













Conforme l’IA generativa rivoluziona varie industrie, i programmatori cercano sempre più modi efficienti per integrare modelli linguistici di grandi dimensioni (LLM) nelle loro applicazioni. Amazon Bedrock è una soluzione potente. Offre un servizio completamente gestito che fornisce accesso a una vasta gamma di modelli di base attraverso un’API unificata. Questa guida esplorerà i principali vantaggi di Amazon Bedrock, come integrare diversi modelli LLM nei tuoi progetti, come semplificare la gestione delle varie istanze di LLM che la tua applicazione utilizza e le migliori pratiche da considerare per un utilizzo in produzione.
Vantaggi chiave di Amazon Bedrock
Amazon Bedrock semplifica l’integrazione iniziale dei LLM in qualsiasi applicazione fornendo tutte le capacità di base necessarie per iniziare.
Accesso Semplificato ai Modelli Principali
Bedrock fornisce accesso a una vasta selezione di modelli di base ad alte prestazioni di leader del settore come AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon. Questa varietà consente ai programmatori di scegliere il modello più adatto al loro caso d’uso e di cambiarlo secondo necessità senza gestire molteplici relazioni con fornitori o API.
Completamente Gestito e Serverless
Come servizio completamente gestito, Bedrock elimina la necessità di gestire l’infrastruttura. Ciò consente ai programmatori di concentrarsi sulla costruzione delle applicazioni anziché preoccuparsi delle complessità sottostanti della configurazione dell’infrastruttura, del rilascio dei modelli e della scalabilità.
Sicurezza e Privacy di Livello Enterprise
Bedrock offre funzionalità di sicurezza integrate, garantendo che i dati non lascino mai i tuoi ambienti AWS ed siano crittografati in transito e a riposo. Supporta inoltre la conformità con vari standard, tra cui ISO, SOC e HIPAA.
Rimani Aggiornato con gli Ultimi Miglioramenti dell’Infrastruttura
Bedrock rilascia regolarmente nuove funzionalità che spingono i limiti delle applicazioni LLM e richiedono poco o nessun setup. Ad esempio, ha recentemente rilasciato una modalità di inferenza ottimizzata che migliora la latenza dell’inferenza LLM senza comprometterne l’accuratezza.
Come Iniziare con Bedrock
In questa sezione, utilizzeremo l’SDK AWS per Python per creare un’applicazione di piccole dimensioni sul tuo computer locale, fornendo una guida pratica per iniziare con Amazon Bedrock. Questo ti aiuterà a comprendere gli aspetti pratici dell’uso di Bedrock e come integrarlo nei tuoi progetti.
Prerequisiti
- Hai un account AWS.
- Hai installato Python. Se non è installato, ottienilo seguendo questa guida.
- Hai installato e configurato correttamente l’SDK AWS per Python (Boto3). È consigliabile creare un utente AWS IAM che Boto3 possa utilizzare. Le istruzioni sono disponibili nella guida introduttiva di Boto3.
- Se si utilizza un utente IAM, assicurarsi di aggiungere la policy
AmazonBedrockFullAccess. È possibile allegare le policy utilizzando la console AWS. - Richiedere l’accesso a 1 o più modelli su Bedrock seguendo questa guida.
1. Creazione del client Bedrock
Bedrock ha diversi client disponibili all’interno del AWS CDK. Il client Bedrock consente di interagire con il servizio per creare e gestire modelli, mentre il client BedrockRuntime consente di invocare modelli esistenti. Utilizzeremo uno dei modelli di base già esistenti per il nostro tutorial, quindi lavoreremo con il client BedrockRuntime.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. Invocazione del modello
In questo esempio, ho utilizzato il modello Amazon Nova Micro (con modelId amazon.nova-micro-v1:0), uno dei modelli più economici di Bedrock. Forniremo un semplice prompt per chiedere al modello di scriverci una poesia e impostare i parametri per controllare la lunghezza dell’output e il livello di creatività (chiamato “temperatura”) che il modello dovrebbe fornire. Sentiti libero di sperimentare con prompt diversi e regolare i parametri per vedere come influenzano l’output.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Possiamo anche provare con un altro modello come Haiku di Anthropic, come mostrato di seguito.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Si noti che le strutture di richiesta/risposta variano leggermente tra i modelli. Questo è un inconveniente che affronteremo utilizzando modelli di prompt predefiniti nella sezione successiva. Per sperimentare con altri modelli, è possibile cercare il modelId e le richieste API di esempio per ciascun modello nella pagina del “Catalogo dei Modelli” nella console Bedrock e adattare il proprio codice di conseguenza. Alcuni modelli hanno anche guide dettagliate scritte da AWS, che è possibile trovare qui.
3. Utilizzo della Gestione dei Prompt
Bedrock fornisce uno strumento intelligente per creare e sperimentare con modelli di prompt predefiniti. Invece di definire prompt e parametri specifici come lunghezza del token o temperatura nel proprio codice ogni volta che ne ha bisogno, è possibile creare modelli predefiniti nella console di Gestione dei Prompt. Si specificano le variabili di input che verranno iniettate durante l’esecuzione, si configurano tutti i parametri di inferenza richiesti e si pubblica una versione del proprio prompt. Una volta fatto ciò, il codice dell’applicazione può invocare la versione desiderata del proprio modello di prompt.
Vantaggi chiave nell’utilizzo di prompt predefiniti:
- Aiuta l’applicazione a rimanere organizzata man mano che cresce e utilizza prompt, parametri e modelli diversi per vari casi d’uso.
- Aiuta nel riutilizzo dei prompt se lo stesso prompt viene utilizzato in più luoghi.
- Occulta i dettagli dell’inferenza di LLM dal codice dell’applicazione.
- Permette agli ingegneri di prompt di lavorare sull’ottimizzazione dei prompt nella console senza dover modificare il proprio codice di applicazione effettivo.
- Consente di sperimentare facilmente, sfruttando diverse versioni di prompt. Puoi modificare l’input del prompt, i parametri come la temperatura o persino il modello stesso.
Proviamolo ora:
- Vai alla console Bedrock e clicca su “Gestione dei prompt” nel pannello di sinistra.
- Clicca su “Crea Prompt” e dai un nome al tuo nuovo prompt
- Inserisci il testo che desideriamo inviare al LLM, insieme a una variabile segnaposto. Ho usato
Scrivi una breve poesia su un {{argomento}}. - Nella sezione Configurazione, specifica quale modello desideri utilizzare e imposta i valori degli stessi parametri utilizzati in precedenza, come “Temperatura” e “Numero massimo di token.” Se preferisci, puoi lasciare i valori predefiniti.
- È ora di testare! In fondo alla pagina, fornisci un valore per la tua variabile di test. Ho usato “Eroe dello sviluppo software.” Quindi, clicca su “Esegui” sulla destra per vedere se sei soddisfatto del risultato.
Per riferimento, ecco la mia configurazione e i risultati.
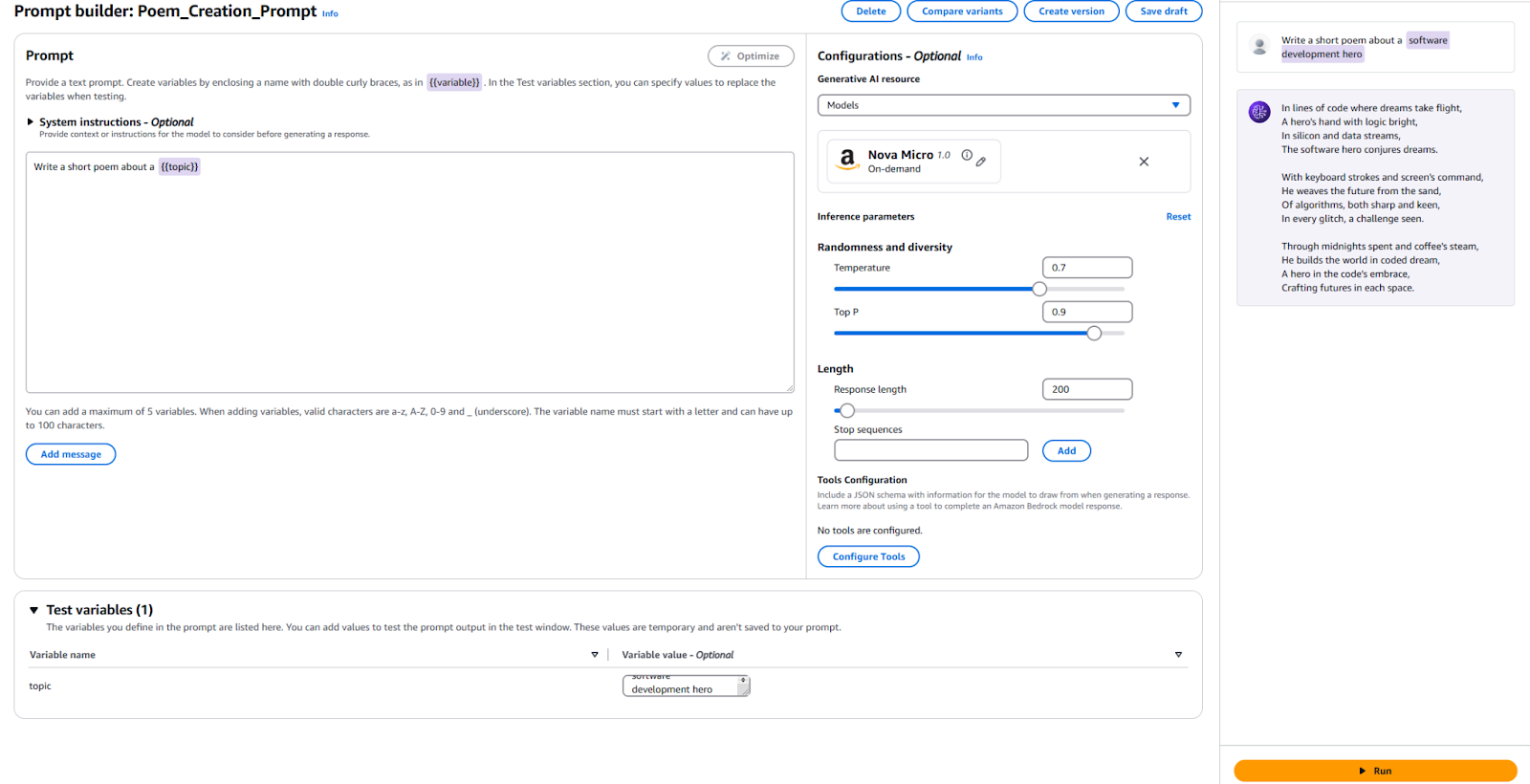
È necessario pubblicare una nuova versione del Prompt per utilizzare questo Prompt nella tua applicazione. Per farlo, clicca sul pulsante “Crea versione” in alto. Questo crea uno snapshot della tua configurazione attuale. Se desideri fare delle prove, puoi continuare a modificare e creare più versioni.
Una volta pubblicato, è necessario trovare l’ARN (Amazon Resource Name) della Versione del Prompt navigando alla pagina del tuo Prompt e cliccando sulla versione appena creata.

Copia l’ARN di questa specifica versione del prompt da utilizzare nel tuo codice.

Una volta che abbiamo l’ARN, possiamo aggiornare il nostro codice per invocare questo prompt predefinito. Abbiamo solo bisogno dell’ARN della versione del prompt e dei valori per qualsiasi variabile che inseriamo in esso.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Come puoi vedere, questo semplifica il nostro codice dell’applicazione astrattendo i dettagli dell’inferenza LLM e promuovendo la riutilizzabilità. Sentiti libero di giocare con i parametri all’interno del tuo prompt, creare diverse versioni e usarle nella tua applicazione. Potresti estendere questo in una semplice applicazione da riga di comando che prende in input dell’utente e scrive una breve poesia su quel tema.
Passaggi successivi e migliori pratiche
Una volta a tuo agio nell’usare Bedrock per integrare un LLM nella tua applicazione, esplora alcune considerazioni pratiche e le migliori pratiche per preparare la tua applicazione per un utilizzo in produzione.
Ingegneria del Prompt
Il prompt che usi per invocare il modello può fare la differenza nella tua applicazione. L’ingegneria del prompt è il processo di creazione e ottimizzazione delle istruzioni per ottenere l’output desiderato da un LLM. Con i modelli di prompt predefiniti esplorati sopra, gli ingegneri di prompt esperti possono iniziare con l’ingegneria del prompt senza interferire con il processo di sviluppo software della tua applicazione. Potresti dover adattare il tuo prompt in modo specifico al modello che desideri utilizzare. Familiarizzati con le tecniche di prompt specifiche per ciascun fornitore di modelli. Bedrock fornisce alcune linee guida per i modelli di dimensioni maggiori.
Selezione del Modello
Fare la scelta del modello giusto è un equilibrio tra le esigenze della tua applicazione e i costi sostenuti. I modelli più capaci tendono ad essere più costosi. Non tutti i casi d’uso richiedono il modello più potente, mentre i modelli più economici potrebbero non sempre offrire le prestazioni di cui hai bisogno. Utilizza la funzionalità di Valutazione del Modello per valutare e confrontare rapidamente gli output dei diversi modelli per determinare quale soddisfa meglio le tue esigenze. Bedrock offre molteplici opzioni per caricare set di dati di test e configurare come valutare l’accuratezza del modello per casi d’uso individuali.
Raffina ed Estendi il Tuo Modello con RAG e Agenti
Se un modello pronto all’uso non è abbastanza efficace per te, Bedrock offre opzioni per ottimizzare il modello per il tuo caso specifico. Crea i tuoi dati di addestramento, caricarli su S3 e utilizza la console Bedrock per avviare un lavoro di raffinamento. Puoi anche estendere i tuoi modelli utilizzando tecniche come la generazione potenziata da recupero (RAG) per migliorare le prestazioni per casi d’uso specifici. Collega le sorgenti di dati esistenti che Bedrock renderà disponibili al modello per arricchire la sua conoscenza. Bedrock offre anche la possibilità di creare agenti per pianificare ed eseguire compiti complessi a più passaggi utilizzando i sistemi e le sorgenti di dati aziendali esistenti.
Sicurezza e Linee Guida
Con Guardrails, puoi assicurarti che la tua applicazione generativa eviti con garbo argomenti sensibili (come il razzismo, i contenuti sessuali e le volgarità) e che il contenuto generato sia basato per prevenire allucinazioni. Questa funzionalità è cruciale per mantenere gli standard etici e professionali delle tue applicazioni. Sfrutta le funzionalità di sicurezza integrate di Bedrock e integrarle con i tuoi controlli di sicurezza AWS esistenti.
Ottimizzazione dei costi
Prima di rilasciare ampiamente la tua applicazione o funzionalità, considera i costi che l’inferenza di Bedrock e le estensioni come RAG comporteranno.
- Se riesci a prevedere i tuoi modelli di traffico, considera l’utilizzo del Throughput Pianificato per un’inferenza del modello più efficiente e conveniente dal punto di vista dei costi.
- Se la tua applicazione è composta da più funzionalità, puoi utilizzare modelli e suggerimenti diversi per ogni funzionalità per ottimizzare i costi su base individuale.
- Rivedi la tua scelta di modello così come la dimensione del suggerimento che fornisci per ciascuna inferenza. In generale, Bedrock stabilisce i prezzi sulla base “per token”, quindi suggerimenti più lunghi e output più grandi comporteranno maggiori costi.
Conclusione
Amazon Bedrock è una piattaforma potente e flessibile per integrare LLM nelle applicazioni. Fornisce accesso a molti modelli, semplifica lo sviluppo e offre robuste funzionalità di personalizzazione e sicurezza. Pertanto, gli sviluppatori possono sfruttare il potere dell’IA generativa concentrandosi sulla creazione di valore per i propri utenti. Questo articolo mostra come iniziare con un’importante integrazione di Bedrock e mantenere organizzati i nostri Suggerimenti.
Con l’evoluzione dell’IA, gli sviluppatori dovrebbero rimanere aggiornati sulle ultime funzionalità e le migliori pratiche in Amazon Bedrock per costruire le loro applicazioni di intelligenza artificiale.
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide