













让我们讨论一个重要问题:如果出现问题,我们如何监控我们的服务?
一方面,我们可以使用Prometheus进行警报,使用Kibana创建仪表板和其他实用功能。我们也知道如何收集日志 – ELK堆栈是我们的首选解决方案。然而,简单的日志记录并不总是足够的:它无法提供对请求在整个组件生态系统中的旅程的整体视图。
您可以在此处找到有关ELK的更多信息此处。
但是,如果我们想要可视化请求呢?如果我们需要关联系统之间传输的请求呢?这适用于微服务和单体架构 – 服务数量多少并不重要;重要的是我们如何管理它们的延迟。
事实上,每个用户请求可能会经过一整套独立的服务、数据库、消息队列和外部API。
在这样一个复杂的环境中,要准确地找出延迟发生的地方、确定链中的哪个部分充当性能瓶颈、并在失败发生时快速找到根本原因变得极其困难。
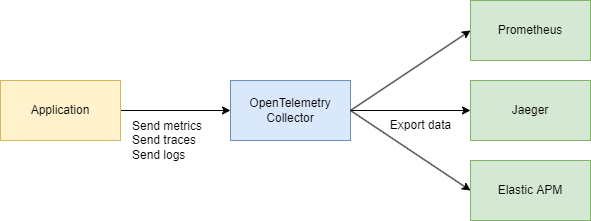
为了有效解决这些挑战,我们需要一个集中、一致的系统来收集遥测数据 – 跟踪、指标和日志。这就是OpenTelemetry和Jaeger发挥作用的地方。
让我们看看基础知识
我们需要理解两个主要术语:
追踪 ID
追踪 ID 是一个 16 字节的标识符,通常表示为一个 32 字符的十六进制字符串。它在追踪开始时自动生成,并在特定请求创建的所有跨度中保持不变。这使得我们可以轻松查看请求如何在系统中的不同服务或组件之间传递。
跨度 ID
追踪中的每个单独操作都有自己的跨度 ID,通常是一个随机生成的 64 位值。跨度共享相同的追踪 ID,但每个跨度都有一个唯一的跨度 ID,因此您可以准确定位每个跨度代表工作流的哪个部分(如数据库查询或对另一个微服务的调用)。
它们是如何关联的?
追踪 ID 和 跨度 ID 互为补充。
当请求被发起时,生成一个追踪 ID 并传递给所有相关服务。每个服务反过来创建一个与追踪 ID 相关联的唯一跨度 ID 的跨度,使您能够从头到尾可视化请求的完整生命周期。
好吧,那为什么不直接使用 Jaeger 呢?? 我们为什么需要 OpenTelemetry (OTEL) 和它的所有规范?? 这是个好问题!让我们一步一步来解答。
想了解更多关于 Jaeger 的信息,请 点击这里。
简而言之
- Jaeger 是一个用于存储和可视化分布式追踪的系统。它收集、存储、搜索并展示数据,显示请求如何在您的服务中“流动”。
- OpenTelemetry (OTEL) 是一个标准(以及一套库),用于从您的应用程序和基础设施中收集遥测数据(追踪、指标、日志)。它并不依赖于任何单一的可视化工具或后端。
简单来说:
- OTEL 就像一个“通用语言”和一套用于遥测收集的库。
- Jaeger 是一个用于查看和分析分布式追踪的后端和用户界面。
如果我们已经有了 Jaeger,为什么还需要 OTEL?
1. 统一的收集标准
过去有像 OpenTracing 和 OpenCensus 这样的项目。OpenTelemetry 将这些收集指标和追踪的方法统一为一个通用标准。
2. 轻松集成
您只需用 Go(或其他语言)编写代码,添加 OTEL 库以自动注入拦截器和跨度,完成后,您想将数据发送到哪里并不重要——Jaeger、Tempo、Zipkin、Datadog、自定义后端——OpenTelemetry 会处理所有的底层工作。您只需更换导出器。
3. 不仅仅是追踪
OpenTelemetry 不仅覆盖追踪,还处理指标和日志。您最终将拥有一个用于所有遥测需求的单一工具集,而不仅仅是追踪。
4. Jaeger 作为后端
Jaeger 是一个出色的选择,如果你主要关注分布式追踪可视化。但它默认不提供跨语言的仪表化。另一方面,OpenTelemetry 为您提供了一种标准化的收集数据的方式,然后由您决定将数据发送到哪里(包括 Jaeger)。
实际上,它们经常一起使用:共同工作:
您的应用程序使用 OpenTelemetry → 通过 OTLP 协议通信 → 发送到 OpenTelemetry Collector(HTTP 或 grpc) → 导出到 Jaeger 进行可视化。
技术部分
系统设计(一点点)
让我们快速勾勒出一对将执行以下操作的服务:
- 购买服务 – 处理付款并在 MongoDB 中记录
- 使用 Debezium 的 CDC – 监听 MongoDB 表中的更改并将其发送到 Kafka
- 购买处理器 – 从 Kafka 消费消息并调用 Auth 服务查找
user_id进行验证 - Auth 服务 – 一个简单的用户服务
总结:
- 3 个 Go 服务
- Kafka
- CDC(Debezium)
- MongoDB
代码部分
让我们从基础架构开始。为了将所有内容整合到一个系统中,我们将创建一个庞大的 Docker Compose 文件。我们将从设置遥测开始。
注意: 所有代码都可以通过文章末尾的链接获取,包括基础设施。
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
我们还将配置收集器——收集遥测数据的组件。
在这里,我们选择 gRPC 进行数据传输,这意味着通信将通过 HTTP/2 进行:
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
确保根据需要调整任何地址,这样你就完成了基本配置。
我们已经知道 OpenTelemetry (OTEL) 使用两个关键概念——跟踪 ID 和 跨度 ID——帮助跟踪和监控分布式系统中的请求。
实现代码
现在,让我们看看如何在你的 Go 代码中实现这个功能。我们需要以下导入:
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
然后,我们在应用程序启动时在 main() 中添加一个函数来初始化我们的追踪器:
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
设置好追踪后,我们只需在代码中放置跨度以跟踪调用。例如,如果我们想要测量数据库调用(因为这通常是我们寻找性能问题的首要地方),我们可以写以下内容:
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
我们在服务层有了追踪——太好了!但我们可以更深入,给数据库层加上监控:
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
现在,我们可以完整地查看请求的旅程。前往 Jaeger UI,在 auth-service 下查询最近的 20 个跟踪,你会看到所有的跨度以及它们在一个地方如何连接。
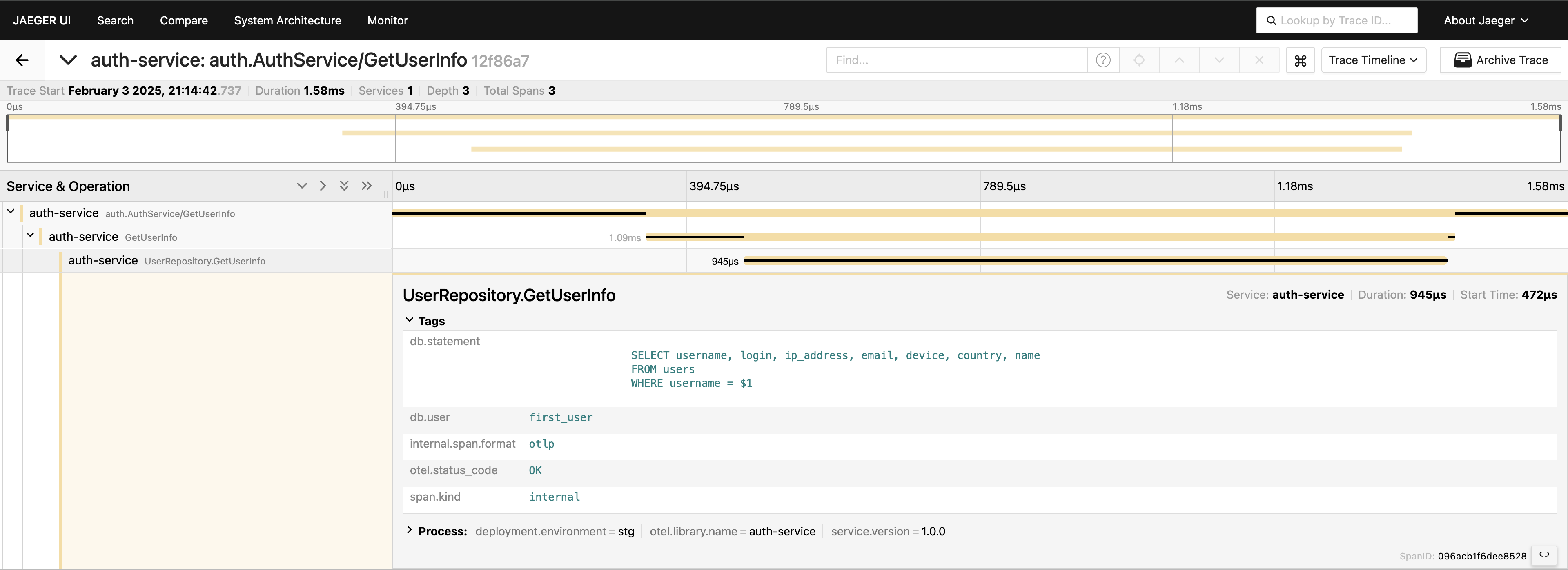
现在,一切都变得可见。如果需要,您可以将整个查询包含在标签中。不过,请记住,不要过载您的遥测——要有意识地添加数据。我只是演示什么是可能的,但以这种方式包含完整的查询并不是我通常会推荐的。
gRPC 客户端-服务器

如果您想查看跨两个 gRPC 服务的跟踪,这非常简单。您只需要从库中添加开箱即用的拦截器。例如,在服务器端:
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
在客户端,代码同样简短:
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
就这样!确保您的导出器配置正确,当客户端调用服务器时,您将在这些服务中看到一个单一的 跟踪 ID 被记录。
处理 CDC 事件和跟踪
想处理来自 CDC 的事件吗?一种简单的方法是在 MongoDB 存储的对象中嵌入跟踪 ID。这样,当 Debezium 捕获更改并将其发送到 Kafka 时,跟踪 ID 已经是记录的一部分。
例如,如果您使用 MongoDB,可以这样做:
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
然后,Debezium 会拾取这个对象(包括 trace_id)并将其发送到 Kafka。在 消费者 端,您只需解析传入的消息,提取 trace_id,并将其合并到您的跟踪上下文中:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
替代方案:使用 Kafka 头部
有时,将Trace ID存储在Kafka标头中比直接放在负载中更容易。对于CDC工作流程,这可能不是开箱即用的功能 — Debezium 可能会限制标头的添加内容。但如果您控制生成者方面(或者使用标准的Kafka生成者),您可以像这样操作 Sarama:
在标头中注入Trace ID
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
在消费者端提取Trace ID
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
根据您的用例以及CDC管道的设置方式,您可以选择最适合的方法:
- 将Trace ID嵌入数据库记录,使其通过CDC自然流动。
- 使用Kafka标头,如果您对生成者方面有更多控制,或者希望避免增加消息负载。
无论哪种方式,您都可以在多个服务之间保持跟踪一致 — 即使事件通过Kafka和Debezium进行异步处理。
结论
使用OpenTelemetry 和 Jaeger 可以提供详细的请求跟踪,帮助您准确定位分布式系统中延迟发生的位置和原因。
添加 Prometheus 可以提供度量标准 — 用于性能和稳定性的关键指标,这些工具共同构建了完整的可观察性堆栈,实现更快的问题检测和解决、性能优化以及整体系统可靠性。
我可以说,这种方法显著加快了在微服务环境中的故障排除速度,并且是我们在项目中实施的首要步骤之一。

链接
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus