













일반적인 AI가 다양한 산업을 혁신함에 따라, 개발자들은 대형 언어 모델(Large Language Models, LLMs)을 애플리케이션에 효율적으로 통합하는 방법을 점점 더 찾고 있습니다. 아마존 베드락은 강력한 솔루션으로, 통합 API를 통해 다양한 기초 모델에 액세스할 수 있는 완전히 관리되는 서비스를 제공합니다. 본 안내서에서는 아마존 베드락의 주요 이점, 다양한 LLM 모델을 프로젝트에 통합하는 방법, 애플리케이션이 사용하는 다양한 LLM 프롬프트를 관리하는 방법, 그리고 제품 사용에 고려해야 할 모범 사례에 대해 탐구할 것입니다.
아마존 베드락의 주요 이점
아마존 베드락은 시작할 때 필요한 모든 기초 능력을 제공하여, LLM을 어떤 애플리케이션에든 효율적으로 통합할 수 있도록 단순화합니다.
선도 모델에 간편하게 액세스
베드락은 AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, 아마존과 같은 산업 리더들로부터 고효율 기초 모델 다양한 선택지에 액세스를 제공합니다. 이 다양성은 개발자들이 사용 사례에 가장 적합한 모델을 선택하고, 여러 공급업체 관계나 API를 관리하지 않고 필요에 따라 모델을 전환할 수 있게 합니다.
완전히 관리되고 서버리스
완전히 관리되는 서비스인 베드락은 인프라 관리가 필요 없게 합니다. 이는 개발자들이 인프라 설정, 모델 배포, 확장과 같은 기본 복잡성에 대해 걱정할 필요 없이 애플리케이션 개발에 집중할 수 있도록 합니다.
기업급 보안과 개인정보
Bedrock는 내장 보안 기능을 제공하여 데이터가 AWS 환경을 떠나지 않고 전송 및 휴식 중에 암호화되도록 보장합니다. 또한 ISO, SOC 및 HIPAA를 포함한 다양한 표준을 준수합니다.
최신 인프라 개선 사항에 대한 최신 정보 유지
Bedrock는 정기적으로 새로운 기능을 출시하여 LLM 애플리케이션의 경계를 넓히고 거의 또는 전혀 설정이 필요하지 않습니다. 예를 들어 최근에는 정확도를 희생하지 않고 LLM 추론 지연 시간을 개선하는 최적화된 추론 모드를 출시했습니다.
Bedrock로 시작하기
이 섹션에서는 AWS SDK for Python을 사용하여 로컬 머신에서 작은 응용 프로그램을 빌드하여 Amazon Bedrock으로 시작하는 촉매제를 제공합니다. 이를 통해 Bedrock 사용의 실제 측면과 프로젝트에 통합하는 방법을 이해할 수 있습니다.
필수 조건
- AWS 계정이 있어야 합니다.
- Python이 설치되어 있어야 합니다. 설치되어 있지 않은 경우 이 가이드를 따라 설치하십시오.
- Python AWS SDK (Boto3)가 올바르게 설치되고 구성되어 있어야 합니다. Boto3를 사용할 수 있는 AWS IAM 사용자를 만드는 것이 좋습니다. 지침은 Boto3 퀵스타트 가이드에서 확인할 수 있습니다.
- IAM 사용자를 사용하는 경우에는
AmazonBedrockFullAccess정책을 추가해야 합니다. AWS 콘솔을 사용하여 정책을 첨부할 수 있습니다. - Bedrock에서 1개 이상의 모델에 액세스 권한을 요청하려면 이 안내서를 따르세요.
1. Bedrock 클라이언트 만들기
Bedrock에는 AWS CDK 내에서 사용할 수 있는 여러 클라이언트가 있습니다. Bedrock 클라이언트를 사용하면 모델을 생성하고 관리할 수 있으며, BedrockRuntime 클라이언트를 사용하면 기존 모델을 호출할 수 있습니다. 이 튜토리얼에서는 기존의 판매 중인 기초 모델 중 하나를 사용하므로 BedrockRuntime 클라이언트를 사용할 것입니다.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. 모델 호출하기
이 예제에서는 Amazon Nova Micro 모델 (모델 ID amazon.nova-micro-v1:0)을 사용했습니다. 이 모델은 Bedrock의 가장 저렴한 모델 중 하나입니다. 모델에 시를 쓰도록 요청하고 출력의 길이와 모델이 제공해야 하는 창의성 수준(“온도”라고 함)을 제어하는 매개변수를 설정했습니다. 다양한 프롬프트를 사용하고 매개변수를 조정하여 출력에 미치는 영향을 확인해보세요.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
또한 Anthropic의 하이쿠와 같은 다른 모델로도 시도해 볼 수 있습니다.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
모델 간 요청/응답 구조가 약간 다르다는 점을 유의하십시오. 다음 섹션에서는 미리 정의된 프롬프트 템플릿을 사용하여 이를 해결할 것입니다. 다른 모델을 실험하려면 Bedrock 콘솔의 “Model Catalog” 페이지에서 각 모델의 modelId 및 샘플 API 요청을 찾아 코드를 조정할 수 있습니다. 어떤 모델은 AWS에 의해 작성된 자세한 가이드도 있으며, 이를 여기에서 찾을 수 있습니다.
3. 프롬프트 관리 사용하기
Bedrock는 미리 정의된 프롬프트 템플릿을 생성하고 실험할 수 있는 편리한 도구를 제공합니다. 필요할 때마다 코드에서 프롬프트 및 특정 매개변수(예: 토큰 길이 또는 온도)를 정의하는 대신, 프롬프트 관리 콘솔에서 미리 정의된 템플릿을 만들 수 있습니다. 런타임 중에 주입될 입력 변수를 지정하고 필요한 추론 매개변수를 설정하고 프롬프트의 버전을 게시합니다. 완료되면 응용 프로그램 코드에서 원하는 프롬프트 템플릿 버전을 호출할 수 있습니다.
미리 정의된 프롬프트 사용의 주요 장점:
- 응용 프로그램이 성장하고 다양한 use case에 대해 다른 프롬프트, 매개변수 및 모델을 사용하는 경우 조직화를 돕습니다.
- 동일한 프롬프트가 여러 곳에서 사용되는 경우 프롬프트 재사용에 도움이 됩니다.
- LLM 추론의 세부 사항을 응용 프로그램 코드에서 추상화합니다.
- 프롬프트 엔지니어가 실제 응용 프로그램 코드를 건드리지 않고 콘솔에서 프롬프트 최적화에 작업할 수 있도록 합니다.
- 쉬운 실험이 가능하며 다양한 프롬프트 버전을 활용할 수 있습니다. 프롬프트 입력이나 온도와 같은 매개변수, 또는 모델 자체를 조정할 수 있습니다.
이제 이를 시도해 보겠습니다:
- Bedrock 콘솔로 이동하여 왼쪽 패널에서 “프롬프트 관리”를 클릭합니다.
- “프롬프트 생성”을 클릭하고 새 프롬프트의 이름을 지정합니다.
- LLM에 보낼 텍스트와 플레이스홀더 변수를 함께 입력합니다. 저는
{{주제}}에 관한 짧은 시를 쓰세요를 사용했습니다. - 구성 섹션에서 사용할 모델을 지정하고 “온도”나 “최대 토큰”과 같은 이전에 사용한 매개변수의 값을 설정합니다. 기본값을 그대로 둘 수도 있습니다.
- 테스트할 시간입니다! 페이지 하단에 테스트 변수에 값을 제공합니다. 저는 “소프트웨어 개발 영웅”을 사용했습니다. 그런 다음 결과를 확인하려면 오른쪽에 있는 “실행”을 클릭합니다.
참고로 제 구성 및 결과는 다음과 같습니다.
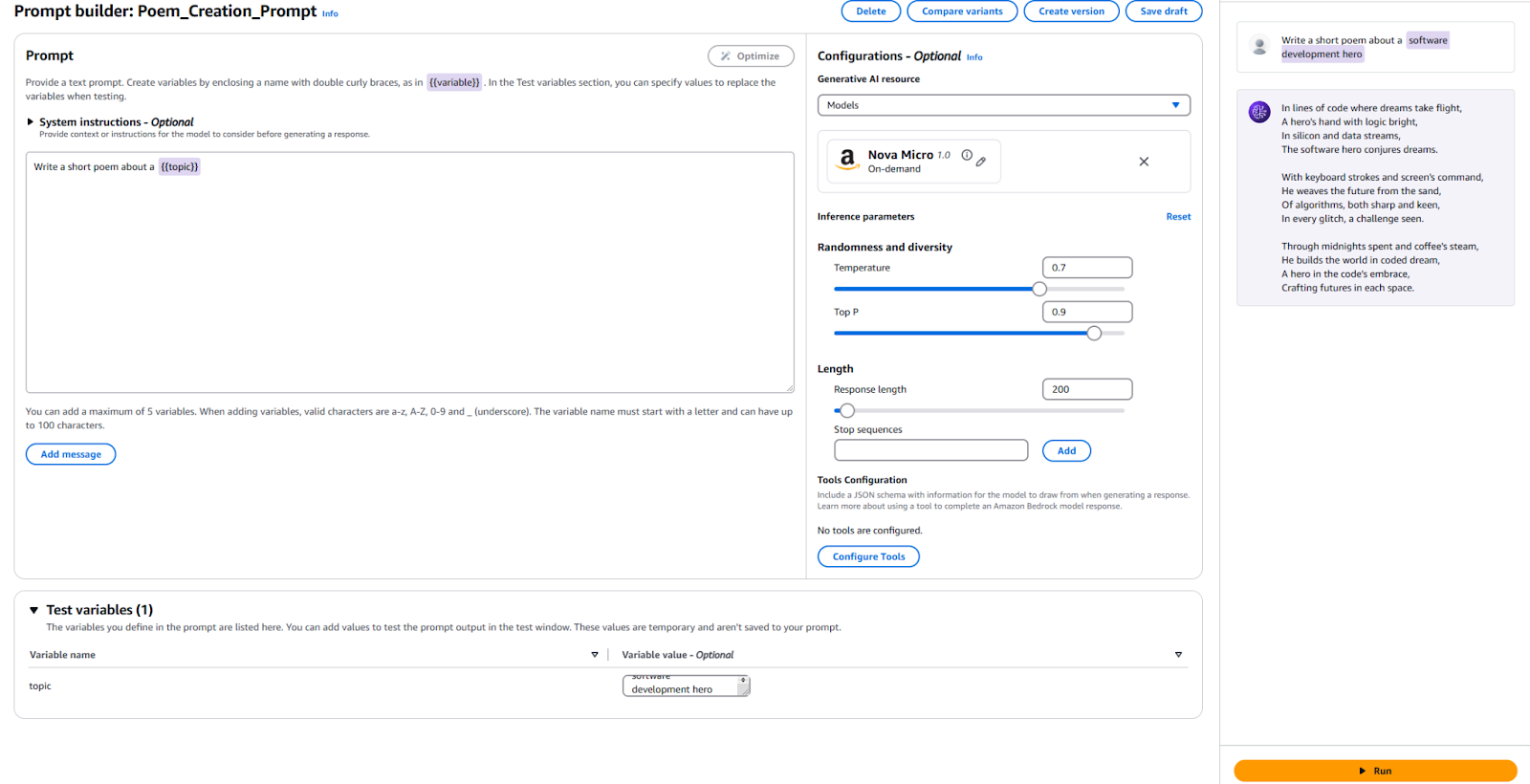
응용 프로그램에서 이 프롬프트를 사용하려면 새 프롬프트 버전을 게시해야 합니다. 이를 위해 상단의 “버전 생성” 버튼을 클릭합니다. 이렇게 하면 현재 구성의 스냅샷이 생성됩니다. 이를 수정하거나 더 많은 버전을 만들고 싶다면 계속해서 편집하면 됩니다.
게시한 후에는 프롬프트 페이지로 이동하여 새로 생성된 버전을 클릭하여 프롬프트 버전의 ARN(Amazon 리소스 이름)을 찾아야 합니다.

이 특정 프롬프트 버전의 ARN을 코드에서 사용하려면 복사합니다.

일단 ARN을 얻으면, 미리 정의된 프롬프트를 호출하기 위해 코드를 업데이트할 수 있습니다. 우리는 프롬프트 버전의 ARN과 그 안에 주입하는 변수들의 값을 필요로 합니다.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
보시다시피, 이는 LLM 추론의 세부 사항을 추상화하고 재사용성을 촉진함으로써 우리의 응용 프로그램 코드를 단순화합니다. 프롬프트 내에서 매개 변수를 실험하고 다른 버전을 만들며 응용 프로그램에서 사용할 수 있습니다. 당신은 이를 확장하여 사용자 입력을 받아 해당 주제에 대한 짧은 시를 작성하는 간단한 명령 줄 응용 프로그램으로 만들 수 있습니다.
다음 단계와 모범 사례
Bedrock를 사용하여 LLM을 응용 프로그램에 통합하는 데 익숙해지면, 생산 환경에 준비할 수 있도록 응용 프로그램을 준비하는 몇 가지 실용적인 고려 사항과 모범 사례를 탐색해보세요.
프롬프트 엔지니어링
모델을 호출하는 데 사용하는 프롬프트는 응용 프로그램을 성공시키거나 망가뜨릴 수 있습니다. 프롬프트 엔지니어링은 LLM에서 원하는 출력을 얻기 위해 지침을 만들고 최적화하는 과정입니다. 위에서 탐색한 미리 정의된 프롬프트 템플릿을 사용하면 숙련된 프롬프트 엔지니어들은 응용 프로그램의 소프트웨어 개발 프로세스를 방해하지 않고 프롬프트 엔지니어링을 시작할 수 있습니다. 사용하려는 모델에 특화된 프롬프트를 맞춤화해야 할 수 있습니다. 각 모델 제공 업체에 특화된 프롬프트 기술을 숙지해보세요. Bedrock는 일반적으로 대형 모델에 대한 지침 을 제공합니다.
모델 선택
올바른 모델 선택은 응용 프로그램의 요구 사항과 발생하는 비용 사이의 균형입니다. 더 능력 있는 모델은 일반적으로 더 비싸지 tend습니다. 모든 사용 사례가 가장 강력한 모델을 요구하는 것은 아니며, 가장 저렴한 모델이 항상 필요한 성능을 제공해주지 않을 수도 있습니다. 모델 평가 기능을 사용하여 서로 다른 모델의 출력을 빠르게 평가하고 비교하여 어떤 모델이 가장 적합한지 결정하세요. Bedrock는 테스트 데이터 세트를 업로드하고 모델 정확도를 개별 사용 사례에 대해 어떻게 평가해야 하는지 구성할 수 있는 여러 옵션을 제공합니다.
모델을 세밀하게 조정하고 RAG 및 에이전트로 모델 확장하기
제대로 작동하지 않는 외장 모델이 있을 경우 Bedrock는 모델을 특정 사용 사례에 맞게 조정할 수 있는 옵션을 제공합니다. 교육 데이터를 만들고 S3에 업로드한 다음 Bedrock 콘솔을 사용하여 세밀한 조정 작업을 시작할 수 있습니다. 또한 특정 사용 사례의 성능을 향상시키기 위해 검색 증강 생성 (RAG)과 같은 기술을 사용하여 모델을 확장할 수도 있습니다. Bedrock가 모델에 제공할 기존 데이터 소스를 연결하여 모델의 지식을 향상시킬 수 있습니다. Bedrock는 또한 기존 회사 시스템과 데이터 소스를 사용하여 복잡한 다단계 작업을 계획하고 실행하는 에이전트를 생성할 수 있는 기능을 제공합니다.
보안 및 가드레일
가드레일을 사용하면 생성 애플리케이션이 민감한 주제(예: 인종 차별, 성적 콘텐츠, 저속한 내용)를 우아하게 피하고 생성된 콘텐츠가 환각을 방지하도록 할 수 있습니다. 이 기능은 응용 프로그램의 윤리적 및 전문적인 표준을 유지하는 데 중요합니다. Bedrock의 내장된 보안 기능을 활용하고 기존 AWS 보안 제어와 통합하십시오.
비용 최적화
애플리케이션이나 기능을 널리 출시하기 전에 Bedrock 추론 및 RAG와 같은 확장이 발생할 수 있는 비용을 고려하십시오.
- 트래픽 패턴을 예측할 수 있다면 더 효율적이고 비용 효율적인 모델 추론을 위해 고정 처리량을 사용하는 것을 고려해 보십시오.
- 애플리케이션이 여러 기능으로 구성된 경우 각 기능마다 다른 모델과 프롬프트를 사용하여 개별적으로 비용을 최적화할 수 있습니다.
- 각 추론에 제공하는 모델 선택 및 프롬프트 크기를 재검토하십시오. Bedrock는 일반적으로 “토큰당” 요금을 책정하므로 더 긴 프롬프트와 큰 출력은 더 많은 비용이 발생할 것입니다.
결론
Amazon Bedrock는 LLM을 애플리케이션에 통합하기 위한 강력하고 유연한 플랫폼입니다. 많은 모델에 액세스할 수 있으며 개발을 간소화하고 견고한 사용자 정의 및 보안 기능을 제공합니다. 따라서 개발자들은 사용자에게 가치를 제공하는 데 초점을 맞춘 채 생성적 AI의 능력을 활용할 수 있습니다. 본 문서는 필수적인 Bedrock 통합을 시작하는 방법과 Prompts를 유지하는 방법을 보여줍니다.
AI가 발전함에 따라, 개발자들은 AI 애플리케이션을 구축하기 위해 Amazon Bedrock의 최신 기능과 모범 사례에 대해 최신 정보를 유지해야 합니다.
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide