













À medida que a IA generativa revoluciona diversas indústrias, os desenvolvedores buscam cada vez mais maneiras eficientes de integrar grandes modelos de linguagem (LLMs) em suas aplicações. O Amazon Bedrock é uma solução poderosa. Ele oferece um serviço totalmente gerenciado que fornece acesso a uma ampla gama de modelos fundamentais por meio de uma API unificada. Este guia explorará os principais benefícios do Amazon Bedrock, como integrar diferentes modelos LLM em seus projetos, como simplificar a gestão dos vários prompts LLM que sua aplicação utiliza e as melhores práticas a serem consideradas para uso em produção.
Principais Benefícios do Amazon Bedrock
Amazon Bedrock simplifica a integração inicial de LLMs em qualquer aplicação, fornecendo todas as capacidades fundamentais necessárias para começar.
Acesso Simplificado a Modelos Líderes
O Bedrock oferece acesso a uma seleção diversificada de modelos fundamentais de alto desempenho de líderes da indústria, como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon. Essa variedade permite que os desenvolvedores escolham o modelo mais adequado para seu caso de uso e troquem de modelos conforme necessário, sem gerenciar múltiplos relacionamentos com fornecedores ou APIs.
Totalmente Gerenciado e Sem Servidor
Como um serviço totalmente gerenciado, o Bedrock elimina a necessidade de gerenciamento de infraestrutura. Isso permite que os desenvolvedores se concentrem na construção de aplicações, em vez de se preocuparem com as complexidades subjacentes da configuração da infraestrutura, implantação de modelos e escalabilidade.
Segurança e Privacidade de Nível Empresarial
O Bedrock oferece recursos de segurança integrados, garantindo que os dados nunca deixem seus ambientes AWS e sejam criptografados em trânsito e em repouso. Ele também suporta conformidade com vários padrões, incluindo ISO, SOC e HIPAA.
Mantenha-se Atualizado Com as Últimas Melhorias de Infraestrutura
O Bedrock lança regularmente novos recursos que ampliam os limites das aplicações LLM e requerem pouca ou nenhuma configuração. Por exemplo, recentemente lançou um modo de inferência otimizado que melhora a latência de inferência do LLM sem comprometer a precisão.
Começando com o Bedrock
Nesta seção, usaremos o AWS SDK para Python para construir um pequeno aplicativo em sua máquina local, fornecendo um guia prático para começar a usar o Amazon Bedrock. Isso ajudará você a entender os aspectos práticos de usar o Bedrock e como integrá-lo em seus projetos.
Pré-requisitos
- Você possui uma conta AWS.
- Você tem o Python instalado. Se não estiver instalado, obtenha-o seguindo este guia.
- Você tem o AWS SDK para Python (Boto3) instalado e configurado corretamente. Recomenda-se criar um usuário IAM da AWS que o Boto3 possa usar. As instruções estão disponíveis no guia rápido do Boto3.
- Se você estiver usando um usuário IAM, certifique-se de adicionar a política
AmazonBedrockFullAccessa ele. Você pode anexar políticas usando o console da AWS. - Solicite acesso a 1 ou mais modelos no Bedrock seguindo este guia.
1. Criando o Cliente Bedrock
O Bedrock possui múltiplos clientes disponíveis dentro do AWS CDK. O cliente Bedrock permite que você interaja com o serviço para criar e gerenciar modelos, enquanto o cliente BedrockRuntime permite que você invoque modelos existentes. Usaremos um dos modelos fundacionais prontos existentes para nosso tutorial, então vamos trabalhar apenas com o cliente BedrockRuntime.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. Invocando o Modelo
Neste exemplo, usei o modelo Amazon Nova Micro (com modelId amazon.nova-micro-v1:0), um dos modelos mais baratos do Bedrock. Vamos fornecer um prompt simples para pedir ao modelo que nos escreva um poema e definir parâmetros para controlar o comprimento da saída e o nível de criatividade (chamado de “temperatura”) que o modelo deve fornecer. Sinta-se à vontade para brincar com diferentes prompts e ajustar parâmetros para ver como eles impactam a saída.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Também podemos tentar isso com outro modelo como o Haiku da Anthropic, conforme mostrado abaixo.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Observe que as estruturas de solicitação/resposta variam ligeiramente entre os modelos. Este é um inconveniente que abordaremos utilizando modelos de prompt pré-definidos na próxima seção. Para experimentar outros modelos, você pode consultar o modelId e exemplos de solicitações de API para cada modelo na página “Catálogo de Modelos” no console do Bedrock e ajustar seu código de acordo. Alguns modelos também têm guias detalhados escritos pela AWS, que você pode encontrar aqui.
3. Usando Gerenciamento de Prompt
O Bedrock fornece uma ferramenta útil para criar e experimentar com modelos de prompt pré-definidos. Em vez de definir prompts e parâmetros específicos, como comprimentos de token ou temperatura, em seu código toda vez que precisar deles, você pode criar modelos pré-definidos no console de Gerenciamento de Prompt. Você especifica variáveis de entrada que serão injetadas durante a execução, configura todos os parâmetros de inferência necessários e publica uma versão do seu prompt. Uma vez feito, seu código de aplicativo pode invocar a versão desejada do seu modelo de prompt.
Principais vantagens de usar prompts pré-definidos:
- Ajuda seu aplicativo a se manter organizado à medida que cresce e utiliza diferentes prompts, parâmetros e modelos para vários casos de uso.
- Ajuda na reutilização de prompts se o mesmo prompt for usado em vários lugares.
- Abstrai os detalhes da inferência de LLM do nosso código de aplicativo.
- Permite que engenheiros de prompt trabalhem na otimização de prompts no console sem tocar no seu código de aplicativo real.
- Permite fácil experimentação, aproveitando diferentes versões de prompts. Você pode ajustar a entrada do prompt, parâmetros como temperatura ou até mesmo o modelo em si.
Vamos tentar isso agora:
- Vá para o console do Bedrock e clique em “Gerenciamento de Prompts” no painel esquerdo.
- Clique em “Criar Prompt” e dê um nome ao seu novo prompt
- Insira o texto que queremos enviar para o LLM, junto com uma variável de espaço reservado. Eu usei
Escreva um poema curto sobre um {{tópico}}. - No seção de Configuração, especifique qual modelo você deseja usar e defina os valores dos mesmos parâmetros que usamos anteriormente, como “Temperatura” e “Máximos Tokens.” Se preferir, você pode deixar os padrões como estão.
- É hora de testar! Na parte inferior da página, forneça um valor para sua variável de teste. Eu usei “Herói do Desenvolvimento de Software.” Em seguida, clique em “Executar” à direita para ver se você está satisfeito com a saída.
Para referência, aqui está minha configuração e os resultados.
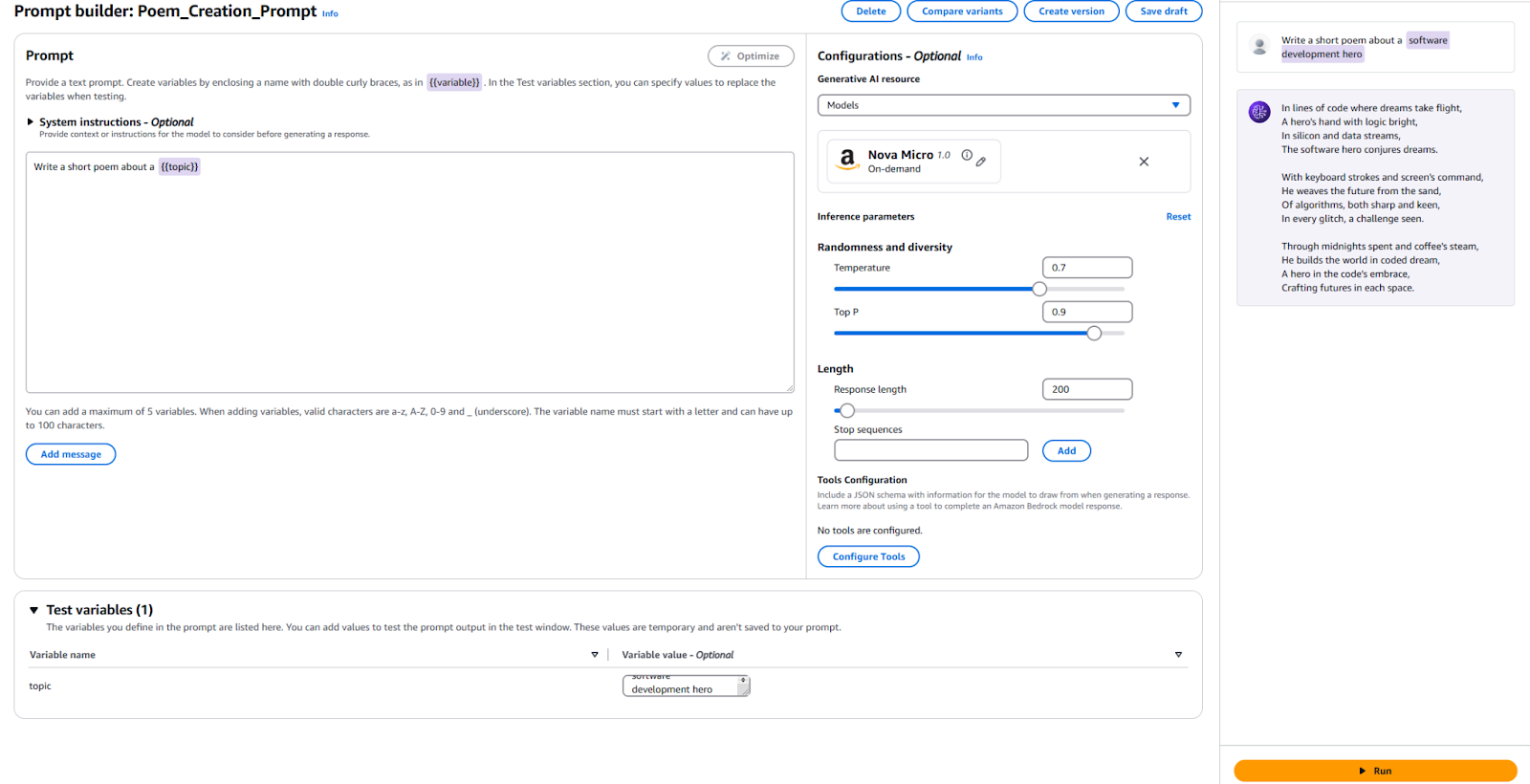
Precisamos publicar uma nova Versão de Prompt para usar este Prompt em sua aplicação. Para fazer isso, clique no botão “Criar Versão” na parte superior. Isso cria uma captura instantânea da sua configuração atual. Se você quiser brincar com isso, pode continuar editando e criando mais versões.
Uma vez publicada, precisamos encontrar o ARN (Nome do Recurso da Amazon) da Versão do Prompt navegando até a página do seu Prompt e clicando na versão recém-criada.

Copie o ARN desta versão específica do prompt para usar em seu código.

Uma vez que temos o ARN, podemos atualizar nosso código para invocar este prompt pré-definido. Precisamos apenas do ARN da versão do prompt e dos valores para quaisquer variáveis que injetamos nele.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Como você pode ver, isso simplifica nosso código de aplicação ao abstrair os detalhes da inferência LLM e promover a reutilização. Sinta-se à vontade para brincar com os parâmetros dentro do seu prompt, criar versões diferentes e usá-las em sua aplicação. Você pode expandir isso para um simples aplicativo de linha de comando que recebe a entrada do usuário e escreve um poema curto sobre esse tema.
Próximos Passos e Melhores Práticas
Uma vez que você esteja confortável usando o Bedrock para integrar um LLM em sua aplicação, explore algumas considerações práticas e melhores práticas para preparar sua aplicação para uso em produção.
Engenharia de Prompt
O prompt que você usa para invocar o modelo pode fazer ou quebrar sua aplicação. A engenharia de prompt é o processo de criar e otimizar instruções para obter a saída desejada de um LLM. Com os templates de prompt pré-definidos explorados acima, engenheiros de prompt habilidosos podem começar a engenharia de prompt sem interferir no processo de desenvolvimento de software da sua aplicação. Você pode precisar adaptar seu prompt para ser específico ao modelo que deseja usar. Familiarize-se com técnicas de prompt específicas de cada provedor de modelo. O Bedrock fornece algumas diretrizes para modelos grandes comuns.
Seleção de Modelo
Fazer a escolha do modelo certo é um equilíbrio entre as necessidades da sua aplicação e o custo incorrido. Modelos mais capazes tendem a ser mais caros. Nem todos os casos de uso exigem o modelo mais poderoso, enquanto modelos mais baratos podem não fornecer sempre o desempenho que você precisa. Use o recurso Avaliação de Modelos para avaliar e comparar rapidamente as saídas de diferentes modelos para determinar qual atende melhor às suas necessidades. O Bedrock oferece várias opções para enviar conjuntos de dados de teste e configurar como a precisão do modelo deve ser avaliada para casos de uso individuais.
Aprimore e Amplie Seu Modelo Com RAG e Agentes
Se um modelo pronto não funcionar bem o suficiente para você, o Bedrock oferece opções para ajustar seu modelo ao seu caso de uso específico. Crie seus dados de treinamento, faça o upload para o S3 e use o console do Bedrock para iniciar um trabalho de ajuste fino. Você também pode ampliar seus modelos usando técnicas como geração aumentada por recuperação (RAG) para melhorar o desempenho em casos de uso específicos. Conecte fontes de dados existentes que o Bedrock disponibilizará para o modelo a fim de aprimorar seu conhecimento. O Bedrock também oferece a capacidade de criar agentes para planejar e executar tarefas complexas em múltiplas etapas usando seus sistemas e fontes de dados da empresa existentes.
Segurança e Diretrizes
Com Guardrails, você pode garantir que sua aplicação generativa evite suavemente tópicos sensíveis (por exemplo, racismo, conteúdo sexual e palavrões) e que o conteúdo gerado esteja fundamentado para evitar alucinações. Este recurso é crucial para manter os padrões éticos e profissionais de suas aplicações. Aproveite os recursos de segurança integrados do Bedrock e integre-os com seus controles de segurança existentes na AWS.
Otimização de Custos
Antes de lançar amplamente sua aplicação ou recurso, considere o custo que a inferência do Bedrock e extensões como RAG irão incorrer.
- Se você puder prever seus padrões de tráfego, considere usar Throughput Provisionado para uma inferência de modelo mais eficiente e econômica.
- Se sua aplicação consistir em vários recursos, você pode usar diferentes modelos e prompts para cada recurso a fim de otimizar os custos de forma individual.
- Reavalie sua escolha de modelo, bem como o tamanho do prompt que você fornece para cada inferência. O Bedrock geralmente cobra com base em “por token”, portanto, prompts mais longos e saídas maiores terão custos mais elevados.
Conclusão
Amazon Bedrock é uma plataforma poderosa e flexível para integrar LLMs em aplicações. Ela fornece acesso a muitos modelos, simplifica o desenvolvimento e oferece recursos robustos de personalização e segurança. Assim, os desenvolvedores podem aproveitar o poder da IA generativa enquanto se concentram em criar valor para seus usuários. Este artigo mostra como começar com uma integração essencial do Bedrock e manter nossos Prompts organizados.
À medida que a IA evolui, os desenvolvedores devem se manter atualizados com os recursos mais recentes e as melhores práticas no Amazon Bedrock para construir suas aplicações de IA.
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide