













Laten we een belangrijke vraag bespreken: hoe monitoren we onze services als er iets misgaat?
Enerzijds hebben we Prometheus met waarschuwingen en Kibana voor dashboards en andere handige functies. We weten ook hoe we logs kunnen verzamelen — de ELK-stack is onze standaardoplossing. Echter, eenvoudig loggen is niet altijd voldoende: het biedt geen alomvattend beeld van de reis van een verzoek over het gehele ecosysteem van componenten.
Je kunt meer informatie vinden over ELK hier.
Maar wat als we verzoeken willen visualiseren? Wat als we verzoeken tussen systemen moeten correleren? Dit geldt zowel voor microservices als voor monolieten — het maakt niet uit hoeveel services we hebben; waar het om draait is hoe we hun latentie beheren.
Inderdaad, elk gebruikersverzoek kan door een hele reeks onafhankelijke services, databases, berichtenwachtrijen en externe API’s gaan.
In zo’n complexe omgeving wordt het extreem moeilijk om precies te bepalen waar vertragingen optreden, te identificeren welk deel van de keten fungeert als prestatieknelpunt, en snel de oorzaak van fouten te vinden wanneer ze zich voordoen.
Om deze uitdagingen effectief aan te pakken, hebben we een gecentraliseerd, consistent systeem nodig om telemetriegegevens te verzamelen — sporen, metrieken en logs. Hier komen OpenTelemetry en Jaeger te hulp.
Laten we naar de basis kijken
Er zijn twee belangrijke termen die we moeten begrijpen:
Trace ID
Een Trace ID is een 16-byte identificatie, vaak weergegeven als een 32-karakter hexadecimale string. Het wordt automatisch gegenereerd aan het begin van een trace en blijft hetzelfde over alle spans die zijn gecreëerd door een specifiek verzoek. Dit maakt het gemakkelijk om te zien hoe een verzoek zich verplaatst door verschillende services of componenten in een systeem.
Span ID
Elke individuele bewerking binnen een trace krijgt zijn eigen Span ID, wat typisch een willekeurig gegenereerde 64-bits waarde is. Spans delen dezelfde Trace ID, maar elk heeft een unieke Span ID, zodat je precies kunt vaststellen welk deel van de workflow elke span vertegenwoordigt (zoals een databasequery of een oproep naar een andere microservice).
Hoe zijn ze gerelateerd?
Trace ID en Span ID vullen elkaar aan.
Wanneer een verzoek wordt geïnitieerd, wordt een Trace ID gegenereerd en doorgegeven aan alle betrokken services. Elke service creëert op zijn beurt een span met een unieke Span ID die is gekoppeld aan de Trace ID, waardoor je de volledige levenscyclus van het verzoek van begin tot eind kunt visualiseren.
Oke, waarom gebruiken we dan niet gewoon Jaeger? Waarom hebben we OpenTelemetry (OTEL) en al zijn specificaties nodig? Dat is een goede vraag! Laten we het stap voor stap uitleggen.
Meer informatie over Jaeger vind je hier.
TL;DR
- Jaeger is een systeem voor het opslaan en visualiseren van gedistribueerde sporen. Het verzamelt, slaat op, doorzoekt en toont gegevens die laten zien hoe verzoeken “reizen” door uw services.
- OpenTelemetry (OTEL) is een standaard (en een set bibliotheken) voor het verzamelen van telemetriegegevens (sporen, metingen, logboeken) van uw toepassingen en infrastructuur. Het is niet gekoppeld aan een enkele visualisatietool of backend.
Kort gezegd:
- OTEL is als een “universele taal” en set bibliotheken voor telemetrie verzameling.
- Jaeger is een backend en UI voor het bekijken en analyseren van gedistribueerde sporen.
Waarom hebben we OTEL nodig als we al Jaeger hebben?
1. Een enkele standaard voor verzameling
Vroeger waren er projecten zoals OpenTracing en OpenCensus. OpenTelemetry verenigt deze benaderingen voor het verzamelen van metingen en sporen in één universele standaard.
2. Gemakkelijke integratie
U schrijft uw code in Go (of een andere taal), voegt OTEL-bibliotheken toe voor het automatisch injecteren van onderscheppers en sporen, en dat is het. Daarna maakt het niet uit waar u die gegevens naartoe wilt sturen—Jaeger, Tempo, Zipkin, Datadog, een aangepaste backend—OpenTelemetry zorgt voor de installatie. U hoeft alleen de exporteur te vervangen.
3. Niet alleen sporen
OpenTelemetry behandelt sporen, maar het gaat ook om metingen en logboeken. U eindigt met een enkele set gereedschappen voor al uw telemetriebehoeften, niet alleen traceren.
4. Jaeger als een backend
Jaeger is een uitstekende keuze als je voornamelijk geïnteresseerd bent in gedistribueerde tracing visualisatie. Maar het biedt geen standaard cross-language instrumentatie. OpenTelemetry daarentegen geeft je een gestandaardiseerde manier om gegevens te verzamelen, waarna je beslist waar je het naartoe stuurt (inclusief Jaeger).
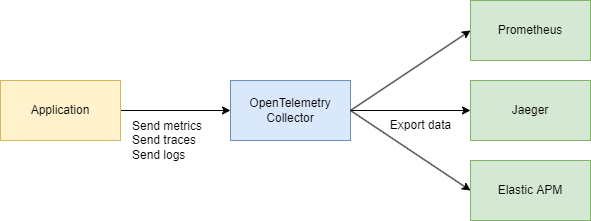
In de praktijk werken ze vaak samen:
Je applicatie gebruikt OpenTelemetry → communiceert via het OTLP-protocol → gaat naar de OpenTelemetry Collector (HTTP of grpc) → exporteert naar Jaeger voor visualisatie.
Tech Part
Systeemontwerp (Een beetje)
Laten we snel een paar services schetsen die het volgende zullen doen:
- Purchase Service – verwerkt een betaling en slaat deze op in MongoDB
- CDC met Debezium – luistert naar wijzigingen in de MongoDB-tabel en stuurt ze naar Kafka
- Purchase Processor – verwerkt het bericht van Kafka en roept de Auth Service aan om de
user_idop te zoeken ter validatie - Auth Service – een eenvoudige gebruikersservice
Samengevat:
- 3 Go-services
- Kafka
- CDC (Debezium)
- MongoDB
Code Part
Laten we beginnen met de infrastructuur. Om alles samen te voegen in één systeem, zullen we een grote Docker Compose-bestand maken. We zullen beginnen met het opzetten van de telemetrie.
Let op: Alle code is beschikbaar via een link aan het einde van het artikel, inclusief de infrastructuur.
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
We gaan ook de collector configureren — het component dat telemetry verzamelt.
Hier kiezen we voor gRPC voor gegevensoverdracht, wat betekent dat de communicatie zal verlopen via HTTP/2:
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
Zorg ervoor dat je eventuele adressen aanpast indien nodig, en dan ben je klaar met de basisconfiguratie.
We weten al dat OpenTelemetry (OTEL) twee belangrijke concepten gebruikt — Trace ID en Span ID — die helpen bij het volgen en monitoren van verzoeken in gedistribueerde systemen.
Implementatie van de Code
Laten we nu bekijken hoe we dit werkend krijgen in je Go-code. We hebben de volgende imports nodig:
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
Vervolgens voegen we een functie toe om onze tracer te initialiseren in main() wanneer de applicatie start:
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
Met tracing ingesteld, hoeven we alleen maar spans in de code te plaatsen om oproepen te volgen. Als we bijvoorbeeld database-oproepen willen meten (omdat dat meestal de eerste plek is waar we naar prestatieproblemen kijken), kunnen we iets als dit schrijven:
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
We hebben tracing op het serviceniveau — geweldig! Maar we kunnen nog dieper gaan door de database-laag instrumenteren:
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
Nu hebben we een compleet overzicht van de verzoekreis. Ga naar de Jaeger UI, vraag de laatste 20 traces op onder auth-service, en je zult alle spans zien en hoe ze met elkaar verbonden zijn op één plek.
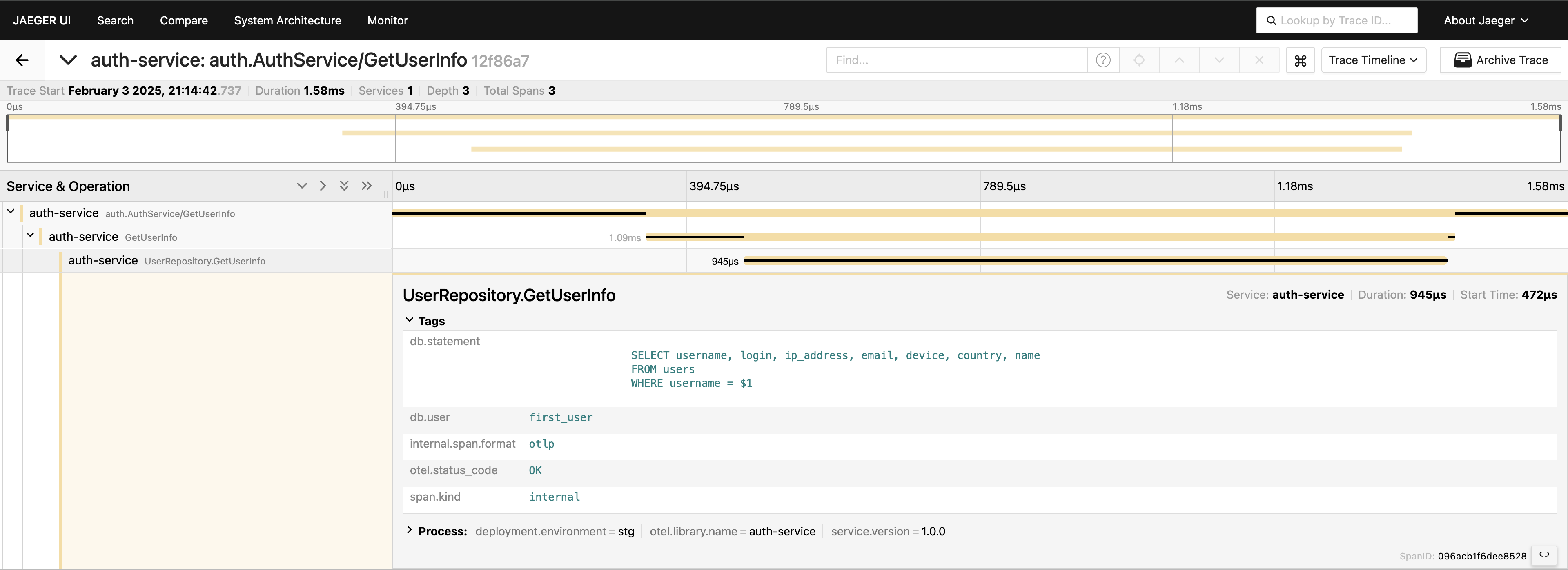
Nu is alles zichtbaar. Als je het nodig hebt, kun je de volledige query opnemen in de tags. Houd er echter rekening mee dat je je telemetrie niet moet overbelasten – voeg gegevens doelbewust toe. Ik demonstreer gewoon wat mogelijk is, maar het opnemen van de volledige query op deze manier is iets wat ik over het algemeen niet zou aanbevelen.
gRPC client-server

Als je een trace wilt zien die twee gRPC-services bestrijkt, is dat heel eenvoudig. Het enige wat je hoeft te doen is de standaard interceptors van de bibliotheek toevoegen. Bijvoorbeeld, aan de serverzijde:
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
Aan de clientzijde is de code net zo kort:
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
Dat is alles! Zorg ervoor dat je exporteurs correct geconfigureerd zijn, en je zult een enkele Trace ID zien gelogd over deze services wanneer de client de server aanroept.
Omgaan met CDC-gebeurtenissen en tracing
Wil je ook gebeurtenissen van CDC afhandelen? Een eenvoudige aanpak is om de Trace ID in te sluiten in het object dat MongoDB opslaat. Op die manier, wanneer Debezium de wijziging vastlegt en naar Kafka stuurt, maakt de Trace ID al deel uit van het record.
Bijvoorbeeld, als je MongoDB gebruikt, kun je zoiets doen:
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
Debezium pakt vervolgens dit object (inclusief trace_id) op en stuurt het naar Kafka. Aan de consumentzijde parseer je eenvoudig het inkomende bericht, haal je de trace_id eruit en voeg je dit samen in je tracingcontext:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
Alternatief: Gebruik van Kafka-headers
Soms is het makkelijker om de Trace ID op te slaan in Kafka headers in plaats van in de payload zelf. Voor CDC-workflows is dit misschien niet direct beschikbaar – Debezium kan beperken wat er aan headers wordt toegevoegd. Maar als je de producentkant beheert (of als je een standaard Kafka-producent gebruikt), kun je iets als dit doen met Sarama:
Het injecteren van een Trace ID in Headers
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
Het extraheren van een Trace ID aan de consumentenkant
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
Afhankelijk van jouw gebruikssituatie en hoe jouw CDC-pijplijn is opgezet, kun je de aanpak kiezen die het beste werkt:
- Voeg de Trace ID toe aan het database-record zodat het natuurlijk meegaat via CDC.
- Gebruik Kafka headers als je meer controle hebt over de producentkant of als je het opblazen van de berichtpayload wilt vermijden.
Op deze manier kun je jouw sporen consistent houden over meerdere services – zelfs wanneer gebeurtenissen asynchroon worden verwerkt via Kafka en Debezium.
Conclusie
Het gebruik van OpenTelemetry en Jaeger biedt gedetailleerde verzoektraces, die je helpen bij het pinpointen van waar en waarom vertragingen optreden in gedistribueerde systemen.
Door Prometheus toe te voegen, wordt het plaatje compleet met metrieken – sleutelindicatoren van prestaties en stabiliteit. Samen vormen deze tools een uitgebreide observability-stack, waardoor snellere detectie en oplossing van problemen, prestatieoptimalisatie en algehele systeembetrouwbaarheid mogelijk zijn.
Ik kan zeggen dat deze aanpak aanzienlijk bijdraagt aan het versnellen van het oplossen van problemen in een microservices-omgeving en een van de eerste dingen is die we implementeren in onze projecten.

Links
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus