













Lassen Sie uns eine wichtige Frage diskutieren: wie überwachen wir unsere Dienste, wenn etwas schief geht?
Auf der einen Seite haben wir Prometheus mit Warnmeldungen und Kibana für Dashboards und andere nützliche Funktionen. Wir wissen auch, wie wir Protokolle sammeln – der ELK-Stack ist unsere Lösung. Allerdings reichen einfache Protokollierungen nicht immer aus: Sie bieten keinen ganzheitlichen Blick auf die Reise einer Anfrage über das gesamte Ökosystem der Komponenten hinweg.
Weitere Informationen zu ELK finden Sie hier.
Aber was ist, wenn wir Anfragen visualisieren möchten? Was ist, wenn wir Anfragen korrelieren müssen, die zwischen Systemen unterwegs sind? Dies gilt sowohl für Mikrodienste als auch für Monolithen – es spielt keine Rolle, wie viele Dienste wir haben; wichtig ist, wie wir ihre Latenz verwalten.
In der Tat kann jede Benutzeranfrage eine ganze Reihe unabhängiger Dienste, Datenbanken, Nachrichtenwarteschlangen und externer APIs durchlaufen.
In einer so komplexen Umgebung wird es äußerst schwierig, genau zu bestimmen, wo Verzögerungen auftreten, zu identifizieren, welcher Teil der Kette als Leistungsengpass fungiert, und schnell die Ursache von Fehlern zu finden, wenn sie auftreten.
Um diesen Herausforderungen effektiv zu begegnen, benötigen wir ein zentrales, konsistentes System zur Erfassung von Telemetriedaten – Traces, Metriken und Protokollen. Hier kommen OpenTelemetry und Jaeger zur Rettung.
Schauen wir uns die Grundlagen an
Es gibt zwei Hauptbegriffe, die wir verstehen müssen:
Trace-ID
Eine Trace-ID ist ein 16-Byte-Identifikator, der oft als 32-stelliger hexadezimaler String dargestellt wird. Sie wird automatisch zu Beginn eines Traces generiert und bleibt über alle von einer bestimmten Anfrage erstellten Spans gleich. Dies erleichtert es, nachzuvollziehen, wie eine Anfrage durch verschiedene Dienste oder Komponenten in einem System läuft.
Span-ID
Jede einzelne Operation innerhalb eines Traces erhält ihre eigene Span-ID, die typischerweise ein zufällig generierter 64-Bit-Wert ist. Spans teilen sich die gleiche Trace-ID, aber jeder hat eine einzigartige Span-ID, sodass Sie genau bestimmen können, welcher Teil des Workflows durch jeden Span dargestellt wird (wie eine Datenbankabfrage oder einen Aufruf an einen anderen Mikrodienst).
Wie hängen sie zusammen?
Trace-ID und Span-IDergänzen sich.
Wenn eine Anfrage initiiert wird, wird eine Trace-ID generiert und an alle beteiligten Dienste weitergegeben. Jeder Dienst erstellt wiederum einen Span mit einer einzigartigen Span-ID, die mit der Trace-ID verknüpft ist, sodass Sie den gesamten Lebenszyklus der Anfrage von Anfang bis Ende visualisieren können.
Okay, warum nicht einfach Jaeger verwenden? Warum brauchen wir OpenTelemetry (OTEL) und all seine Spezifikationen? Das ist eine großartige Frage! Lassen Sie uns das Schritt für Schritt aufschlüsseln.
Erfahren Sie mehr über Jaeger hier.
Zusammenfassung
- Jaeger ist ein System zum Speichern und Visualisieren verteilter Spuren. Es sammelt, speichert, durchsucht und zeigt Daten an, die zeigen, wie Anfragen durch Ihre Dienste „reisen“.
- OpenTelemetry (OTEL) ist ein Standard (und eine Sammlung von Bibliotheken) zum Sammeln von Telemetriedaten (Spuren, Metriken, Protokolle) aus Ihren Anwendungen und Ihrer Infrastruktur. Es ist nicht an ein einzelnes Visualisierungstool oder Backend gebunden.
Vereinfacht gesagt:
- OTEL ist wie eine „universelle Sprache“ und eine Sammlung von Bibliotheken zum Sammeln von Telemetriedaten.
- Jaeger ist ein Backend und eine Benutzeroberfläche zum Anzeigen und Analysieren verteilter Spuren.
Warum brauchen wir OTEL, wenn wir bereits Jaeger haben?
1. Ein einheitlicher Standard für die Sammlung
In der Vergangenheit gab es Projekte wie OpenTracing und OpenCensus. OpenTelemetry vereint diese Ansätze zur Sammlung von Metriken und Spuren in einem universellen Standard.
2. Einfache Integration
Sie schreiben Ihren Code in Go (oder einer anderen Sprache), fügen OTEL-Bibliotheken zum automatischen Injizieren von Interceptoren und Spans hinzu, und das war’s. Danach ist es egal, wohin Sie diese Daten senden möchten – Jaeger, Tempo, Zipkin, Datadog, ein benutzerdefiniertes Backend – OpenTelemetry kümmert sich um die Verkabelung. Sie wechseln einfach den Exporteur.
3. Nicht nur Spuren
OpenTelemetry deckt Spuren ab, aber es behandelt auch Metriken und Protokolle. Sie haben am Ende ein einziges Werkzeugset für all Ihre Telemetriebedürfnisse, nicht nur zum Tracing.
4. Jaeger als Backend
Jaeger ist eine ausgezeichnete Wahl, wenn Sie hauptsächlich an der Visualisierung von verteiltem Tracing interessiert sind. Aber es bietet standardmäßig keine plattformübergreifende Instrumentierung. OpenTelemetry hingegen gibt Ihnen eine standardisierte Möglichkeit, Daten zu sammeln, und dann entscheiden Sie, wohin Sie sie senden (einschließlich Jaeger).
In der Praxis arbeiten sie oft zusammen:
Ihre Anwendung verwendet OpenTelemetry → kommuniziert über das OTLP-Protokoll → geht zum OpenTelemetry Collector (HTTP oder grpc) → exportiert nach Jaeger zur Visualisierung.
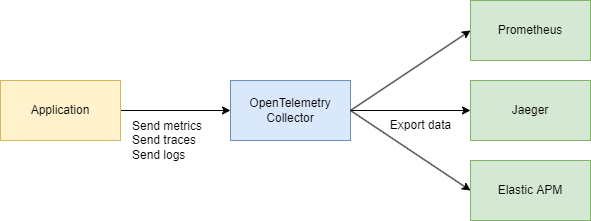
Technischer Teil
Systemdesign (Ein bisschen)
Lassen Sie uns schnell ein paar Dienste skizzieren, die Folgendes tun:
- Kaufdienst – verarbeitet eine Zahlung und zeichnet sie in MongoDB auf
- CDC mit Debezium – hört auf Änderungen in der MongoDB-Tabelle und sendet sie an Kafka
- Kaufverarbeiter – konsumiert die Nachricht von Kafka und ruft den Auth-Dienst auf, um die
user_idzur Validierung abzurufen - Auth-Dienst – ein einfacher Benutzerdienst
Zusammenfassend:
- 3 Go-Dienste
- Kafka
- CDC (Debezium)
- MongoDB
Code-Teil
Fangen wir mit der Infrastruktur an. Um alles zu einem System zusammenzuführen, erstellen wir eine große Docker Compose-Datei. Wir beginnen mit der Einrichtung der Telemetrie.
Hinweis: Der gesamte Code ist über einen Link am Ende des Artikels verfügbar, einschließlich der Infrastruktur.
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
Wir werden auch den Collector konfigurieren – die Komponente, die Telemetrie sammelt.
Hier wählen wir gRPC für den Datentransfer, was bedeutet, dass die Kommunikation über HTTP/2 erfolgt:
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
Stellen Sie sicher, dass Sie alle Adressen nach Bedarf anpassen, und Sie sind mit der Grundkonfiguration fertig.
Wir wissen bereits, dass OpenTelemetry (OTEL) zwei Schlüsselkonzepte verwendet – Trace-ID und Span-ID – die helfen, Anfragen in verteilten Systemen zu verfolgen und zu überwachen.
Implementierung des Codes
Jetzt schauen wir uns an, wie wir das in Ihrem Go-Code zum Laufen bringen können. Wir benötigen die folgenden Importe:
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
Dann fügen wir eine Funktion hinzu, um unseren Tracer in main() beim Start der Anwendung zu initialisieren:
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
Mit dem eingerichteten Tracing müssen wir nur noch Spans im Code platzieren, um die Aufrufe zu verfolgen. Zum Beispiel, wenn wir Datenbankaufrufe messen wollen (da dies normalerweise der erste Ort ist, an dem wir nach Leistungsproblemen suchen), können wir etwas wie das hier schreiben:
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
Wir haben das Tracing auf der Service-Ebene – großartig! Aber wir können sogar noch tiefer gehen und die Datenbankebene instrumentieren:
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
Jetzt haben wir eine vollständige Sicht auf die Reise der Anfrage. Gehen Sie zur Jaeger-Benutzeroberfläche, fragen Sie die letzten 20 Traces unter auth-service ab, und Sie sehen alle Spans und wie sie an einem Ort verbunden sind.
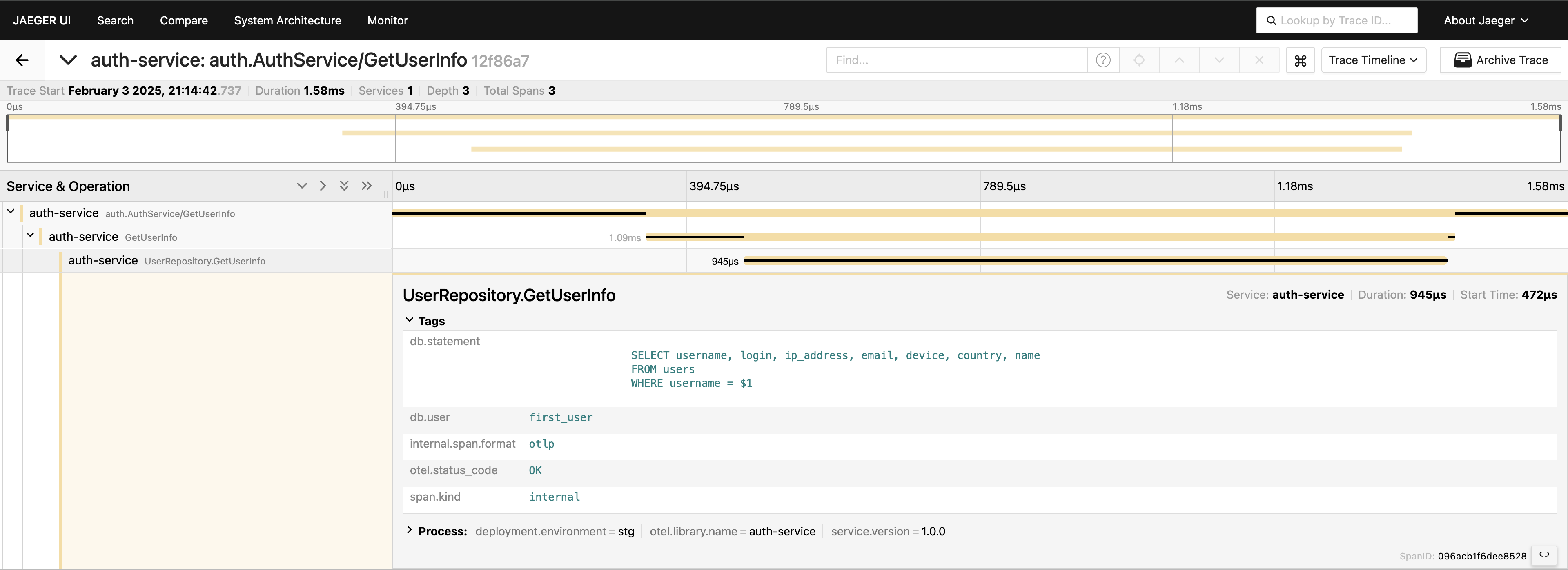
Jetzt ist alles sichtbar. Wenn Sie es benötigen, können Sie die gesamte Abfrage in die Tags einfügen. Bedenken Sie jedoch, dass Sie Ihre Telemetrie nicht überladen sollten — fügen Sie Daten absichtlich hinzu. Ich zeige einfach, was möglich ist, aber die vollständige Abfrage auf diese Weise einzuschließen, ist etwas, das ich im Allgemeinen nicht empfehlen würde.
gRPC-Client-Server

Wenn Sie einen Trace sehen möchten, der sich über zwei gRPC-Dienste erstreckt, ist das ganz einfach. Alles, was Sie tun müssen, ist, die sofort einsatzbereiten Interceptor aus der Bibliothek hinzuzufügen. Zum Beispiel auf der Serverseite:
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
Auf der Clientseite ist der Code ebenso kurz:
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
Das ist alles! Stellen Sie sicher, dass Ihre Exporteure korrekt konfiguriert sind, und Sie werden eine einzige Trace-ID sehen, die über diese Dienste protokolliert wird, wenn der Client den Server aufruft.
Verarbeiten von CDC-Ereignissen und Tracing
Möchten Sie auch Ereignisse aus dem CDC verarbeiten? Ein einfacher Ansatz besteht darin, die Trace-ID in das Objekt einzubetten, das MongoDB speichert. Auf diese Weise ist die Trace-ID bereits Teil des Datensatzes, wenn Debezium die Änderung erfasst und an Kafka sendet.
Wenn Sie beispielsweise MongoDB verwenden, können Sie so etwas tun:
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
Debezium nimmt dann dieses Objekt (einschließlich trace_id) auf und sendet es an Kafka. Auf der Consumer-Seite analysieren Sie einfach die eingehende Nachricht, extrahieren die trace_id und fügen sie in Ihren Tracing-Kontext ein:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
Alternative: Verwendung von Kafka-Headern
Manchmal ist es einfacher, die Trace-ID in Kafka-Headern zu speichern, anstatt im Payload selbst. Für CDC-Workflows ist dies möglicherweise nicht standardmäßig verfügbar — Debezium kann einschränken, was zu Headern hinzugefügt wird. Aber wenn Sie die Produzenten-Seite kontrollieren (oder wenn Sie einen Standard-Kafka-Produzenten verwenden), können Sie etwas wie folgt mit Sarama tun:
Eine Trace-ID in Headern injizieren
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
Eine Trace-ID auf der Verbraucherseite extrahieren
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
Je nach Anwendungsfall und wie Ihre CDC-Pipeline eingerichtet ist, können Sie den Ansatz wählen, der am besten funktioniert:
- Die Trace-ID im Datenbankeintrag einbetten, damit sie natürlich über CDC fließt.
- Verwenden Sie Kafka-Header, wenn Sie mehr Kontrolle über die Produzenten-Seite haben oder wenn Sie vermeiden möchten, das Nachrichten-Payload aufzublähen.
So oder so können Sie Ihre Traces über mehrere Dienste hinweg konsistent halten — selbst wenn Ereignisse asynchron über Kafka und Debezium verarbeitet werden.
Fazit
Die Verwendung von OpenTelemetry und Jaeger liefert detaillierte Anfrage-Trace-Daten, die Ihnen helfen, herauszufinden, wo und warum Verzögerungen in verteilten Systemen auftreten.
Die Hinzufügung von Prometheus vervollständigt das Bild mit Metriken — wichtigen Indikatoren für Leistung und Stabilität. Zusammen bilden diese Werkzeuge einen umfassenden Observabilitäts-Stack, der schnellere Problemerkennung und -lösung, Leistungsoptimierung und die allgemeine Zuverlässigkeit des Systems ermöglicht.
Ich kann sagen, dass dieser Ansatz die Fehlersuche in einer Mikroservices-Umgebung erheblich beschleunigt und eines der ersten Dinge ist, die wir in unseren Projekten umsetzen.

Links
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus