













Une gestion efficace de la base de données est essentielle pour traiter de grands ensembles de données tout en maintenant des performances optimales et une facilité de maintenance. La partition de table dans PostgreSQL est une méthode robuste pour diviser logiquement une grande table en plus petites parties gérables appelées partitions. Cette technique aide à améliorer les performances des requêtes, simplifier les tâches de maintenance et réduire les coûts de stockage.

Cet article plonge profondément dans la création et la gestion de la partition de table dans PostgreSQL, en mettant l’accent sur l’extension pg_partman pour la partitionnement basé sur le temps et le sérial. Les types de partitions pris en charge dans PostgreSQL sont discutés en détail, ainsi que des cas d’utilisation du monde réel et des exemples pratiques pour illustrer leur mise en œuvre.
Introduction
Les applications modernes génèrent des quantités massives de données, nécessitant des stratégies efficaces de gestion de base de données pour gérer ces volumes. La partition de table est une technique où une grande table est divisée en segments plus petits et logiquement liés. PostgreSQL offre un cadre de partitionnement robuste pour gérer efficacement de tels ensembles de données.
Pourquoi partitionner ?
- Amélioration des performances des requêtes. Les requêtes peuvent rapidement sauter les partitions non pertinentes en utilisant l’exclusion de contrainte ou l’élagage des requêtes.
- Simplification de la maintenance. Les opérations spécifiques aux partitions telles que l’aspiration ou la réindexation peuvent être effectuées sur des ensembles de données plus petits.
- Archivage efficace. Les partitions plus anciennes peuvent être supprimées ou archivées sans affecter l’ensemble de données actif.
- Scalabilité. La partition permet une mise à l’échelle horizontale, notamment dans des environnements distribués.
Partitionnement natif vs basé sur une extension
Le partitionnement déclaratif natif de PostgreSQL simplifie de nombreux aspects du partitionnement, tandis que des extensions comme pg_partman offrent des capacités supplémentaires d’automatisation et de gestion, notamment pour des cas d’utilisation dynamiques.
Partitionnement natif vs pg_partman
| Feature | Native Partitioning | pg_partman |
|---|---|---|
| Automatisation | Limitée | Complète |
| Types de partitionnement | Plage, Liste, Hachage | Temps, Série (avancé) |
| Maintenance | Scripts manuels requis | Automatisée |
| Facilité d’utilisation | Requiert une expertise SQL | Simplifiée |
Types de partitionnement de table dans PostgreSQL
PostgreSQL prend en charge trois stratégies de partitionnement principales : Plage, Liste et Hachage. Chacune a des caractéristiques uniques adaptées à différents cas d’utilisation.
Partitionnement par plage
Le partitionnement par plage divise une table en partitions en fonction d’une plage de valeurs dans une colonne spécifique, souvent une colonne de date ou numérique.
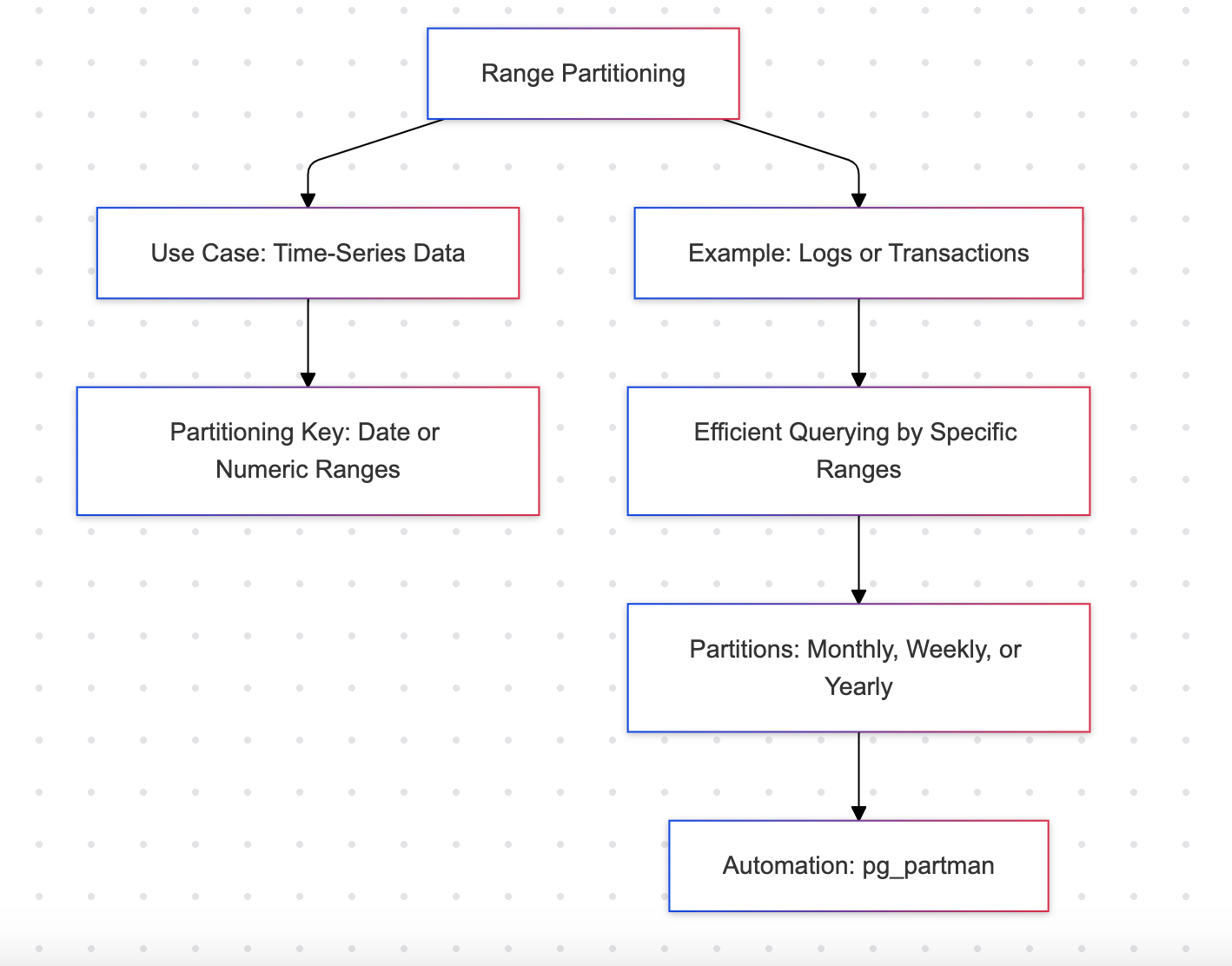
Exemple : Données de ventes mensuelles
CREATE TABLE sales (
sale_id SERIAL,
sale_date DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2023_01 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
Avantages
- Efficient pour les données de séries temporelles comme les journaux ou les transactions
- Prise en charge des requêtes séquentielles, telles que la récupération de données pour des mois spécifiques
Inconvénients
- Requiert des plages prédéfinies, ce qui peut entraîner des mises à jour fréquentes du schéma
Partitionnement par liste
Le partitionnement par liste divise les données en fonction d’un ensemble discret de valeurs, telles que des régions ou des catégories.
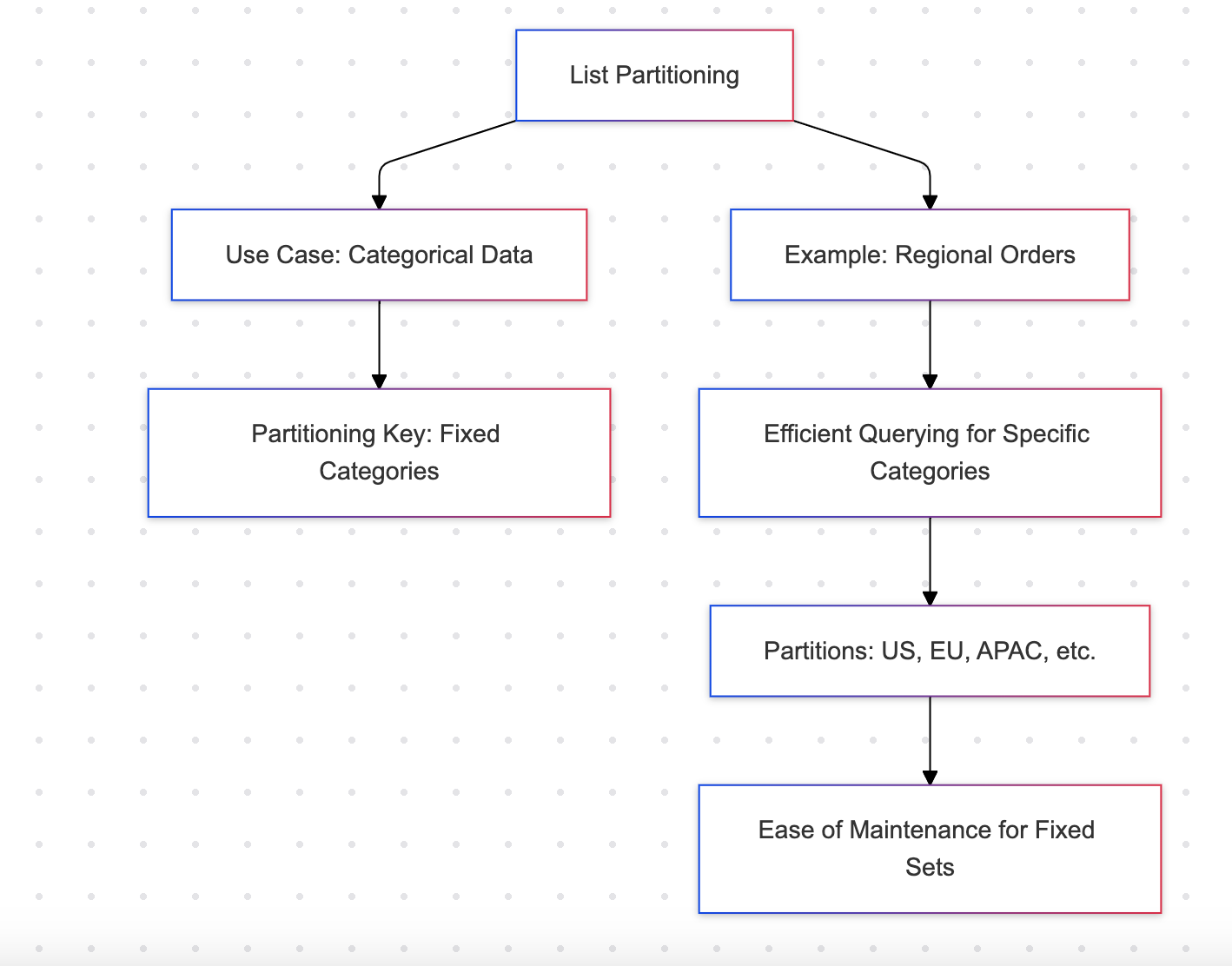
Exemple : Commandes régionales
CREATE TABLE orders (
order_id SERIAL,
region TEXT NOT NULL,
amount NUMERIC
) PARTITION BY LIST (region);
CREATE TABLE orders_us PARTITION OF orders FOR VALUES IN ('US');
CREATE TABLE orders_eu PARTITION OF orders FOR VALUES IN ('EU');
Avantages
- Idéal pour les ensembles de données avec un nombre fini de catégories (par exemple, régions, départements)
- Facile à gérer pour un ensemble fixe de partitions
Inconvénients
- Non adapté aux catégories dynamiques ou en expansion
Partitionnement par hachage
Le partitionnement par hachage distribue les lignes à travers un ensemble de partitions en utilisant une fonction de hachage. Cela garantit une répartition équilibrée des données.
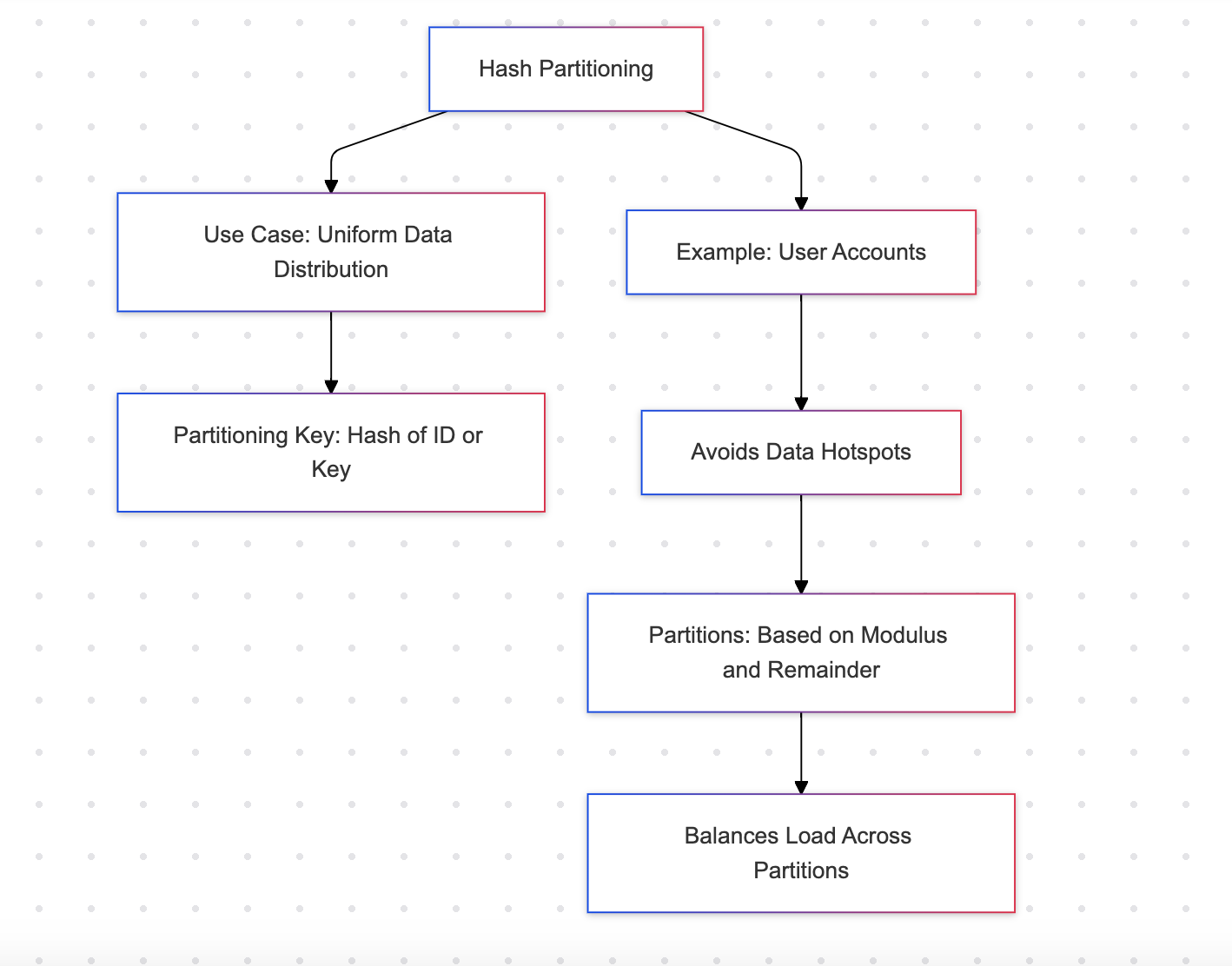
Exemple : Comptes utilisateurs
CREATE TABLE users (
user_id SERIAL,
username TEXT NOT NULL
) PARTITION BY HASH (user_id);
CREATE TABLE users_partition_0 PARTITION OF users
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
Avantages
- Assure une distribution équilibrée à travers les partitions, empêchant les points chauds
- Adapté aux charges de travail uniformément réparties
Inconvénients
- Non lisible par l’humain ; les partitions ne peuvent pas être identifiées de manière intuitive
pg_partman : Un guide complet
pg_partman est une extension PostgreSQL qui simplifie la gestion des partitions, notamment pour les ensembles de données basés sur le temps et les séries.
Installation et configuration
pg_partman nécessite une installation en tant qu’extension dans PostgreSQL. Il fournit un ensemble de fonctions pour créer et gérer dynamiquement des tables partitionnées.
- Installez en utilisant votre gestionnaire de paquets :
Shell
sudo apt-get install postgresql-pg-partman - Créez l’extension dans votre base de données :
SQL
CREATE EXTENSION pg_partman;
La configuration de la partition
pg_partman prend en charge la partition basée sur le temps et la partition basée sur le séquentiel, qui sont particulièrement utiles pour les ensembles de données avec des données temporelles ou des identifiants séquentiels.
Exemple de partitionnement basé sur le temps
CREATE TABLE logs (
id SERIAL,
log_time TIMESTAMP NOT NULL,
message TEXT
);
SELECT partman.create_parent(
p_parent_table := 'public.logs',
p_control := 'log_time',
p_type := 'time',
p_interval := 'daily'
);
Cette configuration :
- Crée automatiquement des partitions quotidiennes
- Simplifie les requêtes et la maintenance des données de journal
Exemple de partitionnement basé sur le séquentiel
CREATE TABLE transactions (
transaction_id BIGSERIAL PRIMARY KEY,
details TEXT NOT NULL
);
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 100000
);
Cela crée des partitions tous les 100 000 lignes, garantissant que la table parent reste gérable.
Fonctionnalités d’automatisation
Maintenance automatique
Utilisez run_maintenance() pour garantir que les futures partitions sont pré-créées :
SELECT partman.run_maintenance();
Politiques de rétention
Définissez des périodes de rétention pour supprimer automatiquement les anciennes partitions :
UPDATE partman.part_config
SET retention = '12 months'
WHERE parent_table = 'public.logs';
Avantages de pg_partman
- Simplifie la création dynamique de partitions
- Automatise le nettoyage et la maintenance
- Réduit le besoin de mises à jour manuelles du schéma
Cas d’utilisation pratiques pour le partitionnement de table
- Gestion des journaux. Journaux à haute fréquence partitionnés par jour pour une archivage et une interrogation faciles.
- Données multirégionales. Systèmes de commerce électronique divisant les commandes par région pour une scalabilité améliorée.
- Données de séries temporelles. Applications IoT avec des données de télémétrie partitionnées.
Gestion des journaux
Partitionner les journaux par jour ou par mois pour gérer efficacement les données à haute fréquence.
SELECT partman.create_parent(
p_parent_table := 'public.server_logs',
p_control := 'timestamp',
p_type := 'time',
p_interval := 'monthly'
);
Données Multi-Régionales
Partitionner les ventes ou les données d’inventaire par région pour une meilleure évolutivité.
CREATE TABLE sales (
sale_id SERIAL,
region TEXT NOT NULL
) PARTITION BY LIST (region);
Transactions à Haut Volume
Partitionner les transactions par identifiant de série ID pour éviter les index surdimensionnés.
SELECT partman.create_parent(
p_parent_table := 'public.transactions',
p_control := 'transaction_id',
p_type := 'serial',
p_interval := 10000
);
Conclusion
La partition de table est une technique indispensable pour gérer de grands ensembles de données. Les fonctionnalités intégrées de PostgreSQL, combinées à l’extension pg_partman, facilitent la mise en œuvre de stratégies de partitionnement dynamiques et automatisées. Ces outils permettent aux administrateurs de base de données d’améliorer les performances, de simplifier la maintenance et de scaler efficacement.
Le partitionnement est un pilier de la gestion moderne des bases de données, notamment dans les applications à haut volume. Comprendre et appliquer ces concepts garantit des systèmes de base de données robustes et évolutifs.
Source:
https://dzone.com/articles/postgresql-partitioning-pg-partman-data-management