













Alors que l’IA générative révolutionne diverses industries, les développeurs cherchent de plus en plus des moyens efficaces d’intégrer de grands modèles de langage (LLM) dans leurs applications. Amazon Bedrock est une solution puissante. Il offre un service entièrement géré qui fournit un accès à une large gamme de modèles de base via une API unifiée. Ce guide explorera les principaux avantages d’Amazon Bedrock, comment intégrer différents modèles LLM dans vos projets, comment simplifier la gestion des diverses invitations LLM que votre application utilise, et les meilleures pratiques à considérer pour une utilisation en production.
Avantages clés d’Amazon Bedrock
Amazon Bedrock simplifie l’intégration initiale des LLM dans n’importe quelle application en fournissant toutes les capacités fondamentales nécessaires pour commencer.
Accès simplifié aux principaux modèles
Bedrock offre un accès à une sélection diversifiée de modèles de base performants de leaders de l’industrie tels que AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI et Amazon. Cette variété permet aux développeurs de choisir le modèle le plus adapté à leur cas d’utilisation et de changer de modèle au besoin sans gérer de multiples relations fournisseur ou APIs.
Entièrement géré et sans serveur
En tant que service entièrement géré, Bedrock élimine le besoin de gestion de l’infrastructure. Cela permet aux développeurs de se concentrer sur la création d’applications plutôt que de se soucier des complexités sous-jacentes de la configuration de l’infrastructure, du déploiement du modèle et de la mise à l’échelle.
Sécurité et confidentialité de qualité entreprise
Bedrock offre des fonctionnalités de sécurité intégrées, garantissant que les données ne quittent jamais vos environnements AWS et sont cryptées en transit et au repos. Il prend également en charge la conformité avec divers standards, notamment ISO, SOC et HIPAA.
Restez à jour avec les dernières améliorations d’infrastructure
Bedrock publie régulièrement de nouvelles fonctionnalités qui repoussent les limites des applications de LLM et nécessitent peu ou pas de configuration. Par exemple, il a récemment lancé un mode d’inférence optimisé qui améliore la latence d’inférence des LLM sans compromettre la précision.
Commencer avec Bedrock
Dans cette section, nous utiliserons le SDK AWS pour Python afin de créer une petite application sur votre machine locale, fournissant un guide pratique pour commencer avec Amazon Bedrock. Cela vous aidera à comprendre les aspects pratiques de l’utilisation de Bedrock et comment l’intégrer dans vos projets.
Prérequis
- Vous avez un compte AWS.
- Vous avez Python installé. Si ce n’est pas le cas, obtenez-le en suivant ce guide.
- Vous avez le SDK AWS pour Python (Boto3) installé et configuré correctement. Il est recommandé de créer un utilisateur IAM AWS que Boto3 peut utiliser. Des instructions sont disponibles dans le guide de démarrage rapide Boto3.
- Si vous utilisez un utilisateur IAM, assurez-vous d’ajouter la politique
AmazonBedrockFullAccessà celui-ci. Vous pouvez attacher des politiques en utilisant la console AWS. - Demandez l’accès à 1 ou plusieurs modèles sur Bedrock en suivant ce guide.
1. Création du client Bedrock
Bedrock dispose de plusieurs clients disponibles dans le CDK AWS. Le client Bedrock vous permet d’interagir avec le service pour créer et gérer des modèles, tandis que le client BedrockRuntime vous permet d’invoquer des modèles existants. Nous utiliserons l’un des modèles de base prêts à l’emploi pour notre tutoriel, donc nous allons simplement travailler avec le client BedrockRuntime.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
2. Invocation du modèle
Dans cet exemple, j’ai utilisé le modèle Amazon Nova Micro (avec modelId amazon.nova-micro-v1:0), l’un des modèles les moins chers de Bedrock. Nous fournirons une simple invite pour demander au modèle de nous écrire un poème et définir des paramètres pour contrôler la longueur de la sortie et le niveau de créativité (appelé « température ») que le modèle doit fournir. N’hésitez pas à jouer avec différentes invites et à ajuster les paramètres pour voir comment ils impactent la sortie.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'amazon.nova-micro-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"schemaVersion": "messages-v1",
"messages": [{"role": "user", "content": [{"text": "Write a short poem about a software development hero."}]}],
"inferenceConfig": {
"max_new_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Nous pouvons également essayer cela avec un autre modèle comme Haiku d’Anthropic, comme indiqué ci-dessous.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select a model (Feel free to play around with different models)
modelId = 'anthropic.claude-3-haiku-20240307-v1:0'
# Configure the request with the prompt and inference parameters
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"messages": [{"role": "user", "content": [{"type": "text", "text": "Write a short poem about a software development hero."}]}],
"max_tokens": 200, # Adjust for shorter or longer outputs.
"temperature": 0.7 # Increase for more creativity, decrease for more predictability
})
# Make the request to Bedrock
response = bedrock.invoke_model(body=body, modelId=modelId)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Notez que les structures de requête/réponse varient légèrement entre les modèles. C’est un inconvénient que nous aborderons en utilisant des modèles de prompt prédéfinis dans la section suivante. Pour expérimenter avec d’autres modèles, vous pouvez consulter le modelId et des exemples de requêtes API pour chaque modèle sur la page « Catalogue des modèles » dans la console Bedrock et ajuster votre code en conséquence. Certains modèles disposent également de guides détaillés rédigés par AWS, que vous pouvez trouver ici.
3. Gestion des prompts
Bedrock fournit un outil pratique pour créer et expérimenter avec des modèles de prompt prédéfinis. Au lieu de définir des prompts et des paramètres spécifiques tels que la longueur des tokens ou la température dans votre code chaque fois que vous en avez besoin, vous pouvez créer des modèles prédéfinis dans la console de gestion des prompts. Vous spécifiez les variables d’entrée qui seront injectées pendant l’exécution, configurez tous les paramètres d’inférence requis et publiez une version de votre prompt. Une fois cela fait, votre code d’application peut invoquer la version souhaitée de votre modèle de prompt.
Les principaux avantages de l’utilisation de prompts prédéfinis :
- Cela aide votre application à rester organisée à mesure qu’elle grandit et utilise différents prompts, paramètres et modèles pour divers cas d’utilisation.
- Cela facilite la réutilisation des prompts si le même prompt est utilisé à plusieurs endroits.
- Abstrait les détails de l’inférence LLM de notre code d’application.
- Permet aux ingénieurs de prompts de travailler sur l’optimisation des prompts dans la console sans toucher à votre code d’application réel.
- Cela permet de faciliter l’expérimentation, en tirant parti de différentes versions de prompts. Vous pouvez ajuster l’entrée du prompt, les paramètres comme la température, ou même le modèle lui-même.
Essayons cela maintenant :
- Allez dans la console Bedrock et cliquez sur « Gestion des Prompts » dans le panneau de gauche.
- Cliquez sur « Créer un Prompt » et donnez un nom à votre nouveau prompt
- Entrez le texte que nous souhaitons envoyer au LLM, ainsi qu’une variable de remplacement. J’ai utilisé
Écrire un court poème sur un {{sujet}}. - Dans la section Configuration, spécifiez quel modèle vous souhaitez utiliser et définissez les valeurs des mêmes paramètres que nous avons utilisés précédemment, tels que « Température » et « Max Tokens ». Si vous préférez, vous pouvez laisser les valeurs par défaut telles quelles.
- Il est temps de tester ! En bas de la page, fournissez une valeur pour votre variable de test. J’ai utilisé « Héros du Développement Logiciel ». Ensuite, cliquez sur « Exécuter » à droite pour voir si le résultat vous satisfait.
Pour référence, voici ma configuration et les résultats.
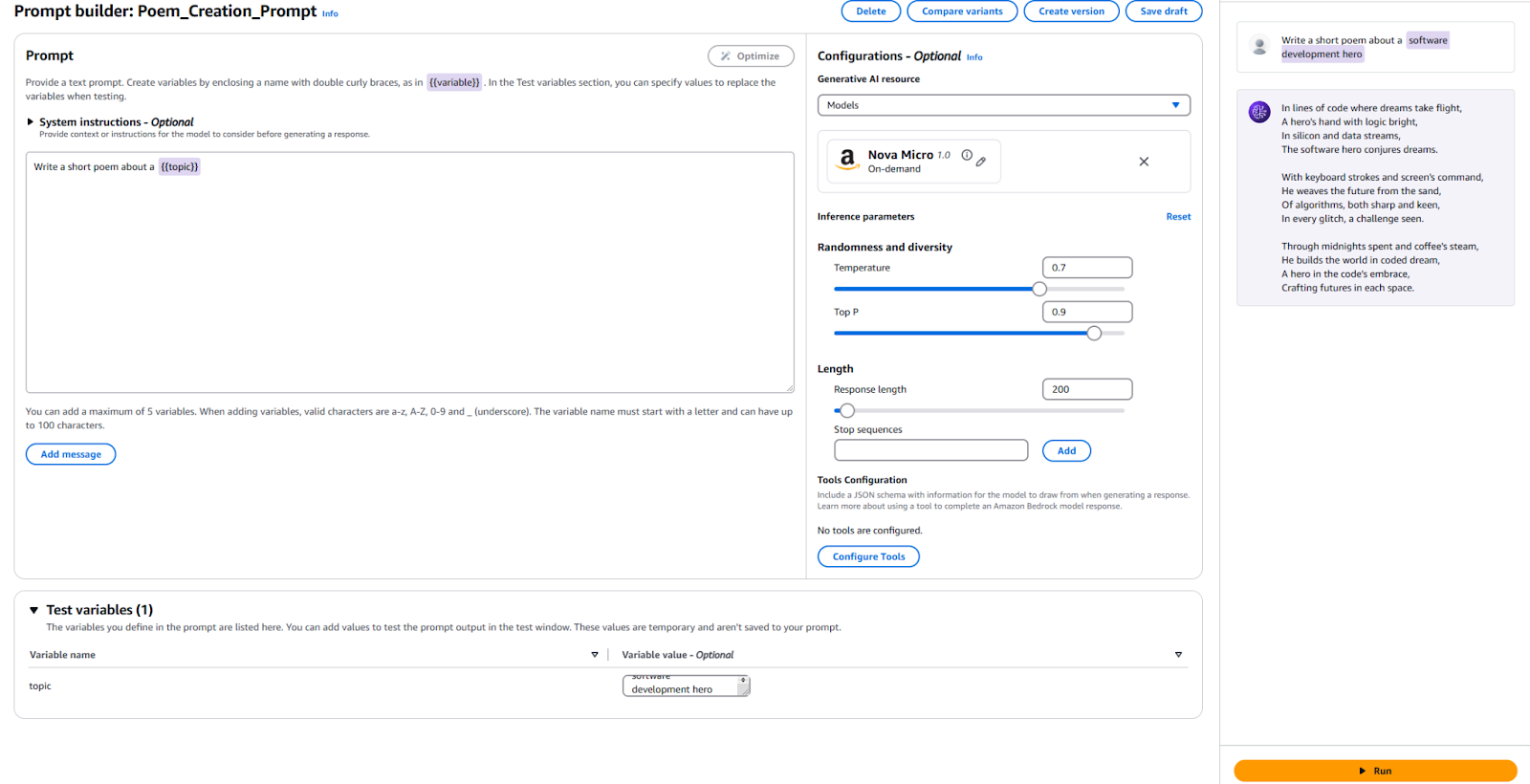
Nous devons publier une nouvelle Version de Prompt pour utiliser ce Prompt dans votre application. Pour ce faire, cliquez sur le bouton « Créer une Version » en haut. Cela crée un instantané de votre configuration actuelle. Si vous souhaitez expérimenter, vous pouvez continuer à éditer et à créer d’autres versions.
Une fois publié, nous devons trouver l’ARN (Amazon Resource Name) de la Version de Prompt en naviguant vers la page de votre Prompt et en cliquant sur la version nouvellement créée.

Copiez l’ARN de cette version spécifique du prompt pour l’utiliser dans votre code.

Une fois que nous avons l’ARN, nous pouvons mettre à jour notre code pour invoquer ce prompt prédéfini. Nous avons seulement besoin de l’ARN de la version du prompt et des valeurs pour toutes les variables que nous y injectons.
import boto3
import json
# Create a Bedrock client
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
# Select your prompt identifier and version
promptArn = "<ARN from the specific prompt version>"
# Define any required prompt variables
body = json.dumps({
"promptVariables": {
"topic":{"text":"software development hero"}
}
})
# Make the request to Bedrock
response = bedrock.invoke_model(modelId=promptArn, body=body)
# Process the response
response_body = json.loads(response.get('body').read())
print(response_body)
Comme vous pouvez le voir, cela simplifie notre code d’application en abstraisant les détails de l’inférence LLM et en favorisant la réutilisabilité. N’hésitez pas à expérimenter avec les paramètres de votre prompt, à créer différentes versions et à les utiliser dans votre application. Vous pourriez étendre cela en une simple application de ligne de commande qui prend l’entrée de l’utilisateur et écrit un court poème sur ce sujet.
Étapes suivantes et meilleures pratiques
Une fois que vous êtes à l’aise avec l’utilisation de Bedrock pour intégrer un LLM dans votre application, explorez quelques considérations pratiques et meilleures pratiques pour préparer votre application à une utilisation en production.
Ingénierie des prompts
Le prompt que vous utilisez pour invoquer le modèle peut faire ou défaire votre application. L’ingénierie des prompts est le processus de création et d’optimisation des instructions pour obtenir le résultat souhaité d’un LLM. Avec les modèles de prompts pré-définis explorés ci-dessus, des ingénieurs de prompts expérimentés peuvent commencer l’ingénierie des prompts sans interférer avec le processus de développement logiciel de votre application. Vous devrez peut-être adapter votre prompt pour qu’il soit spécifique au modèle que vous souhaitez utiliser. Familiarisez-vous avec les techniques de prompt spécifiques à chaque fournisseur de modèle. Bedrock fournit quelques directives pour les modèles généralement grands.
Sélection du modèle
Faire le bon choix de modèle est un équilibre entre les besoins de votre application et le coût engagé. Les modèles plus performants tendent à être plus chers. Tous les cas d’utilisation ne nécessitent pas le modèle le plus puissant, tandis que les modèles les moins chers ne fournissent pas toujours les performances dont vous avez besoin. Utilisez la fonctionnalité Évaluation du modèle pour évaluer et comparer rapidement les sorties de différents modèles afin de déterminer lequel répond le mieux à vos besoins. Bedrock propose plusieurs options pour télécharger des ensembles de données de test et configurer la manière dont la précision du modèle doit être évaluée pour des cas d’utilisation individuels.
Ajustez et étendez votre modèle avec RAG et des agents
Si un modèle prêt à l’emploi ne fonctionne pas assez bien pour vous, Bedrock offre des options pour ajuster votre modèle à votre cas d’utilisation spécifique. Créez vos données d’entraînement, téléchargez-les sur S3, et utilisez la console Bedrock pour initier un travail de réglage fin. Vous pouvez également étendre vos modèles en utilisant des techniques telles que la génération augmentée par récupération (RAG) pour améliorer les performances pour des cas d’utilisation spécifiques. Connectez des sources de données existantes que Bedrock mettra à disposition du modèle pour enrichir ses connaissances. Bedrock offre également la possibilité de créer des agents pour planifier et exécuter des tâches complexes en plusieurs étapes en utilisant vos systèmes et sources de données d’entreprise existants.
Sécurité et garde-fous
Avec Guardrails, vous pouvez vous assurer que votre application générative évite gracieusement les sujets sensibles (par exemple, le racisme, le contenu sexuel et les jurons) et que le contenu généré est ancré pour prévenir les hallucinations. Cette fonctionnalité est cruciale pour maintenir les standards éthiques et professionnels de vos applications. Profitez des fonctionnalités de sécurité intégrées de Bedrock et intégrez-les avec vos contrôles de sécurité AWS existants.
Optimisation des coûts
Avant de publier largement votre application ou votre fonctionnalité, envisagez le coût que l’inférence Bedrock et les extensions telles que RAG entraîneront.
- Si vous pouvez prédire vos modèles de trafic, envisagez d’utiliser le Débit Provisionné pour une inférence de modèle plus efficace et rentable.
- Si votre application se compose de plusieurs fonctionnalités, vous pouvez utiliser différents modèles et invites pour chaque fonctionnalité afin d’optimiser les coûts individuellement.
- Revisitez votre choix de modèle ainsi que la taille de l’invite que vous fournissez pour chaque inférence. Bedrock facture généralement sur une base « par jeton », donc des invites plus longues et des sorties plus importantes entraîneront des coûts plus élevés.
Conclusion
Amazon Bedrock est une plateforme puissante et flexible pour intégrer des LLM dans des applications. Elle donne accès à de nombreux modèles, simplifie le développement et offre des fonctionnalités de personnalisation et de sécurité robustes. Ainsi, les développeurs peuvent exploiter la puissance de l’IA générative tout en se concentrant sur la création de valeur pour leurs utilisateurs. Cet article montre comment commencer avec une intégration essentielle de Bedrock et garder nos invites organisées.
À mesure que l’IA évolue, les développeurs doivent rester informés des dernières fonctionnalités et des meilleures pratiques dans Amazon Bedrock pour créer leurs applications d’IA.
Source:
https://dzone.com/articles/amazon-bedrock-prompts-llm-integration-guide