













Discutons d’une question importante : comment surveillons-nous nos services si quelque chose ne va pas ?
D’une part, nous avons Prometheus avec des alertes et Kibana pour les tableaux de bord et d’autres fonctionnalités utiles. Nous savons également comment rassembler des journaux — la pile ELK est notre solution de prédilection. Cependant, un simple enregistrement n’est pas toujours suffisant : il ne fournit pas une vue d’ensemble du parcours d’une requête à travers l’ensemble de l’écosystème de composants.
Vous pouvez trouver plus d’infos sur ELK ici.
Mais que faire si nous voulons visualiser les requêtes ? Que faire si nous devons corréler les requêtes voyageant entre les systèmes ? Cela s’applique aussi bien aux microservices qu’aux monolithes — peu importe combien de services nous avons ; ce qui compte, c’est comment nous gérons leur latence.
En effet, chaque requête utilisateur peut passer par toute une chaîne de services indépendants, de bases de données, de files d’attente de messages et d’API externes.
Dans un environnement aussi complexe, il devient extrêmement difficile de déterminer exactement où les retards se produisent, d’identifier quelle partie de la chaîne agit comme un goulot d’étranglement en termes de performance, et de trouver rapidement la cause profonde des pannes lorsqu’elles se produisent.
Pour relever ces défis efficacement, nous avons besoin d’un système centralisé et cohérent pour collecter les données de télémétrie — traces, métriques et journaux. C’est là qu’OpenTelemetry et Jaeger interviennent.
Regardons les bases
Il y a deux termes principaux que nous devons comprendre :
ID de trace
Un ID de trace est un identifiant de 16 octets, souvent représenté sous la forme d’une chaîne hexadécimale de 32 caractères. Il est automatiquement généré au début d’une trace et reste le même pour tous les spans créés par une demande particulière. Cela permet de voir facilement comment une demande circule à travers différents services ou composants dans un système.
ID de span
Chaque opération individuelle dans une trace obtient son propre ID de span, qui est généralement une valeur aléatoire de 64 bits. Les spans partagent le même ID de trace, mais chacun a un ID de span unique, ce qui vous permet de déterminer exactement quelle partie du flux de travail chaque span représente (comme une requête de base de données ou un appel à un autre microservice).
Comment sont-ils liés ?
ID de trace et ID de span se complètent mutuellement.
Lorsque qu’une demande est initiée, un ID de trace est généré et transmis à tous les services impliqués. Chaque service, à son tour, crée un span avec un ID de span unique lié à l’ID de trace, vous permettant de visualiser l’ensemble du cycle de vie de la demande du début à la fin.
D’accord, alors pourquoi ne pas simplement utiliser Jaeger? Pourquoi avons-nous besoin d’OpenTelemetry (OTEL) et de toutes ses spécifications? C’est une excellente question ! Décomposons cela étape par étape.
Trouvez plus d’informations sur Jaeger ici.
TL;DR
- Jaeger est un système de stockage et de visualisation des traces distribuées. Il collecte, stocke, recherche et affiche des données montrant comment les requêtes « voyagent » à travers vos services.
- OpenTelemetry (OTEL) est une norme (et un ensemble de bibliothèques) pour collecter des données de télémétrie (traces, métriques, journaux) de vos applications et infrastructures. Il n’est pas lié à un outil de visualisation ou un backend spécifique.
Pour faire simple :
- OTEL est comme un « langage universel » et un ensemble de bibliothèques pour la collecte de télémétrie.
- Jaeger est un backend et une interface utilisateur pour visualiser et analyser des traces distribuées.
Pourquoi avons-nous besoin d’OTEL si nous avons déjà Jaeger ?
1. Une norme unique pour la collecte
Dans le passé, il y avait des projets comme OpenTracing et OpenCensus. OpenTelemetry unifie ces approches de collecte de métriques et de traces en une seule norme universelle.
2. Intégration facile
Vous écrivez votre code en Go (ou dans un autre langage), ajoutez des bibliothèques OTEL pour l’injection automatique des intercepteurs et des spans, et c’est tout. Ensuite, peu importe où vous souhaitez envoyer ces données — Jaeger, Tempo, Zipkin, Datadog, un backend personnalisé — OpenTelemetry s’occupe de la plomberie. Vous n’avez qu’à changer l’exportateur.
3. Pas seulement des traces
OpenTelemetry couvre les traces, mais gère également les métriques et les journaux. Vous vous retrouvez avec un seul ensemble d’outils pour tous vos besoins en télémétrie, pas seulement pour le traçage.
4. Jaeger comme backend
Jaeger est un excellent choix si vous êtes principalement intéressé par la visualisation de la traçabilité distribuée. Mais il ne fournit pas l’instrumentation inter-langage par défaut. OpenTelemetry, en revanche, vous offre un moyen standardisé de collecter des données, puis vous décidez où les envoyer (y compris vers Jaeger).
En pratique, ils travaillent souvent ensemble :
Votre application utilise OpenTelemetry → communique via le protocole OTLP → va vers le Collecteur OpenTelemetry (HTTP ou grpc) → exporte vers Jaeger pour la visualisation.
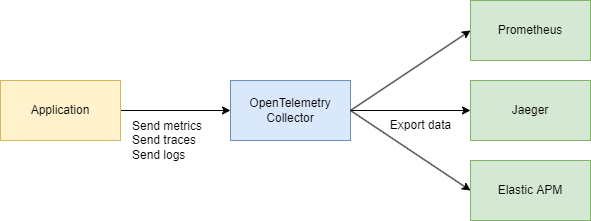
Partie technique
Conception système (un petit peu)
Esquissons rapidement quelques services qui feront ce qui suit :
- Service d’achat – traite un paiement et l’enregistre dans MongoDB
- CDC avec Debezium – écoute les changements dans la table MongoDB et les envoie à Kafka
- Processeur d’achat – consomme le message de Kafka et appelle le Service d’authentification pour rechercher le
user_idpour validation - Service d’authentification – un service utilisateur simple
En résumé :
- 3 services Go
- Kafka
- CDC (Debezium)
- MongoDB
Partie code
Commençons par l’infrastructure. Pour rassembler le tout en un seul système, nous créerons un grand fichier Docker Compose. Nous commencerons par configurer la télémétrie.
Remarque : Tout le code est disponible via un lien à la fin de l’article, y compris l’infrastructure.
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
Nous allons également configurer le collecteur — le composant qui recueille la télémétrie.
Ici, nous choisissons gRPC pour le transfert de données, ce qui signifie que la communication se fera via HTTP/2 :
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
Assurez-vous d’ajuster les adresses si nécessaire, et vous avez terminé avec la configuration de base.
Nous savons déjà qu’OpenTelemetry (OTEL) utilise deux concepts clés — ID de trace et ID de span — qui aident à suivre et surveiller les requêtes dans les systèmes distribués.
Implémentation du code
Maintenant, examinons comment faire fonctionner cela dans votre code Go. Nous avons besoin des imports suivants :
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
Ensuite, nous ajoutons une fonction pour initialiser notre traceur dans main() lorsque l’application démarre :
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
Avec le traçage configuré, nous devons simplement placer des spans dans le code pour suivre les appels. Par exemple, si nous voulons mesurer les appels à la base de données (car c’est généralement le premier endroit où nous cherchons des problèmes de performance), nous pouvons écrire quelque chose comme ceci :
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
Nous avons le traçage au niveau du service — super ! Mais nous pouvons aller encore plus loin, en instrumentant le niveau de la base de données :
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
Maintenant, nous avons une vue complète du parcours de la requête. Rendez-vous sur l’interface utilisateur de Jaeger, interrogez les 20 dernières traces sous auth-service, et vous verrez tous les spans et comment ils se connectent en un seul endroit.
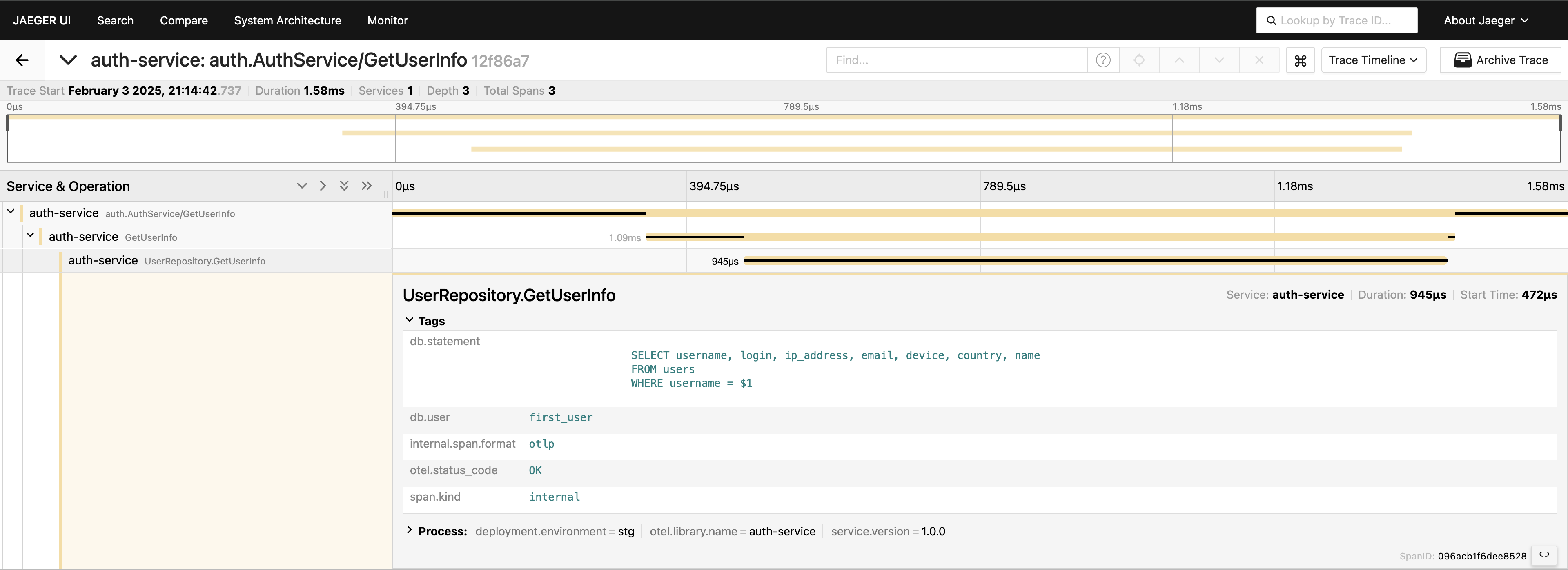
Maintenant, tout est visible. Si vous en avez besoin, vous pouvez inclure la requête entière dans les balises. Cependant, gardez à l’esprit que vous ne devez pas surcharger votre télémétrie — ajoutez les données de manière délibérée. Je ne fais que démontrer ce qui est possible, mais inclure la requête complète de cette manière n’est généralement pas quelque chose que je recommanderais.
Client-serveur gRPC

Si vous souhaitez voir une trace qui s’étend sur deux services gRPC, c’est assez simple. Tout ce que vous devez faire est d’ajouter les intercepteurs prêts à l’emploi de la bibliothèque. Par exemple, du côté du serveur :
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
Du côté client, le code est tout aussi court :
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
C’est tout ! Assurez-vous que vos exportateurs sont configurés correctement, et vous verrez un seul ID de trace enregistré à travers ces services lorsque le client appelle le serveur.
Gestion des événements CDC et traçage
Vous voulez également gérer les événements du CDC ? Une approche simple consiste à intégrer l’ID de trace dans l’objet que MongoDB stocke. De cette façon, lorsque Debezium capture le changement et l’envoie à Kafka, l’ID de trace fait déjà partie de l’enregistrement.
Par exemple, si vous utilisez MongoDB, vous pouvez faire quelque chose comme ceci :
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
Debezium récupère ensuite cet objet (y compris trace_id) et l’envoie à Kafka. Du côté du consommateur, vous analysez simplement le message entrant, extrayez le trace_id et l’intégrez dans votre contexte de traçage :
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
Alternative : Utiliser les en-têtes Kafka
Parfois, il est plus facile de stocker l’ID de trace dans les en-têtes Kafka plutôt que dans le payload lui-même. Pour les flux de travail CDC, cela peut ne pas être disponible par défaut — Debezium peut limiter ce qui est ajouté aux en-têtes. Mais si vous contrôlez le côté producteur (ou si vous utilisez un producteur Kafka standard), vous pouvez faire quelque chose comme ceci avec Sarama :
Injection d’un ID de trace dans les en-têtes
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
Extraction d’un ID de trace du côté consommateur
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
Selon votre cas d’utilisation et la manière dont votre pipeline CDC est configuré, vous pouvez choisir l’approche qui fonctionne le mieux :
- Intégrer l’ID de trace dans l’enregistrement de la base de données afin qu’il circule naturellement via CDC.
- Utiliser les en-têtes Kafka si vous avez plus de contrôle sur le côté producteur ou si vous souhaitez éviter d’enflammer le payload du message.
Dans tous les cas, vous pouvez garder vos traces cohérentes à travers plusieurs services, même lorsque les événements sont traités de manière asynchrone via Kafka et Debezium.
Conclusion
Utiliser OpenTelemetry et Jaeger fournit des traces de requêtes détaillées, vous aidant à identifier où et pourquoi des retards se produisent dans les systèmes distribués.
Ajouter Prometheus complète le tableau avec des métriques — des indicateurs clés de performance et de stabilité. Ensemble, ces outils forment une pile d’observabilité complète, permettant une détection et une résolution plus rapides des problèmes, une optimisation des performances et une fiabilité globale du système.
Je peux dire que cette approche accélère considérablement le dépannage dans un environnement de microservices et est l’une des premières choses que nous mettons en œuvre dans nos projets.

Liens
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus