













生成AIがさまざまな業界を革命的に変えていく中、開発者は大規模言語モデル(LLM)をアプリケーションに統合する効率的な方法をますます求めています。Amazon Bedrockは強力なソリューションです。これは、統一されたAPIを通じて幅広い基盤モデルにアクセスできる完全管理型のサービスを提供します。このガイドでは、Amazon Bedrockの主な利点、さまざまなLLMモデルをプロジェクトに統合する方法、アプリケーションで使用するさまざまなLLMプロンプトの管理を簡素化する方法、および本番環境で考慮すべきベストプラクティスについて探ります。
Amazon Bedrockの主な利点
Amazon Bedrockは、LLMをアプリケーションに初期統合するプロセスを簡素化し、始めるために必要なすべての基盤機能を提供します。
主要モデルへの簡素化されたアクセス
Bedrockは、AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI、Amazonなどの業界リーダーからの多様な高性能基盤モデルへのアクセスを提供します。この多様性により、開発者は自分のユースケースに最も適したモデルを選択し、必要に応じてモデルを切り替えることができ、複数のベンダー関係やAPIを管理する必要がありません。
完全管理型およびサーバーレス
完全管理型サービスとして、Bedrockはインフラストラクチャ管理の必要性を排除します。これにより、開発者はインフラストラクチャのセットアップ、モデルのデプロイ、およびスケーリングの複雑さを心配することなく、アプリケーションの構築に集中できます。
エンタープライズグレードのセキュリティとプライバシー
Bedrockは、組み込みのセキュリティ機能を提供し、データがAWS環境から外部に漏洩することなく、休止中および転送中に暗号化されます。さらに、ISO、SOC、HIPAAなど、さまざまな標準のコンプライアンスもサポートしています。
最新のインフラ改善について最新情報を入手
Bedrockは定期的に新機能をリリースし、LLMアプリケーションの限界を押し上げるもので、ほとんどまたは全くセットアップが必要ありません。たとえば、最近、推論の最適化モードをリリースしました。このモードは、推論の遅延を改善する一方で精度を損ないません。
Bedrockを使い始める
このセクションでは、AWS SDK for Pythonを使用してローカルマシン上で小さなアプリケーションを構築し、Amazon Bedrockの使用を始めるための実践的なガイドを提供します。これにより、Bedrockの使用の実践的な側面とプロジェクトに統合する方法が理解できます。
前提条件
- AWSアカウントを持っていること。
- Pythonがインストールされていること。インストールされていない場合は、このガイドに従って取得してください。
- Python AWS SDK(Boto3)が正しくインストールおよび構成されていること。Boto3が使用できるAWS IAMユーザーを作成することをお勧めします。手順はBoto3クイックスタートガイドで利用可能です。
- IAMユーザーを使用する場合は、それに
AmazonBedrockFullAccessポリシーを追加してください。ポリシーはAWSコンソールを使用してアタッチすることができます。 - Bedrockの1つ以上のモデルへのアクセスをリクエストするには、このガイドに従ってください。
1. Bedrockクライアントの作成
BedrockにはAWS CDK内で複数のクライアントが利用できます。 Bedrockクライアントを使用すると、モデルの作成と管理を行うことができます。一方、BedrockRuntimeクライアントを使用すると、既存のモデルを呼び出すことができます。このチュートリアルでは、既存の汎用ファンデーションモデルのうちの1つを使用するため、BedrockRuntimeクライアントを使用します。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. モデルの呼び出し
この例では、Amazon Nova Microモデル(モデルID:amazon.nova-micro-v1:0)を使用しています。これはBedrockの中で最も安価なモデルの1つです。モデルに詩を書いてもらうようにシンプルなプロンプトを提供し、出力の長さやモデルが提供すべき創造性のレベル(「温度」と呼ばれる)を制御するパラメータを設定します。異なるプロンプトやパラメータを試して、出力に与える影響を見てみてください。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
また、次のようにAnthropic’s Haikuなど別のモデルでも試すことができます。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
異なるモデル間でリクエスト/レスポンスの構造がわずかに異なることに注意してください。次のセクションでは、事前定義されたプロンプトテンプレートを使用してこの欠点に対処します。他のモデルを試すには、「Model Catalog」ページから各モデルのmodelIdとサンプルAPIリクエストを検索し、コードを適切に調整してください。一部のモデルには、AWSによって作成された詳細なガイドもあります。詳細はこちらで確認できます。
3. プロンプト管理の使用
Bedrockには、事前定義されたプロンプトテンプレートを作成および実験するための便利なツールが用意されています。プロンプトや特定のパラメータ(トークン長や温度など)を毎回コード内で定義する代わりに、プロンプト管理コンソールで事前定義されたテンプレートを作成できます。ランタイム中に挿入される入力変数を指定し、すべての必要な推論パラメータを設定し、プロンプトのバージョンを公開します。これらの作業が完了すると、アプリケーションコードは所望のプロンプトテンプレートのバージョンを呼び出すことができます。
事前定義プロンプトを使用する主な利点:
- 成長するアプリケーションがさまざまなユースケースに対して異なるプロンプト、パラメータ、およびモデルを使用する際に、アプリケーションを整理するのに役立ちます。
- 同じプロンプトが複数の場所で使用される場合のプロンプト再利用に役立ちます。
- LLM推論の詳細をアプリケーションコードから抽象化します。
- プロンプトエンジニアが、実際のアプリケーションコードに触れることなく、コンソールでプロンプトの最適化に取り組むことができます。
- 簡単な実験を可能にし、異なるプロンプトバージョンを活用できます。プロンプト入力や温度などのパラメータ、またはモデルそのものを調整できます。
それでは、試してみましょう:
- Bedrockコンソールに移動し、左パネルで「Prompt Management」をクリックします。
- 「Promptを作成」をクリックして、新しいプロンプトに名前を付けます。
- LLMに送信したいテキストとプレースホルダ変数を入力します。私は
Write a short poem about a {{topic}}を使用しました。 - 構成セクションで、使用するモデルを指定し、以前に使用した「Temperature」や「Max Tokens」などの同じパラメータの値を設定します。デフォルトのままにしても構いません。
- テストの時間です!ページの一番下で、テスト変数の値を指定します。私は「Software Development Hero」を使用しました。その後、右側の「Run」をクリックして、出力に満足しているか確認します。
参考のために、こちらが私の構成と結果です。
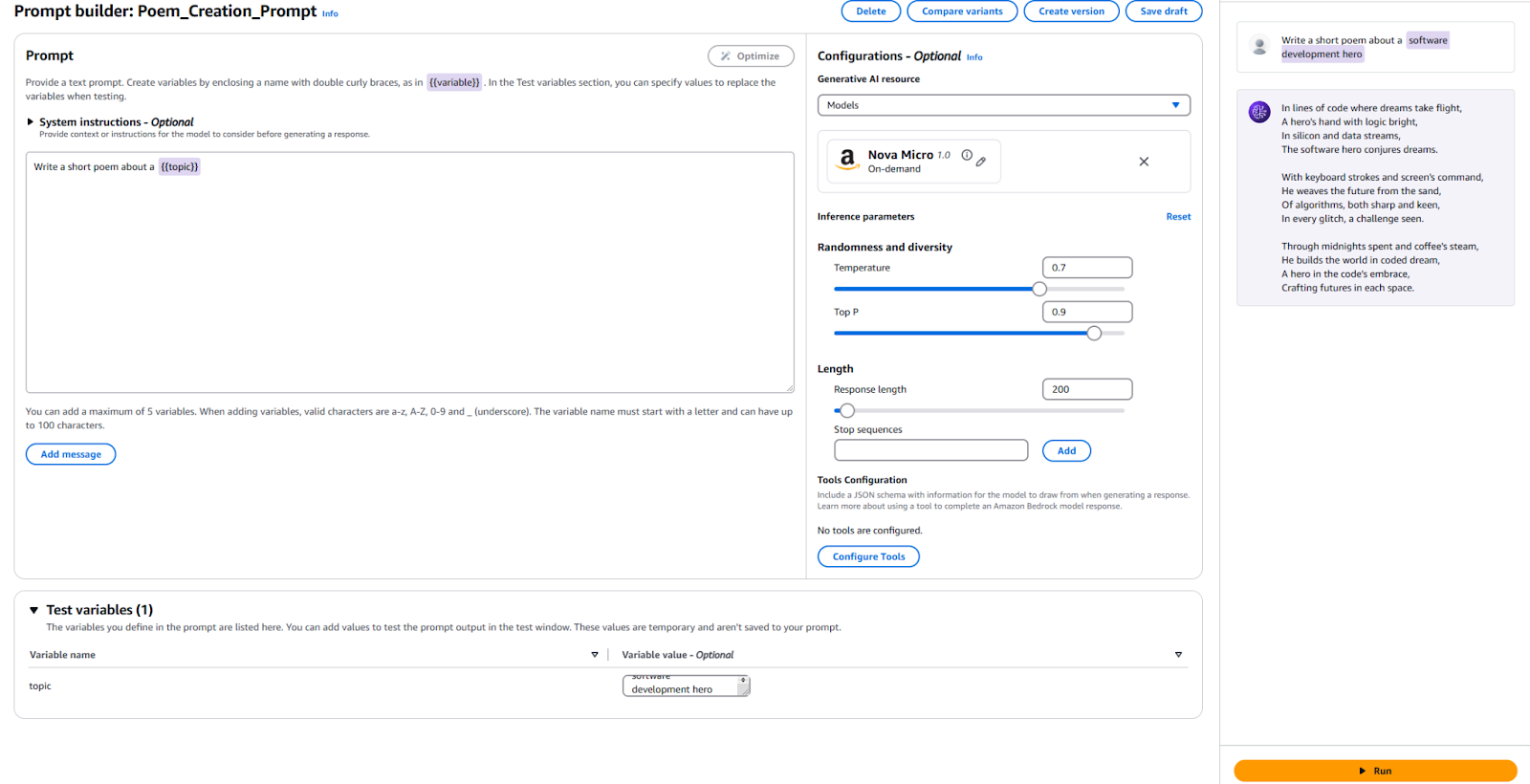
このプロンプトをアプリケーションで使用するために新しいPrompt Versionを公開する必要があります。これを行うには、トップにある「Create Version」ボタンをクリックします。これにより、現在の構成のスナップショットが作成されます。編集やさらなるバージョンの作成を行いたい場合は、続けることができます。
公開後、Promptのページに移動し、新しく作成したバージョンをクリックして、Prompt VersionのARN(Amazon Resource Name)を見つける必要があります。

この特定のプロンプトバージョンのARNをコピーして、コードで使用します。

ARNを取得したら、この事前定義されたプロンプトを呼び出すためのコードを更新できます。プロンプトバージョンのARNと、それに注入する変数の値だけが必要です。
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
ご覧の通り、これによりLLMの推論の詳細が抽象化され、再利用性が向上しました。プロンプト内のパラメータを自由に変更し、異なるバージョンを作成し、アプリケーションで使用してください。これを拡張して、ユーザーの入力を受け取り、そのトピックに関する短い詩を書くシンプルなコマンドラインアプリケーションにも利用できます。
次のステップとベストプラクティス
Bedrockを使用してLLMをアプリケーションに統合するのに慣れたら、本番環境での利用に備えていくつかの実用的な考慮事項やベストプラクティスを探ってみましょう。
プロンプトエンジニアリング
モデルを呼び出すために使用するプロンプトは、アプリケーションの成否を左右することがあります。プロンプトエンジニアリングとは、所望の出力を得るための指示を作成および最適化するプロセスです。上記で探究した事前定義のプロンプトテンプレートを使用することで、熟練したプロンプトエンジニアは、アプリケーションのソフトウェア開発プロセスに干渉せずにプロンプトエンジニアリングを開始できます。使用したいモデルに特化したプロンプトを調整する必要があるかもしれません。各モデルプロバイダー固有のプロンプト技術に精通してください。Bedrockは、一般的な大規模モデルに関するガイドラインを提供しています。
モデル選択
適切なモデルを選択することは、アプリケーションのニーズと発生するコストのバランスです。能力の高いモデルほど高価です。すべてのユースケースが最も強力なモデルを必要とするわけではなく、最も安価なモデルが常に必要なパフォーマンスを提供するとは限りません。異なるモデルの出力を迅速に評価および比較し、最適なものを選択するためにモデル評価機能を使用します。Bedrockには、テストデータセットをアップロードし、個々のユースケースに対してモデルの精度を評価する方法を構成するための複数のオプションが提供されています。
モデルを微調整して拡張する:RAGとエージェント
市販のモデルがうまく機能しない場合、Bedrockにはモデルを特定のユースケースに合わせて調整するオプションが用意されています。トレーニングデータを作成し、S3にアップロードして、Bedrockコンソールを使用して微調整ジョブを開始できます。また、検索増強生成(RAG)などの手法を使用してモデルを拡張し、特定のユースケースのパフォーマンスを向上させることもできます。Bedrockは、既存のデータソースを接続し、モデルが知識を向上させるために利用できるようにすることも提供しています。Bedrockは、既存の企業システムとデータソースを使用して、複雑な多段階タスクを計画および実行するためのエージェントを作成する機能も提供しています。
セキュリティとガードレール
ガードレイルを使用すると、生成アプリケーションが敏感なトピック(例:人種差別、性的内容、冒涜的な言葉)を優雅に避け、生成されたコンテンツがハルシネーションを防ぐために基盤に根ざすことを保証できます。この機能は、アプリケーションの倫理的およびプロフェッショナルな基準を維持するために重要です。Bedrockの組み込みセキュリティ機能を活用し、既存のAWSセキュリティコントロールと統合しましょう。
コスト最適化
アプリケーションや機能を広くリリースする前に、Bedrock推論やRAGなどの拡張機能が発生させるコストを考慮してください。
- トラフィックパターンを予測できる場合は、効率的かつコスト効果の高いモデル推論のためにプロビジョンドスループットの使用を検討してください。
- アプリケーションが複数の機能で構成されている場合、各機能ごとに異なるモデルとプロンプトを使用して、コストを個別に最適化できます。
- 各推論のために提供するモデルの選択とプロンプトのサイズを再考してください。Bedrockは一般的に「トークン単位」で価格が設定されるため、長いプロンプトや大きな出力はより多くのコストがかかります。
結論
Amazon Bedrockは、アプリケーションにLLMを統合するための強力で柔軟なプラットフォームです。多くのモデルへのアクセスを提供し、開発を簡素化し、堅牢なカスタマイズおよびセキュリティ機能を提供します。これにより、開発者はユーザーに価値を提供することに集中しながら、生成AIの力を活用できます。本記事では、基本的なBedrock統合を開始し、プロンプトを整理する方法を示します。
AIが進化するにつれて、開発者はAmazon Bedrockの最新機能やベストプラクティスを把握し、AIアプリケーションを構築する必要があります。
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide