













重要な問題を議論しましょう:何かがうまくいかない場合、どのようにしてサービスを監視するか?
一方で、アラートを備えたPrometheusやダッシュボードなどの便利な機能を備えたKibanaがあります。また、ELKスタックを使用してログを収集する方法も知っています。ただし、単純なログ記録だけでは常に十分ではありません。それは、要求がコンポーネントの全エコシステムを横断する旅の包括的なビューを提供してくれません。
ELKに関する詳細はこちらで確認できます。
しかし、リクエストを視覚化したい場合はどうでしょうか?システム間を移動するリクエストを相関させる必要がある場合はどうでしょうか?これはマイクロサービスでもモノリスでも適用されます。重要なのは、サービスの数ではなく、その遅延をどのように管理するかです。
実際に、各ユーザーリクエストは独立したサービス、データベース、メッセージキュー、外部APIを通過する可能性があります。
そのような複雑な環境では、遅延が発生している具体的な場所を特定したり、どの部分がパフォーマンスのボトルネックとして機能しているかを特定したり、障害の原因を迅速に見つけることが非常に困難になります。
これらの課題に効果的に対処するためには、トレース、メトリクス、ログなどのテレメトリデータを収集するための中央集権的で一貫したシステムが必要です。そのために、OpenTelemetryとJaegerが救世主として登場します。
基本を見てみましょう
理解する必要がある2つの主要な用語があります:
トレースID
トレースIDは16バイトの識別子で、通常は32文字の16進数文字列として表されます。トレースの開始時に自動的に生成され、特定のリクエストによって作成されたすべてのスパンで同じままです。これにより、リクエストがシステム内のさまざまなサービスやコンポーネントを通過する方法が簡単に確認できます。
スパンID
トレース内の個々の操作ごとに固有のスパンIDが割り当てられ、通常はランダムに生成される64ビットの値です。スパンは同じトレースIDを共有しますが、それぞれが固有のスパンIDを持つため、各スパンがワークフローのどの部分を表しているかを正確に特定できます(たとえば、データベースクエリや他のマイクロサービスへの呼び出し)。
それらはどのように関連していますか?
トレースID とスパンIDはお互いを補完します。
リクエストが開始されると、トレースIDが生成され、関係するすべてのサービスに渡されます。その後、それぞれのサービスは、トレースIDにリンクされた固有のスパンIDを持つスパンを作成し、リクエストの開始から終了までの完全なライフサイクルを視覚化できるようにします。
では、なぜJaegerを使用しないのですか? OTEL(OpenTelemetry)やその仕様が必要な理由は何ですか? それは素晴らしい質問です!ステップバイステップで解説していきましょう。
Jaegerの詳細はこちらでご確認いただけます。
要約
- Jaegerは、分散トレースを保存および可視化するシステムです。リクエストがサービスを通過する過程を示すデータを収集、保存、検索、表示します。
- OpenTelemetry(OTEL)は、アプリケーションやインフラストラクチャからテレメトリデータ(トレース、メトリクス、ログ)を収集するための標準(およびライブラリのセット)です。特定の可視化ツールやバックエンドに結び付けられていません。
簡単に言うと:
- OTELは、テレメトリ収集のための「汎用言語」とライブラリのセットです。
- Jaegerは、分散トレースを表示および分析するためのバックエンドおよびUIです。
なぜJaegerがすでにあるのにOTELが必要なのか?
1. 収集のための単一の標準
過去には、OpenTracingやOpenCensusなどのプロジェクトがありました。OpenTelemetryはこれらのメトリクスとトレースを収集するアプローチを1つの汎用標準に統一します。
2. 簡単な統合
Go(または他の言語)でコードを記述し、自動インジェクションインターセプターとスパンのためのOTELライブラリを追加するだけです。その後、データを送信したい場所はどこでも問題ありません—Jaeger、Tempo、Zipkin、Datadog、カスタムバックエンド—OpenTelemetryが配管を処理します。単にエクスポーターを交換するだけです。
3. トレースだけでなく
OpenTelemetryはトレースをカバーしていますが、メトリクスとログも取り扱います。追跡だけでなく、すべてのテレメトリニーズのための単一のツールセットが得られます。
4. バックエンドとしてのJaeger
Jaegerは、分散トレースの可視化に主に興味がある場合には優れた選択肢です。しかし、デフォルトではクロスランゲージの計測を提供しません。一方、OpenTelemetryはデータを収集するための標準化された方法を提供し、その後どこに送信するか(Jaegerを含む)を決定します。
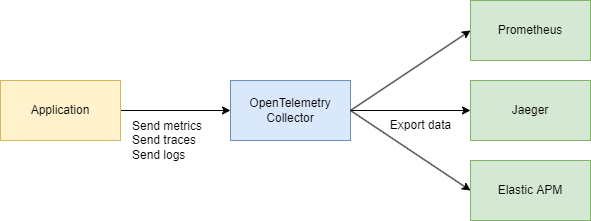
実際には、彼らはしばしば一緒に機能します:
あなたのアプリケーションはOpenTelemetryを使用し→OTLPプロトコルを介して通信し→OpenTelemetryコレクター(HTTPまたはgRPC)に送信し→可視化のためにJaegerにエクスポートします。
テクニカル部分
システム設計(少しだけ)
以下のことを行ういくつかのサービスを簡単に描いてみましょう:
- 購入サービス – 支払いを処理し、MongoDBに記録します
- Debeziumを使用したCDC – MongoDBテーブルの変更をリッスンし、それをKafkaに送信します
- 購入プロセッサ – Kafkaからメッセージを消費し、検証のためにAuth Serviceに
user_idを照会します - Auth Service – シンプルなユーザーサービス
要約すると:
- 3つのGoサービス
- Kafka
- CDC(Debezium)
- MongoDB
コード部分
インフラストラクチャから始めましょう。すべてを1つのシステムにまとめるために、大きなDocker Composeファイルを作成します。まず、テレメトリーの設定を行います。
注意: すべてのコードは、記事の最後にリンクを介して利用できます。その中にはインフラストラクチャも含まれます。
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
また、テレメトリを収集するコンポーネントであるコレクターを構成します。
ここでは、データ転送に gRPC を選択し、通信は HTTP/2 を介して行われます。
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
必要に応じてアドレスを調整して、ベースの構成が完了です。
既に OpenTelemetry(OTEL)が2つの重要な概念、トレースIDとスパンID、を使用してリクエストを分散システムで追跡および監視することがわかっています。
コードの実装
さて、Goコードでこれを動作させる方法を見てみましょう。以下のimport文が必要です:
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
次に、アプリケーションの起動時にmain()内でトレーサーを初期化する関数を追加します:
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
トレースが設定されているため、コード内にスパンを配置して呼び出しを追跡するだけです。たとえば、パフォーマンスの問題を解決する場合は通常最初にデータベース呼び出しを測定したいので、次のように記述できます:
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
サービス層でトレースを行っていますが、データベース層にさらに深く入り込むこともできます:
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
これで、リクエストの経過を完全に把握できます。Jaeger UI に移動し、auth-serviceの下で最後の20件のトレースをクエリし、すべてのスパンとそれらがどのようにつながっているかを1か所で確認できます。
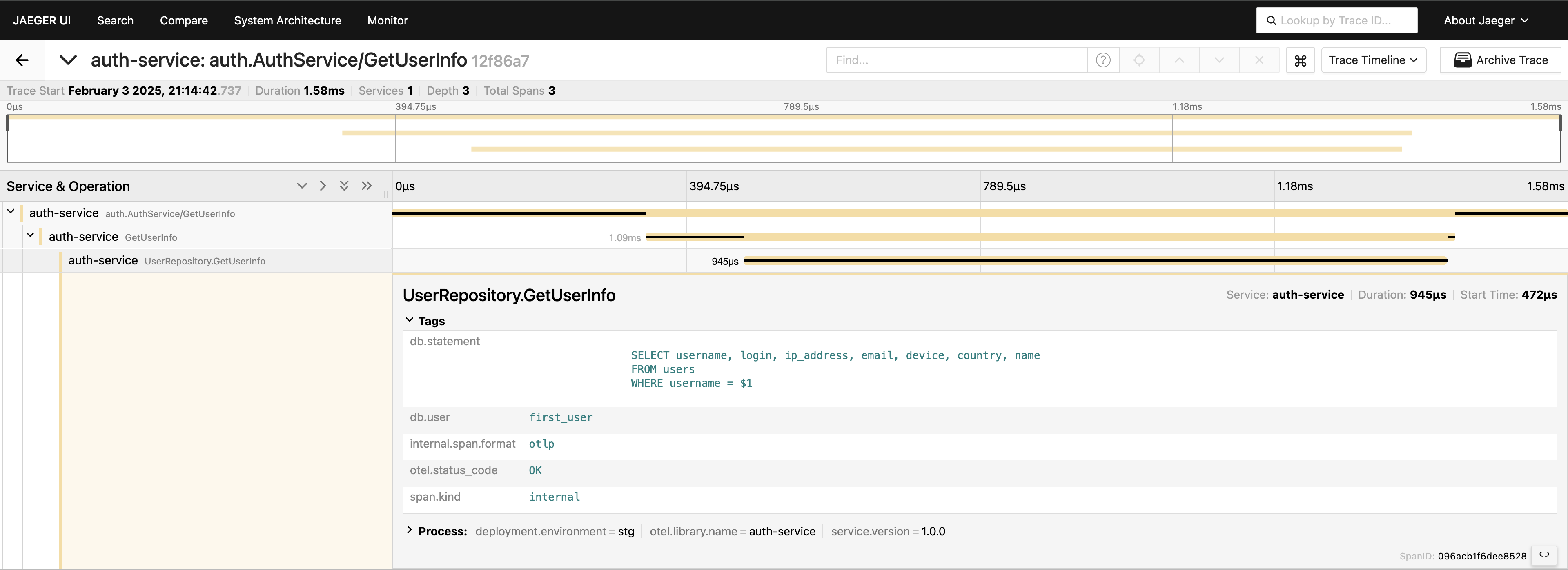
今、すべてが見えるようになりました。必要な場合は、クエリ全体をタグに含めることができます。ただし、テレメトリを過負荷にしないように注意してください。データを慎重に追加してください。私は単に可能なことを示しているだけですが、通常はこの方法でクエリ全体を含めることはお勧めしません。
gRPCクライアントサーバ

2つのgRPCサービスにまたがるトレースを見たい場合、非常に簡単です。必要なのは、ライブラリから提供されているインターセプターを追加するだけです。たとえば、サーバーサイドでは次のようにします:
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
クライアントサイドでは、コードは同じくらい短くなります:
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
それだけです!エクスポーターが正しく構成されていることを確認し、クライアントがサーバーを呼び出すときにこれらのサービス全体で単一のトレースIDが記録されるのを見ることができます。
CDCイベントの処理とトレース
CDCからのイベントを処理したいですか?1つの簡単なアプローチは、MongoDBが保存するオブジェクトにトレースIDを埋め込むことです。これにより、Debeziumが変更をキャプチャしKafkaに送信するときに、トレースIDがレコードの一部としてすでに含まれています。
たとえば、MongoDBを使用している場合、次のようなことができます:
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
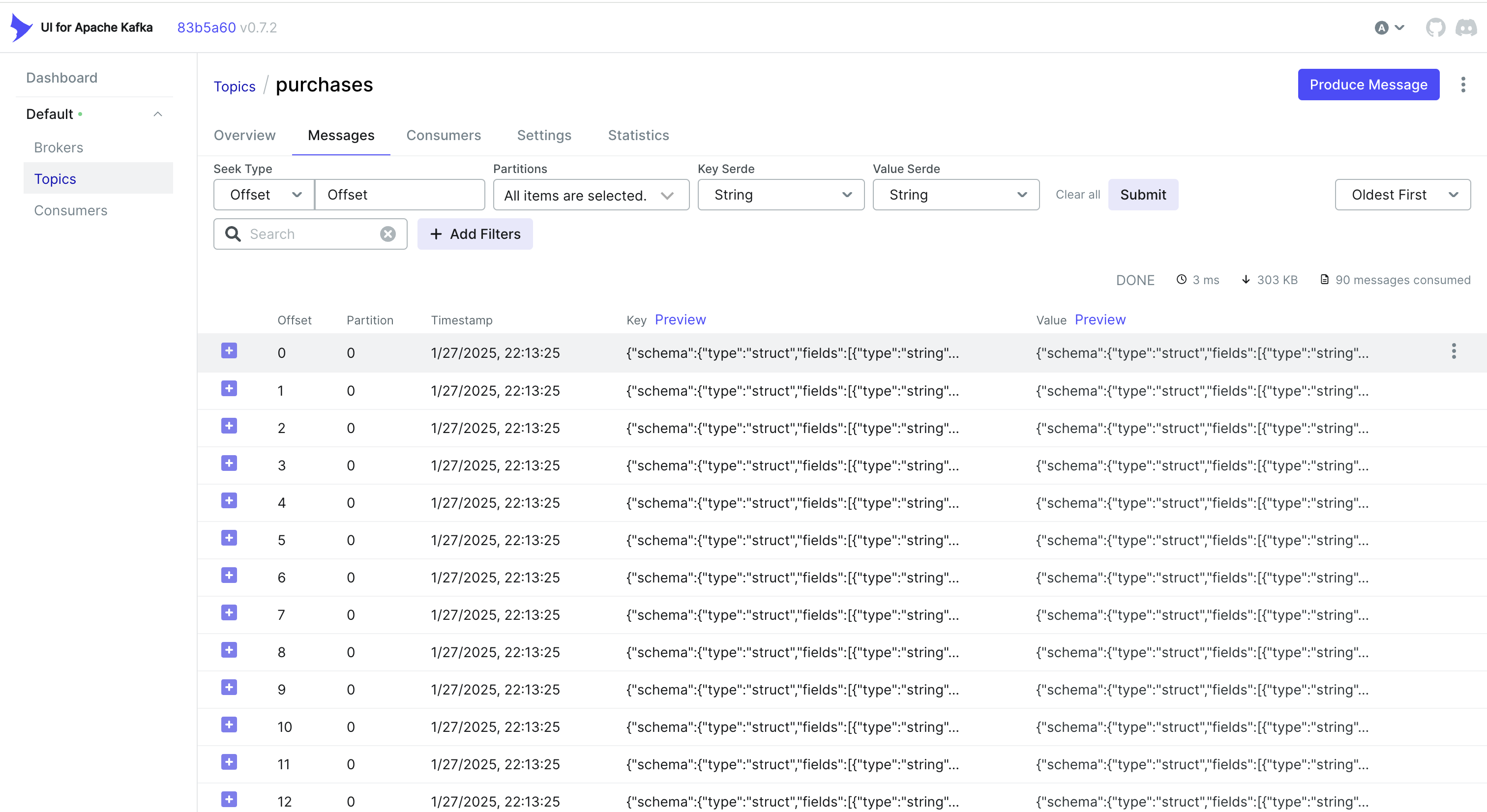
その後、Debeziumはこのオブジェクト(trace_idを含む)を拾い上げ、Kafkaに送信します。コンシューマ側では、受信メッセージを単純に解析し、trace_idを抽出してトレースコンテキストにマージします:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
別の方法:Kafkaヘッダーの使用
時々、Trace IDをペイロード自体ではなく、Kafkaヘッダーに保存する方が簡単です。CDCワークフローでは、これがデフォルトで利用可能ではないことがあります — Debeziumはヘッダーに追加される情報を制限することがあります。しかし、プロデューサーサイドを制御できる場合(または標準のKafkaプロデューサーを使用している場合)、Saramaを使用して次のようなことができます:
ヘッダーへのTrace IDの挿入
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
コンシューマーサイドでのTrace IDの抽出
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
ユースケースやCDCパイプラインの設定に応じて、最適なアプローチを選択できます:
- データベースレコードにTrace IDを埋め込むことで、CDCを介して自然にフローさせることができます。
- Kafkaヘッダーを使用すると、プロデューサーサイドでより多くの制御が可能になり、メッセージペイロードの膨張を避けることができます。
いずれの場合も、KafkaとDebeziumを介して非同期に処理されるイベントでも、複数のサービス間でトレースを一貫させることができます。
結論
OpenTelemetryとJaegerを使用することで、詳細なリクエストトレースを提供し、分散システムで遅延が発生する原因や場所を特定するのに役立ちます。
Prometheusを追加することで、メトリクス(パフォーマンスや安定性の主要な指標)も含めることができます。これらのツールを組み合わせることで、包括的な観測スタックが形成され、より迅速な問題検出と解決、パフォーマンスの最適化、システム全体の信頼性が実現されます。
このアプローチは、マイクロサービス環境でのトラブルシューティングを大幅に加速し、プロジェクトに実装する最初のアプローチの1つです。

リンク
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus