













효율적인 데이터베이스 관리는 대규모 데이터셋을 처리하면서 최적의 성능과 유지보수 편의성을 유지하는 데 중요합니다. PostgreSQL에서의 테이블 파티셔닝은 대형 테이블을 파티션이라 불리는 작은 관리 가능한 조각으로 논리적으로 분할하는 견고한 방법입니다. 이 기술은 쿼리 성능을 향상시키고 유지보수 작업을 간소화하며 저장 비용을 줄이는 데 도움이 됩니다.

이 글은 PostgreSQL에서의 테이블 파티셔닝을 생성하고 관리하는 데 깊이 파고들며, 시간 기반 및 일련 번호 기반 파티셔닝을 위한 pg_partman 확장 기능에 초점을 맞춥니다. PostgreSQL에서 지원하는 파티션 유형에 대해 자세히 설명하고, 실제 사용 사례 및 구현을 설명하는 실용적인 예시도 함께 다룹니다.
소개
현대 애플리케이션은 대량의 데이터를 생성하여 이러한 양을 처리하기 위한 효율적인 데이터베이스 관리 전략이 필요합니다. 테이블 파티셔닝은 대형 테이블을 작고 논리적으로 관련된 세그먼트로 분할하는 기술입니다. PostgreSQL은 이러한 데이터셋을 효과적으로 관리하기 위한 견고한 파티셔닝 프레임워크를 제공합니다.
파티셔닝의 필요성
- 쿼리 성능 향상. 쿼리가 제약 조건 제외 또는 쿼리 가지치기를 사용하여 관련 없는 파티션을 빠르게 건너뛸 수 있습니다.
- 유지보수 간소화. 파티션별 작업(예: vacuuming 또는 reindexing)을 작은 데이터셋에서 수행할 수 있습니다.
- 효율적인 아카이빙. 이전 파티션을 삭제하거나 아카이빙할 수 있으며 활성 데이터셋에 영향을 미치지 않습니다.
- 확장성. 파티셔닝은 특히 분산 환경에서 수평 확장을 가능하게 합니다.
네이티브 vs 확장 기반 파티셔닝
PostgreSQL의 네이티브 선언적 파티셔닝은 파티셔닝의 많은 측면을 단순화하며, pg_partman과 같은 확장은 특히 동적 사용 사례에 대해 추가적인 자동화 및 관리 기능을 제공합니다.
네이티브 파티셔닝 vs pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| 자동화 | 제한적 | 포괄적 |
| 파티션 유형 | 범위, 리스트, 해시 | 시간, 시리얼 (고급) |
| 유지 관리 | 수동 스크립트 필요 | 자동화됨 |
| 사용 용이성 | SQL 전문 지식 필요 | 단순화됨 |
PostgreSQL의 테이블 파티셔닝 유형
PostgreSQL은 세 가지 주요 파티셔닝 전략: 범위, 리스트 및 해시를 지원합니다. 각 전략은 다양한 사용 사례에 적합한 고유한 특성을 가지고 있습니다.
범위 파티셔닝
범위 파티셔닝은 특정 열의 값 범위를 기준으로 테이블을 파티션으로 나누며, 일반적으로 날짜나 숫자 열을 사용합니다.
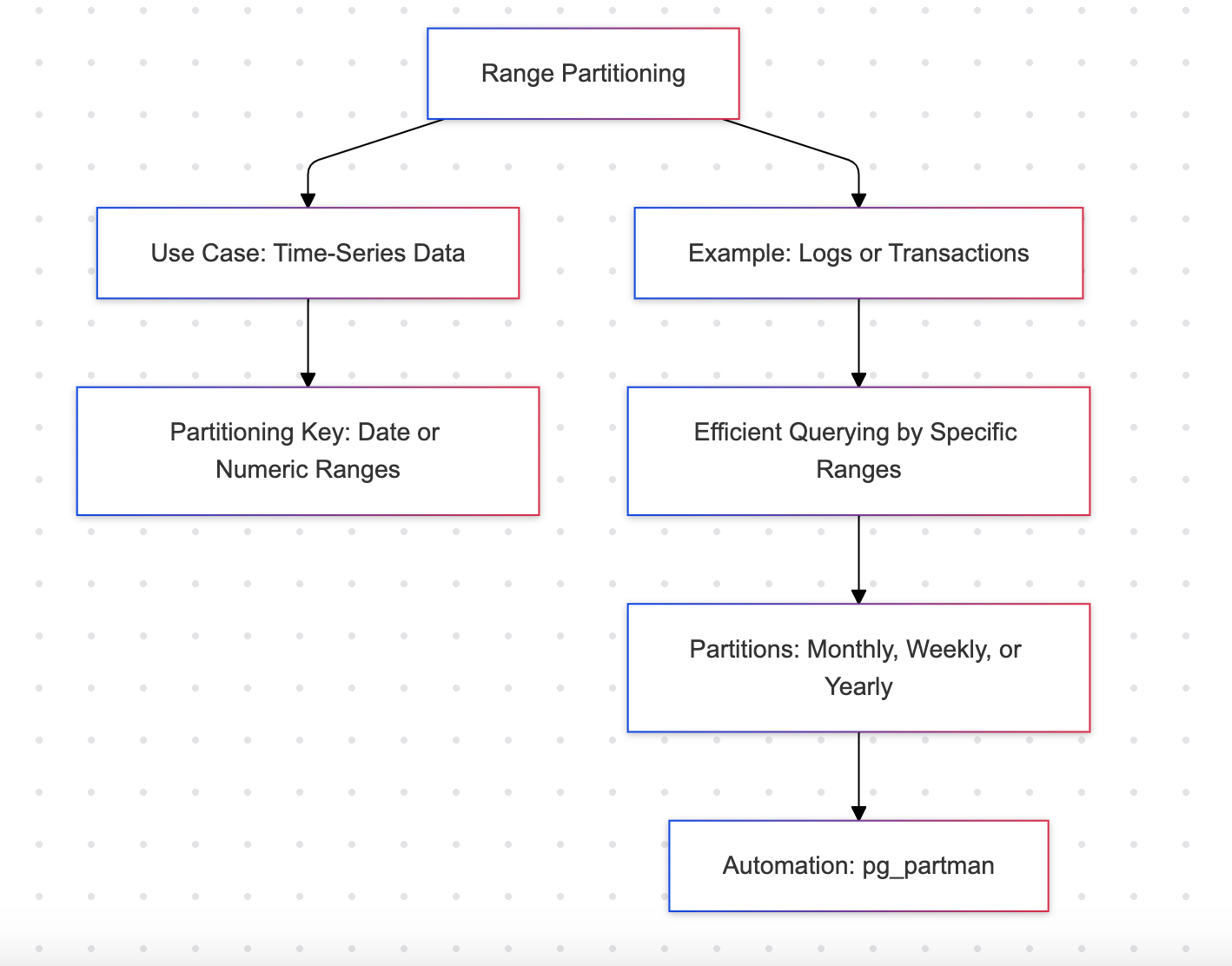
예: 월별 판매 데이터
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
장점
- 로그나 트랜잭션과 같은 시계열 데이터에 효율적
- 특정 월에 대한 데이터 검색과 같은 순차적 쿼리를 지원합니다.
단점
- 미리 정의된 범위가 필요하여 스키마 업데이트가 빈번할 수 있음
리스트 파티셔닝
리스트 파티셔닝은 지역 또는 카테고리와 같은 이산 집합의 값에 따라 데이터를 분할함
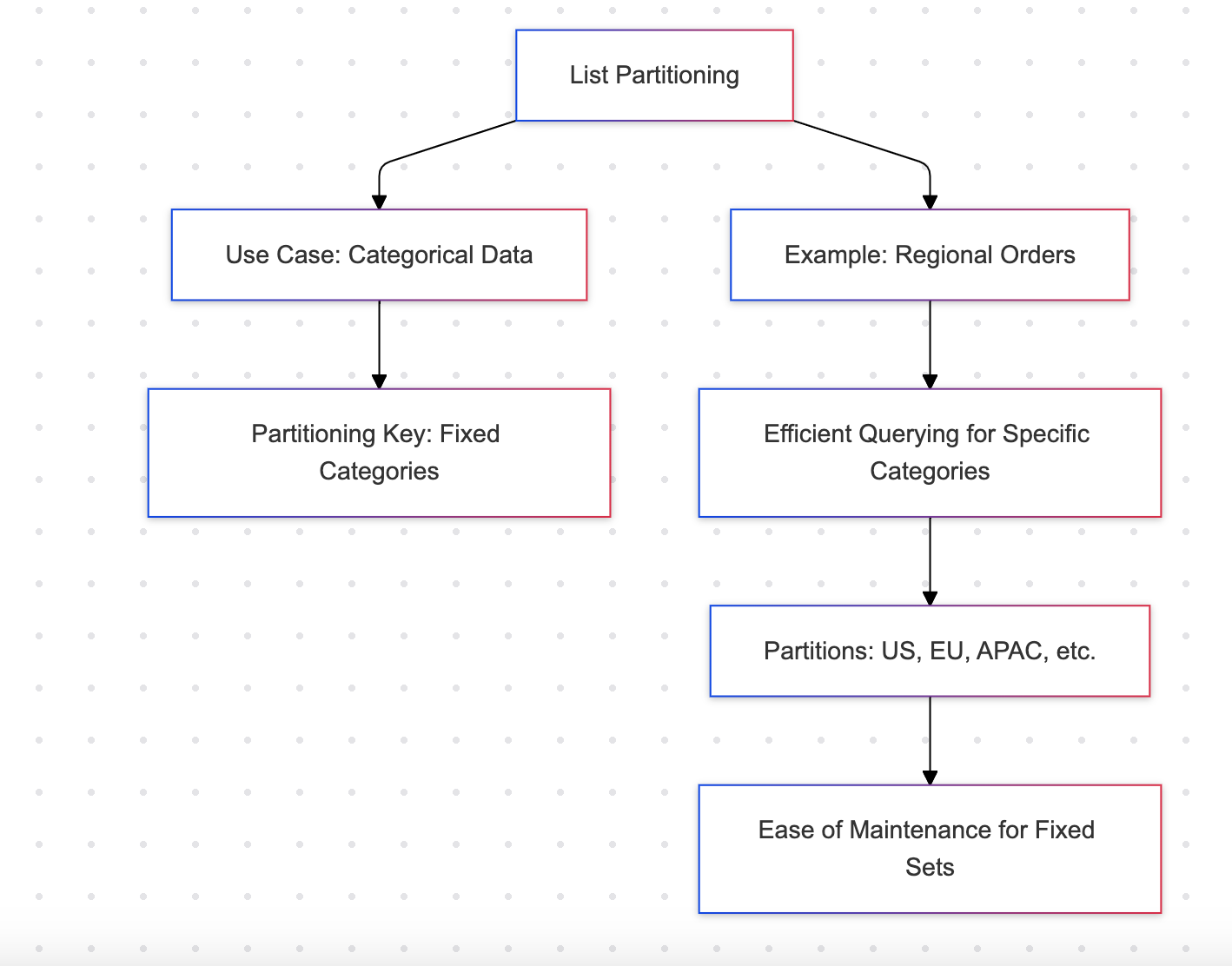
예: 지역 주문
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');
장점
- 유한한 카테고리(예: 지역, 부서)를 가진 데이터 세트에 이상적임
- 고정된 파티션 집합을 관리하기 쉬움
단점
- 동적이거나 확장 중인 카테고리에 적합하지 않음
해시 파티셔닝
해시 파티셔닝은 해시 함수를 사용하여 행을 파티션의 집합에 분산함. 이를 통해 데이터의 균등한 분배가 보장됨
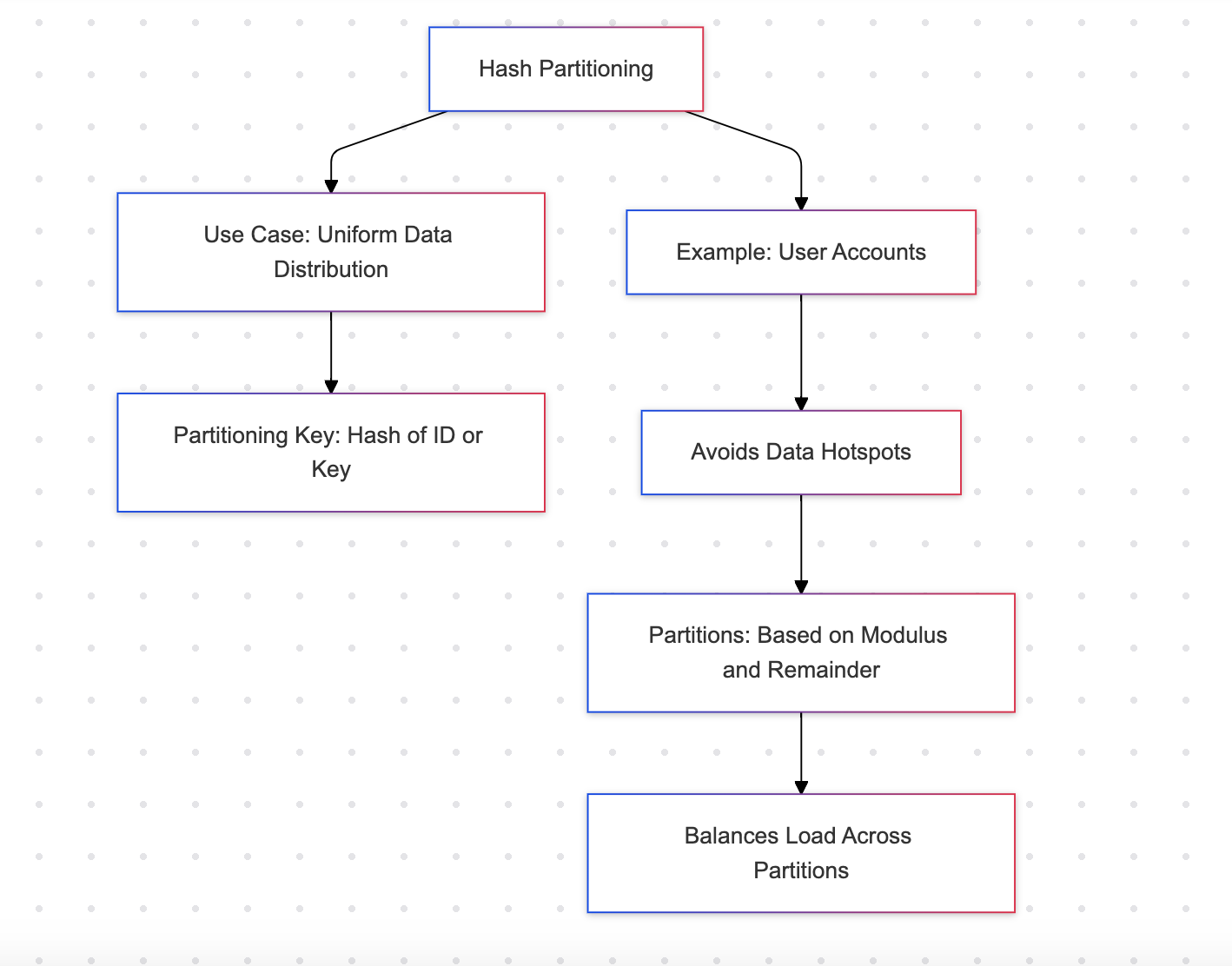
예: 사용자 계정
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
장점
- 핫스팟을 방지하면서 파티션 간 균형있는 분배를 보장함
- 균일하게 퍼져 있는 워크로드에 적합함
단점
- 사람이 읽기 어려우며, 파티션을 직관적으로 식별할 수 없음
pg_partman: 포괄적인 가이드
pg_partman은 PostgreSQL 확장 기능으로, 특히 시간 기반 및 일련 번호 기반 데이터 세트의 파티션 관리를 간소화함
설치 및 설정
pg_partman은 PostgreSQL에서 확장 기능으로 설치되어야 함. 파티션된 테이블을 동적으로 생성하고 관리하기 위한 일련의 함수를 제공함.
- 패키지 매니저를 사용하여 설치하십시오:
쉘
sudo apt-get install postgresql-pg-partman - 데이터베이스에서 확장 기능을 생성하십시오:
SQL
CREATE EXTENSION pg_partman;
파티셔닝 구성
pg_partman은 시간 기반 및 일련 번호 기반의 파티셔닝을 지원하며, 시계열 데이터 또는 연속 식별자를 가진 데이터 세트에 특히 유용합니다.
시간 기반 파티셔닝 예시
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);
다음 구성:
- 매일 자동으로 파티션 생성
- 로그 데이터의 쿼리 및 유지관리 단순화
일련 번호 기반 파티셔닝 예시
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);
100,000개 행마다 파티션 생성으로 상위 테이블 관리 가능성 보장
자동화 기능
자동 유지보수
run_maintenance()를 사용하여 향후 파티션을 사전 생성하도록 설정:
SELECT partman.run_maintenance();
보존 정책
오래된 파티션 자동 삭제를 위한 보존 기간 정의:
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';
pg_partman의 장점
- 동적 파티션 생성 단순화
- 정리 및 유지관리 자동화
- 수동 스키마 업데이트 필요성 감소
테이블 파티셔닝의 실용적 사용 사례
- 로그 관리. 쉬운 아카이브 및 쿼리를 위해 일별로 파티션화된 고빈도 로그
- 다지역 데이터. 개선된 확장성을 위해 지역별 주문을 분할하는 전자상거래 시스템
- 시계열 데이터. 파티션화된 텔레메트리 데이터를 사용하는 IoT 애플리케이션
로그 관리
일일 또는 월별로 로그를 분할하여 고주파 데이터를 효율적으로 관리하십시오.
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);
다지역 데이터
지역별로 판매 또는 재고 데이터를 분할하여 확장성을 향상시키십시오.
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);
고용량 거래
인덱스가 비대해지는 것을 피하기 위해 일련 번호 ID로 거래를 분할하십시오.
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);
결론
테이블 분할은 대규모 데이터 집합을 관리하는 데 필수적인 기술입니다. PostgreSQL의 내장 기능과 pg_partman 확장 프로그램을 결합하여 동적 및 자동 분할 전략을 구현하는 것이 더 쉬워집니다. 이러한 도구들은 데이터베이스 관리자가 성능을 향상시키고 유지 관리를 간소화하며 효율적으로 확장할 수 있도록 지원합니다.
분할은 특히 고용량 애플리케이션에서 현대 데이터베이스 관리의 중추적인 부분입니다. 이러한 개념을 이해하고 적용함으로써 견고하고 확장 가능한 데이터베이스 시스템을 보장할 수 있습니다.
Source:
https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management