindi imposta Node.js con la versione 20.x per corrispondere alla versione di runtime usata dalle funzioni Lambda. Dopo aver installato le dipendenze del progetto navigando nella directory coffee-shop-api e eseguendo npm install.
Il workflow installa anche il Serverless Framework globalmente, permettendo l’uso della CLI serverless per i deploy. A seconda di quale branch viene aggiornata, il workflow deploya condizionalmente nell’ambiente corretto.
Se le modifiche vengono pushate sulla branch dev, viene deployato nella fase dev. Se vengono pushate sulla branch principale, viene deployato nella fase prod. I comandi di deploy, npx serverless deploy --stage dev o npx serverless deploy --stage prod vengono eseguiti all’interno della directory coffee-shop-api.
Per un deploy sicuro, il workflow accede alle credenziali AWS e alla chiave di accesso Serverless tramite variabili d’ambiente memorizzate negli Secrets di GitHub. Questo permette al CI/CD pipeline di autenticarsi con AWS e il Serverless Framework senza esporre informazioni sensibili nel repository.
Ora, possiamo procedere a testare il pipeline.
Step 5: Test the Dev and Prod Pipelines
Prima di tutto, dovrai verificare che la branch principale (prod) sia chiamata “main”. Poi crea una branch dev chiamata “dev”. Una volta apportati eventuali cambiamenti validi nella branch dev, committali per attivare il pipeline GitHub Actions. Questo attiverà automaticamente la distribuzione delle risorse aggiornate all’ambiente di sviluppo. Dopo aver verificato tutto nell’ambiente di sviluppo, puoi poi unire la branch dev alla branch principale.
Unire le modifiche nella branch principale attiva anche automaticamente il pipeline di distribuzione per l’ambiente di produzione. In questo modo, tutte le aggiornazioni necessarie sono applicate e le risorse di produzione vengono distribuite in modo fluido.
Puoi monitorare il processo di distribuzione e rivedere i log dettagliati di ciascuna esecuzione di GitHub Actions navigando alla scheda Actions nel tuo repository GitHub.
I log forniscono una visione d’insieme di ciascuno step del pipeline, aiutandoti a verificare che tutto funzioni come previsto.
Puoi selezionare qualsiasi esecuzione di compilazione per rivedere i log dettagliati sia per la distribuzione nell’ambiente di sviluppo che per quella di produzione, così da tenere traccia del progresso e assicurarti che tutto vada a buon fine.
Naviga fino all’esecuzione specifica del build nel pipeline GitHub Actions, come mostrato nell’immagine sottostante. Lì puoi visualizzare i dettagli di esecuzione e i risultati per entrambe le pipeline di sviluppo e produzione.

Assicurati di testare attivamente sia l’ambiente di sviluppo che quello di produzione per confermare l’esecuzione corretta del pipeline.
Step 6: Testare e validare le API di Prod e Dev usando Postman
Ora che le API e le risorse sono state deployate e configurate, dobbiamo trovare gli endpoint API univoci (URL) generati da AWS per iniziare a fare richieste per testare la funzionalità.
Questi URL possono testare la funzionalità dell’API semplicemente facendo clic su di essi in un browser web. Gli URL API sono presenti negli output dei risultati del tuo processo di CI/CD.
Per recuperarli, naviga nei log di GitHub Actions, seleziona il build più recente dell’ambiente corretto, e fai clic sul pulsante deploy per controllare i dettagli del deploy degli endpoint API generati.
Fai clic sulla fase Deploy to AWS per l’ambiente selezionato (Prod o Dev) nei log di GitHub Actions. Una volta lì, troverai l’URL API generato.
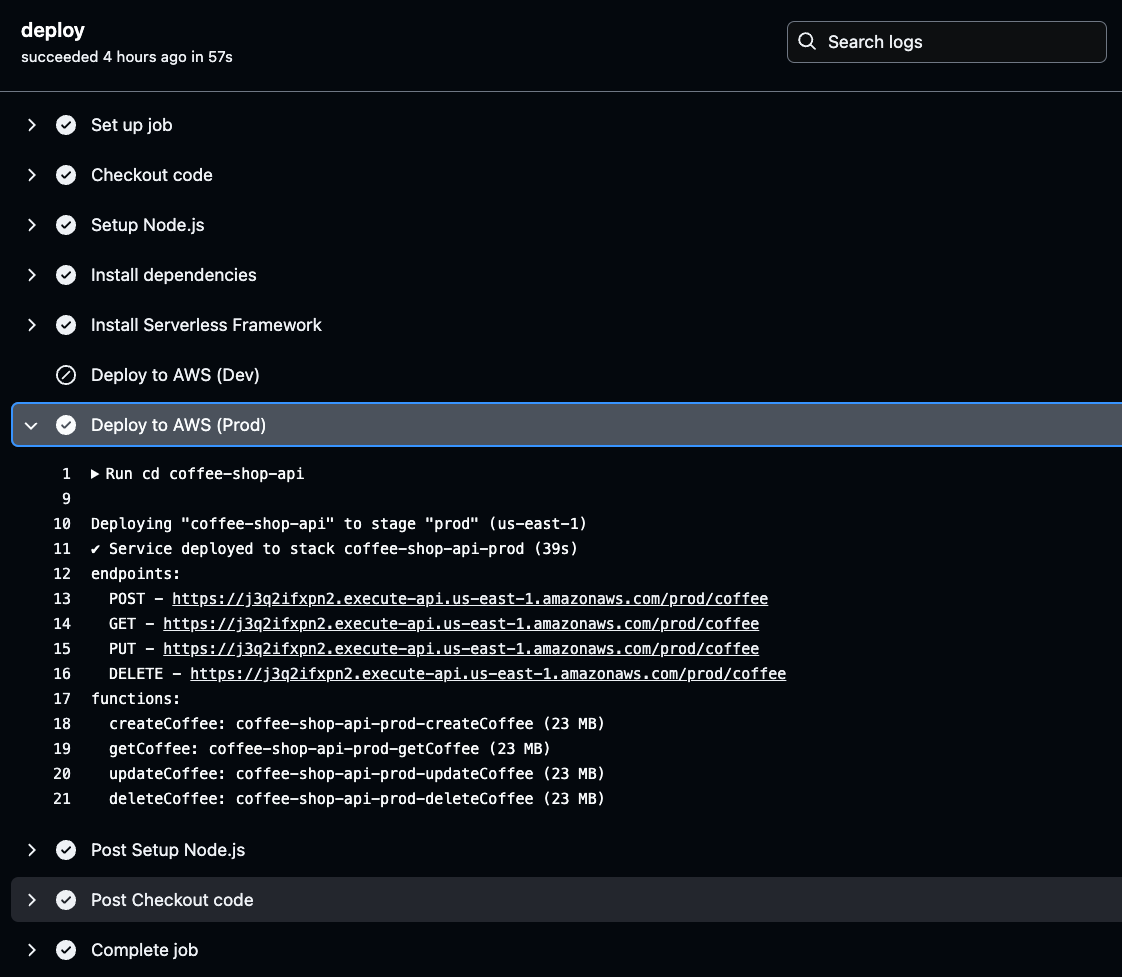
Copia e salva questo URL, poiché sarà necessario durante il test della funzionalità dell’API. Questo URL è il tuo gateway per verificare che l’API deployata funzioni come atteso.
Ora fai una copia di uno degli URL API generati e incolla il testo nel tuo browser. Vedrai che viene visualizzato un array vuoto o una lista nell’risposta. Questo conferma che l’API sta funzionando correttamente e che stai recuperando dati dalla tabella DynamoDB.
Anche se la lista è vuota, indica che l’API è in grado di connettersi al database e restituire informazioni.
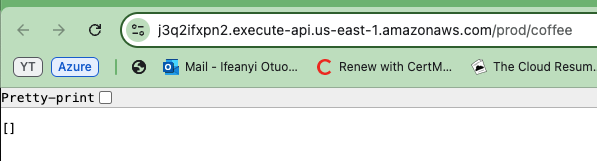
Per verificare che la tua API funziona in entrambi gli ambienti, ripeti i passaggi per l’altro ambiente API (Prod e Dev).
Per test più completi, utilizzeremo Postman per testare tutti i metodi API, Crea, Leggi, Aggiorna e Elimina, e svolgeremo questi test sia per gli ambienti di sviluppo che di produzione.
Per testare il metodo GET, utilizza Postman per inviare una richiesta GET all’endpoint dell’API utilizzando l’URL. Riceverai la stessa risposta, un elenco vuoto di ordini di caffè come mostrato in basso nell’immagine sottostante. Questo conferma la capacità dell’API di recuperare dati con successo, come mostrato nell’immagine sottostante.

Per creare effettivamente un ordine, testiamo il metodo POST. Utilizza nuovamente Postman per fare una richiesta POST all’endpoint dell’API, fornendo il nome del cliente e la miscela di caffè nel corpo della richiesta, come mostrato sotto:
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
La risposta sarà un messaggio di successo con un OrderId unico per l’ordine effettuato.
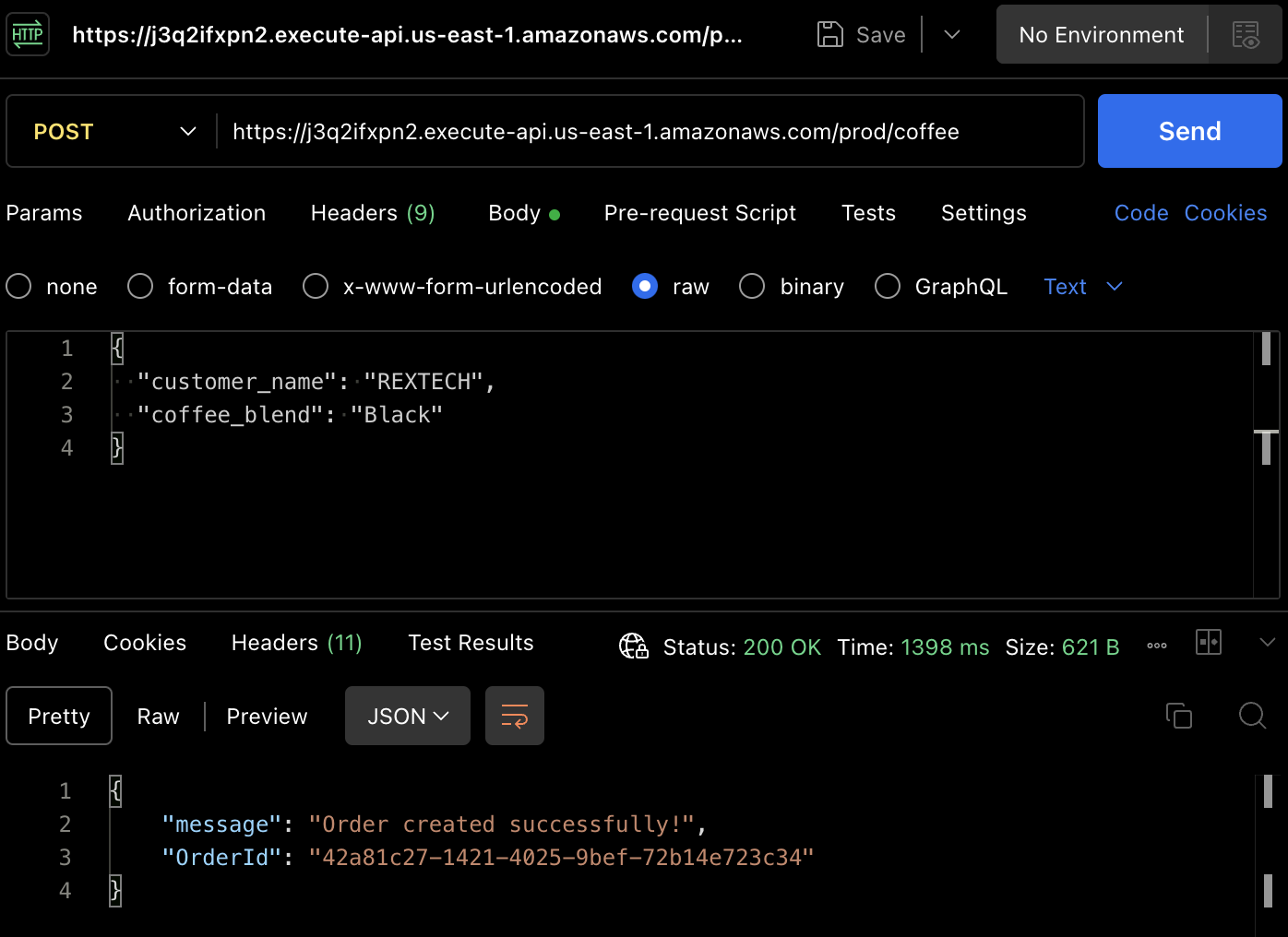
Verifica che il nuovo ordine sia stato salvato nella tabella DynamoDB esaminando gli elementi nella tabella specifica dell’ambiente:

Per testare il metodo PUT, fai una richiesta PUT all’endpoint dell’API fornendo l’ID dell’ordine precedente e un nuovo stato dell’ordine nel corpo della richiesta come mostrato sotto:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
La risposta sarà un messaggio di aggiornamento ordine riuscito con l’OrderId dell’ordine effettuato.
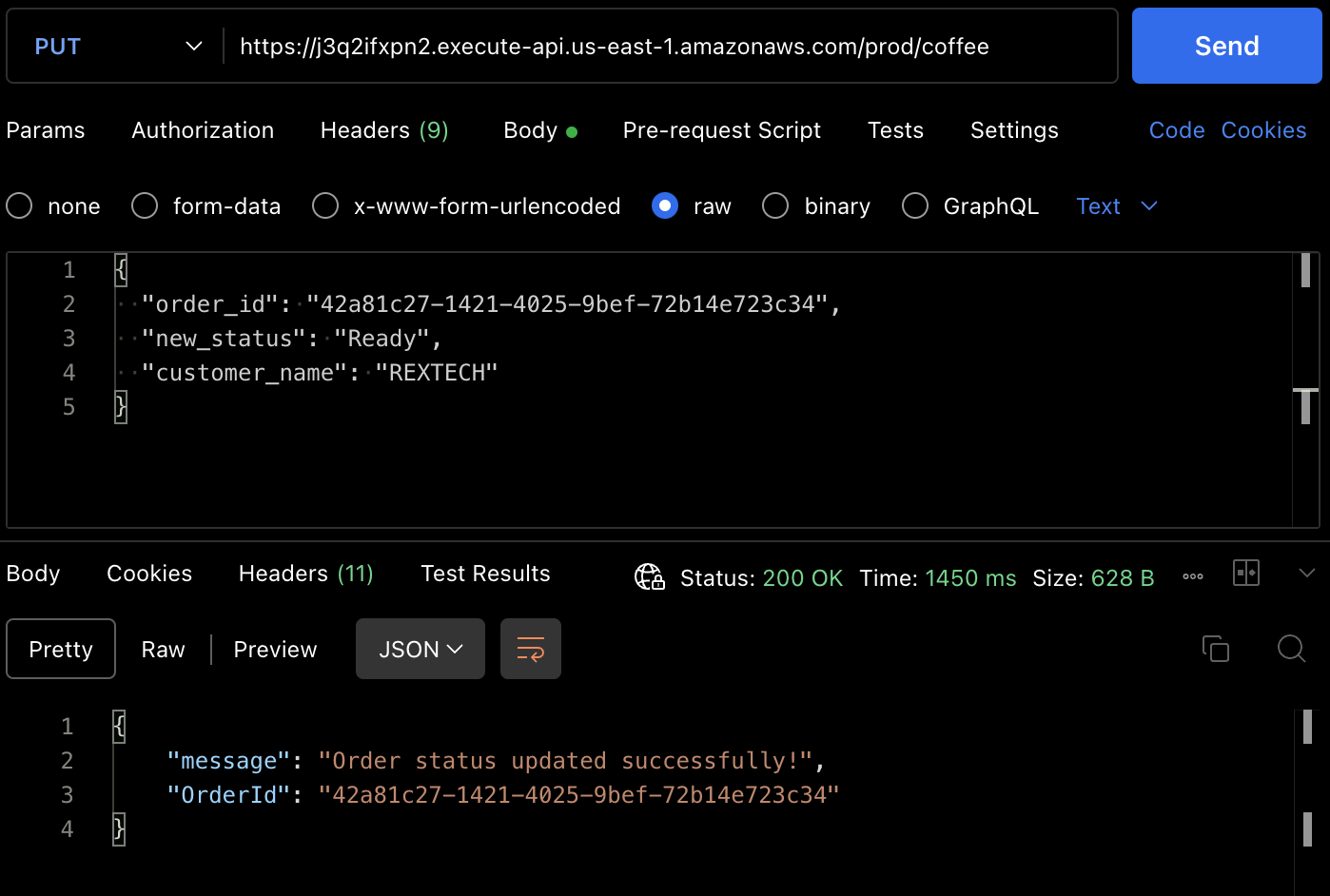
Puoi anche verificare che lo stato dell’ordine sia stato aggiornato dall’elemento della tabella DynamoDB.

Per testare il metodo DELETE, utilizzando Postman, fai una richiesta DELETE fornendo l’ID dell’ordine precedente e il nome del cliente nel corpo della richiesta come mostrato sotto:
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
L’ordine è stato cancellato con successo e la risposta sarà un messaggio che contiene l’ID dell’ordine.
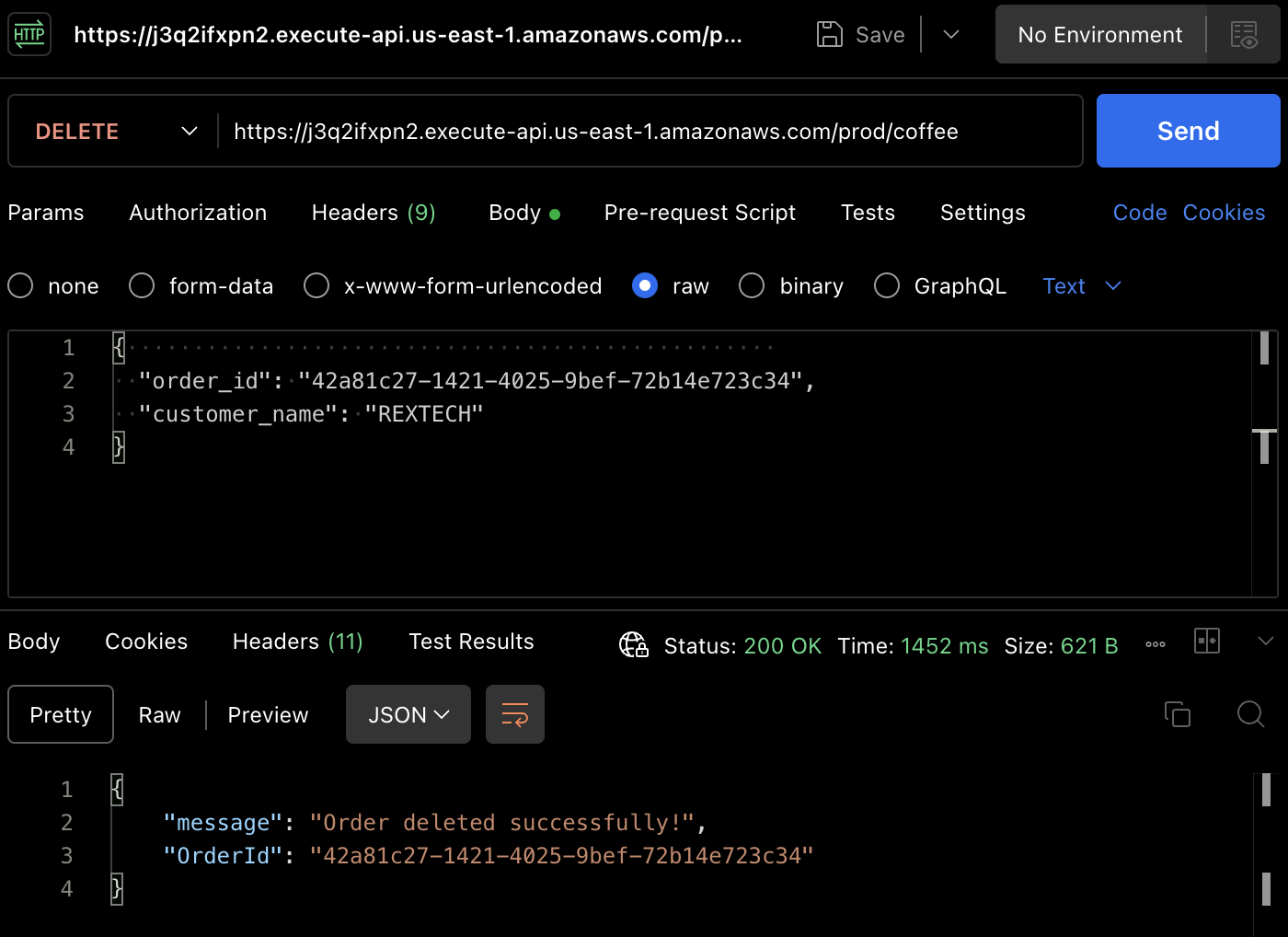
Di nuovo, puoi verificare che l’ordine è stato cancellato nella tabella DynamoDB.

Conclusione
Ecco questo – congratulazioni! Hai completato con successo tutti i passaggi. Abbiamo creato un API REST serverless che supporta le funzionalità CRUD (Create, Read, Update, Delete) con API Gateway, Lambda, DynamoDB, Serverless Framework e Node.js, automatizzando la distribuzione dei cambiamenti di codice approvati tramite Github Actions.
Se sei arrivato a questo punto, grazie per aver letto! Spero sia stato utile a te.
Ifeanyi Otuonye è un cloud engineer AWS certificato 6X esperto in DevOps, scrittura tecnica e competenza didattica come insegnante tecnico. È motivato dalla sua ansia di apprendimento e sviluppo e prospera in ambienti collaborativi. Prima della transizione al Cloud, ha passato sei anni come atleta professionista di atletica leggera.
All’inizio del 2022, ha avviato strategicamente un missione per diventare un Cloud/DevOps Engineer tramite autodidattismo e partecipando a un programma accelerato di Cloud di 6 mesi.
Il 13 maggio 2023, ha raggiunto quell’obiettivo e ha ottenuto il suo primo ruolo di ingegnere Cloud e ora ha impostato un’altra missione personale per empowerre altri individui sulla loro strada verso il Cloud.
Source:
https://www.freecodecamp.org/news/how-to-build-a-serverless-crud-rest-api/