













중요한 질문에 대해 논의해 봅시다: 문제가 발생했을 때 서비스를 어떻게 모니터링할까요?
한편으로는 경보 기능이 있는 Prometheus와 대시보드 및 다른 유용한 기능을 제공하는 Kibana을 사용할 수 있습니다. 또한 우리는 로그를 수집하는 방법을 알고 있습니다 — ELK 스택이 우리의 해결책이 됩니다. 그러나 간단한 로깅만으로 충분하지 않을 수 있습니다: 이는 요청이 전체 구성 요소 생태계를 횡단하는 과정에 대한 종합적인 보기를 제공하지 않기 때문입니다.
ELK에 대한 자세한 정보는 여기에서 찾을 수 있습니다.
그러나 요청을 시각화하고 시스템 간에 이동하는 요청을 연관시켜야 하는 경우는 어떨까요? 이는 마이크로 서비스와 단일체에 적용됩니다 — 서비스가 몇 개인지는 중요하지 않으며, 중요한 것은 지연 시간을 관리하는 방법입니다.
사용자 요청은 독립적인 서비스, 데이터베이스, 메시지 대기열 및 외부 API의 전체 체인을 통과할 수 있습니다.
이러한 복잡한 환경에서는 지연이 발생하는 구체적인 위치를 정확하게 파악하거나 성능 병목 현상으로 작용하는 체인의 어떤 부분인지 식별하고, 장애의 근본 원인을 신속하게 찾는 것이 매우 어려워집니다.
이러한 과제를 효과적으로 해결하기 위해 추적, 메트릭 및 로그와 같은 데이터를 수집하고 통일된 중앙 시스템이 필요합니다. 이것이 OpenTelemetry와 Jaeger가 도움이 되는 곳입니다.
기본 사항을 살펴봅시다
이해해야 할 주요 용어가 두 가지 있습니다:
Trace ID
Trace ID는 16바이트 식별자로, 종종 32자리의 16진수 문자열로 표현됩니다. 이것은 추적 시작시 자동으로 생성되고 특정 요청에 의해 생성된 모든 스팬에서 동일하게 유지됩니다. 이를 통해 요청이 시스템 내의 다른 서비스나 구성 요소를 통해 이동하는 방식을 쉽게 파악할 수 있습니다.
Span ID
추적 내의 각 개별 작업은 고유한 Span ID를 가지며, 일반적으로 무작위로 생성된 64비트 값입니다. 스팬은 동일한 Trace ID를 공유하지만 각각 고유한 Span ID를 가지므로 각 스팬이 어떤 부분을 나타내는지 정확하게 파악할 수 있습니다(예: 데이터베이스 쿼리 또는 다른 마이크로서비스 호출).
이들은 어떻게 관련되어 있나요?
Trace ID 와 Span ID는 서로 보완적입니다.
요청이 시작되면 Trace ID가 생성되어 관련된 모든 서비스로 전달됩니다. 각 서비스는 고유한 Span ID가 Trace ID에 연결된 스팬을 생성하여 요청의 전체 수명주기를 시작부터 끝까지 시각화할 수 있도록 합니다.
그럼, Jaeger를 사용하지 않는 이유는 무엇인가요? OpenTelemetry(OTEL) 및 모든 사양이 필요한 이유는 무엇인가요? 좋은 질문입니다! 단계별로 자세히 살펴보겠습니다.
Jaeger에 대해 더 자세히 알아보려면 여기를 참조하십시오.
요약
- Jaeger는 분산 추적을 저장하고 시각화하는 시스템입니다. 요청이 서비스를 통해 “이동”하는 방식을 보여주는 데이터를 수집, 저장, 검색 및 표시합니다.
- OpenTelemetry (OTEL)은 응용 프로그램 및 인프라에서 텔레메트리 데이터(추적, 메트릭, 로그)를 수집하는 표준(및 라이브러리 세트)입니다. 이는 특정 시각화 도구나 백엔드에 결합되어 있지 않습니다.
간단히 말해:
- OTEL은 텔레메트리 수집을위한 “유니버설 언어” 및 라이브러리 세트입니다.
- Jaeger는 분산 추적을 보고 분석하기위한 백엔드 및 UI입니다.
우리가 이미 Jaeger를 가지고 있다면 왜 OTEL이 필요한 이유입니까?
1. 수집을위한 단일 표준
과거에는 OpenTracing 및 OpenCensus와 같은 프로젝트가 있었습니다. OpenTelemetry은 이러한 메트릭 및 추적 수집 방법을 하나의 범용 표준으로 통합합니다.
2. 쉬운 통합
Go (또는 다른 언어)에서 코드를 작성하고 OTEL 라이브러리를 추가하여 자동 삽입 인터셉터와 스팬을 추가하면 됩니다. 그 후 데이터를 어디로 보내든 상관없습니다. Jaeger, Tempo, Zipkin, Datadog, 사용자 정의 백엔드 – OpenTelemetry가 배관을 처리합니다. 단순히 익스포터를 교체하면 됩니다.
3. 추적뿐만 아니라
OpenTelemetry은 추적을 다루지만 메트릭과 로그도 처리합니다. 추적만이 아닌 모든 텔레메트리 요구에 대한 단일 도구 세트가 만들어집니다.
4. 백엔드로서의 Jaeger
Jaeger는 분산 추적 시각화에 주로 관심이 있는 경우 훌륭한 선택입니다. 그러나 기본적으로 다국어 인스트루먼테이션을 제공하지는 않습니다. 반면에 OpenTelemetry는 데이터 수집을 표준화된 방법으로 제공하고, 데이터를 어디로 보낼지(포함하여 Jaeger)를 결정할 수 있습니다.
귀하의 애플리케이션은 OpenTelemetry를 사용합니다 → OTLP 프로토콜을 통해 통신합니다 → OpenTelemetry 수집기(HTTP 또는 grpc)로 이동합니다 → 시각화를 위해 Jaeger로 내보냅니다.
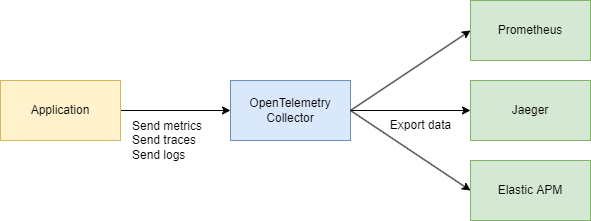
기술 부분
시스템 디자인 (조금)
다음을 수행하는 몇 가지 서비스에 대한 빠른 스케치를 만들어 봅시다:
- 구매 서비스 – 지불을 처리하고 MongoDB에 기록합니다
- Debezium과 CDC – MongoDB 테이블의 변경 사항을 감지하고 Kafka로 전송합니다
- 구매 처리기 – Kafka로부터 메시지를 소비하고 인증 서비스를 호출하여 유효성을 검사하기 위해
user_id를 조회합니다 - 인증 서비스 – 간단한 사용자 서비스
요약하면:
- 3개의 Go 서비스
- Kafka
- CDC (Debezium)
- MongoDB
코드 부분
인프라 구축부터 시작해 봅시다. 모든 것을 하나의 시스템으로 통합하기 위해 큰 Docker Compose 파일을 만들 것입니다. 우선 텔레메트리를 설정해 보겠습니다.
참고: 모든 코드는 인프라를 포함한 기사 끝의 링크를 통해 제공됩니다.
services
jaeger
imagejaegertracing/all-in-one1.52
ports
"6831:6831/udp" # UDP port for the Jaeger agent
"16686:16686" # Web UI
"14268:14268" # HTTP port for spans
networks
internal
prometheus
imageprom/prometheuslatest
volumes
./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports
"9090:9090"
depends_on
kafka
jaeger
otel-collector
command
--config.file=/etc/prometheus/prometheus.yml
networks
internal
otel-collector
imageotel/opentelemetry-collector-contrib0.91.0
command'--config=/etc/otel-collector.yaml'
ports
"4317:4317" # OTLP gRPC receiver
volumes
./otel-collector.yaml:/etc/otel-collector.yaml
depends_on
jaeger
networks
internal
또한 텔레메트리를 수집하는 컬렉터를 구성할 것입니다.
여기서 데이터 전송을 위해 gRPC를 선택했기 때문에 통신은 HTTP/2를 통해 이루어집니다.
receivers
# Add the OTLP receiver listening on port 4317.
otlp
protocols
grpc
endpoint"0.0.0.0:4317"
processors
batch
# https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/memorylimiterprocessor
memory_limiter
check_interval1s
limit_percentage80
spike_limit_percentage15
extensions
health_check
exporters
otlp
endpoint"jaeger:4317"
tls
insecuretrue
prometheus
endpoint0.0.0.09090
debug
verbositydetailed
service
extensionshealth_check
pipelines
traces
receiversotlp
processorsmemory_limiter batch
exportersotlp
metrics
receiversotlp
processorsmemory_limiter batch
exportersprometheus
필요에 따라 주소를 조정하고 기본 구성을 마치면 됩니다.
우리는 이미 OpenTelemetry(OTEL)이 분산 시스템에서 요청을 추적하고 모니터링하는 데 도움이 되는 Trace ID와 Span ID 두 가지 핵심 개념을 사용한다는 것을 알고 있습니다.
코드 구현하기
이제 Go 코드에서 이를 작동시키는 방법을 살펴봅시다. 다음 import가 필요합니다.
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/sdk/resource"
"go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.17.0"
그런 다음 애플리케이션이 시작될 때 main()에서 추적기를 초기화하는 함수를 추가합니다.
func InitTracer(ctx context.Context) func() {
exp, err := otlptrace.New(
ctx,
otlptracegrpc.NewClient(
otlptracegrpc.WithEndpoint(endpoint),
otlptracegrpc.WithInsecure(),
),
)
if err != nil {
log.Fatalf("failed to create OTLP trace exporter: %v", err)
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String("auth-service"),
semconv.ServiceVersionKey.String("1.0.0"),
semconv.DeploymentEnvironmentKey.String("stg"),
),
)
if err != nil {
log.Fatalf("failed to create resource: %v", err)
}
tp := trace.NewTracerProvider(
trace.WithBatcher(exp),
trace.WithResource(res),
)
otel.SetTracerProvider(tp)
return func() {
err := tp.Shutdown(ctx)
if err != nil {
log.Printf("error shutting down tracer provider: %v", err)
}
}
}
추적이 설정되면 코드에 스팬을 배치하여 호출을 추적할 수 있습니다. 예를 들어, 성능 문제를 찾는 데 일반적으로 첫 번째로 살펴보는 데이터베이스 호출을 측정하려면 다음과 같이 작성할 수 있습니다.
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "GetUserInfo")
defer span.End()
tracedLogger := logging.AddTraceContextToLogger(ctx)
tracedLogger.Info("find user info",
zap.String("operation", "find user"),
zap.String("username", username),
)
user, err := s.userRepo.GetUserInfo(ctx, username)
if err != nil {
s.logger.Error(errNotFound)
span.RecordError(err)
span.SetStatus(otelCodes.Error, "Failed to fetch user info")
return nil, status.Errorf(grpcCodes.NotFound, errNotFound, err)
}
span.SetStatus(otelCodes.Ok, "User info retrieved successfully")
서비스 레이어에서 추적이 수행되었습니다. 그러나 데이터베이스 레이어를 계측하여 더 심층적으로 분석할 수도 있습니다.
func (r *UserRepository) GetUserInfo(ctx context.Context, username string) (*models.User, error) {
tracer := otel.Tracer("auth-service")
ctx, span := tracer.Start(ctx, "UserRepository.GetUserInfo",
trace.WithAttributes(
attribute.String("db.statement", query),
attribute.String("db.user", username),
),
)
defer span.End()
var user models.User
// Some code that queries the DB...
// err := doDatabaseCall()
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, "Failed to execute query")
return nil, fmt.Errorf("failed to fetch user info: %w", err)
}
span.SetStatus(codes.Ok, "Query executed successfully")
return &user, nil
}
이제 요청 경로의 전체적인 내용을 파악했습니다. Jaeger UI로 이동하여 auth-service 아래의 마지막 20개의 추적을 쿼리하면 모든 스팬 및 연결 방법이 한 곳에 표시됩니다.
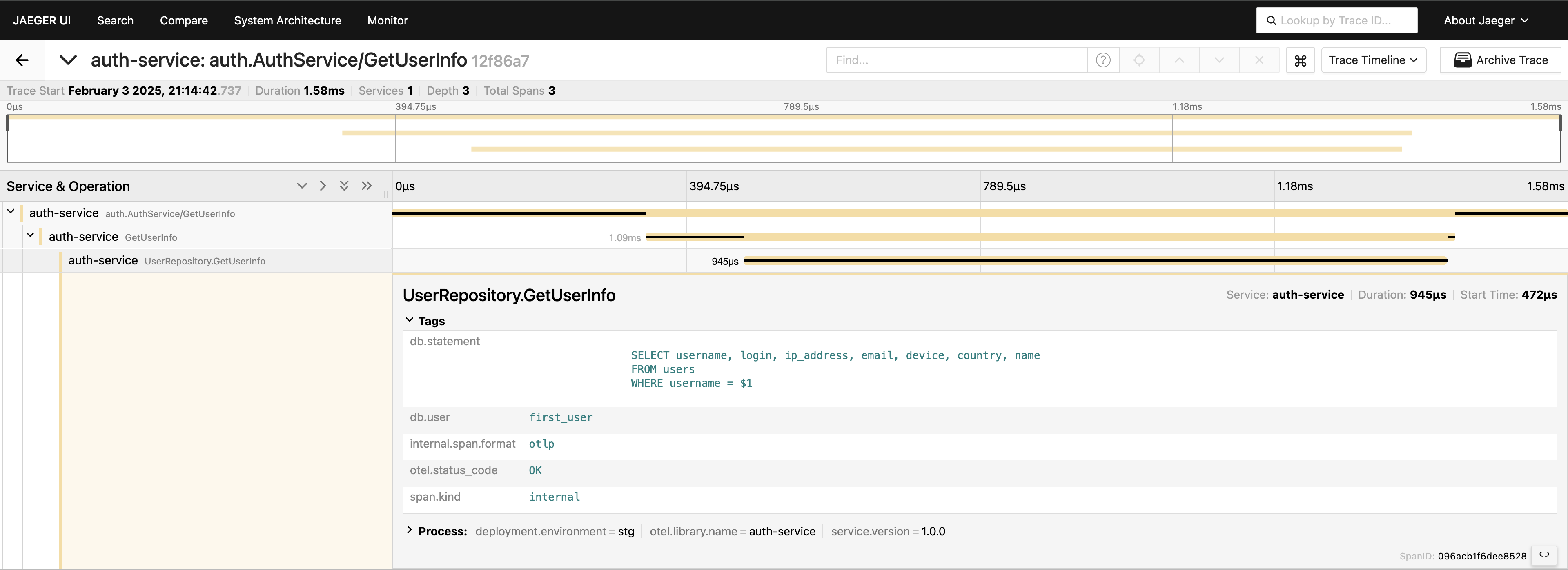
이제 모든 것이 보입니다. 필요하다면 전체 쿼리를 태그에 포함시킬 수 있습니다. 그러나 텔레메트리를 과도하게 추가하지 않도록 주의하십시오. 데이터를 신중하게 추가하십시오. 가능한 것을 보여주기만 하는 것이므로, 일반적으로 이 방식으로 전체 쿼리를 포함하는 것은 권장하지 않습니다.
gRPC 클라이언트-서버

두 개의 gRPC 서비스를 포함하는 추적을 보고 싶다면, 매우 간단합니다. 라이브러리에서 제공하는 기본 인터셉터를 추가하면 됩니다. 예를 들어, 서버 측에서는 다음과 같습니다:
server := grpc.NewServer(
grpc.StatsHandler(otelgrpc.NewServerHandler()),
)
pb.RegisterAuthServiceServer(server, authService)
클라이언트 측에서는 코드가 아주 간결합니다:
shutdown := tracing.InitTracer(ctx)
defer shutdown()
conn, err := grpc.Dial(
"auth-service:50051",
grpc.WithInsecure(),
grpc.WithStatsHandler(otelgrpc.NewClientHandler()),
)
if err != nil {
logger.Fatal("error", zap.Error(err))
}
그게 전부입니다! 익스포터가 올바르게 구성되어 있는지 확인하고, 클라이언트가 서버를 호출할 때 이 서비스들 사이에 기록된 단일 추적 ID를 볼 수 있게 됩니다.
CDC 이벤트 처리 및 추적
CDC에서 이벤트를 처리하고 싶으신가요? 하나의 간단한 접근 방법은 MongoDB가 저장하는 객체에 추적 ID를 내장하는 것입니다. 이렇게 하면 Debezium이 변경 사항을 캡처하고 Kafka로 보낼 때, 추적 ID가 이미 레코드의 일부로 됩니다.
예를 들어, MongoDB를 사용 중이라면, 다음과 같이 할 수 있습니다:
func (r *mongoPurchaseRepo) SavePurchase(ctx context.Context, purchase entity.Purchase) error {
span := r.handleTracing(ctx, purchase)
defer span.End()
// Insert the record into MongoDB, including the current span's Trace ID
_, err := r.collection.InsertOne(ctx, bson.M{
"_id": purchase.ID,
"user_id": purchase.UserID,
"username": purchase.Username,
"amount": purchase.Amount,
"currency": purchase.Currency,
"payment_method": purchase.PaymentMethod,
// ...
"trace_id": span.SpanContext().TraceID().String(),
})
return err
}
그럼 Debezium은 이 객체(포함된 trace_id)를 가져와 Kafka로 보냅니다. 소비자 측에서는 간단히 들어오는 메시지를 파싱하여 trace_id를 추출하고 추적 컨텍스트에 병합하면 됩니다:
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
// If we find a Trace ID in the payload, attach it to the context
newCtx := ctx
if traceID != "" {
log.Printf("Found Trace ID: %s", traceID)
newCtx = context.WithValue(ctx, "trace-id", traceID)
}
// Create a new span
tracer := otel.Tracer("purchase-processor")
newCtx, span := tracer.Start(newCtx, "handler.processPayload")
defer span.End()
if traceID != "" {
span.SetAttributes(
attribute.String("trace.id", traceID),
)
}
// Parse the "after" field into a Purchase struct...
var purchase model.Purchase
if err := mapstructure.Decode(afterDoc, &purchase); err != nil {
log.Printf("Failed to map 'after' payload to Purchase struct: %v", err)
return err
}
대안: Kafka 헤더 사용
가끔은 페이로드 자체가 아닌 Kafka 헤더에 Trace ID를 저장하는 것이 더 쉬울 수 있습니다. CDC 워크플로우의 경우, 이는 기본적으로 사용할 수 없을 수도 있습니다 — Debezium은 헤더에 추가되는 것을 제한할 수 있습니다. 그러나 프로듀서 측을 제어할 수 있다면(또는 표준 Kafka 프로듀서를 사용한다면), Sarama를 사용하여 다음과 같은 작업을 수행할 수 있습니다:
헤더에 Trace ID 삽입
// saramaHeadersCarrier is a helper to set/get headers in a Sarama message.
type saramaHeadersCarrier *[]sarama.RecordHeader
func (c saramaHeadersCarrier) Get(key string) string {
for _, h := range *c {
if string(h.Key) == key {
return string(h.Value)
}
}
return ""
}
func (c saramaHeadersCarrier) Set(key string, value string) {
*c = append(*c, sarama.RecordHeader{
Key: []byte(key),
Value: []byte(value),
})
}
// Before sending a message to Kafka:
func produceMessageWithTraceID(ctx context.Context, producer sarama.SyncProducer, topic string, value []byte) error {
span := trace.SpanFromContext(ctx)
traceID := span.SpanContext().TraceID().String()
headers := make([]sarama.RecordHeader, 0)
carrier := saramaHeadersCarrier(&headers)
carrier.Set("trace-id", traceID)
msg := &sarama.ProducerMessage{
Topic: topic,
Value: sarama.ByteEncoder(value),
Headers: headers,
}
_, _, err := producer.SendMessage(msg)
return err
}
컨슈머 측에서 Trace ID 추출
for message := range claim.Messages() {
// Extract the trace ID from headers
var traceID string
for _, hdr := range message.Headers {
if string(hdr.Key) == "trace-id" {
traceID = string(hdr.Value)
}
}
// Now continue your normal tracing workflow
if traceID != "" {
log.Printf("Found Trace ID in headers: %s", traceID)
// Attach it to the context or create a new span with this info
}
}
귀하의 사용 사례 및 CDC 파이프라인 설정에 따라 최적인 접근 방식을 선택할 수 있습니다:
- 데이터베이스 레코드에 Trace ID 삽입하여 CDC를 통해 자연스럽게 흐르게 합니다.
- 프로듀서 측을 보다 세밀하게 제어하거나 메시지 페이로드를 팽창시키지 않으려면Kafka 헤더를 사용하세요.
어느 방식을 선택하든, Kafka 및 Debezium을 통해 비동기적으로 처리되는 이벤트를 통해 여러 서비스 간의 추적을 일관되게 유지할 수 있습니다.
결론
OpenTelemetry와 Jaeger를 사용하면 세부적인 요청 추적을 제공하여 분산 시스템에서 지연이 발생하는 위치 및 이유를 정확히 파악할 수 있습니다.
Prometheus를 추가하면 성능 및 안정성의 핵심 지표인 메트릭을 얻을 수 있습니다. 이러한 도구들은 종합적인 관측 스택을 형성하여 빠른 문제 감지 및 해결, 성능 최적화, 전반적인 시스템 신뢰성을 가능하게 합니다.
이 접근 방식은 마이크로서비스 환경에서 문제 해결 속도를 크게 높이고, 저희 프로젝트에서 처음으로 구현하는 중요한 요소 중 하나입니다.

링크
Source:
https://dzone.com/articles/control-services-otel-jaeger-prometheus