













Effizientes Datenbankmanagement ist entscheidend für den Umgang mit großen Datensätzen, während optimale Leistung und Wartungsfreundlichkeit aufrechterhalten werden. Die Tabellenpartitionierung in PostgreSQL ist eine robuste Methode, um eine große Tabelle logisch in kleinere, handhabbare Teile zu unterteilen, die als Partitionen bezeichnet werden. Diese Technik hilft, die Abfrageleistung zu verbessern, Wartungsaufgaben zu vereinfachen und die Speicherkosten zu senken.

Dieser Artikel beschäftigt sich eingehend mit der Erstellung und Verwaltung von Tabellenpartitionen in PostgreSQL, mit einem Fokus auf die pg_partman-Erweiterung für zeitbasierte und serienbasierte Partitionierung. Die Arten von Partitionen, die in PostgreSQL unterstützt werden, werden ausführlich besprochen, zusammen mit realen Anwendungsfällen und praktischen Beispielen zur Veranschaulichung ihrer Implementierung.
Einführung
Moderne Anwendungen erzeugen enorme Datenmengen, die effiziente Datenbankmanagement-Strategien erfordern, um mit diesen Volumina umzugehen. Die Tabellenpartitionierung ist eine Technik, bei der eine große Tabelle in kleinere, logisch verwandte Segmente unterteilt wird. PostgreSQL bietet ein robustes Partitionierungsframework, um solche Datensätze effektiv zu verwalten.
Warum Partitionierung?
- Verbesserte Abfrageleistung. Abfragen können schnell irrelevante Partitionen mithilfe von Einschränkungsausschluss oder Abfragebeschneidung überspringen.
- Vereinfachte Wartung. Partition-spezifische Operationen wie das Vacuumieren oder Reindizieren können auf kleineren Datensätzen durchgeführt werden.
- Effizientes Archivieren. Ältere Partitionen können ohne Auswirkungen auf den aktiven Datensatz gelöscht oder archiviert werden.
- Skalierbarkeit. Partitionierung ermöglicht horizontale Skalierung, insbesondere in verteilten Umgebungen.
Native vs Erweiterungsbasierte Partitionierung
Die native deklarative Partitionierung von PostgreSQL vereinfacht viele Aspekte der Partitionierung, während Erweiterungen wie pg_partman zusätzliche Automatisierungs- und Verwaltungsmöglichkeiten bieten, insbesondere für dynamische Anwendungsfälle.
Native Partitionierung vs pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| Automatisierung | Begrenzt | Umfassend |
| Partitionstypen | Bereich, Liste, Hash | Zeit, Serie (fortgeschritten) |
| Wartung | Manuelle Skripte erforderlich | Automatisiert |
| Benutzerfreundlichkeit | Benötigt SQL-Expertise | Vereinfachte |
Arten der Tabellenpartitionierung in PostgreSQL
PostgreSQL unterstützt drei primäre Partitionierungsstrategien: Bereich, Liste und Hash. Jede hat einzigartige Merkmale, die für unterschiedliche Anwendungsfälle geeignet sind.
Bereichspartitionierung
Die Bereichspartitionierung teilt eine Tabelle in Partitionen auf, basierend auf einem Bereich von Werten in einer bestimmten Spalte, oft einer Daten- oder Zahlen-Spalte.
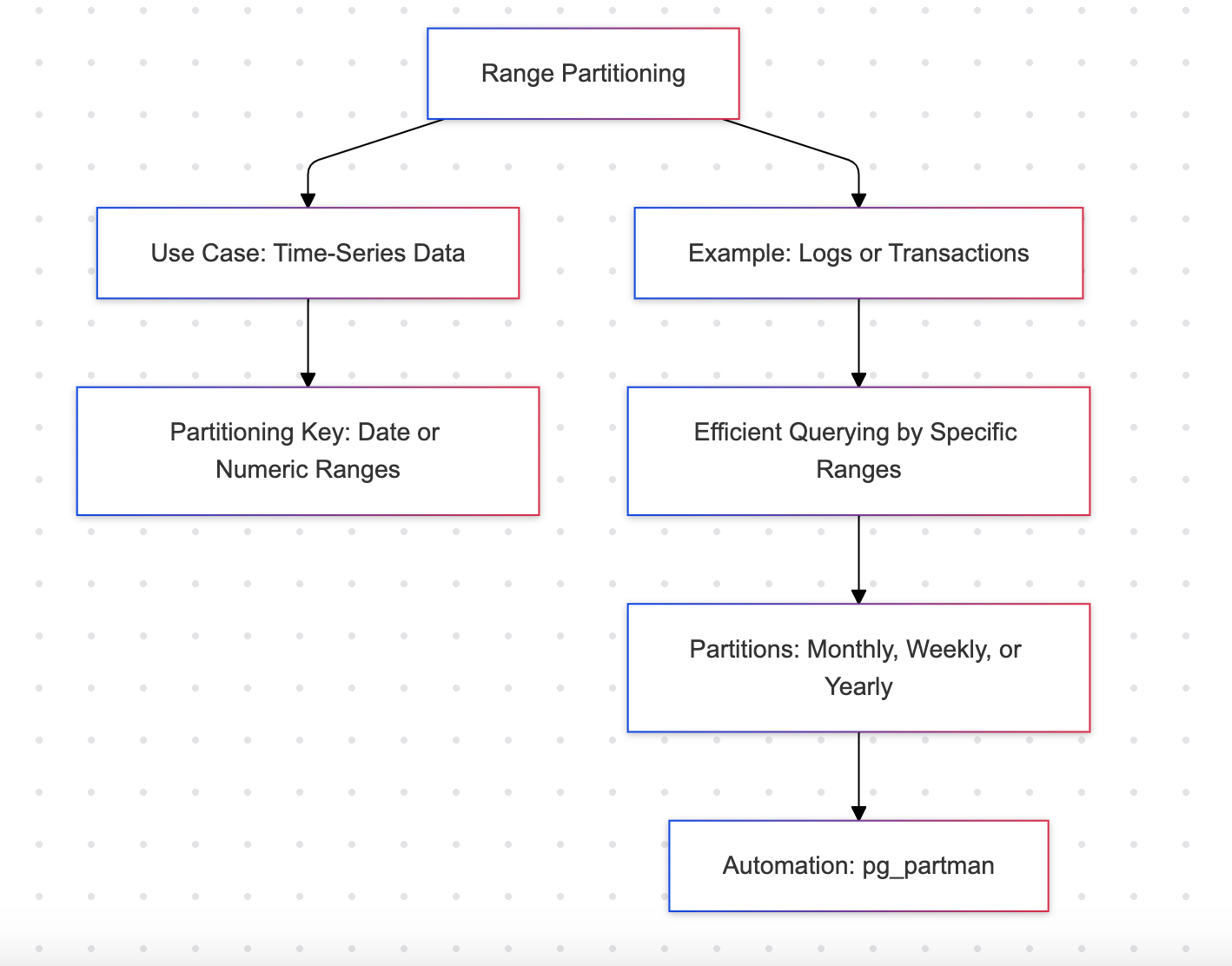
Beispiel: Monatliche Verkaufsdaten
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
Vorteile
- Effizient für zeitbasierte Daten wie Protokolle oder Transaktionen
- Unterstützt sequenzielle Abfragen, wie das Abrufen von Daten für bestimmte Monate
Nachteile
- Erfordert vordefinierte Bereiche, was zu häufigen Schema-Updates führen kann
Listenpartitionierung
Die Listenpartitionierung teilt Daten basierend auf einer diskreten Menge von Werten, wie Regionen oder Kategorien.
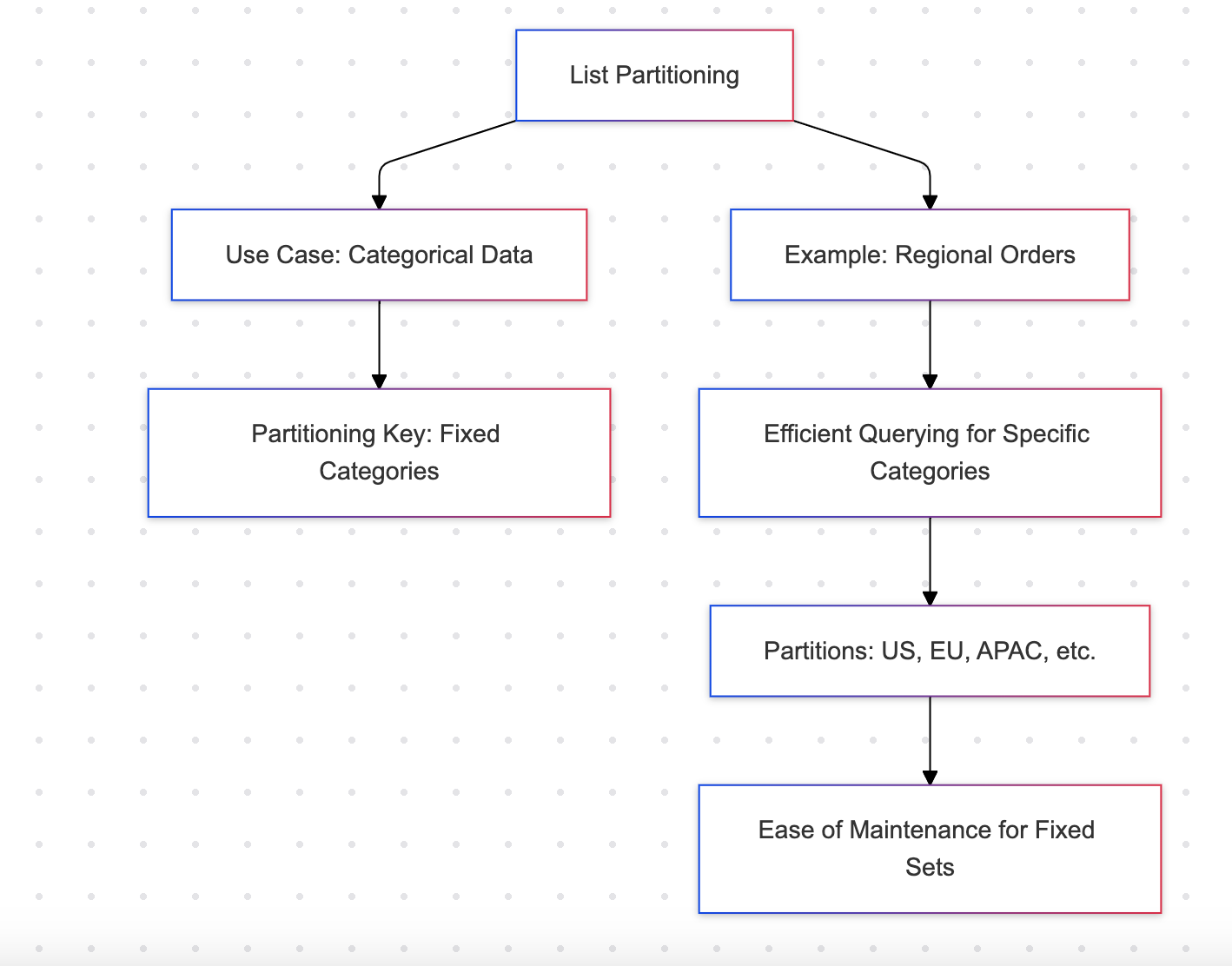
Beispiel: Regionale Bestellungen
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');
Vorteile
- Ideal für Datensätze mit einer endlichen Anzahl von Kategorien (z. B. Regionen, Abteilungen)
- Einfach zu verwalten für eine feste Menge von Partitionen
Nachteile
- Nicht geeignet für dynamische oder erweiterbare Kategorien
Hash-Partitionierung
Die Hash-Partitionierung verteilt Zeilen über eine Menge von Partitionen mithilfe einer Hash-Funktion. Dies gewährleistet eine gleichmäßige Verteilung der Daten.
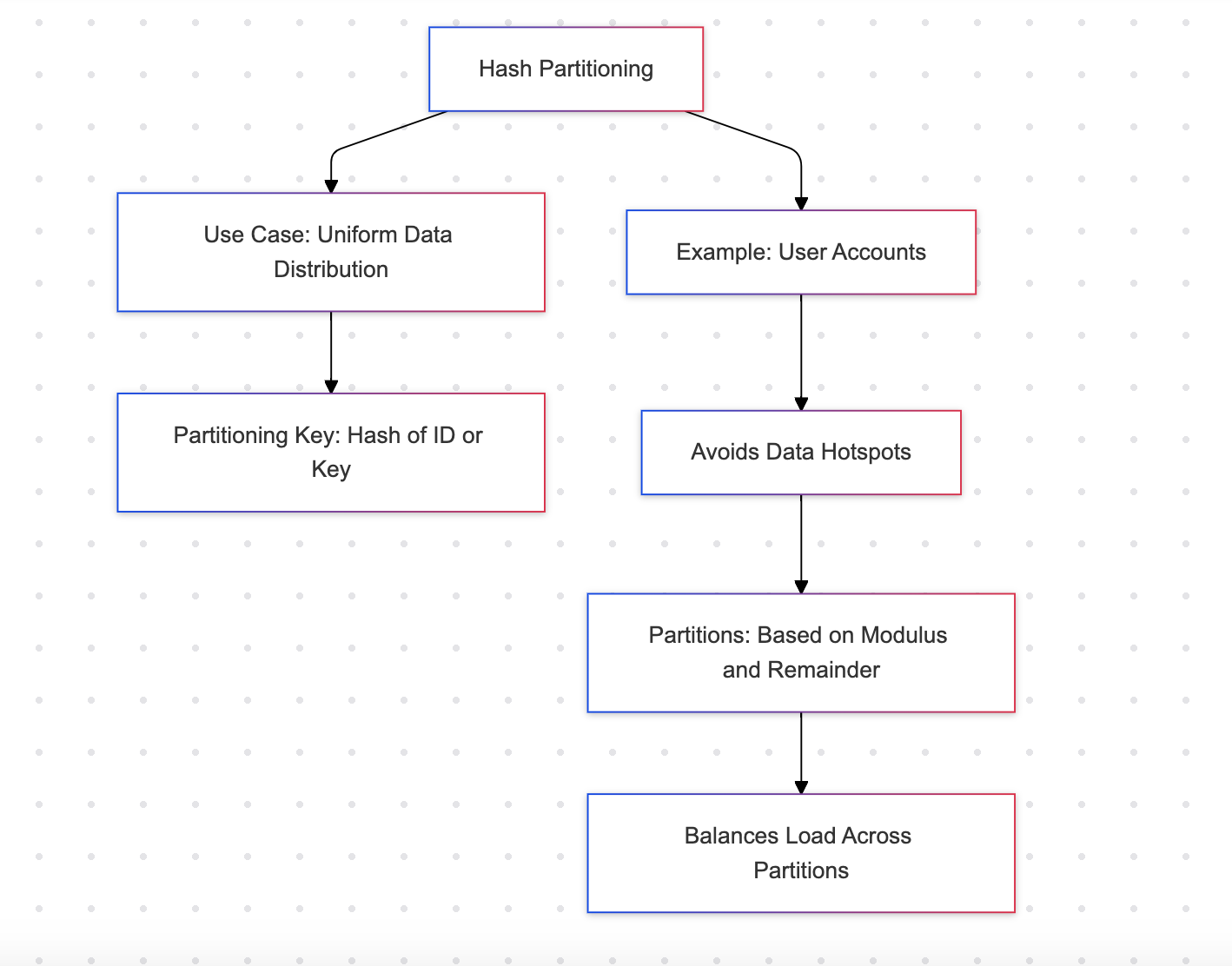
Beispiel: Benutzerkonten
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
Vorteile
- Gewährleistet eine ausgewogene Verteilung über Partitionen, wodurch Hotspots verhindert werden
- Geeignet für gleichmäßig verteilte Arbeitslasten
Nachteile
- Nicht menschenlesbar; Partitionen können nicht intuitiv identifiziert werden
pg_partman: Ein umfassender Leitfaden
pg_partman ist eine PostgreSQL-Erweiterung, die das Partitionmanagement vereinfacht, insbesondere für zeitbasierte und serienbasierte Datensätze.
Installation und Einrichtung
pg_partman erfordert die Installation als Erweiterung in PostgreSQL. Es bietet eine Suite von Funktionen zur dynamischen Erstellung und Verwaltung von partitionierten Tabellen.
- Installieren Sie es mit Ihrem Paketmanager:
Shell
sudo apt-get install postgresql-pg-partman - Erstellen Sie die Erweiterung in Ihrer Datenbank:
SQL
ERSTELLEN ERWEITERUNG pg_partman;
Konfigurieren der Partitionierung
pg_partman unterstützt zeitbasierte und serienbasierte Partitionierung, die besonders nützlich für Datensätze mit zeitlichen Daten oder sequenziellen Identifikatoren sind.
Beispiel für zeitbasierte Partitionierung
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);
Diese Konfiguration:
- Erstellt automatisch tägliche Partitionen
- Vereinfacht Abfragen und Wartung für Protokolldaten
Beispiel für serienbasierte Partitionierung
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);
Dadurch werden Partitionen alle 100.000 Zeilen erstellt, um sicherzustellen, dass die Elterntabelle handhabbar bleibt.
Automatisierungsfunktionen
Automatische Wartung
Verwenden Sie run_maintenance(), um sicherzustellen, dass zukünftige Partitionen vorab erstellt werden:
SELECT partman.run_maintenance();
Retention-Policies
Definieren Sie Aufbewahrungsfristen, um alte Partitionen automatisch zu löschen:
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';
Vorteile von pg_partman
- Vereinfacht die dynamische Partitionserstellung
- Automatisiert Bereinigung und Wartung
- Reduziert die Notwendigkeit manueller Schemupdates
Praktische Anwendungsfälle für die Tabellenpartitionierung
- Protokollverwaltung. Hochfrequente Protokolle werden nach Tag partitioniert für einfache Archivierung und Abfrage.
- Multiregionale Daten. E-Commerce-Systeme teilen Bestellungen nach Regionen auf zur Verbesserung der Skalierbarkeit.
- Zeitreihendaten. IoT-Anwendungen mit partitionierten Telemetriedaten.
Protokollverwaltung
Protokolliere die Daten nach Tag oder Monat, um hochfrequente Daten effizient zu verwalten.
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);
Multiregionale Daten
Unterteile Verkaufs- oder Lagerdaten nach Region für eine bessere Skalierbarkeit.
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);
Transaktionen mit hohem Volumen
Unterteile Transaktionen nach Seriennummer ID, um aufgeblähte Indizes zu vermeiden.
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);
Schlussfolgerung
Die Tabellenpartitionierung ist eine unverzichtbare Technik zur Verwaltung großer Datensätze. Die integrierten Funktionen von PostgreSQL in Kombination mit der Erweiterung pg_partman erleichtern die Implementierung dynamischer und automatisierter Partitionierungsstrategien. Diese Tools ermöglichen es Datenbankadministratoren, die Leistung zu verbessern, die Wartung zu vereinfachen und effektiv zu skalieren.
Partitionierung ist ein Eckpfeiler für das moderne Datenbankmanagement, insbesondere in Anwendungen mit hohem Volumen. Das Verständnis und die Anwendung dieser Konzepte gewährleisten robuste und skalierbare Datenbanksysteme.
Source:
https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management