













Probleemstelling
De “waarom” van deze AI-oplossing is erg belangrijk en verspreid over meerdere gebieden.
Imagineer dat u meerdere gescande PDF-documenten heeft:
- Waar klanten enkele handmatige selecties maken, een handtekening/data/klantgegevens toevoegen
- U heeft meerdere pagina’s geschreven documentatie die zijn gescand en een oplossing zoekt die tekst uit deze documenten verkrijgt
OF
- U zoekt een AI-ondersteund kanaal dat een interactieve mechanismus biedt om documenten op te vragen die geen gestructureerd formaat hebben
Het werken met zulke gescande/gemengde/ongestructureerde documenten kan lastig zijn, en het uit trekken van belangrijke informatie ervan kan handmatig zijn, dus gevoelig voor fouten en langzaam.
De onderstaande oplossing gebruikt de kracht van OCR (Optische Character Recognition) en LLM (Grote Taalkiezen Modelle) om tekst uit zulke documenten te verkrijgen en ze aan te vragen om gestructureerde vertrouwelijke informatie te verkrijgen.
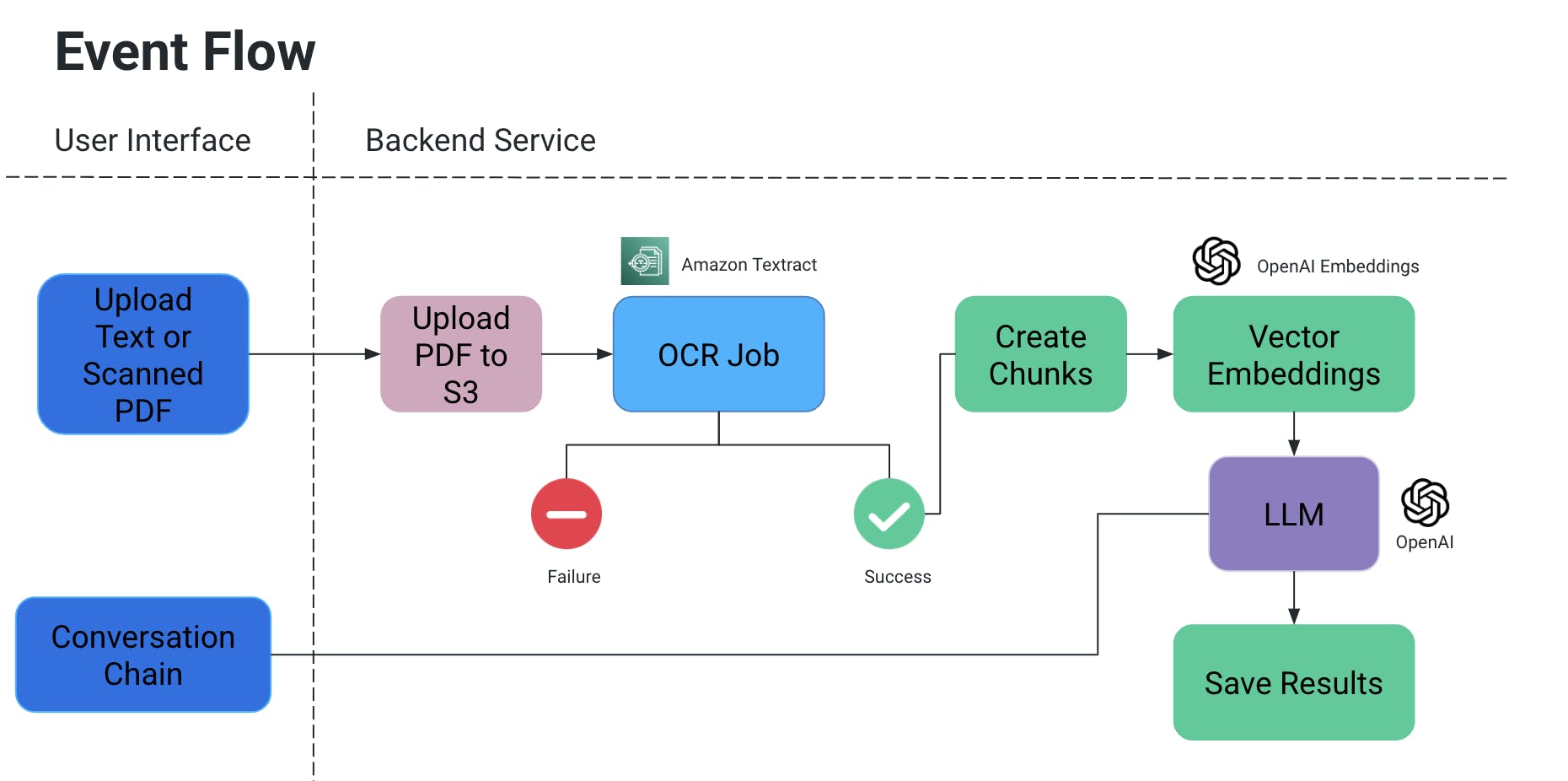
Hoog niveau architectuur
Gebruikersinterface
- Met de gebruikersinterface kunnen PDF/Gescande documenten worden geüpload (dit kan worden uitgebreid naar andere documenttypes).
- Streamlit wordt gebruikt voor de gebruikersinterface:
- Het is een open-source Python framework en is zeer eenvoudig te gebruiken.
- Als er veranderingen worden doorgevoerd, worden deze gereflecteerd in de lopende apps, waardoor dit een snel testmechanisme is.
- De ondersteuning van de gemeenschap voor Streamlit is redelijk sterk en groeiende.
- Conversatieketen:
- Dit is in wezen nodig om chatbots op te nemen die vervolgvragen kunnen beantwoorden en de chatgeschiedenis kunnen weergeven.
- We maken gebruik van LangChain voor de interface met het AI-model dat we gebruiken; voor dit project hebben we getest met OpenAI en Mistral AI.
Backenddienst
Gebeurtenisverloop
- De gebruiker uploadt een PDF/scandocument, dat vervolgens wordt geupload naar een S3-opslagbucket.
- Een OCR-dienst haalt vervolgens dit bestand van de S3-opslagbucket en verwerkt het om tekst uit dit document te extraheren.
- Tekstfragmenten worden aangemaakt uit de bovenstaande uitvoer, en bijbehorende vectorachtingsreeksen voor hen worden aangemaakt.
- Hier is dit erg belangrijk omdat u context niet wilt verliezen wanneer fragmenten worden gesplitst: ze kunnen in het midden van een zin worden gesplitst, zonder sommige punctuele elementen kan de betekenis verloren gaan, enzovoort.
- Daarom proberen we overlappende fragmenten te maken.
- Het grote taalmodel dat we gebruiken neemt deze embeddings als invoer en we hebben twee functionaliteiten:
- Specifieke uitvoer genereren:
-
Als we een specifiek soort informatie hebben die uit documenten moet worden gehaald, kunnen we een query in code aan het AI-model geven, gegevens verkrijgen en deze in een gestructureerd formaat opslaan.
- Voorkom AI-hallucinaties door expliciet in-code queries toe te voegen met voorwaarden om bepaalde waarden niet te verzinnen en alleen de context van het document te gebruiken.
- We kunnen het opslaan als een bestand in S3/lokaal OF wegschrijven naar een database.
- Chat
- Hier bieden we de eindgebruiker de mogelijkheid om een chat te starten met AI om specifieke informatie te verkrijgen in de context van het document.
- Specifieke uitvoer genereren:
OCR-taak
- We gebruiken Amazon Textract voor de optische herkenning van deze documenten.
- Het werkt goed met documenten die ook tabellen/formulieren hebben, enzovoort.
- Bij het werken aan een POC, gebruik dan de gratis laag van dit service.
Vector Embeddings
- Een zeer eenvoudige manier om vectorembedding te begrijpen, is om woorden of zinnen in getallen uit te drukken die de betekenis en relaties van dit context
- Verlang je even naar de term “ring” als ornamentechniek: in termen van hetzelfde woord, is een goed match “zing”. Maar in termen van de betekenis van het woord, zou je misschien willen dat het overeenkomt met iets als “jewelry”, “vinger”, “gemstones”, of misschien iets als “hoop”, “cirkel”, enzovoort.
- Daarom, als we vector embedding aanmaken voor “ring”, vullen we het eigenlijk aan met veel informatie over zijn betekenis en relaties.
- Deze informatie, samen met de vector embeddings van andere woorden/uitspraken in een document, zorgt ervoor dat de correcte betekenis van het woord “ring” in context wordt gekozen.
- We hebben OpenAIEmbeddings gebruikt voor het maken van vector embeddings.
LLM
- Er zijn vele grote taalmodellen die kunnen worden gebruikt voor onze scenario’s.
- Binnen het kader van dit project is测试 gedaan met OpenAI en Mistral AI.
- Lees meer hier over API-sleutels voor OpenAI.
- Voor MistralAI is HuggingFace gebruikt.
Gebruiks- en Testgevallen
We hebben de volgende tests uitgevoerd:
- Handgeschreven datums/tekst en handgeselecteerde opties in het document zijn gelezen met OCR.
- Digitale selecties op het document
- Ongestructureerde data die wordt geanalyseerd om tabulaire inhoud te verkrijgen (toevoegen aan bestand/DB, enzovoort)
- Uitzonderingen
Toekomstige scope
We kunnen de toepassingen van bovenstaand project verder uitbreiden door afbeeldingen te integreren, samen te werken met documentatieopslagsystemen zoals Confluence/Drive, etc., om informatie over een specifiek onderwerp uit verschillende bronnen te halen, en een sterker medium aan te bieden voor de kwalitatieve analyse tussen twee documenten, enzovoort.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data