













De grote virtuele infrastructuren van vandaag genereren een enorme hoeveelheid gegevens. Dit leidt tot een toename van back-upgegevens en tot uitgaven aan back-upopslaginfrastructuur, inclusief opslagapparaten en hun onderhoud. Om deze reden zoeken netwerkbeheerders naar manieren om opslagruimte te besparen bij het maken van frequente back-ups van kritieke machines en toepassingen.
Een van de veelgebruikte technieken is back-up deduplicatie. In deze blogpost wordt behandeld wat gegevensdeduplicatie is, deduplicatietypen en gebruiksscenario’s met een focus op back-ups.
Wat Is Deduplicatie?
Gegevensdeduplicatie is een technologie voor het optimaliseren van opslagcapaciteit. Gegevensdeduplicatie omvat het lezen van de brongegevens en de gegevens die al in opslag zijn om alleen unieke gegevensblokken over te dragen of op te slaan. Verwijzingen naar de dubbele gegevens worden gehandhaafd. Door deze technologie te gebruiken om duplicaten op een volume te vermijden, kunt u schijfruimte besparen en de opslagoverhead verminderen.
Oorsprong van gegevensdeduplicatie
De voorlopers van gegevensdeduplicatie zijn de LZ77- en LZ78-compressiealgoritmen die respectievelijk in 1977 en 1978 zijn geïntroduceerd. Ze omvatten het vervangen van herhaalde gegevensreeksen door verwijzingen naar de originele gegevens.
Dit concept heeft andere populaire compressiemethoden beïnvloed. De bekendste hiervan is DEFLATE, dat wordt gebruikt in PNG-afbeeldings- en ZIP-bestandsindelingen. Laten we nu kijken hoe deduplicatie werkt met VM-back-ups en hoe het precies helpt om opslagruimte te besparen en kosten te besparen die worden besteed aan infrastructuur.
Wat is Deduplicatie in Back-up?
Tijdens een back-up controleert gegevens deduplicatie op identieke datablokken tussen de brondopslag en het doelback-uprepository. Duplicaten worden niet gekopieerd en er wordt een verwijzing of pointer naar de bestaande datablokken in de doelback-upopslag gemaakt.
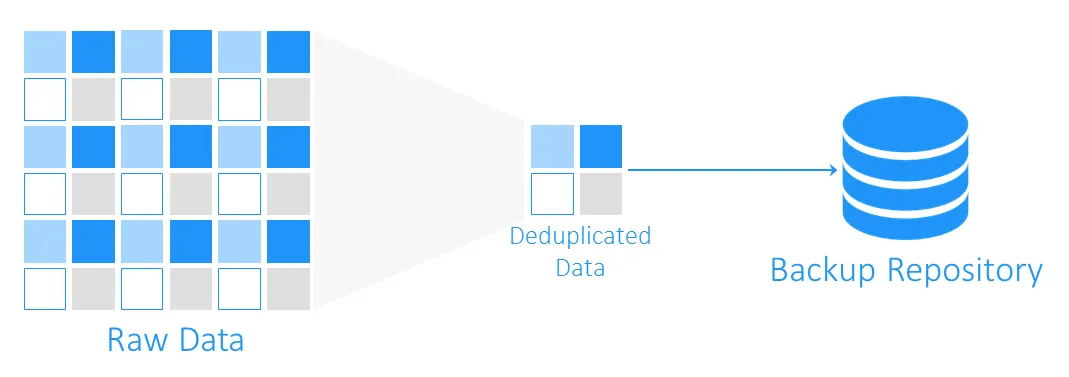
Hoeveel ruimte kan gegevensdeduplicatie u besparen?
Om te begrijpen hoeveel opslagruimte kan worden bespaard met deduplicatie, laten we een voorbeeld bekijken. De minimale systeemvereisten voor het installeren van Windows Server 2016 is minimaal 32 GB vrije schijfruimte. Als u tien VM’s met dit besturingssysteem draait, bedragen de back-ups minimaal 320 GB, en dit is alleen een schoon besturingssysteem zonder enige toepassingen of databases erop.
Het is waarschijnlijk dat als u meer dan één virtuele machine (VM) met hetzelfde systeem moet implementeren, u een sjabloon zult gebruiken, en dit betekent dat u aanvankelijk tien identieke machines zult hebben. En dit betekent ook dat u 10 sets duplicaatdatablokken zult krijgen. In dit voorbeeld heeft u een opslagruimtebesparingsratio van 10:1. Over het algemeen worden besparingen variërend van 5:1 tot 10:1 als goed beschouwd.
Gegevens Deduplicatie Ratio
De data-deduplicatieverhouding is een metriek die wordt gebruikt om de oorspronkelijke gegevensgrootte te meten ten opzichte van de grootte van de gegevens nadat redundante delen zijn verwijderd. Met deze metriek kunt u de effectiviteit van het data-deduplicatieproces beoordelen. Om de waarde te berekenen, moet u de hoeveelheid gegevens vóór deduplicatie delen door de opslagruimte die deze gegevens na deduplicatie in beslag neemt.
Bijvoorbeeld, de deduplicatieverhouding van 5:1 betekent dat u vijf keer meer geback-upte gegevens kunt opslaan in uw back-upopslag dan nodig is om dezelfde gegevens zonder deduplicatie op te slaan.
U moet de deduplicatieverhouding en opslagruimtereductie bepalen. Deze twee parameters worden soms verward. Deduplicatieverhoudingen veranderen niet evenredig met de voordelen van gegevensreductie, omdat het beginsel van afnemende meeropbrengsten een rol speelt na een bepaald punt. Zie de onderstaande grafiek.
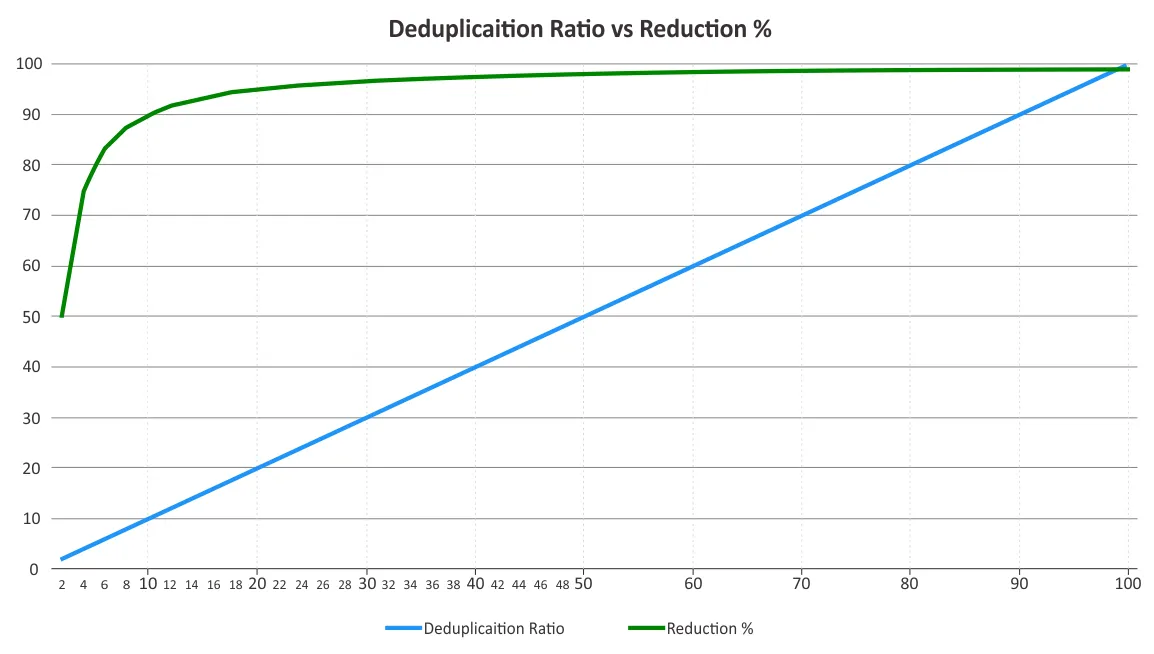
Dit betekent dat lagere verhoudingen aanzienlijk meer besparingen kunnen opleveren dan een hogere verhouding. Bijvoorbeeld, een deduplicatieverhouding van 50:1 is niet vijf keer beter dan een verhouding van 10:1. De verhouding van 10:1 zorgt voor een reductie van 90% van de gebruikte opslagruimte, terwijl de verhouding van 50:1 deze waarde verhoogt naar 98%, aangezien het grootste deel van de redundantie al is geëlimineerd. Voor meer informatie over hoe deze percentages worden berekend, kunt u de documentatie van de Storage Networking Industry Association (SNIA) over data-deduplicatie raadplegen.
Factoren die van invloed zijn op de efficiëntie van data-deduplicatie
Het is moeilijk om de efficiëntie van gegevensreductie te voorspellen totdat de gegevens daadwerkelijk zijn gededupliceerd vanwege verschillende factoren. Enkele van de factoren die van invloed zijn op gegevensreductie bij het gebruik van deduplicatie zijn onder andere:
- Back-uptypen en -beleid. Deduplicatie voor volledige back-ups is effectiever dan voor incrementele of differentiële back-ups.
- Veranderingspercentage. Als er veel gegevenswijzigingen zijn om een back-up van te maken, is de deduplicatieratio lager.
- Bewaarinstellingen. Hoe langer u gegevensback-ups opslaat in back-upopslag, hoe effectiever de deduplicatie van gegevens op deze opslag kan zijn.
- Gegevenstype. Deduplicatie voor bestanden waarin gegevens al zijn gecomprimeerd, zoals JPG, PNG, MPG, AVI, MP4, ZIP, RAR, enz., is niet effectief. Hetzelfde geldt voor metagegevensrijke en versleutelde gegevens. Gegevenstypen die repetitieve delen bevatten, zijn beter geschikt voor deduplicatie.
- Gegevensbereik. Gegevensdeduplicatie is effectiever voor een groot gegevensbereik. Globale deduplicatie kan meer opslagruimte besparen in vergelijking met lokale deduplicatie.
Opmerking: Lokale deduplicatie werkt op een enkele node/schijfapparaat. Globale deduplicatie analyseert de hele dataset op alle nodes/schijfapparaten om gegevensduplicaten te elimineren. Als u meerdere nodes heeft met lokale deduplicatie ingeschakeld op elk ervan, zou deduplicatie niet zo efficiënt zijn als wanneer globale deduplicatie voor hen is ingeschakeld.
- Software en hardware. Het combineren van softwareoplossingen en deduplicatiehardware kan betere deduplicatieratio’s bieden dan alleen software. Bijvoorbeeld, de back-upoplossing van NAKIVO biedt integratie met HP StoreOnce, Dell EMC Data Domain en NEC HYDRAstor deduplicatie-apparaten voor deduplicatieratio’s tot 17:1.
Back-up Deduplicatietechnieken
De back-up deduplicatietechnieken kunnen worden gecategoriseerd op basis van het volgende:
- Waar gegevensdeduplicatie wordt uitgevoerd
- Wanneer de deduplicatie wordt uitgevoerd
- Hoe deduplicatie wordt uitgevoerd
Waar gegevensdeduplicatie wordt uitgevoerd
Back-up deduplicatie kan worden uitgevoerd aan de bronkant of aan de doelkant, en die technieken worden respectievelijk bronkantdeduplicatie en doelkantdeduplicatie genoemd.
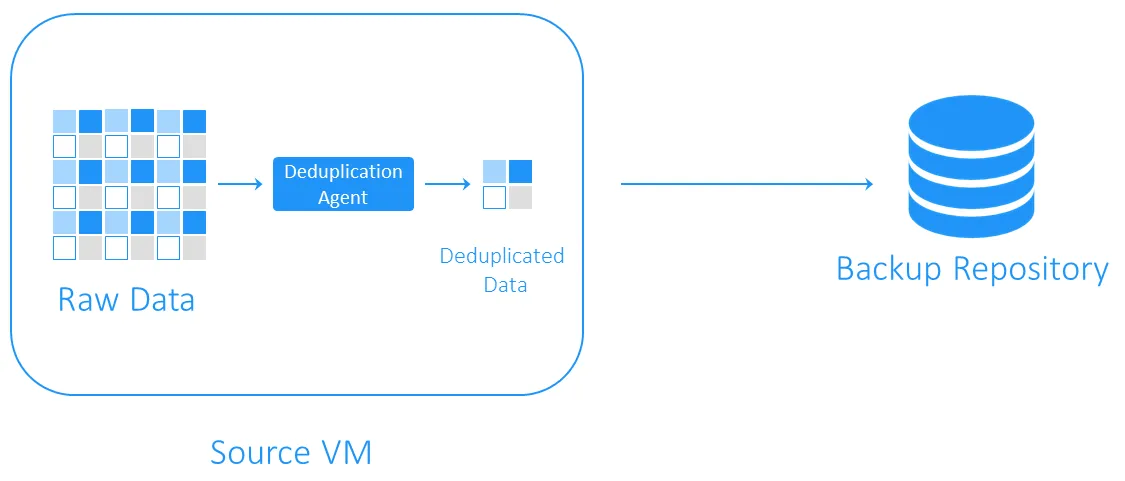
Bronkantdeduplicatie;
Bronzijde deduplicatie vermindert de netwerkbelasting omdat er minder gegevens worden overgedragen tijdens de back-up. Het vereist echter dat er een deduplicatie-agent wordt geïnstalleerd op elke VM of op elke host. Het andere nadeel is dat bronzijde deduplicatie VM’s kan vertragen vanwege de berekeningen die nodig zijn voor de identificatie van duplicaatgegevensblokken.
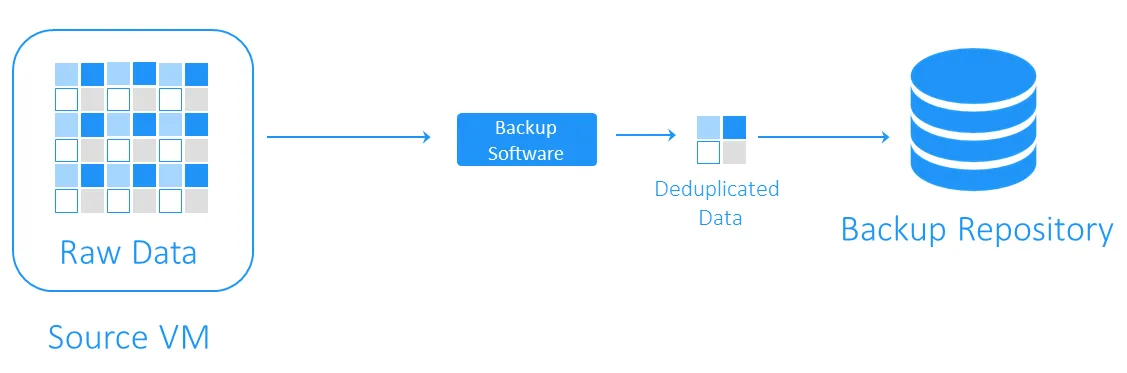
Doelzijde deduplicatie
Doelzijde deduplicatie verplaatst eerst de gegevens naar het back-uprepository en voert vervolgens deduplicatie uit. De zware rekenkundige taken worden uitgevoerd door de software die verantwoordelijk is voor deduplicatie.
Wanneer gegevensdeduplicatie wordt uitgevoerd
Back-updeduplicatie kan inline of post-processing zijn.
- Inline deduplicatie controleert op gegevensduplicaten voordat ze naar een back-uprepository worden geschreven. Deze techniek vereist minder opslagruimte in een back-uprepository omdat het de back-upgegevensstroom vrijmaakt van redundanties, maar dit resulteert in langere back-uptijden omdat de inline deduplicatie plaatsvindt tijdens de back-uptaak.
- Post-processing deduplicatie verwerkt gegevens nadat ze naar het back-uprepository zijn geschreven. Deze aanpak vereist uiteraard meer vrije ruimte in het repository, maar back-ups worden sneller uitgevoerd en alle noodzakelijke bewerkingen worden achteraf uitgevoerd. Post-processing deduplicatie wordt ook wel asynchrone deduplicatie genoemd.
Hoe gegevensdeduplicatie wordt uitgevoerd
De meest voorkomende methoden om duplicaten te identificeren zijn de op hash gebaseerde en gemodificeerde op hash gebaseerde methoden.
- Met de hash-gebaseerde methode verdeelt de deduplicatiesoftware gegevens in blokken van vaste of variabele lengte en berekent een hash voor elk van hen met behulp van cryptografische algoritmen zoals MD5, SHA-1 of SHA-256. Elk van deze methoden levert een unieke vingerafdruk van de datablokken op, dus de blokken met vergelijkbare hashes worden als identiek beschouwd. Het nadeel van deze methode is dat het aanzienlijke rekencapaciteit kan vereisen, vooral bij grote back-ups.
- De aangepaste hash-gebaseerde methode gebruikt eenvoudigere hash-genererende algoritmen zoals CRC, die slechts 16 bits produceren (in vergelijking met 256 bits in SHA-256). Vervolgens worden, als de blokken vergelijkbare hashes hebben, ze byte voor byte vergeleken. Als ze volledig identiek zijn, worden de blokken als identiek beschouwd. Deze methode is iets langzamer dan de hash-gebaseerde methode, maar vereist minder rekencapaciteit.
Het kiezen van deduplicatiesoftware voor back-ups
Deduplicatie van back-ups is een van de meest populaire toepassingen van deduplicatie. Toch moet je de juiste softwareoplossing en hardware voor opslag hebben om deze gegevensverminderende technologie te implementeren.
NAKIVO Backup & Replication is een back-upoplossing die het gebruik van wereldwijde post-processing deduplicatie met aangepaste hash-gebaseerde duplicaatdetectie ondersteunt. Je kunt ook profiteren van source-side deduplicatie door een deduplicatie-appliance, zoals DELL EMC Data Domain met DD Boost, NEC HYDRAstor en HP StoreOnce met Catalyst-ondersteuning, te integreren met de NAKIVO-oplossing.
Source:
https://www.nakivo.com/blog/backup-deduplication-explained/