













随着生成式人工智能(AI)革命各行各业,开发人员越来越寻求将大型语言模型(LLMs)高效集成到他们的应用程序中。亚马逊Bedrock是一个强大的解决方案。它提供了一个完全托管的服务,通过统一的API访问各种基础模型。本指南将探讨亚马逊Bedrock的关键优势,如何将不同的LLM模型集成到您的项目中,如何简化应用程序使用的各种LLM提示的管理,以及考虑用于生产使用的最佳实践。
亚马逊Bedrock的关键优势
亚马逊Bedrock通过提供启动所需的所有基础功能,简化了LLMs集成到任何应用程序中的初始过程。
简化访问领先模型
Bedrock提供了对来自AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI和亚马逊等行业领先公司的多样化高性能基础模型的访问。这种多样性使开发人员能够选择最适合其用例的模型,并根据需要切换模型,而无需管理多个供应商关系或API。
完全托管和无服务器
作为一个完全托管的服务,Bedrock消除了基础设施管理的需要。这使开发人员能够专注于构建应用程序,而不必担心基础设施设置、模型部署和扩展的复杂性。
企业级安全和隐私
Bedrock提供内置的安全功能,确保数据永远不会离开您的AWS环境,并在传输和静止时进行加密。它还支持符合各种标准,包括ISO、SOC和HIPAA。
与最新基础设施改进保持更新
Bedrock定期发布新功能,推动LLM应用程序的边界,并且几乎不需要设置。例如,它最近发布了一个优化的推理模式,可以提高LLM推理延迟,而不影响准确性。
开始使用Bedrock
在本节中,我们将使用AWS SDK for Python在本地计算机上构建一个小应用程序,为您提供一个入门指南,帮助您了解如何实际使用Bedrock以及如何将其集成到您的项目中。
先决条件
- 您拥有一个AWS账户。
- 您已安装Python。如果尚未安装,请按照此指南进行安装。
- 您已安装并正确配置了Python AWS SDK(Boto3)。建议创建一个Boto3可用的AWS IAM用户。有关说明,请参阅Boto3快速入门指南。
- 如果使用IAM用户,请确保为其添加
AmazonBedrockFullAccess策略。您可以使用AWS控制台附加策略。 - 按照此指南的步骤请求在Bedrock上访问一个或多个模型。
1. 创建Bedrock客户端
Bedrock在AWS CDK中有多个可用客户端。Bedrock客户端可让您与服务交互以创建和管理模型,而BedrockRuntime客户端使您可以调用现有模型。在本教程中,我们将使用一个现成的基础模型,因此我们将仅使用BedrockRuntime客户端。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. 调用模型
在这个例子中,我使用了Amazon Nova Micro模型(具有modelId amazon.nova-micro-v1:0),这是Bedrock中最便宜的模型之一。我们将提供一个简单的提示,要求模型为我们写一首诗,并设置参数来控制输出的长度和模型应该提供的创造力水平(称为“温度”)。随意尝试不同的提示并调整参数,看看它们如何影响输出。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
我们也可以尝试使用另一个模型,比如Anthropic的Haiku,如下所示。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
请注意,不同模型之间的请求/响应结构略有不同。这是一个我们将在下一部分使用预定义提示模板来解决的缺点。要尝试其他模型,您可以在Bedrock控制台的“模型目录”页面查找每个模型的modelId和示例API请求,并相应调整您的代码。一些模型还有由AWS撰写的详细指南,您可以在这里找到。
3. 使用提示管理
Bedrock提供了一个方便的工具用于创建和尝试预定义提示模板。您可以在提示管理控制台中创建预定义模板,而不是每次需要时在您的代码中定义提示和具体参数,比如令牌长度或温度。您指定在运行时将被注入的输入变量,设置所有必需的推理参数,并发布您的提示的一个版本。完成后,您的应用代码可以调用所需版本的提示模板。
使用预定义提示的主要优势:
- 有助于您的应用在不同用例中增长并使用不同的提示、参数和模型时保持有条理。
- 如果同一提示在多个地方使用,则有助于提示重用。
- 从我们的应用代码中抽象出LLM推理的细节。
- 允许提示工程师在控制台上进行提示优化工作,而无需触及您的实际应用代码。
- 它允许轻松实验,利用不同版本的提示。您可以调整提示输入、参数,如温度,甚至模型本身。
现在让我们试一下:
- 转到Bedrock控制台,点击左侧面板上的“提示管理”。
- 点击“创建提示”,给您的新提示取一个名称。
- 输入我们想发送给LLM的文本,以及一个占位变量。我使用了
写一首关于{{topic}}的短诗。 - 在配置部分,指定您想使用的模型,并设置与我们之前使用的相同参数的值,如“温度”和“最大标记”。如果您愿意,可以保留默认设置。
- 是时候测试了!在页面底部,为您的测试变量提供一个值。我使用了“软件开发英雄”。然后,点击右侧的“运行”按钮,看看您是否满意输出。
供参考,这是我的配置和结果。
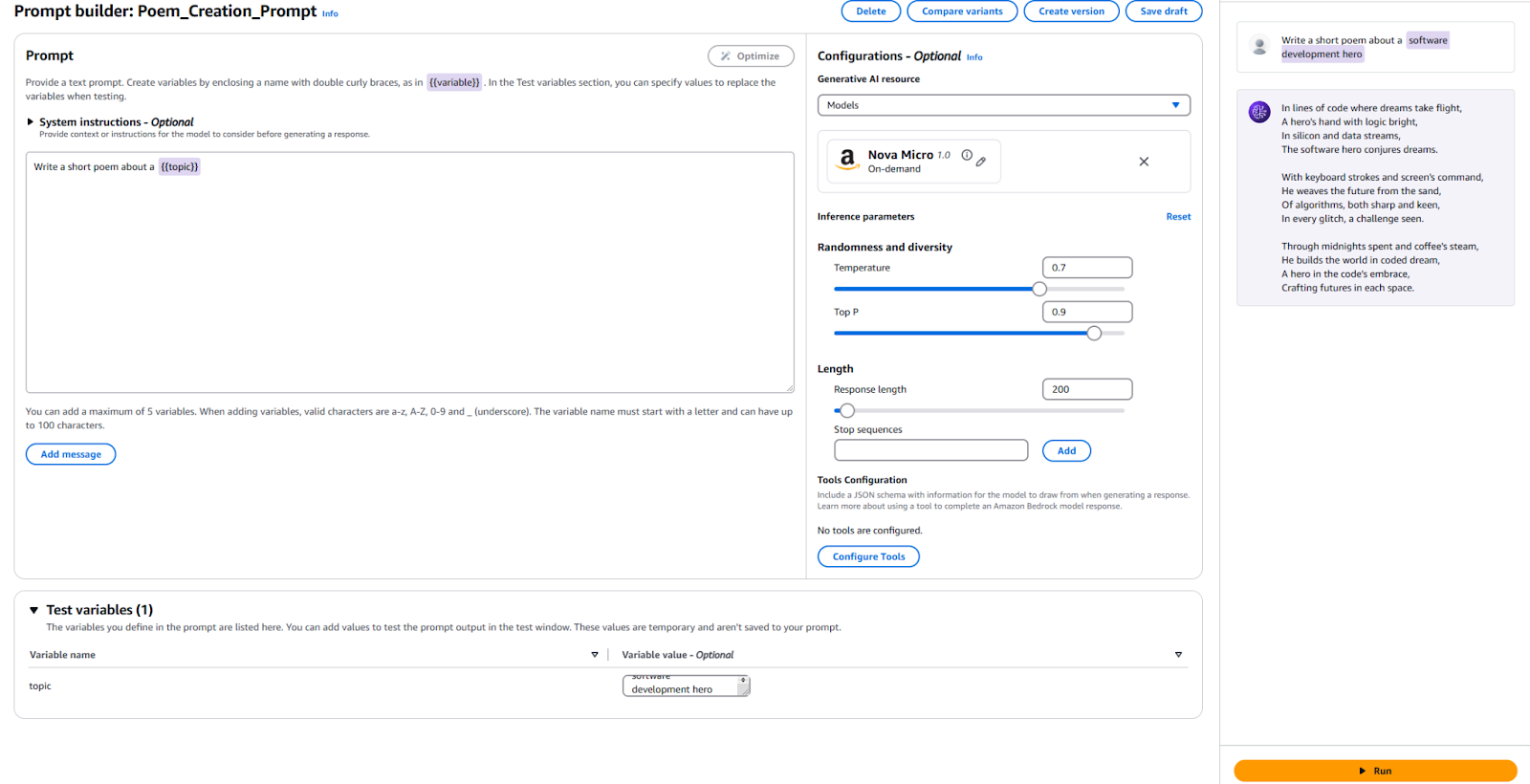
我们需要发布一个新的提示版本,以便在您的应用程序中使用此提示。要这样做,点击顶部的“创建版本”按钮。这将创建您当前配置的快照。如果您想继续尝试,可以继续编辑并创建更多版本。
发布后,我们需要找到提示版本的ARN(Amazon资源名称),方法是转到您的提示页面,并单击新创建的版本。

复制此特定提示版本的ARN以在您的代码中使用。

一旦我们获得了ARN,我们就可以更新我们的代码来调用这个预定义提示。我们只需要提示版本的ARN和我们注入其中的任何变量的值。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
正如您所看到的,通过将LLM推断的细节抽象化并促进可重用性,这简化了我们的应用代码。随意在您的提示中尝试不同的参数,创建不同版本,并在您的应用程序中使用它们。您可以将其扩展为一个简单的命令行应用程序,接受用户输入,并在该主题上撰写一首简短的诗歌。
下一步和最佳实践
一旦您熟悉使用Bedrock将LLM集成到您的应用程序中,请探索一些实际考虑因素和最佳实践,使您的应用程序准备好用于生产。
提示工程
您用来调用模型的提示可能会成就或毁掉您的应用程序。提示工程是创建和优化指令以从LLM获取所需输出的过程。通过上述探讨的预定义提示模板,熟练的提示工程师可以开始进行提示工程,而不干扰您的应用程序的软件开发过程。您可能需要定制您的提示以特定于您想要使用的模型。熟悉特定于每个模型提供者的提示技术。Bedrock为常见的大型模型提供了一些 指南。
模型选择
正确选择模型是在满足应用需求和承担成本之间取得平衡。更强大的模型往往更昂贵。并非所有的使用情况都需要最强大的模型,而最便宜的模型也不总能提供您所需的性能。使用模型评估功能快速评估和比较不同模型的输出,以确定哪个最符合您的需求。Bedrock提供多种选项来上传测试数据集,并配置如何为各个使用情况评估模型准确性。
通过RAG和Agents对您的模型进行微调和扩展
如果现成的模型不够好,Bedrock提供选项来调整您的模型以适应特定的使用情况。创建您的训练数据,将其上传至S3,并使用Bedrock控制台启动微调作业。您还可以使用诸如检索增强生成(RAG)之类的技术来扩展您的模型,以提高特定使用情况的性能。连接现有数据源,Bedrock将使这些数据源可供模型使用,以增强其知识。Bedrock还提供创建代理的功能,用于规划和执行复杂的多步任务,利用您现有的公司系统和数据源。
安全与防护措施
使用Guardrails,您可以确保您的生成应用程序优雅地避开敏感话题(例如种族主义、性内容和亵渎),并且生成的内容扎根以防止幻觉。此功能对于维护您的应用程序的道德和专业标准至关重要。利用Bedrock内置的安全功能,并将其与您现有的AWS安全控制集成。
成本优化
在广泛发布您的应用程序或功能之前,考虑Bedrock推理和诸如RAG之类的扩展将产生的成本。
- 如果您能预测您的流量模式,请考虑使用预配吞吐量以实现更高效和具有成本效益的模型推理。
- 如果您的应用程序由多个功能组成,您可以针对每个功能使用不同的模型和提示来根据个别情况优化成本。
- 重新审视您的模型选择以及为每个推理提供的提示大小。Bedrock通常按“每标记”计价,因此更长的提示和更大的输出将产生更多成本。
结论
Amazon Bedrock是一个强大而灵活的平台,可将LLM集成到应用程序中。它提供了许多模型的访问权限,简化了开发,并提供了强大的定制和安全功能。因此,开发人员可以利用生成式人工智能的力量,同时专注于为他们的用户创造价值。本文展示了如何开始使用基本的Bedrock集成并保持我们的提示有序。
随着人工智能的发展,开发者应该及时了解亚马逊Bedrock的最新特性和最佳实践,以构建他们的人工智能应用程序。
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide