













Mit der Revolution der generativen KI in verschiedenen Branchen suchen Entwickler zunehmend nach effizienten Möglichkeiten, um große Sprachmodelle (LLMs) in ihre Anwendungen zu integrieren. Amazon Bedrock ist eine leistungsstarke Lösung. Es bietet einen vollständig verwalteten Service, der Zugriff auf eine Vielzahl von Grundlagenmodellen über eine einheitliche API ermöglicht. Dieser Leitfaden wird die wichtigsten Vorteile von Amazon Bedrock untersuchen, wie man verschiedene LLM-Modelle in Projekte integriert, wie man das Management der verschiedenen LLM-Aufforderungen, die Ihre Anwendung verwendet, vereinfacht und bewährte Verfahren für die Produktionsnutzung berücksichtigt.
Wichtige Vorteile von Amazon Bedrock
Amazon Bedrock vereinfacht die anfängliche Integration von LLMs in jede Anwendung, indem es alle erforderlichen Grundfähigkeiten bereitstellt, um loszulegen.
Vereinfachter Zugriff auf führende Modelle
Bedrock bietet Zugriff auf eine vielfältige Auswahl an leistungsstarken Grundlagenmodellen von Branchenführern wie AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI und Amazon. Diese Vielfalt ermöglicht es Entwicklern, das geeignetste Modell für ihren Anwendungsfall auszuwählen und Modelle bei Bedarf zu wechseln, ohne mehrere Anbieterbeziehungen oder APIs verwalten zu müssen.
Vollständig verwaltet und serverlos
Als vollständig verwalteter Service beseitigt Bedrock die Notwendigkeit des Infrastrukturmanagements. Dies ermöglicht es Entwicklern, sich auf den Aufbau von Anwendungen zu konzentrieren, anstatt sich um die zugrunde liegenden Komplexitäten der Infrastruktur, Modellbereitstellung und Skalierung sorgen zu müssen.
Unternehmenssicherheit und Datenschutz
Bedrock bietet integrierte Sicherheitsfunktionen, die sicherstellen, dass Daten niemals Ihre AWS-Umgebungen verlassen und während der Übertragung sowie im Ruhezustand verschlüsselt sind. Es unterstützt auch die Einhaltung verschiedener Standards, einschließlich ISO, SOC und HIPAA.
Aktualisieren Sie sich über die neuesten Infrastrukturverbesserungen
Bedrock veröffentlicht regelmäßig neue Funktionen, die die Grenzen von LLM-Anwendungen erweitern und wenig bis gar keine Einrichtung erfordern. Zum Beispiel wurde kürzlich ein optimierter Inferenzmodus veröffentlicht, der die LLM-Inferenzlatenz verbessert, ohne die Genauigkeit zu beeinträchtigen.
Erste Schritte mit Bedrock
In diesem Abschnitt verwenden wir das AWS SDK für Python, um eine kleine Anwendung auf Ihrem lokalen Computer zu erstellen, und bieten Ihnen einen praktischen Leitfaden für den Einstieg mit Amazon Bedrock. Dies wird Ihnen helfen, die praktischen Aspekte der Verwendung von Bedrock zu verstehen und wie Sie es in Ihre Projekte integrieren können.
Voraussetzungen
- Sie haben ein AWS-Konto.
- Sie haben Python installiert. Wenn nicht installiert, erhalten Sie es, indem Sie diesem Leitfaden folgen.
- Sie haben das Python AWS SDK (Boto3) installiert und korrekt konfiguriert. Es wird empfohlen, einen AWS IAM-Benutzer zu erstellen, den Boto3 verwenden kann. Anleitungen finden Sie im Boto3 Quickstart-Leitfaden.
- Wenn Sie einen IAM-Benutzer verwenden, stellen Sie sicher, dass Sie die Richtlinie
AmazonBedrockFullAccesshinzufügen. Sie können Richtlinien über die AWS-Konsole anhängen. - Beantragen Sie Zugriff auf 1 oder mehr Modelle auf Bedrock, indem Sie dieser Anleitung folgen.
1. Erstellen des Bedrock-Clients
Bedrock verfügt über mehrere Clients im AWS CDK. Der Bedrock-Client ermöglicht es Ihnen, mit dem Dienst zu interagieren, um Modelle zu erstellen und zu verwalten, während der BedrockRuntime-Client es Ihnen ermöglicht, vorhandene Modelle aufzurufen. Wir werden eines der vorhandenen Standardmodelle für unser Tutorial verwenden, daher werden wir nur mit dem BedrockRuntime-Client arbeiten.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. Aufrufen des Modells
In diesem Beispiel habe ich das Amazon Nova Micro-Modell (mit ModelId amazon.nova-micro-v1:0) verwendet, eines der günstigsten Modelle von Bedrock. Wir werden eine einfache Aufforderung bereitstellen, um das Modell zu bitten, uns ein Gedicht zu schreiben, und Parameter festlegen, um die Länge der Ausgabe und das Maß an Kreativität („Temperatur“), das das Modell bieten soll, zu steuern. Spielen Sie gerne mit verschiedenen Aufforderungen und passen Sie die Parameter an, um zu sehen, wie sie sich auf die Ausgabe auswirken.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Wir können dies auch mit einem anderen Modell wie Anthropic’s Haiku ausprobieren, wie unten gezeigt.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Beachten Sie, dass die Anfrage-/Antwortstrukturen bei den Modellen leicht variieren. Dies ist ein Nachteil, den wir im nächsten Abschnitt durch die Verwendung vordefinierter Prompt-Vorlagen angehen werden. Um mit anderen Modellen zu experimentieren, können Sie die modelId und Beispiels-API-Anfragen für jedes Modell auf der Seite „Model Catalog“ in der Bedrock-Konsole nachschlagen und Ihren Code entsprechend anpassen. Einige Modelle haben auch detaillierte Anleitungen von AWS verfasst, die Sie hier finden können.
3. Verwendung der Prompt-Verwaltung
Bedrock bietet ein praktisches Tool zur Erstellung und zum Experimentieren mit vordefinierten Prompt-Vorlagen. Anstatt Prompt und spezifische Parameter wie Token-Längen oder Temperatur jedes Mal in Ihrem Code zu definieren, wenn Sie sie benötigen, können Sie vordefinierte Vorlagen in der Prompt-Verwaltungskonsole erstellen. Sie legen Eingabevariablen fest, die zur Laufzeit injiziert werden, richten alle erforderlichen Inferenzparameter ein und veröffentlichen eine Version Ihres Prompts. Sobald dies erledigt ist, kann Ihr Anwendungscode die gewünschte Version Ihrer Prompt-Vorlage aufrufen.
Hauptvorteile der Verwendung vordefinierter Prompts:
- Es hilft Ihrer Anwendung, organisiert zu bleiben, wenn sie wächst und verschiedene Prompts, Parameter und Modelle für verschiedene Anwendungsfälle verwendet.
- Es hilft bei der Wiederverwendung von Prompts, wenn das gleiche Prompt an mehreren Stellen verwendet wird.
- Abstrahiert die Details der LLM-Inferenz von unserem Anwendungscodes.
- Ermöglicht es Prompt-Ingenieuren, an der Optimierung von Prompts in der Konsole zu arbeiten, ohne Ihren tatsächlichen Anwendungscodes zu ändern.
- Es ermöglicht einfache Experimente, indem verschiedene Versionen von Aufforderungen genutzt werden. Sie können die Eingabe der Aufforderung, Parameter wie die Temperatur oder sogar das Modell selbst anpassen.
Probieren wir das jetzt aus:
- Wechseln Sie zur Bedrock-Konsole und klicken Sie auf der linken Seite auf „Aufforderungsverwaltung“.
- Klicken Sie auf „Aufforderung erstellen“ und geben Sie Ihrer neuen Aufforderung einen Namen
- Geben Sie den Text ein, den wir an den LLM senden möchten, zusammen mit einer Platzhaltervariablen. Ich habe
Schreibe ein kurzes Gedicht über ein {{Thema}}verwendet. - In der Konfigurationssitzung geben Sie an, welches Modell Sie verwenden möchten, und legen Sie die Werte derselben Parameter fest, die wir zuvor verwendet haben, wie „Temperatur“ und „Maximale Token“. Wenn Sie möchten, können Sie die Standardeinstellungen belassen.
- Es ist Zeit zum Testen! Geben Sie unten auf der Seite einen Wert für Ihre Testvariable ein. Ich habe „Softwareentwicklungs-Held“ verwendet. Klicken Sie dann rechts auf „Ausführen“, um zu sehen, ob Sie mit dem Ergebnis zufrieden sind.
Zur Referenz hier meine Konfiguration und die Ergebnisse.
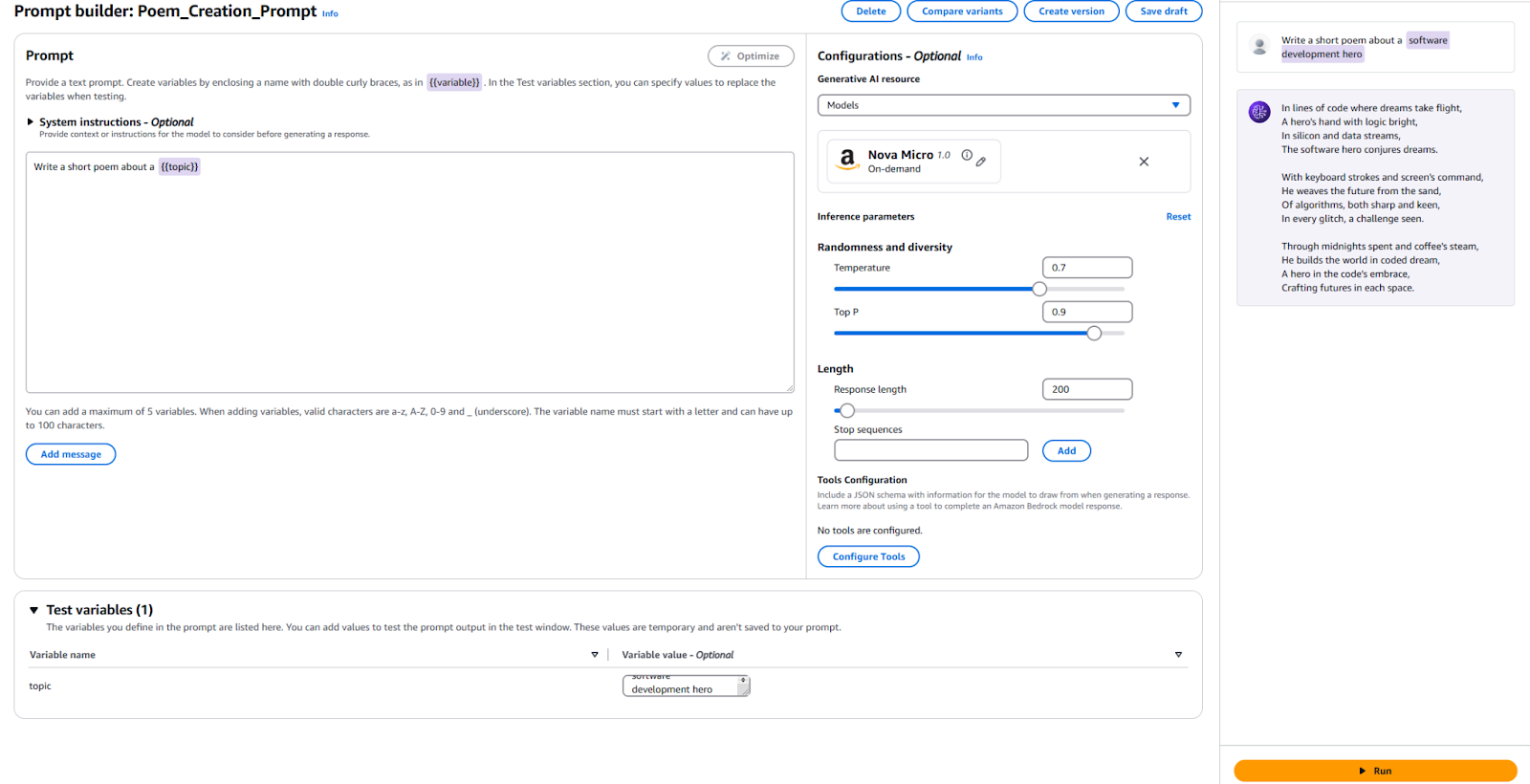
Wir müssen eine neue Aufforderungsversion veröffentlichen, um diese Aufforderung in Ihrer Anwendung zu verwenden. Klicken Sie dazu oben auf die Schaltfläche „Version erstellen“. Dies erstellt einen Schnappschuss Ihrer aktuellen Konfiguration. Wenn Sie damit herumspielen möchten, können Sie weiter bearbeiten und weitere Versionen erstellen.
Nach der Veröffentlichung müssen wir den ARN (Amazon Resource Name) der Aufforderungsversion finden, indem wir zur Seite Ihrer Aufforderung navigieren und auf die neu erstellte Version klicken.

Kopieren Sie den ARN dieser spezifischen Aufforderungsversion, um ihn in Ihrem Code zu verwenden.

Sobald wir die ARN haben, können wir unseren Code aktualisieren, um diesen vordefinierten Aufruf durchzuführen. Wir benötigen nur die ARN der Prompt-Version und die Werte für eventuelle Variablen, die wir injizieren.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Wie Sie sehen können, vereinfacht dies unseren Anwendungscode, indem es die Details der LLM-Inferenz abstrahiert und die Wiederverwendbarkeit fördert. Spielen Sie mit Parametern innerhalb Ihres Prompts herum, erstellen Sie verschiedene Versionen und verwenden Sie diese in Ihrer Anwendung. Sie könnten dies zu einer einfachen Befehlszeilenanwendung erweitern, die Benutzereingaben entgegennimmt und ein kurzes Gedicht zu diesem Thema verfasst.
Nächste Schritte und bewährte Verfahren
Sobald Sie sich mit der Verwendung von Bedrock vertraut gemacht haben, um ein LLM in Ihre Anwendung zu integrieren, erkunden Sie einige praktische Überlegungen und bewährte Verfahren, um Ihre Anwendung für den produktiven Einsatz vorzubereiten.
Prompt-Engineering
Der Prompt, den Sie zur Ansteuerung des Modells verwenden, kann Ihre Anwendung entscheidend beeinflussen. Prompt-Engineering ist der Prozess der Erstellung und Optimierung von Anweisungen, um den gewünschten Output aus einem LLM zu erhalten. Mit den oben untersuchten vordefinierten Prompt-Vorlagen können erfahrene Prompt-Engineers mit dem Prompt-Engineering beginnen, ohne den Softwareentwicklungsprozess Ihrer Anwendung zu beeinträchtigen. Möglicherweise müssen Sie Ihren Prompt an das Modell anpassen, das Sie verwenden möchten. Machen Sie sich mit den spezifischen Prompt-Techniken jedes Modellanbieters vertraut. Bedrock bietet einige Richtlinien für in der Regel große Modelle.
Modellauswahl
Die richtige Modellauswahl ist ein ausgewogenes Verhältnis zwischen den Anforderungen Ihrer Anwendung und den damit verbundenen Kosten. Leistungsfähigere Modelle neigen dazu, teurer zu sein. Nicht alle Anwendungsfälle erfordern das leistungsstärkste Modell, während die günstigsten Modelle möglicherweise nicht immer die Leistung bieten, die Sie benötigen. Verwenden Sie die Funktion Modellbewertung, um schnell die Ausgaben verschiedener Modelle zu bewerten und zu vergleichen, um herauszufinden, welches Ihren Anforderungen am besten entspricht. Bedrock bietet mehrere Optionen zum Hochladen von Testdatensätzen und zur Konfiguration, wie die Modellgenauigkeit für einzelne Anwendungsfälle bewertet werden soll.
Feinabstimmung und Erweiterung Ihres Modells mit RAG und Agents
Wenn ein Modell von der Stange nicht gut genug für Sie funktioniert, bietet Bedrock Optionen, um Ihr Modell auf Ihren spezifischen Anwendungsfall anzupassen. Erstellen Sie Ihre Trainingsdaten, laden Sie sie in S3 hoch und verwenden Sie die Bedrock-Konsole, um einen Feinabstimmungsjob zu starten. Sie können auch Ihre Modelle mit Techniken wie retrieval-augmented generation (RAG) erweitern, um die Leistung für spezifische Anwendungsfälle zu verbessern. Verknüpfen Sie vorhandene Datenquellen, die Bedrock dem Modell zur Verfügung stellt, um sein Wissen zu erweitern. Bedrock bietet auch die Möglichkeit, Agenten zu erstellen, um komplexe mehrstufige Aufgaben mit Ihren vorhandenen Unternehmenssystemen und Datenquellen zu planen und auszuführen.
Sicherheit und Sicherheitsvorkehrungen
Mit Guardrails können Sie sicherstellen, dass Ihre generative Anwendung sensiblen Themen (z.B. Rassismus, sexuelle Inhalte und Obszönitäten) elegant ausweicht und dass der generierte Inhalt fundiert ist, um Halluzinationen zu verhindern. Diese Funktion ist entscheidend für die Aufrechterhaltung der ethischen und professionellen Standards Ihrer Anwendungen. Nutzen Sie die integrierten Sicherheitsfeatures von Bedrock und integrieren Sie diese mit Ihren bestehenden AWS-Sicherheitskontrollen.
Kostenoptimierung
Bevor Sie Ihre Anwendung oder Funktion breit veröffentlichen, sollten Sie die Kosten berücksichtigen, die durch die Bedrock-Inferenz und Erweiterungen wie RAG anfallen werden.
- Wenn Sie Ihre Verkehrsmuster vorhersagen können, sollten Sie Provisioned Throughput für eine effizientere und kostengünstigere Modellenferenz in Betracht ziehen.
- Wenn Ihre Anwendung aus mehreren Funktionen besteht, können Sie für jede Funktion unterschiedliche Modelle und Eingabeaufforderungen verwenden, um die Kosten individuell zu optimieren.
- Überdenken Sie Ihre Modellwahl sowie die Größe der Eingabeaufforderung, die Sie für jede Inferenz bereitstellen. Bedrock berechnet in der Regel nach einem „pro Token“-Modell, sodass längere Eingabeaufforderungen und größere Ausgaben höhere Kosten verursachen.
Fazit
Amazon Bedrock ist eine leistungsstarke und flexible Plattform zur Integration von LLMs in Anwendungen. Sie bietet Zugang zu vielen Modellen, vereinfacht die Entwicklung und bietet robuste Anpassungs- und Sicherheitsfunktionen. So können Entwickler die Leistungsfähigkeit von generativer KI nutzen und sich gleichzeitig darauf konzentrieren, ihren Nutzern einen Mehrwert zu bieten. Dieser Artikel zeigt, wie man mit einer wesentlichen Bedrock-Integration beginnt und unsere Eingabeaufforderungen organisiert hält.
Mit der Entwicklung von KI sollten Entwickler auf dem neuesten Stand der neuesten Funktionen und bewährten Verfahren in Amazon Bedrock bleiben, um ihre KI-Anwendungen zu erstellen.
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide