













Давайте обсудим важный вопрос: как мы можем мониторить наши сервисы, если что-то пойдет не так?
С одной стороны, у нас есть Prometheus с оповещениями и Kibana для панелей и других полезных функций. Мы также знаем, как собирать логи — стек ELK – наше стандартное решение. Однако простое логирование не всегда достаточно: оно не предоставляет всестороннего взгляда на путь запроса по всей экосистеме компонентов.
Больше информации о ELK вы можете найти здесь.
Но что, если мы хотим визуализировать запросы? Что, если нам нужно коррелировать запросы, передвигающиеся между системами? Это относится как к микросервисам, так и к монолитам — не важно, сколько у нас сервисов; важно, как мы управляем их задержкой.
Действительно, каждый пользовательский запрос может проходить через целую цепочку независимых сервисов, баз данных, очередей сообщений и внешних API.
В такой сложной среде становится чрезвычайно сложно точно определить, где возникают задержки, выявить, какая часть цепи действует как узкое место производительности, и быстро найти причину сбоев, когда они происходят.
Для эффективного решения этих задач нам необходима централизованная, последовательная система для сбора телеметрических данных — трассировок, метрик и логов. Именно здесь нам на помощь приходят OpenTelemetry и Jaeger.
Давайте рассмотрим основные понятия
Существуют два основных термина, которые нам необходимо понять:
Идентификатор трассировки
Идентификатор трассировки – это 16-байтовый идентификатор, часто представленный в виде 32-символьной шестнадцатеричной строки. Он автоматически генерируется в начале трассировки и остается неизменным для всех спанов, созданных в рамках конкретного запроса. Это упрощает отслеживание пути запроса через различные службы или компоненты в системе.
Идентификатор спана
Каждая отдельная операция в рамках трассировки получает свой собственный идентификатор спана, который обычно является случайно сгенерированным 64-битным значением. Спаны имеют общий идентификатор трассировки, но каждый из них имеет уникальный идентификатор спана, поэтому вы можете точно определить, какая часть рабочего процесса представлена каждым спаном (например, запрос к базе данных или вызов другой микрослужбы).
Как они связаны между собой?
Идентификатор трассировки и Идентификатор спана дополняют друг друга.
Когда запрос инициируется, генерируется и передается идентификатор трассировки всем участвующим службам. Каждая служба ihreredze собственный спан с уникальным идентификатором спана, связанным с идентификатором трассировки, что позволяет визуализировать полный жизненный цикл запроса от начала до конца.
Хорошо, а почему бы просто не использовать Jaeger? Зачем нам нужен OpenTelemetry (OTEL) и все его спецификации? Отличный вопрос! Давайте разберем его пошагово.
Узнайте больше о Jaeger здесь.
Кратко
- Jaeger – это система для хранения и визуализации распределенных трассировок. Она собирает, хранит, ищет и отображает данные, показывающие, как запросы “путешествуют” через ваши службы.
- OpenTelemetry (OTEL) – это стандарт (и набор библиотек) для сбора телеметрических данных (трассировок, метрик, журналов) из ваших приложений и инфраструктуры. Он не привязан к какому-либо конкретному инструменту визуализации или бэкэнду.
Просто говоря:
- OTEL – это как “универсальный язык” и набор библиотек для сбора телеметрических данных.
- Jaeger – это бэкэнд и пользовательский интерфейс для просмотра и анализа распределенных трассировок.
Зачем нам нужен OTEL, если у нас уже есть Jaeger?
1. Единый стандарт для сбора
В прошлом существовали проекты типа OpenTracing и OpenCensus. OpenTelemetry объединяет эти подходы к сбору метрик и трассировок в единый универсальный стандарт.
2. Легкая интеграция
Вы пишете свой код на Go (или другом языке), добавляете библиотеки OTEL для автоматической инъекции перехватчиков и спанов, и все. После этого не имеет значения, куда вы хотите отправить эти данные – Jaeger, Tempo, Zipkin, Datadog, пользовательский бэкэнд – OpenTelemetry позаботится о всей “сантехнике”. Вам нужно просто заменить экспортер.
3. Не только трассировки
OpenTelemetry охватывает трассировки, но также обрабатывает метрики и логи. Вы получаете единый набор инструментов для всех ваших потребностей в телеметрии, а не только в трассировке.
4. Jaeger как бэкэнд
Jaeger – отличный выбор, если вас в первую очередь интересует визуализация распределенного трассирования. Но он не предоставляет кросс-языковую инструментацию по умолчанию. OpenTelemetry, с другой стороны, предоставляет вам стандартизированный способ сбора данных, после чего вы решаете, куда их отправить (включая Jaeger).
На практике они часто работают вместе:
Ваше приложение использует OpenTelemetry → общается через протокол OTLP → отправляется в OpenTelemetry Collector (HTTP или grpc) → экспортируется в Jaeger для визуализации.
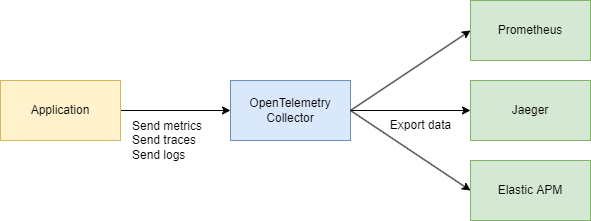
Техническая часть
Дизайн системы (немного)
Давайте быстро набросаем несколько служб, которые будут делать следующее:
- Служба покупки – обрабатывает платеж и записывает его в MongoDB
- CDC с Debezium – отслеживает изменения в таблице MongoDB и отправляет их в Kafka
- Процессор покупок – получает сообщение из Kafka и вызывает Службу аутентификации для поиска
user_idдля проверки - Служба аутентификации – простая пользовательская служба
В итоге:
- 3 службы на Go
- Kafka
- CDC (Debezium)
- MongoDB
Часть кода
Давайте начнем с инфраструктуры. Чтобы объединить все в одну систему, мы создадим большой файл Docker Compose. Мы начнем с настройки телеметрии.
Примечание: Весь код доступен по ссылке в конце статьи, включая инфраструктуру.
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
Также мы настроим коллектор — компонент, собирающий телеметрию.
Здесь мы выбираем gRPC для передачи данных, что означает, что общение будет происходить по HTTP/2:
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
Убедитесь, что адреса настроены правильно, и базовая конфигурация завершена.
Мы уже знаем, что OpenTelemetry (OTEL) использует два ключевых концепта — Идентификатор трассировки и Идентификатор спана— которые помогают отслеживать и мониторить запросы в распределенных системах.
Реализация кода
Теперь давайте посмотрим, как сделать это в вашем коде на Go. Нам понадобятся следующие импорты:
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
Затем мы добавляем функцию для инициализации нашего трейсера в main() при запуске приложения:
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
Настроив трассировку, нам просто нужно разместить спаны в коде для отслеживания вызовов. Например, если мы хотим измерить вызовы к базе данных (поскольку обычно это первое место, на которое мы смотрим при проблемах с производительностью), мы можем написать что-то вроде этого:
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
У нас есть трассировка на уровне сервиса — замечательно! Но мы можем пойти еще глубже, инструментируя уровень базы данных:
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
Теперь у нас есть полное представление о пути запроса. Перейдите в интерфейс Jaeger, запросите последние 20 трассировок для auth-service, и вы увидите все спаны и их связи в одном месте.
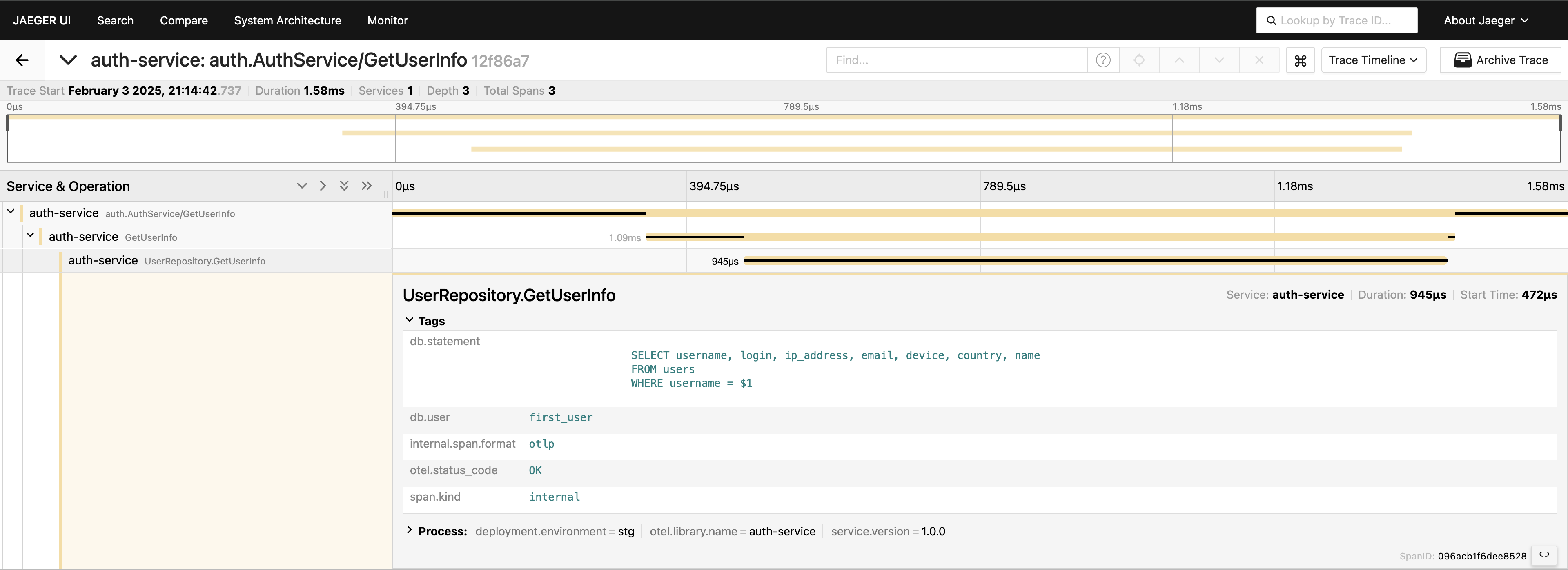
Теперь всё видно. Если вам это нужно, вы можете включить весь запрос в теги. Тем не менее, помните, что не следует перегружать телеметрию — добавляйте данные осознанно. Я просто демонстрирую возможности, но включение полного запроса таким образом обычно не рекомендуется.
gRPC клиент-сервер

Если вы хотите увидеть трассировку, охватывающую два сервиса gRPC, это довольно просто. Вам просто нужно добавить готовые перехватчики из библиотеки. Например, на стороне сервера:
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
На стороне клиента код так же короток:
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
Вот и всё! Убедитесь, что ваши экспортеры настроены правильно, и вы увидите один идентификатор трассировки, зарегистрированный в этих сервисах при вызове клиента сервера.
Обработка событий CDC и трассировка
Хотите также обрабатывать события из CDC? Одним из простых подходов является встраивание идентификатора трассировки в объект, который хранит MongoDB. Таким образом, когда Debezium захватывает изменение и отправляет его в Kafka, идентификатор трассировки уже является частью записи.
Например, если вы используете MongoDB, вы можете сделать что-то подобное:
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
Затем Debezium забирает этот объект (включая trace_id) и отправляет его в Kafka. Со стороны потребителя вам просто нужно разобрать входящее сообщение, извлечь trace_id и объединить его в ваш контекст трассировки:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
Альтернатива: Использование заголовков Kafka
Иногда проще хранить идентификатор трассировки в заголовках Kafka, а не в самом полезном нагрузке. Для рабочих процессов CDC это может быть недоступно из коробки — Debezium может ограничивать то, что добавляется в заголовки. Но если вы контролируете сторону производителя (или если вы используете стандартный производитель Kafka), вы можете сделать что-то подобное с Sarama:
Внедрение идентификатора трассировки в заголовки
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
Извлечение идентификатора трассировки на стороне потребителя
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
В зависимости от вашего случая использования и того, как настроен ваш конвейер CDC, вы можете выбрать подход, который лучше всего подходит:
- Встраивайте идентификатор трассировки в запись базы данных, чтобы он естественно проходил через CDC.
- Используйте заголовки Kafka, если у вас больше контроля над стороной производителя или если вы хотите избежать раздувания полезной нагрузки сообщения.
В любом случае, вы можете поддерживать консистентность ваших трассировок между несколькими службами — даже когда события обрабатываются асинхронно через Kafka и Debezium.
Заключение
Использование OpenTelemetry и Jaeger предоставляет подробные трассировки запросов, помогая вам точно определить, где и почему возникают задержки в распределенных системах.
Добавление Prometheus завершает картину метриками — ключевыми показателями производительности и стабильности. Вместе эти инструменты образуют комплексный стек наблюдаемости, позволяющий быстрее обнаруживать и решать проблемы, оптимизировать производительность и повышать общую надежность системы.
Могу сказать, что этот подход значительно ускоряет устранение неполадок в среде микросервисов и является одним из первых шагов, которые мы реализуем в наших проектах.

Ссылки
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus